Глибока залишкова мережа зі стисненням (Deep Residual Shrinkage Network, DRSN) — це покращена версія класичної глибокої залишкової мережі (ResNet). По суті, це інтеграція ResNet, механізмів уваги та функцій м’якої порогової обробки (soft thresholding).
Певною мірою принцип роботи DRSN можна зрозуміти так: за допомогою механізму уваги мережа виявляє неважливі ознаки та обнуляє їх через функцію м’якої порогової обробки; або ж, навпаки, виявляє важливі ознаки та зберігає їх. Цей процес значно посилює здатність глибокої нейронної мережі витягувати корисні ознаки (features) із сигналів, що містять шум.
1. Мотивація дослідження
По-перше, при класифікації зразків у них неминуче присутній певний шум, наприклад, гаусів шум, рожевий шум, лапласів шум тощо. Більш узагальнено, зразки часто містять інформацію, не пов’язану з поточною задачею класифікації, яку також можна розглядати як шум. Цей шум може негативно вплинути на результати класифікації. (Варто зазначити, що м’яка порогова обробка є ключовим етапом у багатьох алгоритмах шумозаглушення сигналу).
Наприклад, під час розмови на узбіччі дороги аудіосигнал може змішуватися зі звуками автомобільних гудків та шумом коліс. Якщо виконувати розпізнавання мови на таких сигналах, результати неминуче постраждають від цих сторонніх звуків. З погляду глибокого навчання (Deep Learning), ознаки, що відповідають гудкам та шуму коліс, повинні бути видалені всередині глибокої нейронної мережі, щоб уникнути їхнього впливу на результат розпізнавання мови.
По-друге, навіть у межах одного набору даних (dataset) кількість шуму в різних зразках часто відрізняється. (Це перегукується з ідеєю механізмів уваги; якщо взяти як приклад набір зображень, то розташування цільового об’єкта може відрізнятися на різних картинках, і механізм уваги дозволяє фокусуватися саме на розташуванні об’єкта в кожному конкретному випадку).
Наприклад, при навчанні класифікатора “кішка/собака”, розглянемо 5 зображень з міткою “собака”. Перше зображення може містити собаку і мишу, друге — собаку і гусака, третє — собаку і курку, четверте — собаку і віслюка, а п’яте — собаку і качку. Під час навчання класифікатор неминуче піддаватиметься впливу нерелевантних об’єктів (мишей, гусей, курей, віслюків та качок), що призведе до зниження точності класифікації. Якщо ми зможемо виявити ці сторонні об’єкти та видалити відповідні їм ознаки, це дозволить підвищити точність класифікатора.
2. М’яка порогова обробка (Soft Thresholding)
М’яка порогова обробка — це основний етап багатьох алгоритмів очищення сигналу від шуму. Вона видаляє ознаки, абсолютне значення яких менше певного порогу, і “стягує” (shrink) до нуля ті ознаки, абсолютне значення яких перевищує цей поріг. Цей процес можна описати такою формулою:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Похідна вихідного значення м’якої порогової обробки по відношенню до вхідного виглядає так:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Як видно з формул, похідна м’якої порогової обробки дорівнює або 1, або 0. Ця властивість ідентична властивості функції активації ReLU. Тому використання м’якої порогової обробки також дозволяє знизити ризик виникнення проблем зникання градієнта (gradient vanishing) та вибуху градієнта (gradient exploding) в алгоритмах глибокого навчання.
У функції м’якої порогової обробки налаштування порогу повинно відповідати двом умовам: по-перше, поріг має бути додатним числом; по-друге, поріг не може перевищувати максимальне значення вхідного сигналу, інакше вихід повністю складатиметься з нулів.
Крім того, бажано, щоб поріг відповідав третій умові: кожен зразок повинен мати свій власний незалежний поріг, що базується на рівні шуму в цьому конкретному зразку.
Це пов’язано з тим, що вміст шуму в зразках часто різниться. Наприклад, у межах одного набору даних часто трапляється ситуація, коли зразок A містить менше шуму, а зразок B — більше. У такому випадку, при виконанні м’якої порогової обробки в алгоритмах шумозаглушення, для зразка A слід використовувати менший поріг, а для зразка B — більший. У глибоких нейронних мережах, хоча ці ознаки та пороги втрачають чіткий фізичний зміст, базова логіка залишається незмінною. Тобто, кожен зразок повинен мати власний адаптивний поріг.
