Deep Residual Shrinkage Network (DRSN) — бұл Deep Residual Network (ResNet) желісінің жақсартылған нұсқасы. Негізінен, бұл — Deep Residual Network, Attention Mechanism (назар аудару механизмі) және Soft Thresholding (жұмсақ табалдырық) функцияларының интеграциясы.
Deep Residual Shrinkage Network-ның жұмыс істеу принципін белгілі бір деңгейде былай түсінуге болады: ол Attention Mechanism арқылы маңызды емес белгілерді (features) анықтап, Soft Thresholding функциясы арқылы оларды нөлге теңестіреді; ал маңызды белгілерді сақтап қалады. Бұл процесс терең нейрондық желінің (Deep Neural Network) шулы сигналдардан пайдалы ақпаратты бөліп алу қабілетін күшейтеді.
1. Зерттеу мотивациясы
Біріншіден, үлгілерді (samples) жіктеу кезінде, Гаусс шуы (Gaussian noise), қызғылт шу (pink noise) және Лаплас шуы (Laplacian noise) сияқты шулардың болуы сөзсіз. Кеңірек мағынада айтсақ, үлгілерде көбінесе ағымдағы жіктеу тапсырмасына қатысы жоқ ақпараттар болады, оларды да “шу” деп қабылдауға болады. Бұл шу жіктеу нәтижесіне кері әсер етуі мүмкін. (Айта кету керек, Soft Thresholding — сигналдарды шудан тазарту алгоритмдеріндегі негізгі қадамдардың бірі).
Мысалы, жол жиегінде сөйлесу кезінде, дауысқа көлік сигналдары мен дөңгелектердің дыбысы араласуы мүмкін. Осы дыбыстық сигналдарға сөйлеуді тану (speech recognition) жүргізгенде, нәтижеге фондық дыбыстар сөзсіз әсер етеді. Терең оқыту (Deep Learning) тұрғысынан қарағанда, сөйлеуді тану нәтижесіне кедергі келтірмес үшін, көлік сигналы мен дөңгелек дыбыстарына сәйкес келетін белгілер (features) нейрондық желінің ішінде жойылуы керек.
Екіншіден, тіпті бір деректер жиынтығының (dataset) ішінде де, әр үлгідегі шу мөлшері әртүрлі болады. (Бұл Attention Mechanism-ге ұқсас; мысалы, суреттер жиынтығында нысаналы объектінің орналасуы әр суретте әртүрлі болуы мүмкін, ал Attention Mechanism әр суреттегі нақты орынға назар аудара алады).
Мысалы, мысық пен итті жіктейтін классификаторды үйрету кезінде “ит” деп белгіленген 5 суретті қарастырайық. 1-ші суретте ит пен тышқан, 2-шісінде ит пен қаз, 3-шісінде ит пен тауық, 4-шісінде ит пен есек, ал 5-ші суретте ит пен үйрек болуы мүмкін. Үйрету (training) барысында классификаторға тышқан, қаз, тауық, есек және үйрек сияқты қатысы жоқ объектілер сөзсіз кедергі келтіреді, бұл жіктеу дәлдігінің төмендеуіне әкеледі. Егер біз осы қатысы жоқ объектілерді анықтап, оларға сәйкес келетін белгілерді (features) жоя алсақ, мысық пен итті жіктеу дәлдігін арттыруға мүмкіндік туады.
2. Soft Thresholding
Soft Thresholding — сигналдарды шудан тазарту алгоритмдерінің негізгі қадамы. Ол абсолюттік мәні белгілі бір табалдырықтан (threshold) төмен белгілерді жояды және абсолюттік мәні табалдырықтан жоғары белгілерді нөлге қарай қысады (shrinks). Оны келесі формула арқылы жүзеге асыруға болады:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Soft thresholding шығысының кіріске қатысты туындысы:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Жоғарыда көрсетілгендей, Soft thresholding-нің туындысы не 1-ге, не 0-ге тең. Бұл қасиет ReLU активтендіру функциясымен бірдей. Сондықтан, Soft thresholding терең оқыту алгоритмдерінде градиенттің жоғалуы (gradient vanishing) және градиенттің жарылуы (gradient exploding) қаупін азайта алады.
