تُعد Deep Residual Shrinkage Network (التي يمكن ترجمتها إلى “شبكة الانكماش المتبقية العميقة”) نسخة مُحسنة من Deep Residual Network (أو ما يُعرف بـ ResNet). وهي في الجوهر عبارة عن دمج بين ثلاثة عناصر: Deep Residual Network، وآليات الانتباه (Attention Mechanisms)، ودوال العتبة الناعمة (Soft Thresholding).
إلى حد معين، يمكن فهم مبدأ عمل Deep Residual Shrinkage Network كالتالي: تقوم الشبكة باستخدام Attention Mechanism لملاحظة الميزات (Features) غير المهمة، ثم تستخدم Soft Thresholding لتحويل قيم هذه الميزات إلى صفر؛ وبالمقابل، تلاحظ الميزات المهمة وتبقي عليها. هذه العملية تعزز قدرة الشبكة العصبية العميقة (Deep Neural Network) على استخراج الميزات المفيدة من الإشارات التي تحتوي على ضجيج (Noise).
1. دافع البحث (Research Motivation)
أولاً، عند تصنيف العينات (Samples)، من المحتم وجود بعض الضجيج (Noise)، مثل Gaussian Noise، و Pink Noise، و Laplacian Noise وغيرها. وبمفهوم أوسع، غالباً ما تحتوي العينات على معلومات لا علاقة لها بمهمة التصنيف الحالية، ويمكن اعتبار هذه المعلومات أيضاً بمثابة “ضجيج”. هذا الضجيج قد يؤثر سلباً على دقة التصنيف. (تُعد Soft Thresholding خطوة أساسية في العديد من خوارزميات إزالة الضجيج من الإشارات أو ما يسمى Signal Denoising).
على سبيل المثال، عند التحدث بجانب الطريق، قد يختلط صوت المحادثة بأصوات أبواق السيارات وعجلات المركبات. عند إجراء “التعرف على الكلام” (Speech Recognition) على هذه الإشارات الصوتية، ستتأثر النتيجة حتماً بهذه الأصوات الدخيلة. من منظور Deep Learning، يجب حذف الميزات (Features) التي تمثل أصوات الأبواق والعجلات داخل الشبكة العصبية، لتجنب تأثيرها على دقة التعرف على الكلام.
ثانياً، حتى داخل مجموعة البيانات (Dataset) الواحدة، غالباً ما تختلف كمية الضجيج من عينة إلى أخرى. (هذا يتشابه مع Attention Mechanism؛ فإذا أخذنا مجموعة صور كمثال، قد يختلف موقع “الجسم المستهدف” من صورة لأخرى؛ وهنا تقوم آلية الانتباه بالتركيز على الموقع المحدد للجسم في كل صورة على حدة).
لنفترض مثلاً أننا ندرب مُصنِّفاً للقطط والكلاب. بالنسبة لـ 5 صور تحمل علامة “كلب”: الصورة الأولى قد تحتوي على كلب وفأر، الثانية كلب وإوزة، الثالثة كلب ودجاجة، الرابعة كلب وحمار، والخامسة كلب وبطة. عند تدريب المُصنِّف، سنتعرض حتماً لتشويش من الكائنات غير ذات الصلة (الفأر، الإوزة، الدجاجة، الحمار، البطة)، مما يقلل من دقة التصنيف. إذا تمكنا من ملاحظة هذه الكائنات الدخيلة وحذف الميزات (Features) الخاصة بها، فمن المحتمل أن نرفع دقة تصنيف القطط والكلاب.
2. العتبة الناعمة (Soft Thresholding)
تُعتبر Soft Thresholding خطوة جوهرية في العديد من خوارزميات Signal Denoising. فهي تقوم بحذف الميزات التي تكون قيمتها المطلقة أقل من عتبة (Threshold) معينة، وتقوم بـ “تقليص” (Shrink) الميزات التي تكون قيمتها المطلقة أكبر من هذه العتبة باتجاه الصفر. يمكن التعبير عنها بالمعادلة التالية:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]أما مُشتقة دالة Soft Thresholding بالنسبة للمُدخل فهي:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]كما نلاحظ أعلاه، فإن مشتقة Soft Thresholding تكون إما 1 أو 0. هذه الخاصية مماثلة لدالة التفعيل ReLU. لذلك، فإن Soft Thresholding تساعد أيضاً في تقليل مخاطر تعرض خوارزميات Deep Learning لمشاكل تلاشي التدرج (Gradient Vanishing) أو انفجار التدرج (Gradient Exploding).
