Deep Residual Shrinkage Network चाहिँ Deep Residual Network को एक सुधार गरिएको (improved) variant हो। वास्तवमा, यो Deep Residual Network, Attention Mechanisms, र Soft Thresholding functions को एकीकरण (integration) हो。
केही हदसम्म, Deep Residual Shrinkage Network को काम गर्ने तरिका (working principle) यसरी बुझ्न सकिन्छ: यसले Attention Mechanisms को प्रयोग गरेर unimportant features लाई पहिचान गर्छ र Soft Thresholding functions द्वारा तिनीहरूलाई zero set गर्छ; त्यसै गरी, यसले important features लाई पहिचान गरी तिनीहरूलाई retain गर्छ। यो process ले Deep Neural Network को noise भएको signals बाट useful features extract गर्ने क्षमता (ability) लाई बढाउँछ。
1. Research Motivation
पहिलो कुरा, samples लाई classify गर्दा, noise—जस्तै Gaussian noise, pink noise, र Laplacian noise—हुनु स्वाभाविक (inevitable) हो。 अझ विस्तृत रूपमा भन्नुपर्दा, samples मा धेरै जसो current classification task सँग असम्बन्धित (irrelevant) information हुन सक्छ, जसलाई पनि noise को रूपमा बुझ्न सकिन्छ。 यस्तो noise ले classification performance मा नकारात्मक असर पार्न सक्छ。 (Soft thresholding धेरै signal denoising algorithms को एक मुख्य step हो。)
उदाहरणको लागि, सडक छेउमा कुरा गर्दा, आवाजमा गाडीको हर्न र पाङ्ग्रा (wheels) को आवाज mix हुन सक्छ। यस्ता signals मा speech recognition गर्दा, यिनीहरूको नतिजा (result) मा background sounds को असर पर्नु स्वाभाविक हो。 Deep learning को दृष्टिकोणबाट हेर्दा, हर्न र wheels सँग सम्बन्धित features लाई Deep Neural Network भित्र नै हटाउनुपर्छ, जसले गर्दा speech recognition को result मा असर नपरोस्。