Soft thresholding функциясында табалдырықты (threshold) орнату екі шартқа сай болуы керек: біріншіден, табалдырық оң сан болуы тиіс; екіншіден, табалдырық кіріс сигналының максималды мәнінен аспауы керек, әйтпесе шығыс (output) толығымен нөлге тең болады.
Сонымен қатар, табалдырықтың үшінші шартқа сай болғаны дұрыс: әр үлгінің (sample) өзіндегі шу мөлшеріне байланысты жеке, тәуелсіз табалдырығы болуы керек.
Себебі, үлгілер арасында шу мөлшері жиі өзгеріп отырады. Мысалы, бір деректер жиынтығында А үлгісінде шу аз, ал В үлгісінде шу көп болуы қалыпты жағдай. Мұндай жағдайда, шуды тазарту алгоритмінде Soft thresholding қолданғанда, А үлгісі үшін кішірек табалдырық, ал В үлгісі үшін үлкенірек табалдырық қолданылуы тиіс. Терең нейрондық желілерде бұл белгілер мен табалдырықтар нақты физикалық мағынасын жоғалтса да, негізгі логика өзгеріссіз қалады. Басқаша айтқанда, әр үлгінің шу мөлшеріне қарай анықталған жеке табалдырығы болуы керек.
3. Attention Mechanism
Attention Mechanism (назар аудару механизмі) компьютерлік көру (Computer Vision) саласында түсінуге оңай ұғым. Жануарлардың көру жүйесі барлық аймақты жылдам сканерлеп, нысаналы объектіні ажырата алады, содан кейін назарды сол объектіге аударып, қажетсіз ақпаратты елемей, көбірек детальдарды қабылдайды. Толығырақ ақпаратты Attention Mechanism туралы әдебиеттерден қараңыз.
Squeeze-and-Excitation Network (SENet) — Attention Mechanism-ді қолданатын салыстырмалы түрде жаңа терең оқыту әдісі. Әр түрлі үлгілерде, әр түрлі feature арналарының (feature channels) жіктеу тапсырмасына қосатын үлесі әртүрлі болады. SENet кішкентай ішкі желіні (sub-network) қолданып, салмақтар жиынтығын алады, содан кейін бұл салмақтарды сәйкес арналардың белгілеріне көбейтіп, әр арнадағы белгілердің мөлшерін реттейді. Бұл процесті әр түрлі feature арналарына әртүрлі деңгейде назар аудару (attention) деп қарастыруға болады.
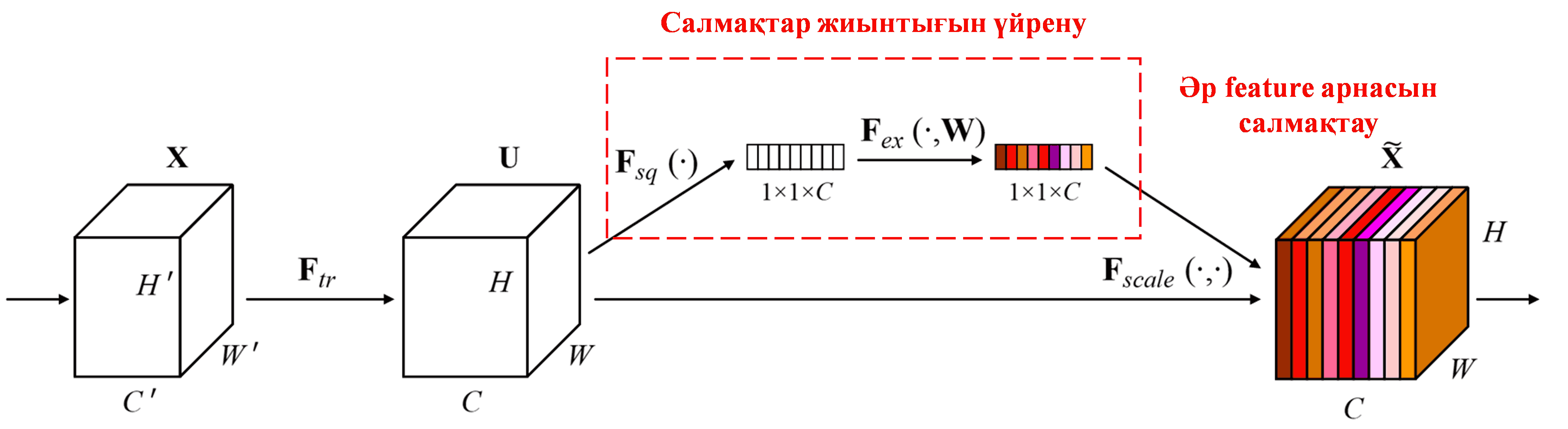
Бұл тәсілде әр үлгінің өзіндік тәуелсіз салмақтар жиынтығы болады. Басқаша айтқанда, кез келген екі үлгінің салмақтары әртүрлі. SENet-те салмақтарды алудың нақты жолы: “Global Pooling → Fully Connected Layer → ReLU функциясы → Fully Connected Layer → Sigmoid функциясы”.