في دالة Soft Thresholding، يجب أن يحقق إعداد العتبة (Threshold) شرطين: الأول، أن تكون العتبة رقماً موجباً؛ والثاني، ألا تكون العتبة أكبر من القيمة العظمى للإشارة المُدخلة، وإلا ستكون المخرجات جميعها أصفاراً.
بالإضافة إلى ذلك، يُفضل أن تحقق العتبة شرطاً ثالثاً: يجب أن يكون لكل عينة عتبة مستقلة خاصة بها بناءً على كمية الضجيج التي تحتويها.
السبب في ذلك هو أن محتوى الضجيج يختلف غالباً بين العينات. فمثلاً، من الشائع في نفس مجموعة البيانات أن تحتوي العينة A على ضجيج قليل، بينما تحتوي العينة B على ضجيج كثير. في هذه الحالة، عند تطبيق Soft Thresholding داخل خوارزمية إزالة الضجيج، يجب أن تستخدم العينة A عتبة صغيرة، بينما تستخدم العينة B عتبة كبيرة. في الشبكات العصبية العميقة، ورغم أن هذه الميزات والعتبات تفقد معانيها الفيزيائية الملموسة، إلا أن المنطق الأساسي يظل كما هو. بمعنى آخر، يجب أن تمتلك كل عينة عتبة مستقلة خاصة بها تتناسب مع محتواها من الضجيج.
3. آلية الانتباه (Attention Mechanism)
من السهل فهم Attention Mechanism في مجال الرؤية الحاسوبية (Computer Vision). فالنظام البصري لدى الحيوانات يمكنه مسح كامل المنطقة بسرعة لاكتشاف الجسم المستهدف، ومن ثم تركيز الانتباه عليه لاستخراج تفاصيل أكثر، مع تجاهل المعلومات غير ذات الصلة. لمزيد من التفاصيل، يرجى الرجوع إلى الأبحاث المتعلقة بـ Attention Mechanism.
تُعد شبكة Squeeze-and-Excitation Network (SENet) طريقة حديثة نسبياً في Deep Learning تعتمد على آليات الانتباه. في العينات المختلفة، تختلف مساهمة “قنوات الميزات” (Feature Channels) المختلفة في مهمة التصنيف. تستخدم SENet شبكة فرعية صغيرة للحصول على مجموعة من الأوزان (Weights)، ثم تضرب هذه الأوزان في ميزات القنوات المختلفة لضبط حجم الميزات في كل قناة. يمكن اعتبار هذه العملية بمثابة تطبيق درجات متفاوتة من “الانتباه” على قنوات الميزات المختلفة.
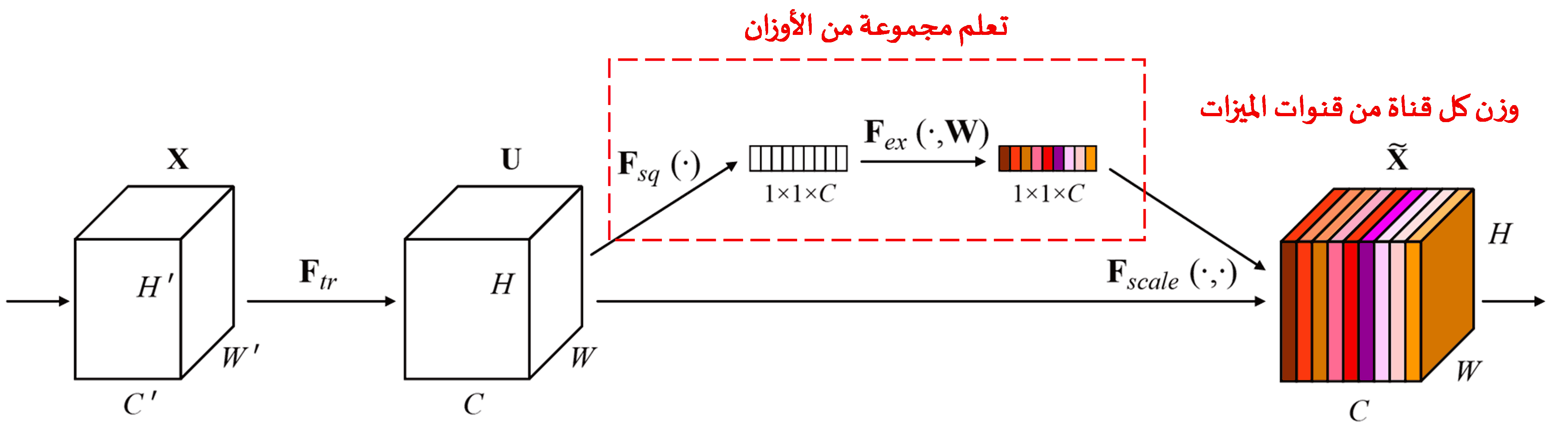
بهذه الطريقة، تمتلك كل عينة مجموعة مستقلة من الأوزان. بعبارة أخرى، الأوزان الخاصة بأي عينتين تكون مختلفة. في SENet، المسار المحدد للحصول على الأوزان هو: “Global Pooling ← Fully Connected Layer ← ReLU ← Fully Connected Layer ← Sigmoid”.