3. Механізм уваги (Attention Mechanism)
Механізм уваги в галузі комп’ютерного зору зрозуміти досить легко. Зорова система тварин здатна швидко сканувати всю зону огляду, виявляти цільовий об’єкт і фокусувати на ньому увагу для отримання більшої кількості деталей, одночасно пригнічуючи нерелевантну інформацію. Детальніше про це можна дізнатися з літератури, присвяченої механізмам уваги.
Squeeze-and-Excitation Network (SENet) — це відносно новий метод глибокого навчання, що використовує механізми уваги. Вклад різних каналів ознак (feature channels) у виконання задачі класифікації часто варіюється від зразка до зразка. SENet використовує невелику підмережу для отримання набору ваг, а потім множить ці ваги на ознаки відповідних каналів, щоб скоригувати їх величину. Цей процес можна розглядати як застосування різного рівня “уваги” до різних каналів ознак.
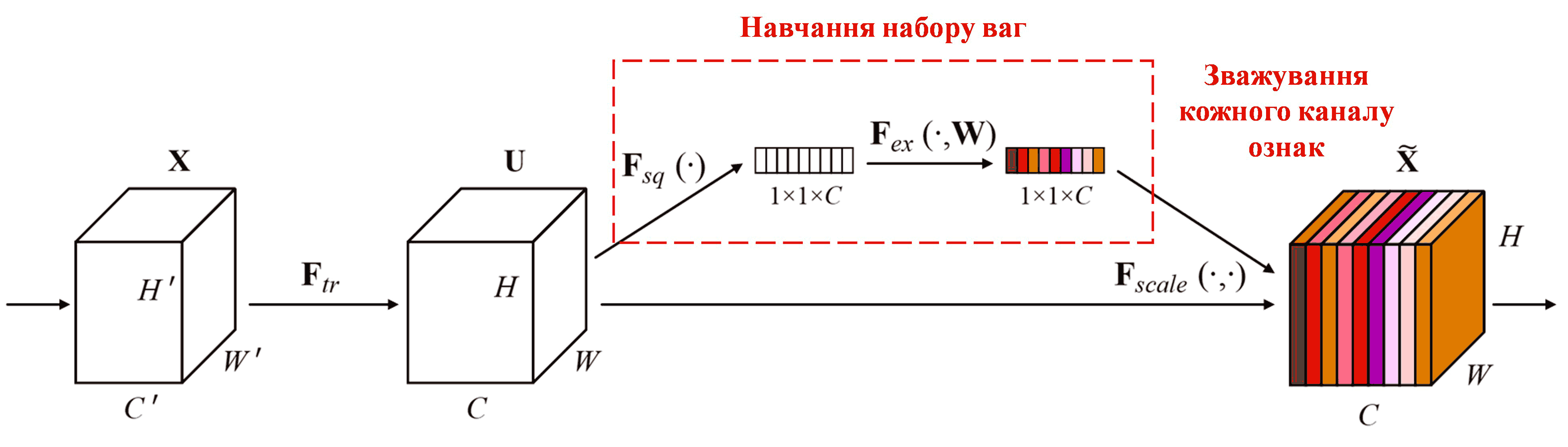
При такому підході кожен зразок отримує свій власний незалежний набір ваг. Іншими словами, для будь-яких двох зразків ваги будуть різними. У SENet шлях отримання ваг виглядає так: “Глобальний пулінг (Global Pooling) → Повнозв’язний шар (FC layer) → Функція ReLU → Повнозв’язний шар → Функція Sigmoid”.