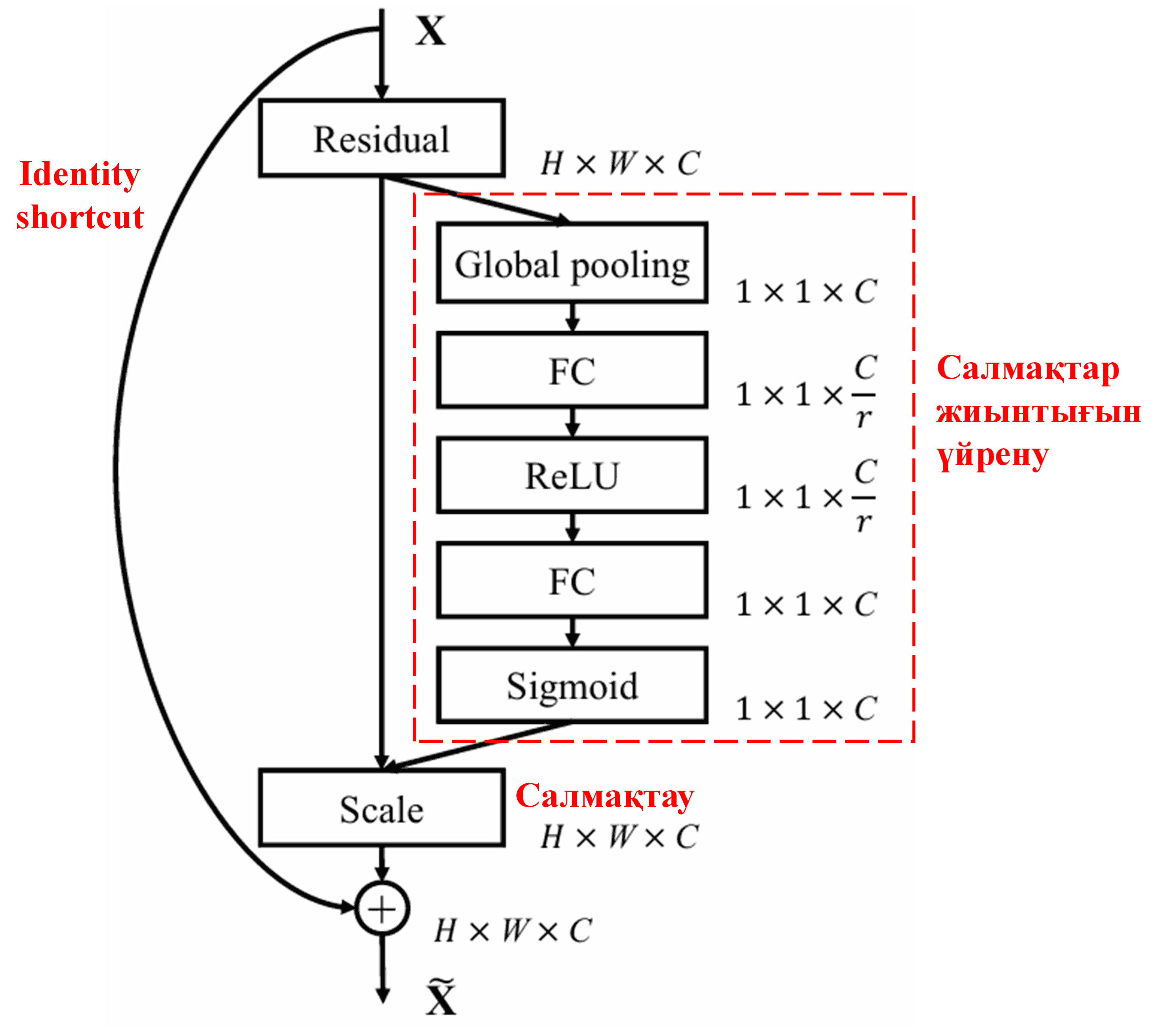
4. Deep Attention Mechanism негізіндегі Soft Thresholding
Deep Residual Shrinkage Network жоғарыда аталған SENet ішкі желісінің құрылымынан шабыт алып, Deep Attention Mechanism негізінде Soft Thresholding-ді жүзеге асырады. Ішкі желі арқылы (қызыл қорапшада көрсетілген) әр feature арнасына Soft Thresholding қолдану үшін табалдырықтар жиынтығын үйренуге (learn) болады.
