Deep Residual Shrinkage Network ni toleo lililoboreshwa la Deep Residual Network (ResNet). Kiuhalisia, ni muunganiko wa Deep Residual Network, attention mechanisms, na soft thresholding functions.
Kwa kiasi fulani, kanuni ya utendaji ya Deep Residual Shrinkage Network inaweza kueleweka hivi: inatumia attention mechanisms kugundua features zisizo muhimu, na kupitia soft thresholding functions inazifanya kuwa sifuri; au tuseme, kupitia attention mechanisms inagundua features muhimu na kuzihifadhi. Mchakato huu unaimarisha uwezo wa deep neural network kuchakata features muhimu kutoka kwenye signals zenye noise.
1. Motisha ya Utafiti (Research Motivation)
Kwanza, wakati wa kuainisha (classifying) sampuli, ni jambo lisiloepukika kuwa sampuli zitakuwa na noise fulani, kama vile Gaussian noise, pink noise, na Laplacian noise. Kwa mapana zaidi, sampuli zinaweza kuwa na taarifa ambazo hazihusiani na jukumu la sasa la classification, na taarifa hizi pia zinaweza kueleweka kama noise. Noise hizi zinaweza kuathiri vibaya matokeo ya classification. (Soft thresholding ni hatua muhimu katika algoriti nyingi za signal denoising).
Kwa mfano, wakati wa maongezi kando ya barabara, sauti za maongezi zinaweza kuchanganyika na noise za honi za magari, sauti za magurudumu, n.k. Tunapofanya speech recognition kwenye signals hizi, matokeo yake bila shaka yataathiriwa na sauti hizo za honi na magurudumu. Kwa mtazamo wa Deep Learning, features zinazotokana na sauti hizi za honi na magurudumu zinapaswa kufutwa ndani ya deep neural network ili kuzuia zisiathiri ufanisi wa speech recognition.
Pili, hata katika mkusanyiko mmoja wa sampuli (dataset), kiasi cha noise mara nyingi hutofautiana kutoka sampuli moja hadi nyingine. (Hii inafanana na attention mechanism; kwa mfano katika dataset ya picha, eneo la kitu kinacholengwa linaweza kuwa tofauti katika kila picha; attention mechanism inaweza kulenga eneo mahususi la kitu hicho kwa kila picha).
Kwa mfano, wakati wa kufunza classifier ya paka na mbwa, chukulia picha 5 zilizo na lebo ya “mbwa”. Picha ya 1 inaweza kuwa na mbwa na panya, picha ya 2 mbwa na bata, picha ya 3 mbwa na kuku, picha ya 4 mbwa na punda, na picha ya 5 mbwa na bata-maji. Tunapofunza classifier ya paka na mbwa, bila shaka tutapata usumbufu kutoka kwa vitu visivyohusika kama panya, bata, kuku, punda, na bata-maji, jambo linalosababisha kushuka kwa usahihi (accuracy). Kama tukiweza kugundua vitu hivi visivyohusika—panya, bata, kuku, punda, na bata-maji—na kufuta features zake, inawezekana kuongeza usahihi wa classifier ya paka na mbwa.
2. Soft Thresholding
Soft thresholding ni hatua ya msingi katika algoriti nyingi za signal denoising, ambapo inafuta features ambazo absolute value yake ni ndogo kuliko threshold fulani, na kusogeza features ambazo absolute value yake ni kubwa kuliko threshold kuelekea kwenye sifuri. Inaweza kutekelezwa kwa kutumia fomula ifuatayo:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Derivative ya output ya soft thresholding ukilinganisha na input ni:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Kama inavyoonekana hapo juu, derivative ya soft thresholding ni 1 au 0. Sifa hii ni sawa na ile ya ReLU activation function. Kwa hivyo, soft thresholding inaweza pia kupunguza hatari ya Deep Learning algorithms kukumbana na matatizo ya gradient vanishing na gradient exploding.