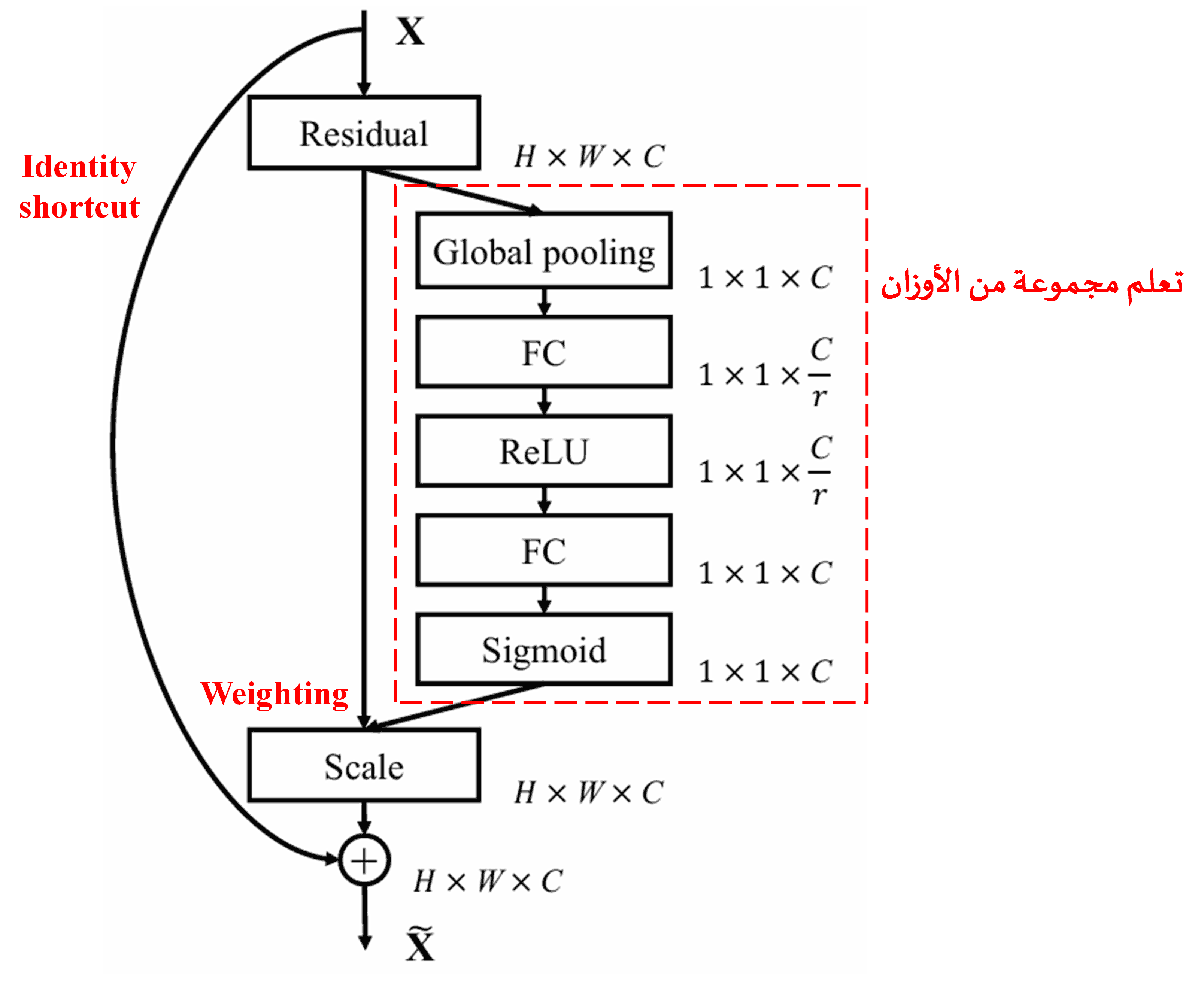
4. تطبيق Soft Thresholding تحت مظلة Deep Attention Mechanism
استوحت Deep Residual Shrinkage Network هيكلية الشبكة الفرعية من SENet المذكورة أعلاه، لتحقيق Soft Thresholding ضمن آلية انتباه عميقة. من خلال الشبكة الفرعية (الموضحة داخل الإطار الأحمر في المخططات الهيكلية)، يمكن تعلم مجموعة من العتبات لتطبيق Soft Thresholding على كل قناة من قنوات الميزات.