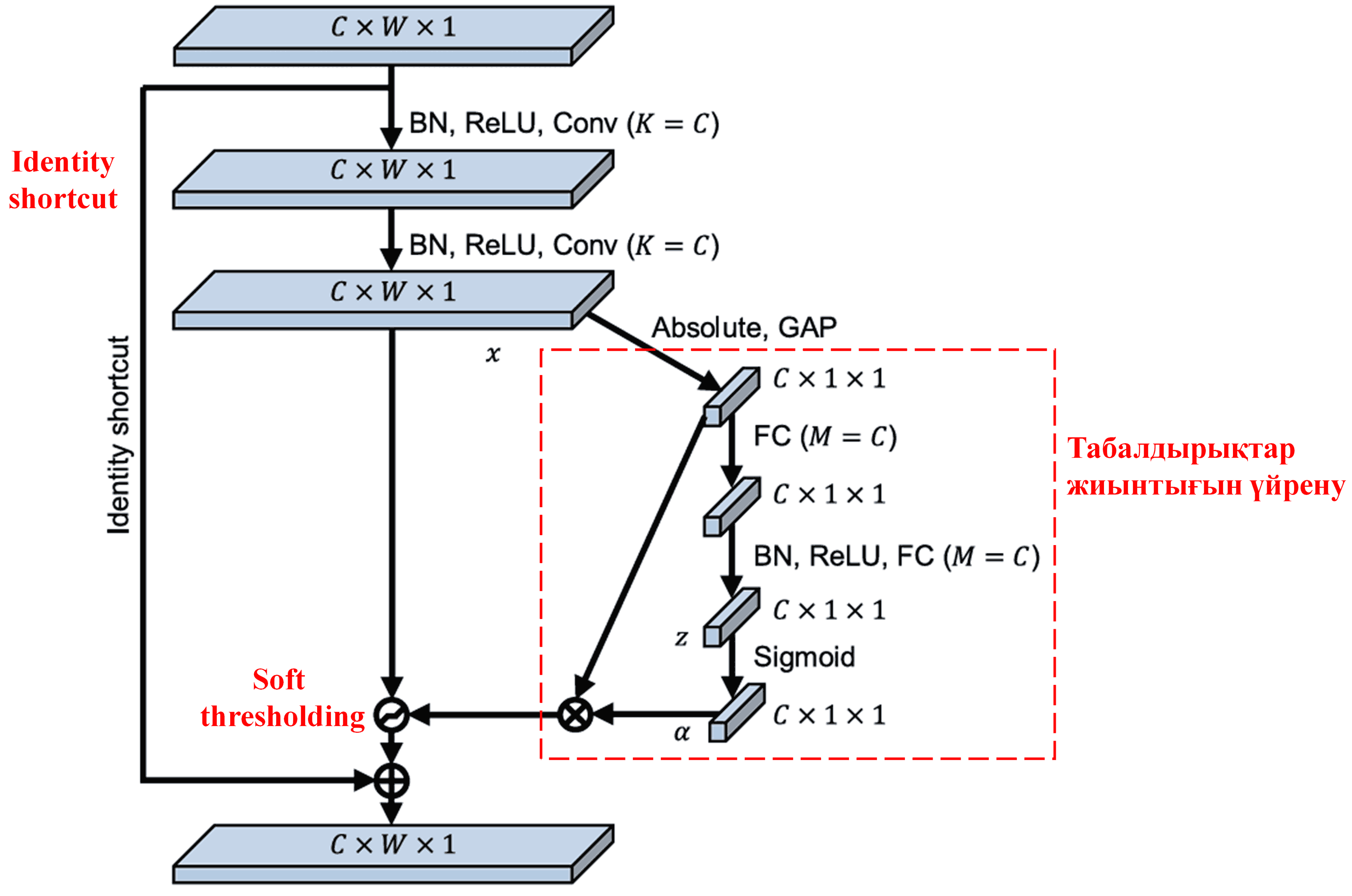
Бұл ішкі желіде алдымен кіріс feature картасындағы (feature map) барлық белгілердің абсолюттік мәндері есептеледі. Содан кейін Global Average Pooling (GAP) және орташалау арқылы A деп белгіленген сипаттама алынады. Екінші жолда, Global Average Pooling-нен өткен feature картасы кішкентай толық байланысқан желіге (fully connected network) енгізіледі. Бұл желі соңғы қабат ретінде Sigmoid функциясын қолданып, шығысты 0 мен 1 аралығында қалыпқа келтіреді (normalize), нәтижесінде α деп белгіленген коэффициент алынады. Соңғы табалдырықты α × A деп өрнектеуге болады. Демек, табалдырық — бұл 0 мен 1 арасындағы сан мен feature картасының абсолюттік мәндерінің орташа көрсеткішінің көбейтіндісі. Бұл әдіс табалдырықтың тек оң сан болуын ғана емес, сонымен қатар оның тым үлкен болмауын да қамтамасыз етеді.
Сонымен қатар, әр түрлі үлгілер үшін әр түрлі табалдырықтар пайда болады. Нәтижесінде, мұны белгілі бір деңгейде арнайы Attention Mechanism ретінде түсінуге болады: ол ағымдағы тапсырмаға қатысы жоқ белгілерді анықтап, екі