Katika soft thresholding function, mpangilio wa threshold lazima ukidhi masharti mawili: Kwanza, threshold lazima iwe namba chanya (positive number); Pili, threshold haiwezi kuwa kubwa kuliko thamani ya juu (maximum value) ya signal inayoingia, vinginevyo output yote itakuwa sifuri.
Vilevile, ni vyema threshold ikidhi sharti la tatu: kila sampuli inapaswa kuwa na threshold yake inayojitegemea kulingana na kiasi cha noise ilichonacho.
Hii ni kwa sababu kiasi cha noise mara nyingi hutofautiana kati ya sampuli. Kwa mfano, ni kawaida katika dataset moja kwa Sampuli A kuwa na noise kidogo wakati Sampuli B ina noise nyingi. Katika hali hii, wakati wa kufanya soft thresholding kwenye algoriti ya denoising, Sampuli A inapaswa kutumia threshold ndogo, wakati Sampuli B inapaswa kutumia threshold kubwa. Katika deep neural networks, ingawa features na thresholds hizi zinapoteza maana halisi ya kifizikia, mantiki ya msingi inabaki ileile. Yaani, kila sampuli inapaswa kuwa na threshold yake inayojitegemea kulingana na kiasi chake cha noise.
3. Attention Mechanism
Attention mechanism inaeleweka kwa urahisi katika nyanja ya computer vision. Mfumo wa kuona wa wanyama unaweza kuchanganua eneo lote kwa haraka na kugundua kitu kinacholengwa, na kisha kuelekeza umakini (attention) kwenye kitu hicho ili kupata maelezo zaidi, huku ukipuuza taarifa zisizohusika. Kwa maelezo zaidi, tafadhali rejelea machapisho yanayohusu attention mechanisms.
Squeeze-and-Excitation Network (SENet) ni njia ya Deep Learning ya hivi karibuni inayotumia attention mechanism. Katika sampuli tofauti, mchango wa feature channels tofauti katika kazi ya classification mara nyingi hutofautiana. SENet inatumia sub-network ndogo kupata seti ya weights, na kisha kuzidisha weights hizi na features za channels husika ili kurekebisha ukubwa wa features katika kila channel. Mchakato huu unaweza kuchukuliwa kama kuweka viwango tofauti vya attention kwenye feature channels tofauti.
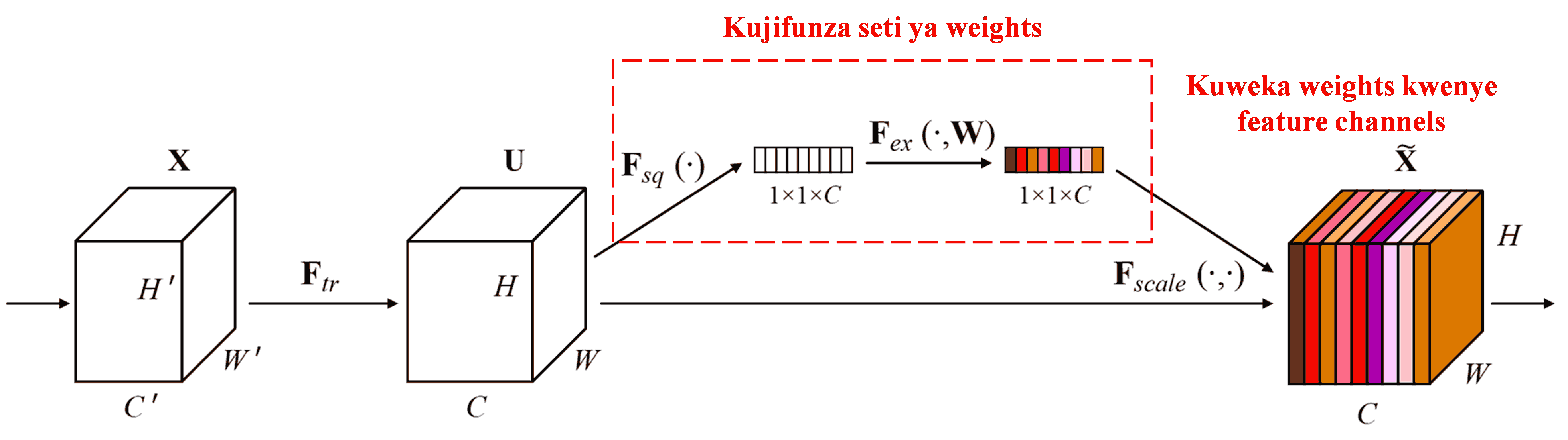
Kwa njia hii, kila sampuli inakuwa na seti yake ya weights inayojitegemea. Kwa maneno mengine, weights za sampuli mbili zozote ni tofauti. Katika SENet, njia mahususi ya kupata weights ni “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”.