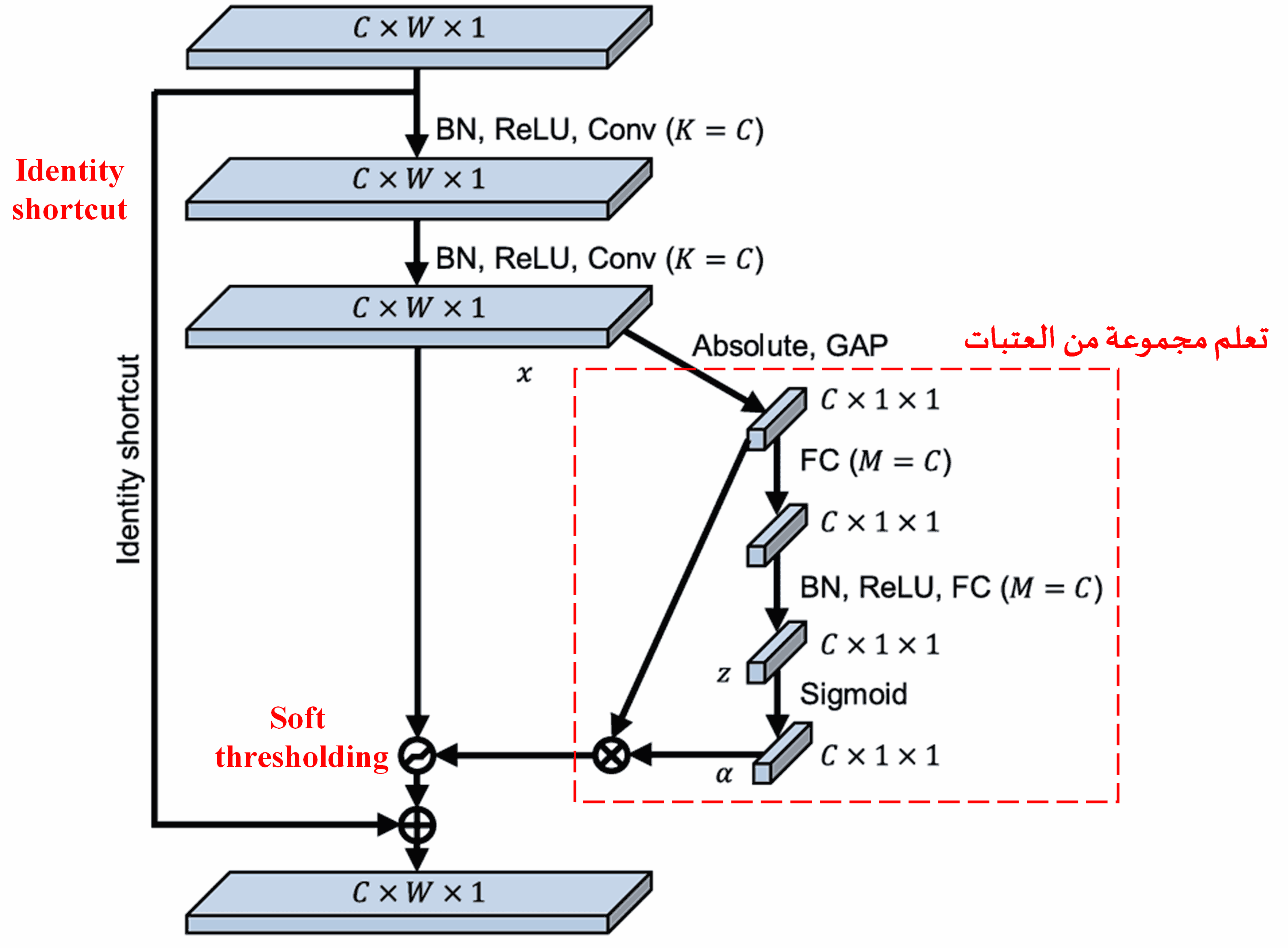
في هذه الشبكة الفرعية، يتم أولاً حساب القيم المطلقة لجميع الميزات في خريطة الميزات (Feature Map). ثم، من خلال Global Average Pooling وحساب المتوسط، نحصل على ميزة نرمز لها بـ A. في مسار آخر، يتم إدخال خريطة الميزات (بعد عملية الـ Global Average Pooling) إلى شبكة صغيرة متصلة بالكامل (Fully Connected Network). تنتهي هذه الشبكة بدالة Sigmoid كآخر طبقة لضبط المخرجات بين 0 و 1، مما يعطينا معاملاً نرمز له بـ α. يمكن التعبير عن العتبة النهائية بـ α × A. وبالتالي، العتبة هي عبارة عن: (رقم بين 0 و 1) × (متوسط القيم المطلقة لخريطة الميزات). تضمن هذه الطريقة أن تكون العتبة موجبة، وألا تكون كبيرة جداً في نفس الوقت.
علاوة على ذلك، ستحصل العينات المختلفة على عتبات مختلفة. لذلك، إلى حد معين، يمكن فهم هذا كنوع خاص من Attention Mechanism: حيث تلاحظ الشبكة الميزات غير المتعلقة بالمهمة الحالية، وتقوم بتحويلها عبر طبقتين من Convolutional Layers إلى قيم قريبة من