दोस्रो कुरा, एउटै dataset भित्र पनि, noise को मात्रा (amount) sample अनुसार फरक हुन सक्छ。 (यो कुरा attention mechanisms सँग मिल्दोजुल्दो छ; image dataset को उदाहरण लिँदा, target object को location फरक-फरक image मा फरक हुन सक्छ, र attention mechanisms ले प्रत्येक image मा target object को location मा focus गर्न सक्छ。)
उदाहरणको लागि, यदि हामी कुकुर र बिरालो (cat-and-dog) classifier train गरिरहेका छौं भने, “dog” label गरिएका ५ वटा images लाई लिन सकिन्छ। पहिलो image मा कुकुर र मुसा हुन सक्छ, दोस्रोमा कुकुर र हाँस (goose), तेस्रोमा कुकुर र कुखुरा, चौथोमा कुकुर र गधा (donkey), र पाँचौंमा कुकुर र हाँस (duck) हुन सक्छ। Training को दौरान, classifier ले मुसा, हाँस, कुखुरा, गधा, र हाँस जस्ता irrelevant objects बाट interference महसुस गर्न सक्छ, जसले गर्दा classification accuracy घट्न सक्छ। यदि हामी यस्ता irrelevant objects—मुसा, हाँस, कुखुरा, गधा, र हाँस—लाई पहिचान गर्न सक्छौं र तिनका corresponding features लाई हटाउन सक्छौं भने, cat-and-dog classifier को accuracy सुधार गर्न सकिन्छ。
2. Soft Thresholding
Soft thresholding धेरै signal denoising algorithms को एक core step हो। यसले ती features लाई हटाउँछ जसको absolute values एउटा निश्चित threshold भन्दा कम हुन्छन्, र ती features लाई zero तिर shrink गर्छ जसको absolute values threshold भन्दा बढी हुन्छन्。 यसलाई तलको formula बाट implement गर्न सकिन्छ:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Input को respect मा soft thresholding output को derivative यस प्रकार छ:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]माथि देखाइए जस्तै, soft thresholding को derivative या त 1 हुन्छ या 0 हुन्छ। यो property ReLU activation function सँग मिल्दोजुल्दो छ。 