Ny Deep Residual Shrinkage Network dia dikan-teny nohatsaraina avy amin’ny Deep Residual Network. Amin’ny ankapobeny, io dia fampiarahana ny Deep Residual Network, attention mechanisms, ary soft thresholding functions.
Azo lazaina fa ny fomba fiasan’ny Deep Residual Shrinkage Network dia toy izao: mampiasa attention mechanisms izy mba hamantarana ireo features tsy dia ilaina, ary mampiasa soft thresholding functions mba hanaovana azy ireo ho zero; etsy ankilany, mamantatra ireo features manan-danja izy ary mitazona azy ireo. Izany dingana izany dia manatsara ny fahaizan’ny deep neural network maka features mahasoa avy amin’ny signals izay misy noise.
1. Antony nanaovana ny fikarohana (Research Motivation)
Voalohany, rehefa manao classifying samples, dia tsy azo ialana ny fisian’ny noise—toy ny Gaussian noise, pink noise, ary Laplacian noise. Amin’ny heviny mivelatra kokoa, ny samples dia matetika misy fampahalalana tsy misy ifandraisany amin’ny classification task atao amin’izany fotoana izany, ary azo raisina ho toy ny noise koa izany. Mety hisy fiantraikany ratsy amin’ny vokatry ny classification io noise io. (Ny Soft thresholding dia dingana lehibe amin’ny signal denoising algorithms maro.)
Ohatra, mandritra ny resaka eny amoron-dalana, ny feo dia mety hifangaro amin’ny feon’ny klakson’ny fiara sy ny kodiaran’ny fiara. Rehefa manao speech recognition amin’ireo signals ireo, dia tsy maintsy hisy fiantraikany amin’ny vokatra ireo feo avy any ivelany ireo. Raha jerena amin’ny fomba fijery deep learning, ireo features mifanandrify amin’ny klakson sy ny kodia dia tokony hesorina ao anatin’ny deep neural network mba tsy hisy fiantraikany amin’ny vokatry ny speech recognition.
Faharoa, na dia ao anatin’ny dataset iray ihany aza, dia matetika miovaova ny habetsahan’ny noise isaky ny sample. (Misy itovizana amin’ny attention mechanisms izany; raha maka dataset-na sary isika ohatra, dia mety tsy hitovy ny toerana misy ilay zavatra tadiavina na target object isaky ny sary, ary ny attention mechanisms dia afaka mifantoka amin’ny toerana manokana misy ilay target object isaky ny sary.)
Ohatra, rehefa manao training an’ny cat-and-dog classifier, andao haka sary dimy misy label hoe “alika” (dog). Ny sary voalohany dia mety misy alika sy voalavo, ny faharoa misy alika sy gisa, ny fahatelo misy alika sy akoho, ny fahefatra misy alika sy ampondra, ary ny fahadimy misy alika sy gana. Mandritra ny training, ny classifier dia tsy maintsy hiharan’ny fanelingelenana avy amin’ireo zavatra tsy misy ifandraisany toy ny voalavo, gisa, akoho, ampondra, ary gana, izay mahatonga ny fihenan’ny classification accuracy. Raha afaka mamantatra ireo zavatra tsy ilaina ireo isika—ireo voalavo, gisa, akoho, ampondra, ary gana—ary manala ireo features mifanandrify aminy, dia azo atao ny manatsara ny accuracy an’ny cat-and-dog classifier.
2. Soft Thresholding
Ny Soft thresholding dia dingana fototra ao amin’ny signal denoising algorithms maro. Fafany ireo features izay manana absolute values ambany noho ny threshold iray, ary ataony manakaiky ny zero (shrinks) ireo features izay manana absolute values ambony noho io threshold io. Azo tanterahina amin’ny alalan’ity formula manaraka ity izany:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Ny derivative-n’ny output-n’ny soft thresholding raha oharina amin’ny input dia:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Araka ny hita eo ambony, ny derivative-n’ny soft thresholding dia na 1 na 0. Ity toetra ity dia mitovy tanteraka amin’ny an’ny ReLU activation function. Noho izany, ny soft thresholding dia afaka mampihena koa ny risika mety hahatonga ny deep learning algorithms hiharan’ny gradient vanishing sy gradient exploding.