الصفر، ثم تستخدم Soft Thresholding لجعلها صفراً تماماً؛ أو تلاحظ الميزات المتعلقة بالمهمة، وتحولها إلى قيم بعيدة عن الصفر، لتقوم بالاحتفاظ بها.
أخيراً، من خلال تكديس عدد معين من الوحدات الأساسية بالإضافة إلى Convolutional Layers، و Batch Normalization، و Activation Functions، و Global Average Pooling، وطبقة الإخراج Fully Connected Layer، نحصل على Deep Residual Shrinkage Network الكاملة.
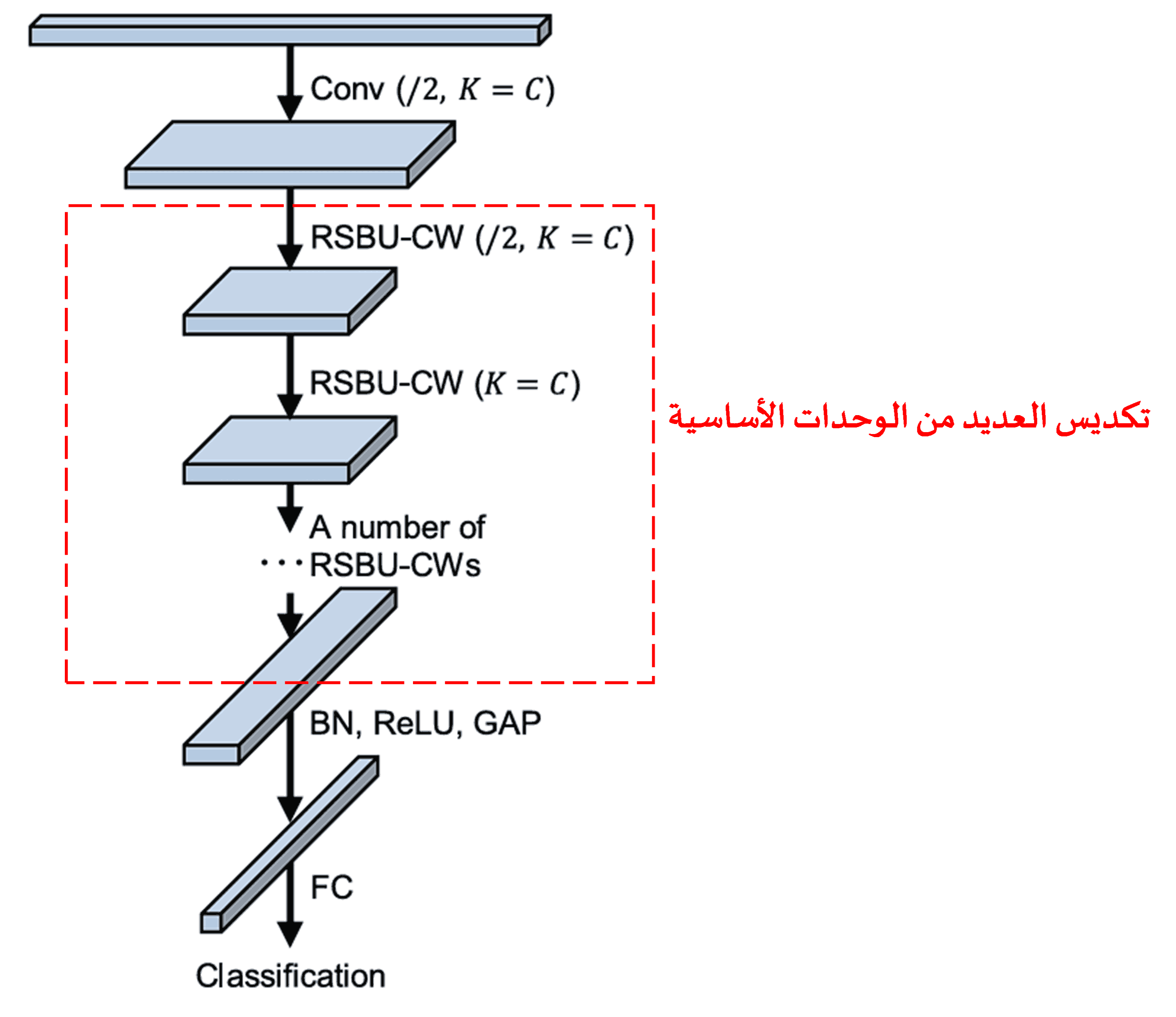
5. قابلية التعميم (Generalization Capability)
في الواقع، تُعد Deep Residual Shrinkage Network طريقة عامة لتعلم الميزات (Feature Learning). وذلك لأن العينات في العديد من مهام تعلم الميزات تحتوي، بدرجة أو بأخرى، على بعض الضجيج والمعلومات غير ذات الصلة. هذا الضجيج والمعلومات غير المهمة قد تؤثر على جودة التعلم. على سبيل المثال:
في تصنيف الصور (Image Classification)، إذا كانت الصورة تحتوي على العديد من الأشياء الأخرى في نفس الوقت، يمكن اعتبار هذه الأشياء “ضجيجاً”. قد تتمكن Deep Residual Shrinkage Network، بمساعدة Attention Mechanism، من ملاحظة هذا “الضجيج”، ثم استخدام Soft Thresholding لجعل الميزات المقابلة لهذا الضجيج صفراً، مما قد يرفع من دقة تصنيف الصور.
في التعرف على الكلام (Speech Recognition)، خاصة في البيئات الصاخبة مثل المحادثات بجانب الطريق أو داخل ورش المصانع، قد تتمكن Deep Residual Shrinkage Network من تحسين دقة التعرف على الكلام، أو على الأقل تقديم منهجية قادرة على تحسين الدقة.
المراجع (Reference)
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
التأثير الأكاديمي (Academic Impact)
تجاوز عدد الاستشهادات بهذه الورقة البحثية في “Google Scholar” أكثر من 1400 استشهاد.
وفقاً لإحصائيات غير كاملة، تم استخدام Deep Residual Shrinkage Networks (أو تحسينها وتطبيقها) في أكثر من 1000 بحث منشور في مجالات متعددة تشمل الهندسة الميكانيكية، والطاقة الكهربائية، والرؤية الحاسوبية، والمجال الطبي، ومعالجة الصوت والنصوص، والرادار، والاستشعار عن بعد.