त्यसैले, soft thresholding ले deep learning algorithms मा हुने gradient vanishing र gradient exploding को जोखिम (risk) लाई कम गर्न सक्छ。
Soft thresholding function मा, threshold set गर्दा दुई वटा conditions पूरा गर्नुपर्छ: पहिलो, threshold positive number हुनुपर्छ; दोस्रो, threshold input signal को maximum value भन्दा बढी हुनु हुँदैन, अन्यथा output पुरै zero हुनेछ。
साथै, threshold ले तेस्रो condition पनि पूरा गरे राम्रो हुन्छ: प्रत्येक sample को आफ्नो noise content को आधारमा आफ्नै स्वतन्त्र (independent) threshold हुनुपर्छ。
किनकि, धेरै जसो samples मा noise content फरक हुन्छ। उदाहरणको लागि, एउटै dataset भित्र Sample A मा कम noise र Sample B मा बढी noise हुनु सामान्य हो। यस्तो अवस्थामा, denoising algorithm मा soft thresholding गर्दा, Sample A ले सानो threshold use गर्नुपर्छ भने Sample B ले ठूलो threshold use गर्नुपर्छ। यद्यपि deep neural networks मा यी features र thresholds ले आफ्नो भौतिक अर्थ (explicit physical definitions) गुमाउँछन्, तर यसको आधारभूत logic उस्तै रहन्छ। अर्को शब्दमा भन्नुपर्दा, प्रत्येक sample को आफ्नो specific noise content द्वारा निर्धारित आफ्नै independent threshold हुनुपर्छ。
3. Attention Mechanism