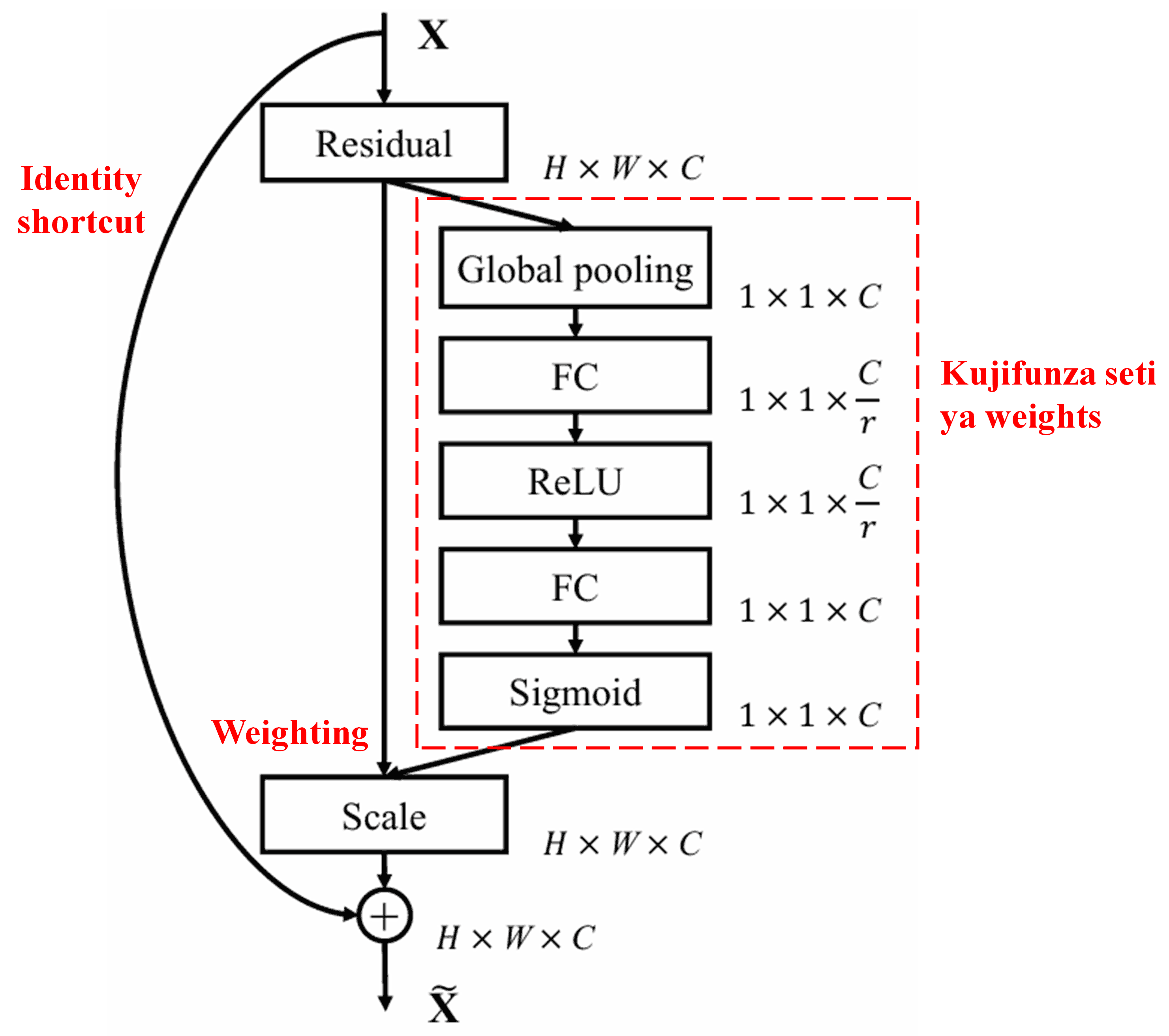
4. Soft Thresholding chini ya Deep Attention Mechanism
Deep Residual Shrinkage Network inaiga muundo wa sub-network wa SENet uliotajwa hapo juu, ili kutekeleza soft thresholding chini ya deep attention mechanism. Kupitia sub-network iliyo ndani ya sanduku jekundu, inawezekana kujifunza seti ya thresholds ili kufanya soft thresholding kwenye kila feature channel.