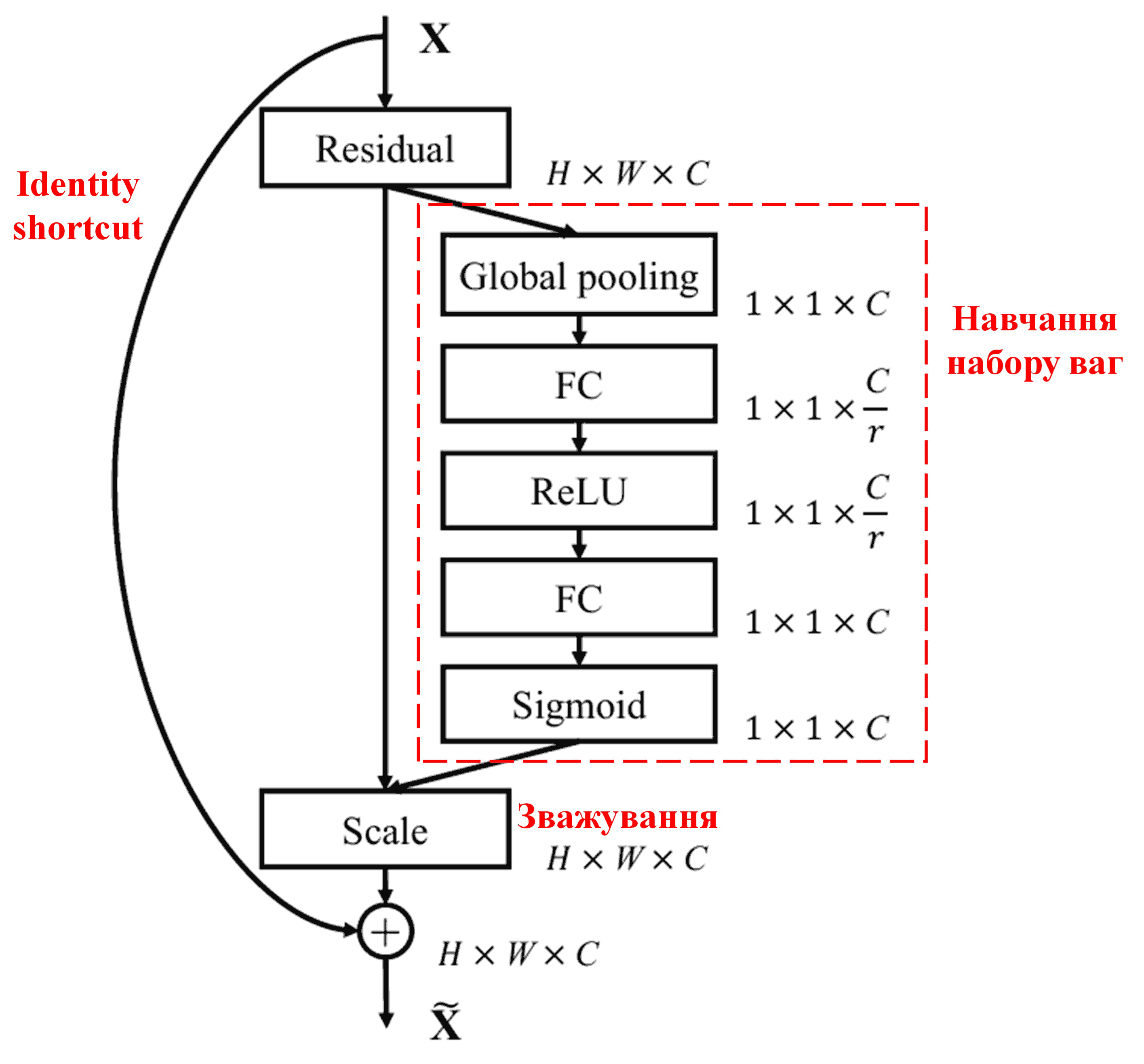
4. М’яка порогова обробка з механізмом глибокої уваги
Мережа DRSN запозичує структуру вищезгаданої підмережі SENet для реалізації м’якої порогової обробки під керуванням механізму глибокої уваги. Через спеціальну підмережу (позначену червоною рамкою на схемах архітектури) можна навчитися генерувати набір порогів для застосування м’якої порогової обробки до кожного каналу ознак.
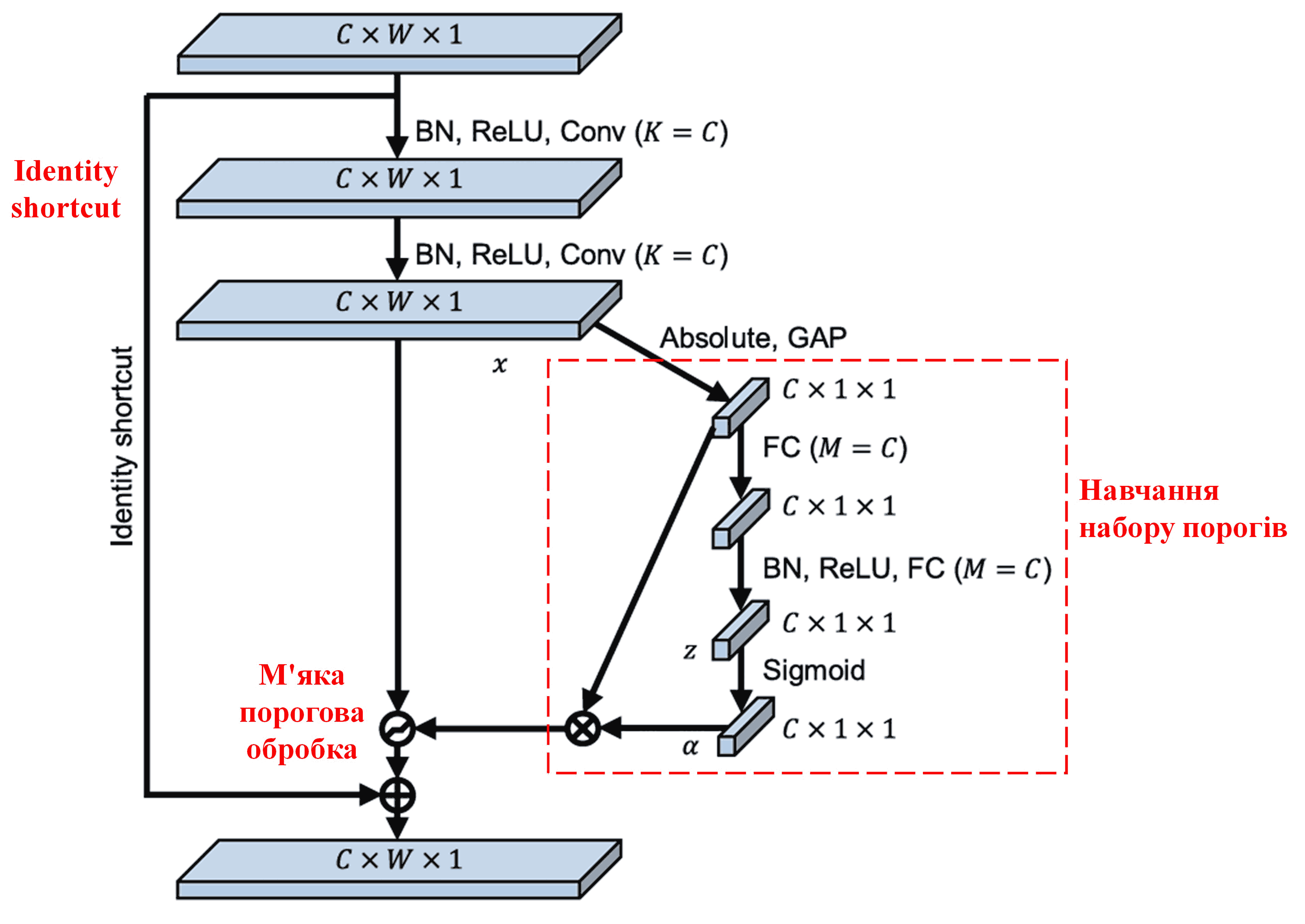
У цій підмережі спочатку обчислюються абсолютні значення всіх ознак вхідної карти ознак. Потім, через глобальний пулінг усреднення (global average pooling), отримується одна усереднена ознака, яку ми позначимо як A. Паралельно карта ознак після глобального пулінгу подається в невелику повнозв’язну мережу. Ця повнозв’язна мережа використовує функцію Sigmoid як останній шар, щоб нормалізувати вихідне значення в діапазоні від 0 до 1, отримуючи коефіцієнт, який ми позначимо як α. Остаточний поріг можна виразити як α × A. Таким чином, поріг — це число від 0 до 1, помножене на середнє значення абсолютних величин карти ознак. Такий метод гарантує, що поріг буде не тільки додатним, але й не надто великим.
Більше того, різні зразки отримують різні пороги. Тому, певною мірою, це можна розглядати як спеціальний механізм уваги: мережа помічає ознаки, не пов’язані з поточним завданням, перетворює їх за допомогою згорткових шарів у значення, близькі до нуля, і через м’яку порогову обробку остаточно обнуляє їх. Або ж навпаки: помічає важливі ознаки, перетворює їх у значення, далекі від нуля, і зберігає їх.