Computer Vision को क्षेत्रमा Attention mechanisms बुझ्न अलि सजिलो छ। जनावरहरूको visual system ले पुरै area लाई छिटो scan गरेर targets लाई छुट्याउन सक्छ, र त्यसपछि target object मा attention focus गरेर बढी details extract गर्छ र irrelevant information लाई suppress गर्छ। यसको बारेमा थप जानकारीको लागि attention mechanisms सम्बन्धी literature हेर्न सक्नुहुन्छ。
Squeeze-and-Excitation Network (SENet) चाहिँ attention mechanisms use गर्ने एक relatively नयाँ deep learning method हो। विभिन्न samples मा, फरक-फरक feature channels ले classification task मा पुर्याउने योगदान (contribution) फरक हुन सक्छ। SENet ले एउटा सानो sub-network use गरेर weights को set प्राप्त गर्छ र ती weights लाई सम्बन्धित channels को features सँग multiply गरेर प्रत्येक channel को feature magnitude लाई adjust गर्छ। यो process लाई विभिन्न feature channels मा फरक-फरक level को attention दिने तरिकाको रूपमा हेर्न सकिन्छ。
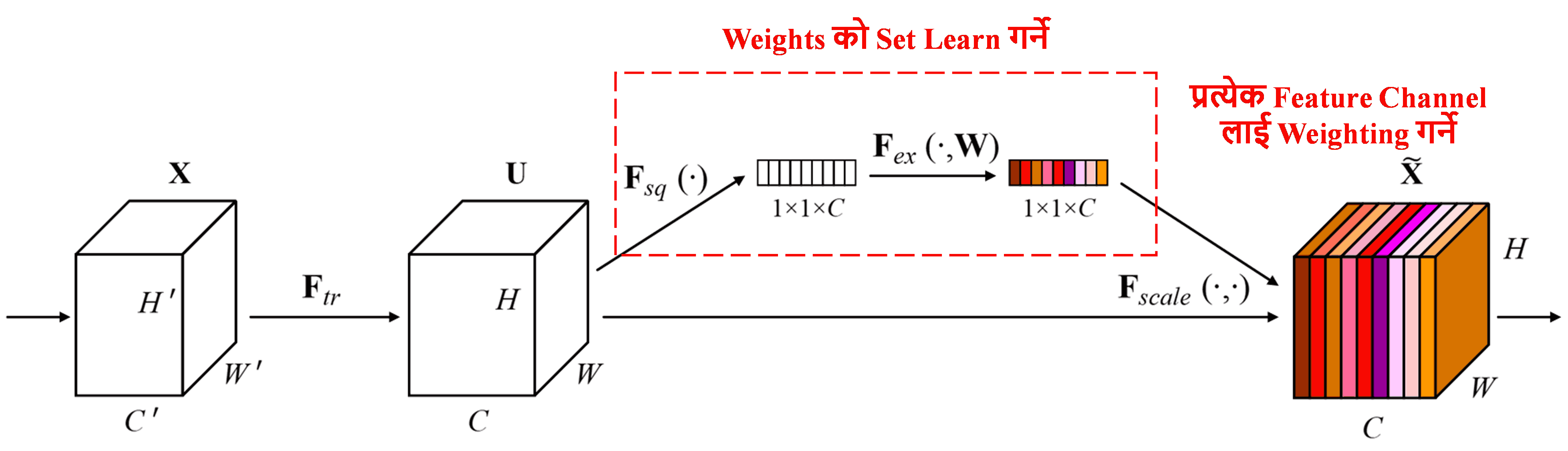
यो approach मा, प्रत्येक sample सँग आफ्नै independent weights को set हुन्छ। अर्को शब्दमा, कुनै पनि दुई arbitrary samples को weights फरक हुन्छन्। SENet मा, weights प्राप्त गर्ने specific path “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function” हो。
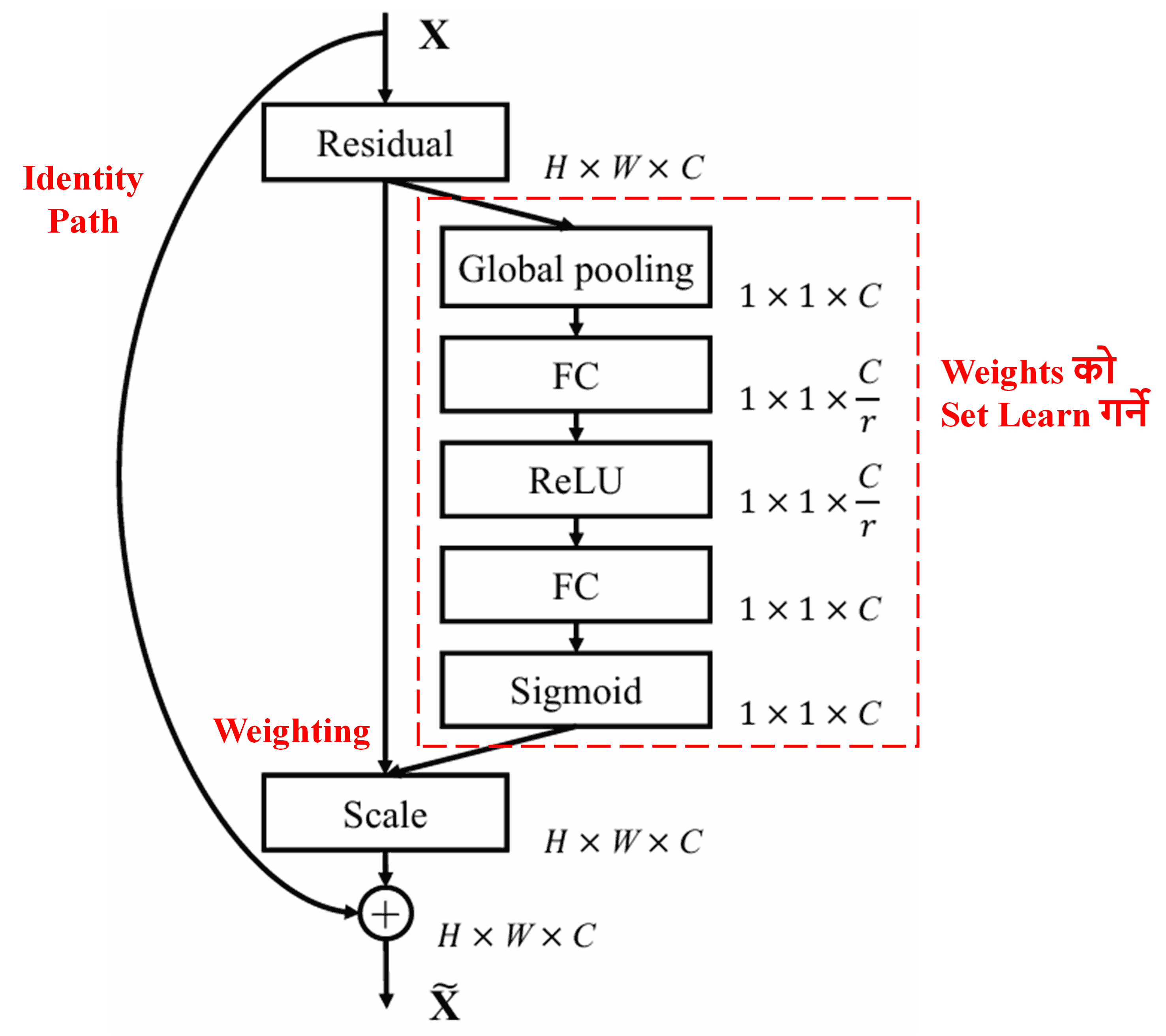
4. Soft Thresholding with Deep Attention Mechanism
Deep Residual Shrinkage Network ले माथि उल्लेखित SENet sub-network structure बाट प्रेरणा लिएर Deep Attention Mechanism अन्तर्गत soft thresholding implement गर्छ। Sub-network (रातो box भित्र देखाइएको) द्वारा, प्रत्येक feature channel मा soft thresholding apply गर्न thresholds को एउटा set learn गर्न सकिन्छ。
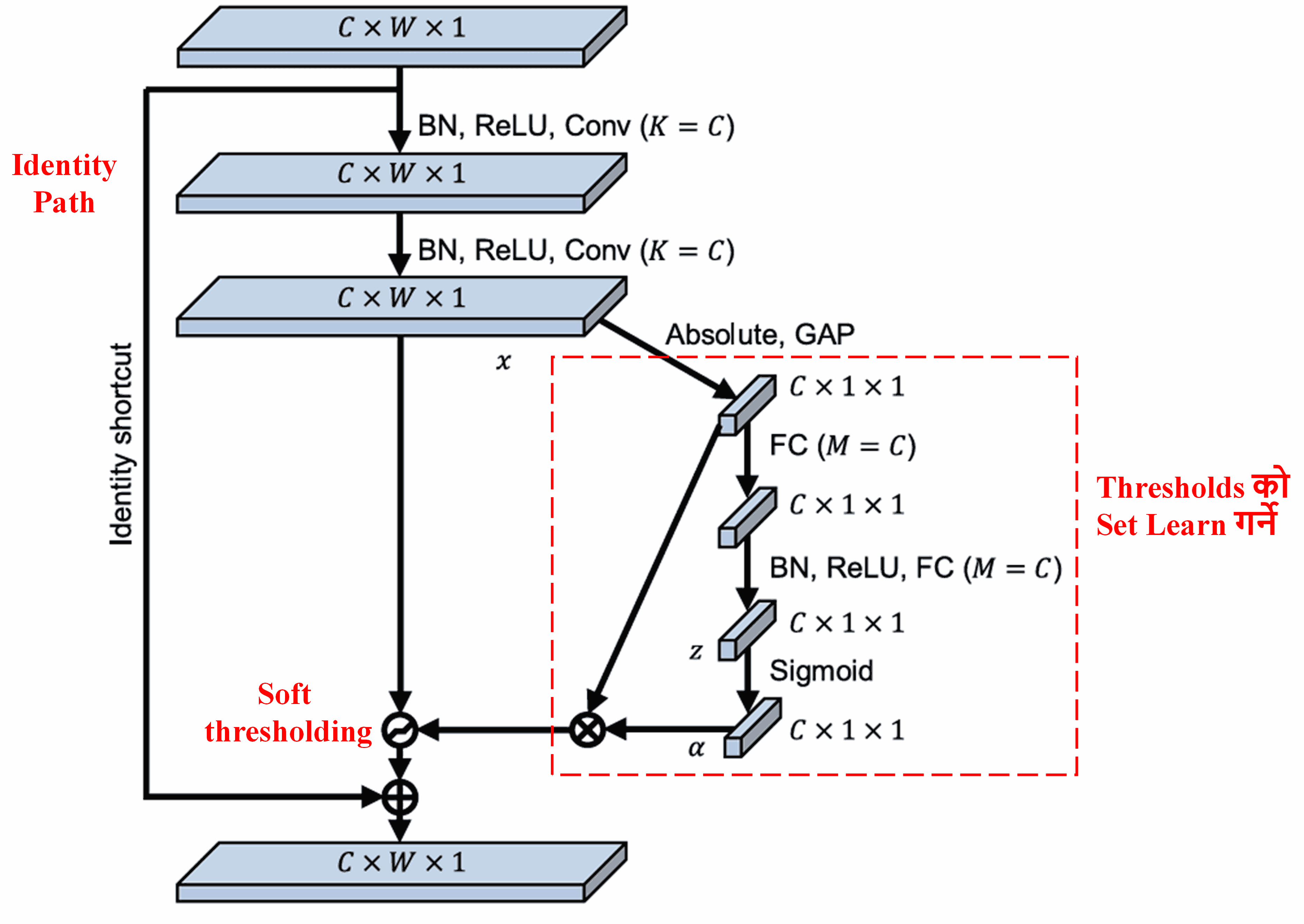