конволюциялық қабат (convolutional layers) арқылы оларды нөлге жақын мәндерге айналдырады және Soft Thresholding арқылы оларды нөлге теңестіреді; немесе ағымдағы тапсырмаға қатысты маңызды белгілерді анықтап, оларды нөлден алыс мәндерге айналдырып, сақтап қалады.
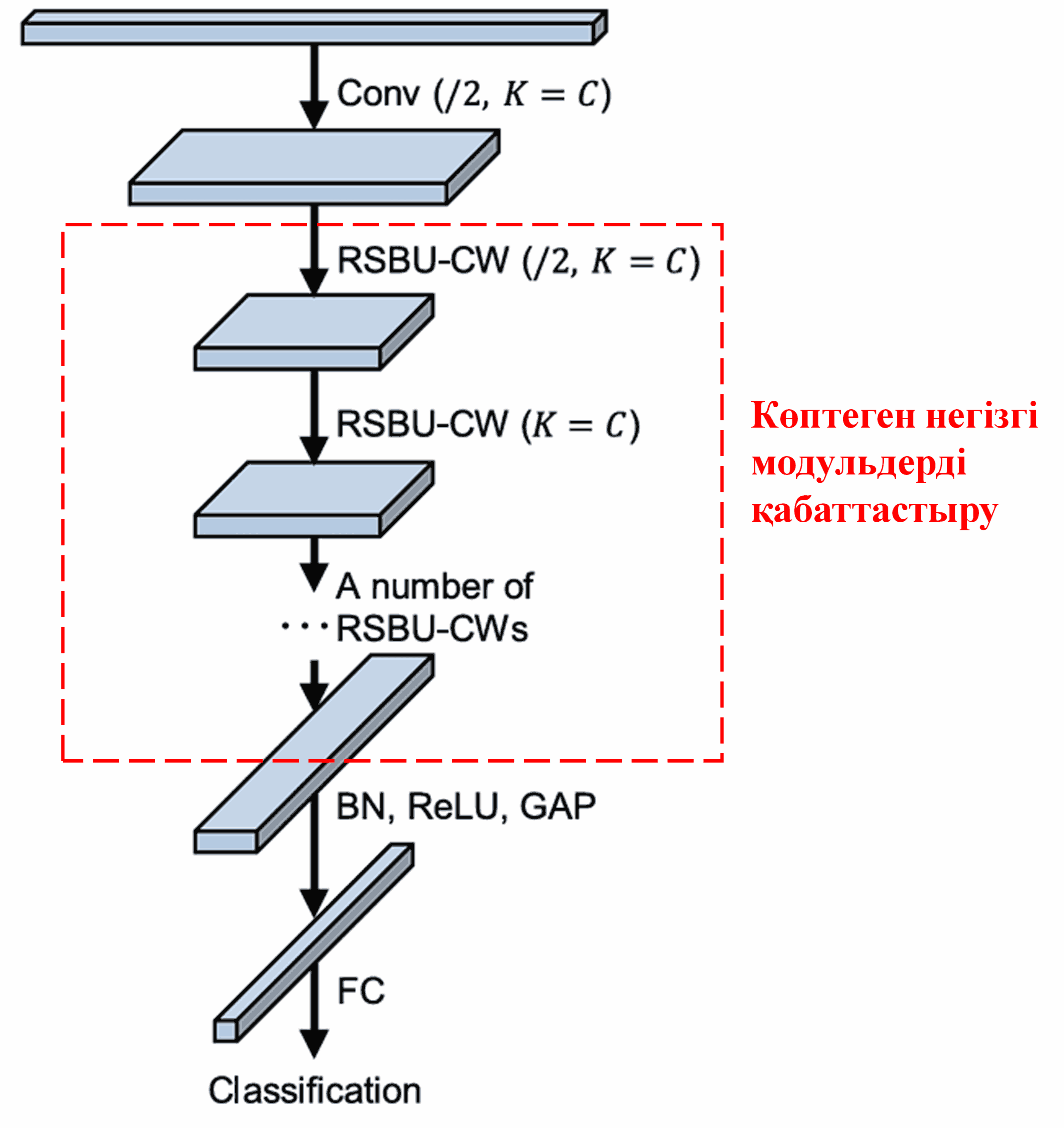
Соңында, негізгі модульдердің белгілі бір санын, сондай-ақ конволюциялық қабаттарды, Batch Normalization, активтендіру функцияларын (activation functions), Global Average Pooling және толық байланысқан шығыс қабаттарын (fully connected output layers) қабаттастыру (stacking) арқылы толық Deep Residual Shrinkage Network құрылады.
5. Жалпылау қабілеті (Generalization Capability)
Deep Residual Shrinkage Network, іс жүзінде, жалпылама белгілерді оқыту (feature learning) әдісі болып табылады. Себебі көптеген feature learning тапсырмаларында үлгілер азды-көпті шу мен қатысы жоқ ақпаратты қамтиды. Бұл шу мен қатысы жоқ ақпарат оқыту нәтижесіне әсер етуі мүмкін. Мысалы:
Кескінді жіктеу (image classification) кезінде, егер суретте көптеген басқа объектілер болса, бұл объектілерді “шу” деп түсінуге болады. Deep Residual Shrinkage Network осы “шуды” байқау үшін Attention Mechanism-ді қолданып, содан кейін Soft Thresholding арқылы осы “шуға” сәйкес келетін белгілерді нөлге теңестіре алады, сөйтіп кескінді жіктеу дәлдігін жақсартуы мүмкін.
Сөйлеуді тану (speech recognition) кезінде, әсіресе жол бойындағы немесе зауыт цехындағы әңгімелесу сияқты шулы орталарда, Deep Residual Shrinkage Network сөйлеуді тану дәлдігін жақсартуы мүмкін, немесе кем дегенде, дәлдікті жақсартуға қабілетті әдістемені ұсынады.
Пайдаланылған әдебиеттер (Reference)
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Академиялық ықпалы
Бұл мақала Google Scholar-да 1400-ден астам сілтеме жинады.
Толық емес статистикалық мәліметтерге сәйкес, Deep Residual Shrinkage Network (DRSN) машина жасау, электр энергетикасы, компьютерлік көру (vision), медицина, сөйлеу, мәтін, радиолокация және қашықтан зондтау (remote sensing) сияқты көптеген салалардағы 1000-нан астам жарияланымдарда/зерттеулерде тікелей қолданылған немесе түрлендіріліп қолданылған.