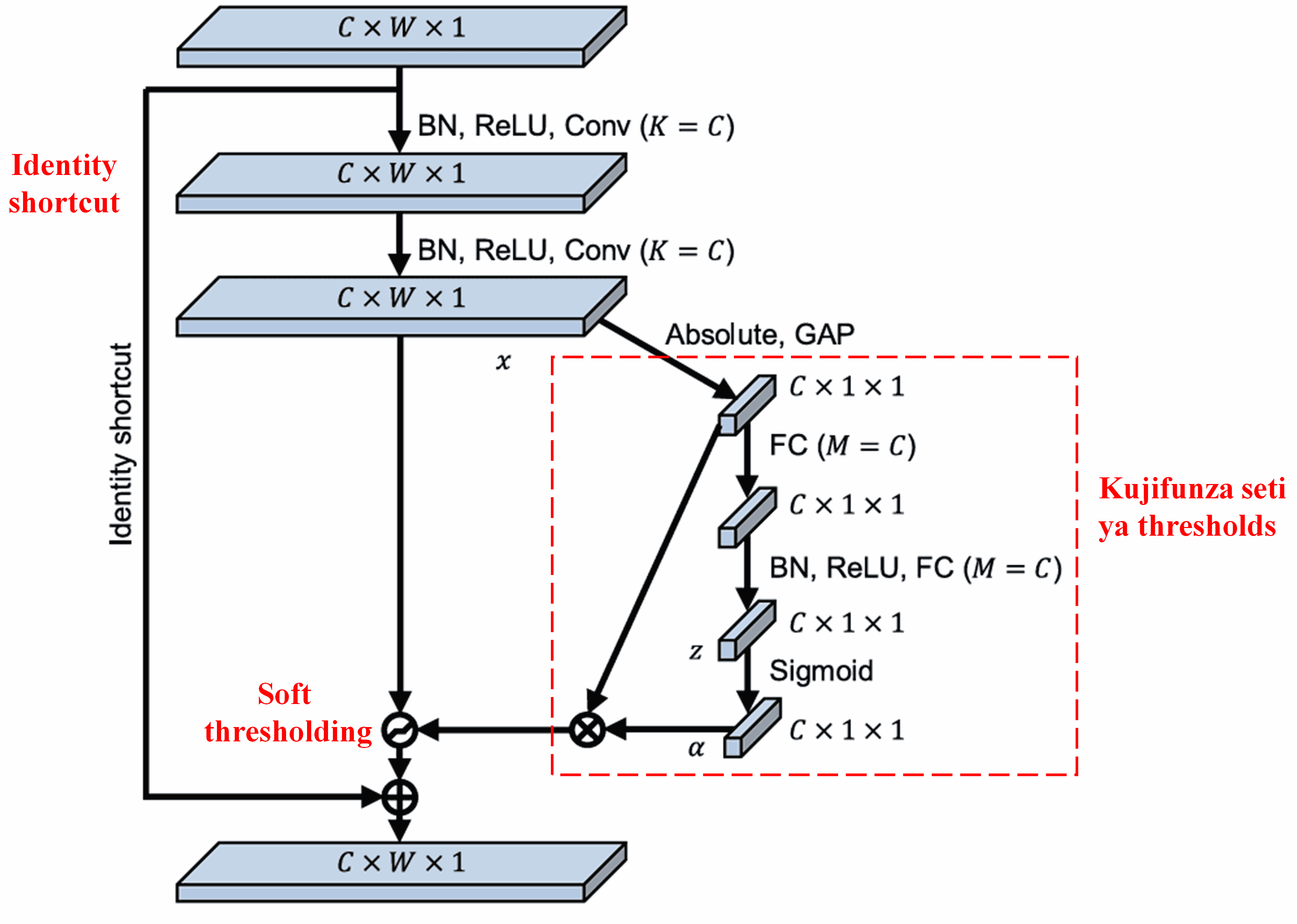
Katika sub-network hii, kwanza absolute values za features zote katika input feature map zinatafutwa. Kisha, kupitia global average pooling na wastani (averaging), tunapata feature moja, tunayoita A. Katika njia nyingine, feature map baada ya kupita kwenye global average pooling inaingizwa kwenye fully connected network ndogo. Network hii inatumia Sigmoid function kama safu ya mwisho (last layer) ili kuweka output kati ya 0 na 1, na hivyo kupata kizidisho (coefficient), tunachokiita α. Threshold ya mwisho inaweza kuandikwa kama α×A. Hivyo, threshold ni zao la namba kati ya 0 na 1 na wastani wa absolute values za feature map. Njia hii inahakikisha kuwa threshold ni chanya na pia si kubwa kupita kiasi.
Zaidi ya hayo, sampuli tofauti zinakuwa na thresholds tofauti. Hivyo, kwa kiasi fulani, hii inaweza kueleweka kama aina maalum ya attention mechanism: inatambua features zisizohusiana na kazi ya sasa, inabadilisha features hizi kuwa karibu na 0 kupitia convolutional layers mbili, na