Ao amin’ny soft thresholding function, ny fametrahana ny threshold dia tsy maintsy manaraka fepetra roa: voalohany, ny threshold dia tsy maintsy isa positive; faharoa, ny threshold dia tsy mahazo mihoatra ny maximum value an’ny input signal, raha tsy izany dia ho zero tanteraka ny output.
Fanampin’izany, tsara kokoa raha manaraka fepetra fahatelo ny threshold: Isaky ny sample dia tokony hanana threshold mahaleo tena (independent) mifanaraka amin’ny habetsahan’ny noise ao aminy.
Izany dia satria matetika tsy mitovy ny habetsahan’ny noise amin’ireo samples samihafa. Ohatra, fahita matetika ao anatin’ny dataset iray ihany fa ny Sample A dia mety misy noise kely kokoa raha ny Sample B kosa misy noise betsaka kokoa. Amin’ity tranga ity, rehefa manao soft thresholding ao amin’ny denoising algorithm, ny Sample A dia tokony hampiasa threshold kely kokoa, fa ny Sample B kosa tokony hampiasa threshold lehibe kokoa. Na dia very aza ny dika fizika mazava (explicit physical definitions) an’ireo features sy thresholds ireo ao anatin’ny deep neural networks, dia mbola mitovy ihany ny lojika fototra. Izany hoe, ny sample tsirairay dia tokony hanana threshold manokana voafaritry ny habetsahan’ny noise ao aminy.
3. Attention Mechanism
Ny Attention mechanisms dia somary mora azo ao amin’ny sehatry ny computer vision. Ny rafi-pahitana (visual systems) an’ny biby dia afaka manavaka ireo zavatra kendrena (targets) amin’ny alalan’ny fijerena haingana ny faritra manontolo, ary avy eo mifantoka (focusing attention) amin’ilay target object mba hahazoana antsipiriany bebe kokoa sady manakana ireo fampahalalana tsy ilaina. Raha mila fanazavana fanampiny dia jereo ny boky momba ny attention mechanisms.
Ny Squeeze-and-Excitation Network (SENet) dia fomba deep learning somary vaovao izay mampiasa attention mechanisms. Amin’ny samples samihafa, ny fandraisan’anjaran’ny feature channels samihafa amin’ny classification task dia matetika tsy mitovy. Ny SENet dia mampiasa sub-network kely mba hahazoana andiana weights ary avy eo dia mampitombo ireo weights ireo amin’ny features mifanandrify amin’ny channels tsirairay mba hanitsiana ny haben’ny (magnitude) features isaky ny channel. Ity dingana ity dia azo raisina ho toy ny fampiharana attention amin’ny ambaratonga samihafa ho an’ny feature channels samihafa.
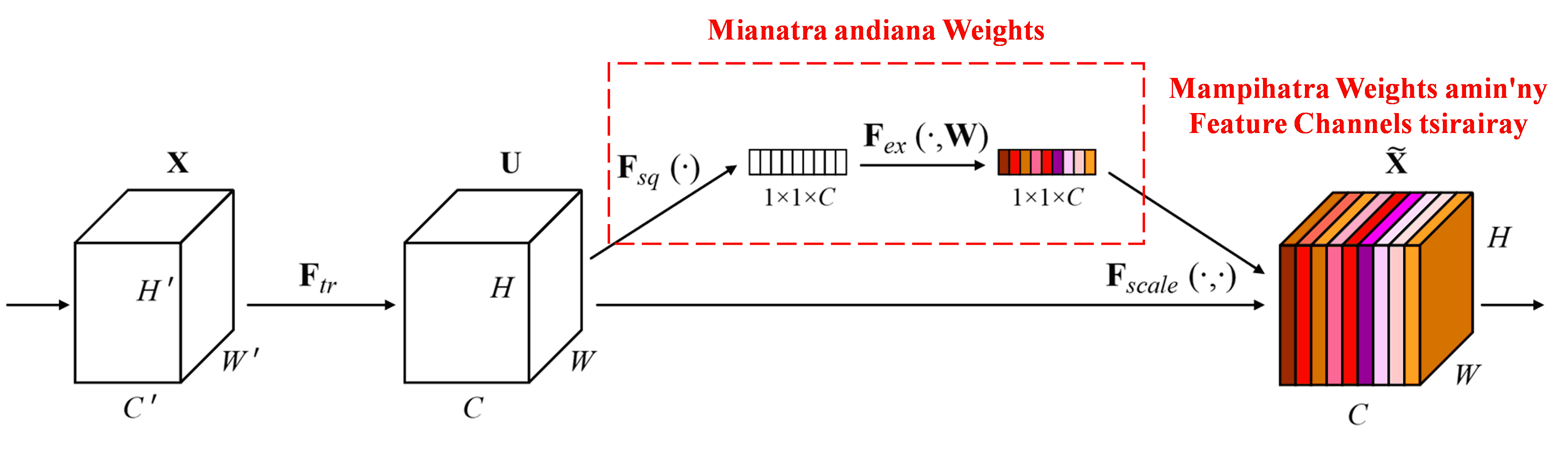
Amin’ity fomba ity, ny sample tsirairay dia manana andiana weights azy manokana sy mahaleo tena. Raha lazaina amin’ny teny hafa, ny weights ho an’ny samples roa samy hafa dia tsy mitovy. Ao amin’ny SENet, ny lalana manokana ahazoana ny weights dia “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function.”