यो sub-network मा, सबै भन्दा पहिला input feature map को सबै features को absolute values निकालिन्छ। त्यसपछि, Global Average Pooling (GAP) र averaging गरेर एउटा feature प्राप्त गरिन्छ, जसलाई A मानौं। अर्को path मा, Global Average Pooling पछिको feature map लाई एउटा सानो Fully Connected (FC) Network मा input गरिन्छ। यो FC Network ले Sigmoid function लाई आफ्नो अन्तिम layer को रूपमा use गरेर output लाई 0 र 1 को बीचमा normalize गर्छ, जसबाट एउटा coefficient α प्राप्त हुन्छ। Final threshold लाई α × A को रूपमा express गर्न सकिन्छ। त्यसैले, threshold भनेको 0 र 1 बीचको एउटा number र feature map को absolute values को average को product हो। यो method ले threshold positive मात्र होइन, अति ठूलो (excessively large) नहुने कुरा पनि ensure गर्छ。
अझ मुख्य कुरा, फरक-फरक samples को लागि फरक-फरक thresholds हुन्छन्। फलस्वरूप, केही हदसम्म, यसलाई एउटा specialized attention mechanism को रूपमा बुझ्न सकिन्छ: यसले current task सँग असम्बन्धित (irrelevant) features लाई identify गर्छ, दुई वटा convolutional layers द्वारा तिनीहरूलाई zero को नजिकको value मा transform गर्छ, र soft thresholding use गरेर zero बनाउँछ; अथवा, यसले current task सँग सम्बन्धित (relevant) features लाई identify गर्छ, दुई वटा convolutional layers द्वारा तिनीहरूलाई zero भन्दा टाढाको value मा transform गर्छ, र तिनीहरूलाई preserve गर्छ。
अन्त्यमा, Convolutional layers, Batch Normalization, Activation functions, Global Average Pooling, र Fully Connected output layers सँगै केही संख्यामा basic modules लाई stack गरेर, पुरै Deep Residual Shrinkage Network बनाउन सकिन्छ。