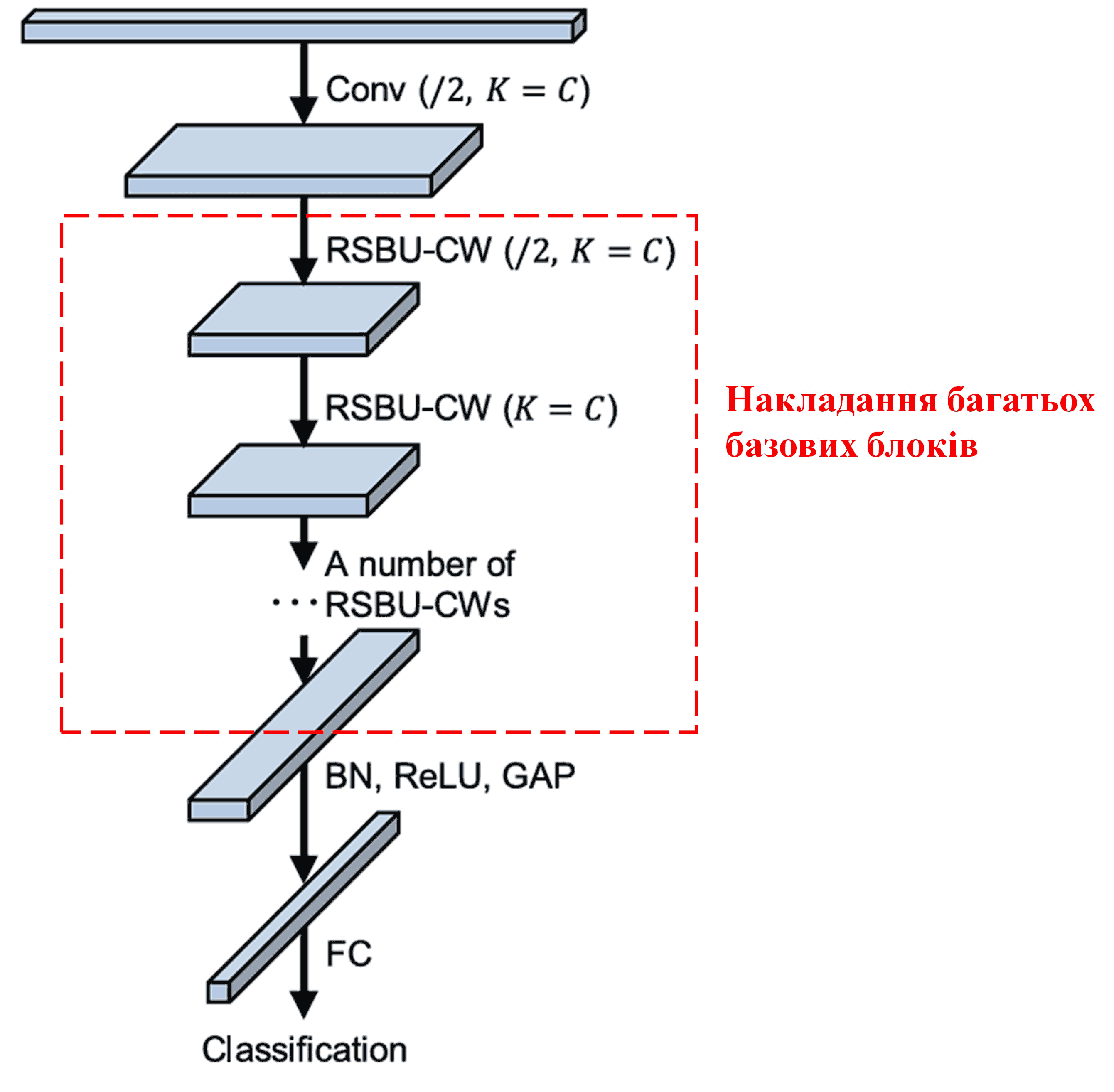
Зрештою, шляхом накладання (stacking) певної кількості базових блоків, а також шарів згортки, пакетної нормалізації (Batch Normalization), функцій активації, глобального пулінгу та повнозв’язних вихідних шарів, будується повна архітектура DRSN.
5. Універсальність
Фактично, DRSN — це універсальний метод навчання ознак (feature learning). Це пояснюється тим, що в багатьох задачах навчання ознак зразки тією чи іншою мірою містять шум та нерелевантну інформацію. Цей шум може впливати на ефективність навчання. Наприклад:
При класифікації зображень, якщо картинка містить багато сторонніх об’єктів, їх можна розглядати як “шум”. DRSN може використовувати механізм уваги, щоб помітити цей “шум”, а потім застосувати м’яку порогову обробку, щоб обнулити ознаки, що відповідають цьому “шуму”, тим самим підвищуючи точність класифікації зображень.
У розпізнаванні мови, особливо в шумному середовищі (наприклад, розмова на вулиці або в заводському цеху), DRSN може підвищити точність розпізнавання або, як мінімум, запропонувати перспективний підхід для покращення результатів у таких умовах.
Література
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Вплив у науковій спільноті
Кількість цитувань цієї статті в Google Scholar перевищила 1400 разів.
За неповними статистичними даними, мережі DRSN були використані або вдосконалені в більш ніж 1000 наукових публікаціях у таких галузях, як механічна інженерія, енергетика, комп’ютерний зір, медицина, обробка мови, аналіз тексту, радіолокація, дистанційне зондування та багатьох інших.