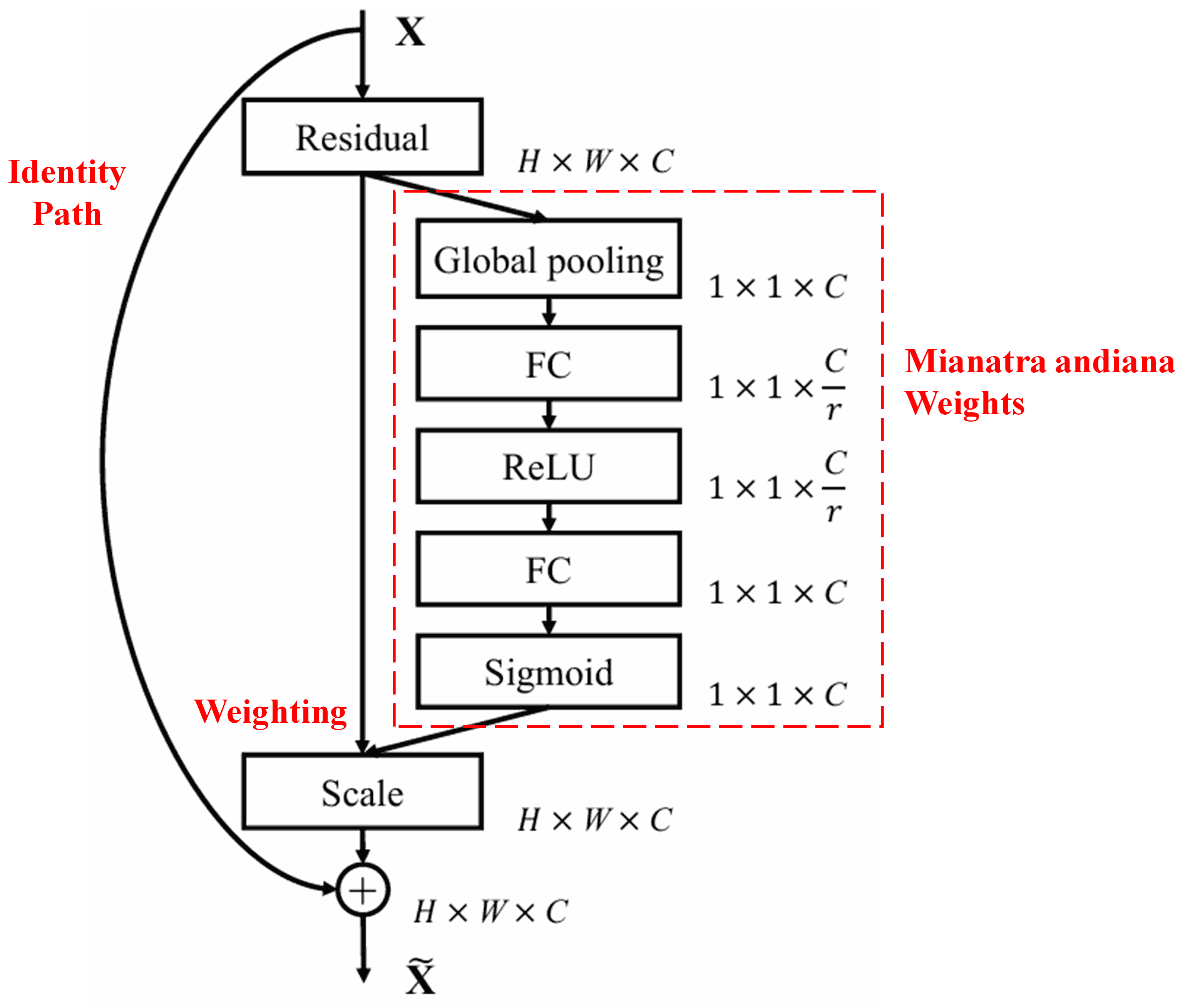
4. Soft Thresholding miaraka amin’ny Deep Attention Mechanism
Ny Deep Residual Shrinkage Network dia naka tahaka ny firafitry ny sub-network SENet voalaza etsy ambony mba hametrahana soft thresholding eo ambany fitantanan’ny deep attention mechanism. Amin’ny alalan’ny sub-network (aseho ao anatin’ny boaty mena), dia azo atao ny mianatra andiana thresholds mba hampiharana soft thresholding amin’ny feature channel tsirairay.