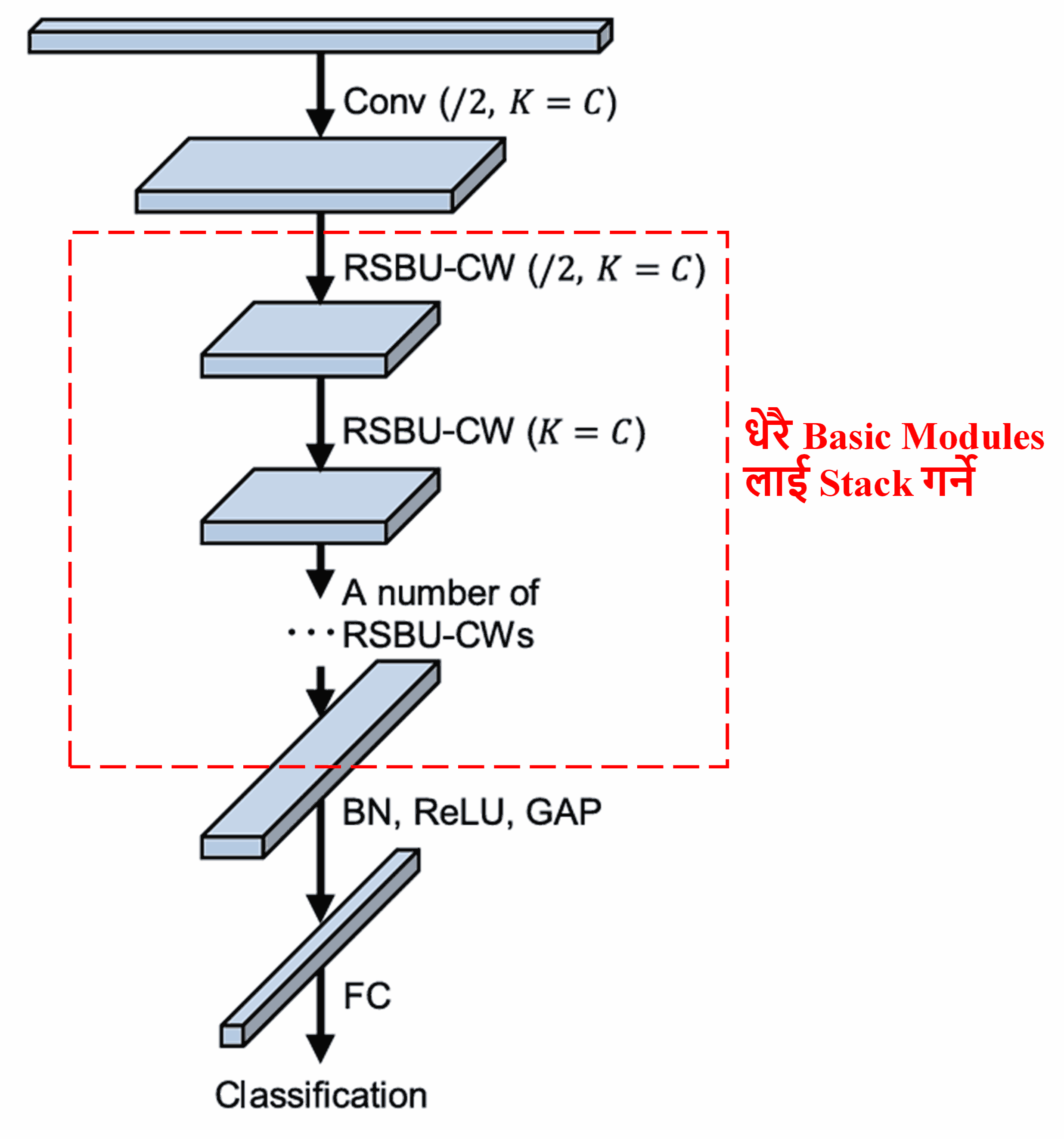
5. Generalization Capability
Deep Residual Shrinkage Network वास्तवमा एउटा general feature learning method हो। किनकि, धेरै जसो feature learning tasks मा, samples मा केही हदसम्म noise र irrelevant information हुन्छ। यस्तो noise र irrelevant information ले feature learning को performance मा असर पार्न सक्छ। उदाहरणको लागि:
Image classification मा, यदि एउटा image मा धेरै अन्य objects हरू छन् भने, ती objects लाई “noise” को रूपमा बुझ्न सकिन्छ। Deep Residual Shrinkage Network ले attention mechanism use गरेर यो “noise” लाई notice गर्न सक्छ र soft thresholding द्वारा यो “noise” सँग corresponding features लाई zero बनाउन सक्छ, जसले गर्दा image classification accuracy बढ्न सक्छ。
Speech recognition मा, विशेष गरी noisy environments जस्तै सडक छेउमा कुरा गर्दा वा factory workshop भित्र, Deep Residual Shrinkage Network ले speech recognition accuracy सुधार गर्न सक्छ, वा कम्तीमा पनि speech recognition accuracy बढाउने एउटा तरिका (methodology) प्रदान गर्न सक्छ。
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Academic Impact
यो paper ले Google Scholar मा 1,400 भन्दा बढी citations प्राप्त गरेको छ。
अपूर्ण तथ्याङ्क (Incomplete statistics) अनुसार, Deep Residual Shrinkage Network (DRSN) लाई mechanical engineering, electrical power, vision, healthcare, speech, text, radar, र remote sensing लगायत धेरै क्षेत्रहरू (fields) मा 1,000 भन्दा बढी publications/studies मा सिधै apply गरिएको छ वा modify गरेर apply गरिएको छ。