kuzifanya kuwa sifuri kupitia soft thresholding; au tuseme, inatambua features zinazohusiana na kazi ya sasa, inabadilisha features hizi kuwa mbali na 0 kupitia convolutional layers mbili, na kuzihifadhi.
Mwishowe, kwa kupanga idadi fulani ya basic modules pamoja na convolutional layers, batch normalization, activation functions, global average pooling, na fully connected output layers, tunapata Deep Residual Shrinkage Network iliyokamilika.
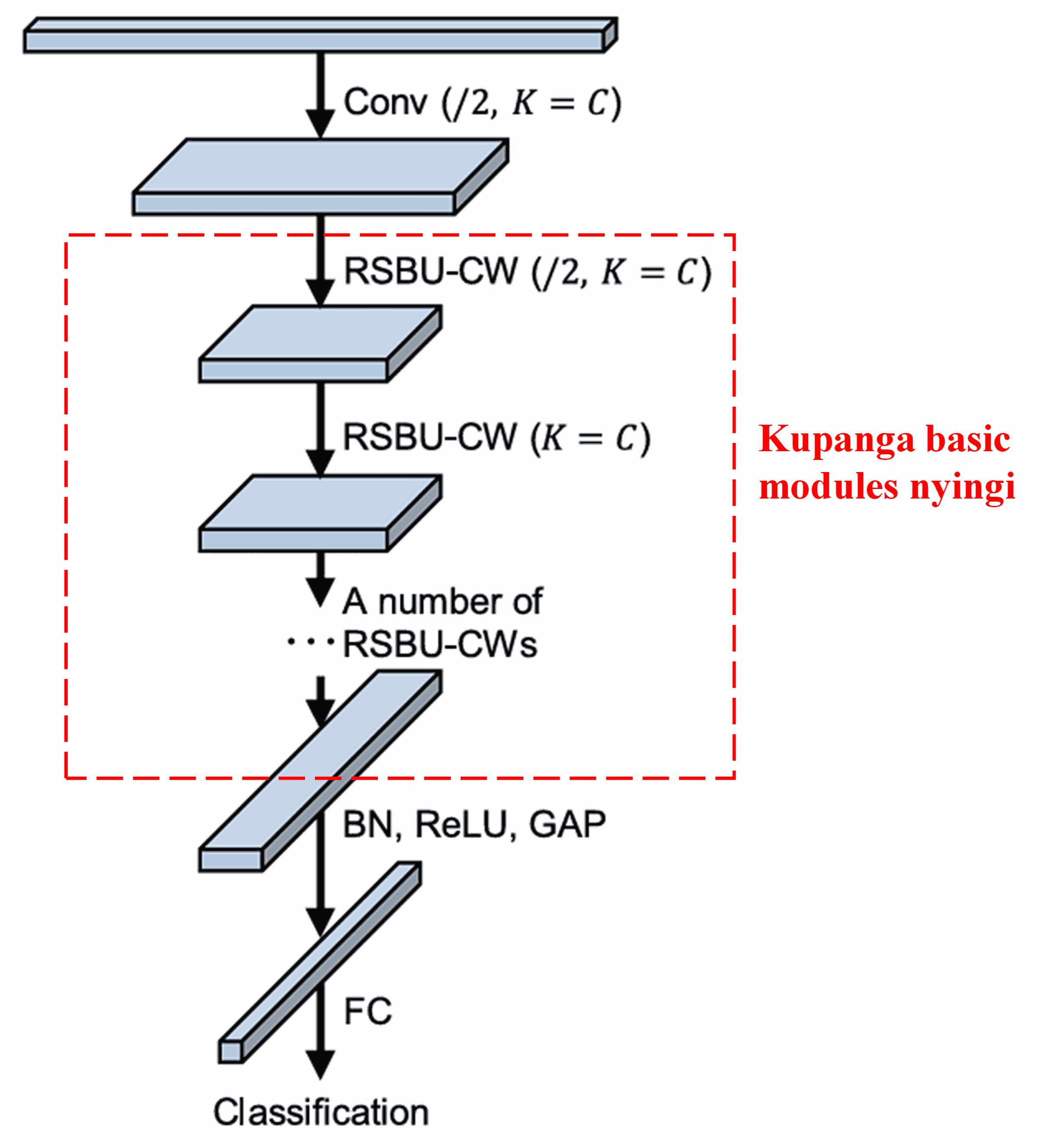
5. Uwezo wa Kijumla (Generalization Capability)
Deep Residual Shrinkage Network kiuhalisia ni njia ya jumla ya kujifunza features (feature learning method). Hii ni kwa sababu katika kazi nyingi za kujifunza features, sampuli mara nyingi huwa na kiasi fulani cha noise pamoja na taarifa zisizohusika. Noise na taarifa hizi zisizohusika zinaweza kuathiri ufanisi wa kujifunza features. Kwa mfano:
Katika image classification, ikiwa picha ina vitu vingine vingi kwa wakati mmoja, vitu hivi vinaweza kueleweka kama “noise”; Deep Residual Shrinkage Network inaweza kutumia attention mechanism kutambua “noise” hizi, na kisha kutumia soft thresholding kufanya features zinazolingana na “noise” hizi kuwa sifuri, jambo ambalo linaweza kuongeza usahihi wa image classification.
Katika speech recognition, hasa katika mazingira yenye kelele kama vile maongezi kando ya barabara au ndani ya karakana ya kiwanda, Deep Residual Shrinkage Network inaweza kuongeza usahihi wa speech recognition, au angalau kutoa mbinu inayoweza kuongeza usahihi huo.
Marejeleo (References)
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Ushawishi wa Kitaaluma (Academic Impact)
Makala hii imetajwa (cited) zaidi ya mara 1400 kwenye Google Scholar.
Kulingana na takwimu zisizo kamili, Deep Residual Shrinkage Network imetumika moja kwa moja au kuboreshwa katika machapisho zaidi ya 1000 katika nyanja mbalimbali, ikiwa ni pamoja na uhandisi wa mitambo (mechanical engineering), nishati ya umeme, computer vision, matibabu, uchakataji wa sauti (speech processing), maandishi (text), rada, na remote sensing.