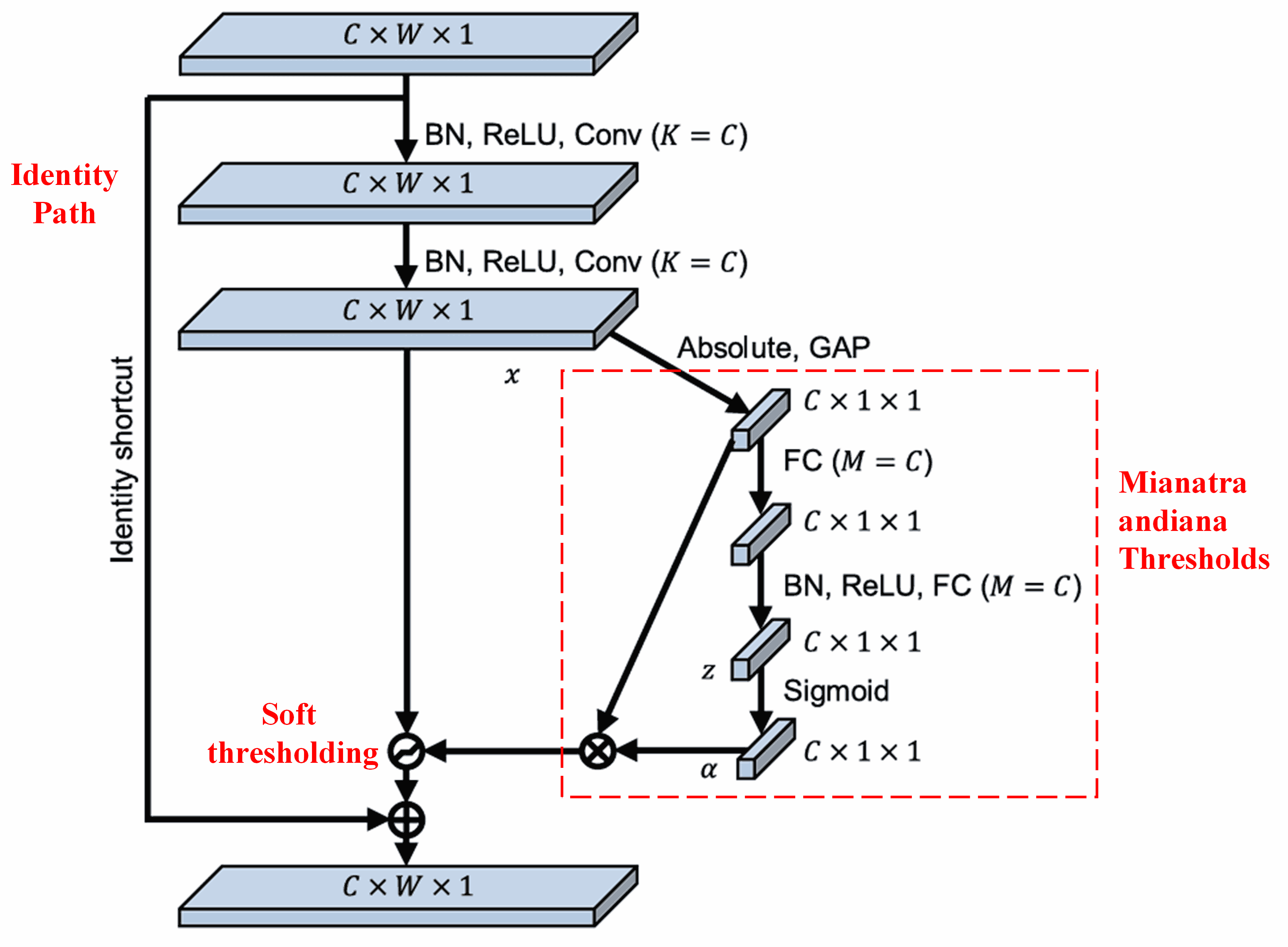
Ao anatin’ity sub-network ity, kajiana aloha ny absolute values an’ny features rehetra ao amin’ny input feature map. Avy eo, amin’ny alalan’ny global average pooling sy ny fanaovana salan’isa (averaging), dia mahazo feature iray isika, izay antsoina hoe A. Any amin’ny lalana iray hafa, ny feature map avy eo amin’ny global average pooling dia ampidirina ao anaty fully connected network kely. Ity fully connected network ity dia mampiasa ny Sigmoid function ho toy ny layer farany mba hanaovana normalize ny output ho eo anelanelan’ny 0 sy 1, ka manome coefficient iray antsoina hoe α. Ny threshold farany dia azo soratana hoe α × A. Noho izany, ny threshold dia vokatry ny fampitomboana isa iray eo anelanelan’ny 0 sy 1 sy ny salan’isan’ny absolute values an’ny feature map. Ity fomba ity dia manome antoka fa ny threshold dia tsy vitan’ny hoe positive fotsiny, fa tsy lehibe loatra koa.
Fanampin’izany, ny samples samihafa dia manome thresholds samihafa. Vokatr’izany, amin’ny lafiny iray, dia azo adika ho toy ny attention mechanism manokana izany: mamantatra ireo features tsy misy ifandraisany amin’ny task atao ankehitriny izy, manova azy ireo ho sanda manakaiky ny zero amin’ny alalan’ny convolutional layers roa, ary mametraka azy ireo ho zero amin’ny alalan’ny soft thresholding; na amin’ny lafiny hafa, mamantatra ireo features mifandraika amin’ny task ankehitriny izy, manova azy ireo ho sanda lavitra ny zero amin’ny alalan’ny convolutional layers roa, ary mitazona azy ireo.
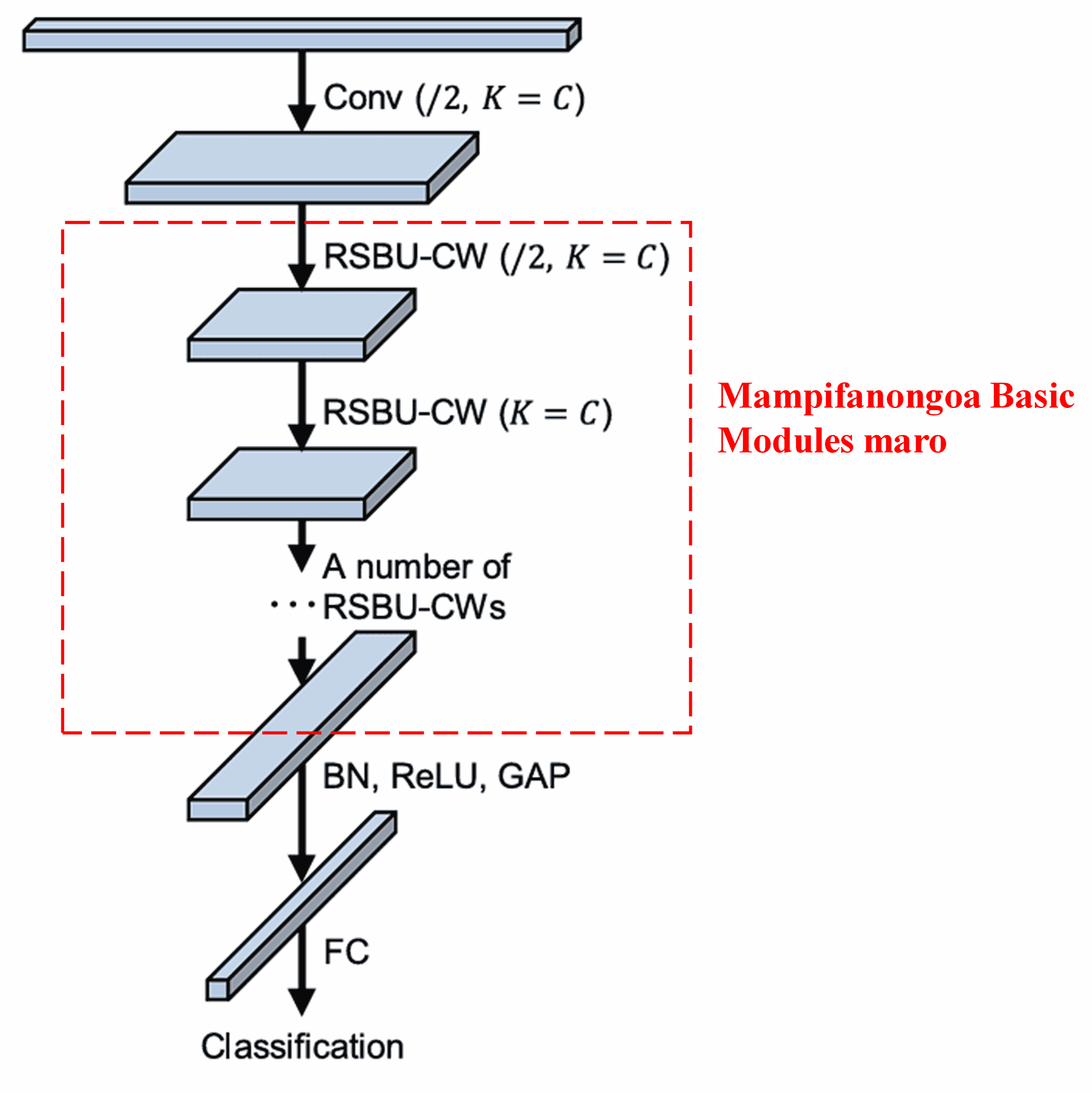
Farany, amin’ny alalan’ny stacking (fampifanongoavana) basic modules maromaro miaraka amin’ny convolutional layers, batch normalization, activation functions, global average pooling, ary fully connected output layers, dia voaorina ny Deep Residual Shrinkage Network feno.
5. Fahaiza-manao ankapobeny (Generalization Capability)
Ny Deep Residual Shrinkage Network raha ny marina dia fomba feature learning ankapobeny. Satria, amin’ny feature learning tasks maro, ny samples dia misy noise na kely na be ary koa fampahalalana tsy ilaina. Ireo noise sy fampahalalana tsy ilaina ireo dia mety hisy fiantraikany amin’ny fahombiazan’ny feature learning. Ohatra:
Amin’ny image classification, raha misy zavatra maro hafa ao anatin’ny sary iray, ireo zavatra ireo dia azo heverina ho “noise.” Ny Deep Residual Shrinkage Network dia mety afaka mampiasa ny attention mechanism mba hamantarana io “noise” io ary avy eo mampiasa soft thresholding mba hametrahana ireo features mifanandrify amin’io “noise” io ho zero, ka mety hanatsara ny accuracy an’ny image classification.
Amin’ny speech recognition, indrindra amin’ny tontolo be tabataba (noisy environments) toy ny resaka eny amoron-dalana na ao anatin’ny orinasa, ny Deep Residual Shrinkage Network dia mety hanatsara ny accuracy an’ny speech recognition, na farafaharatsiny, manolotra fomba fiasa afaka manatsara ny accuracy an’ny speech recognition.
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Fiantraikany ara-akademika (Academic Impact)
Ity taratasy fikarohana ity dia nahazo citations maherin’ny 1,400 ao amin’ny Google Scholar.
Miorina amin’ny antontan’isa tsy feno, ny Deep Residual Shrinkage Network (DRSN) dia efa nampiasaina mivantana na novaina ary nampiasaina tamin’ny famoahana/fikarohana maherin’ny 1,000 amin’ny sehatra maro, ao anatin’izany ny mechanical engineering, electrical power, vision, healthcare, speech, text, radar, ary remote sensing.