Deep Residual Shrinkage Network (DRSN) është një variant i përmirësuar i Deep Residual Network (ResNet). Në thelb, ai është një integrim i ResNet, mekanizmave të vëmendjes (attention mechanisms) dhe funksioneve të Soft Thresholding.
Në njëfarë mase, parimi i punës së Deep Residual Shrinkage Network mund të kuptohet kështu: përmes mekanizmit të vëmendjes, ai evidenton tiparet e parëndësishme dhe përdor funksionin e Soft Thresholding për t’i bërë ato zero; ose anasjelltas, ai evidenton tiparet e rëndësishme dhe i ruan ato. Ky proces përforcon aftësinë e rrjetit neural të thellë (Deep Neural Network) për të nxjerrë tipare të dobishme nga sinjalet që përmbajnë zhurmë.
1. Motivimi i Kërkimit
Së pari, kur klasifikojmë mostrat, prania e zhurmës—si zhurma Gaussiane, zhurma rozë (pink noise), dhe zhurma e Laplasit—është e pashmangshme. Në sensin më të gjerë, mostrat shpesh përmbajnë informacion që nuk ka lidhje me detyrën aktuale të klasifikimit, gjë që gjithashtu mund të kuptohet si zhurmë. Kjo zhurmë mund të ndikojë negativisht në rezultatet e klasifikimit. (Soft Thresholding është një hap kyç në shumë algoritme për heqjen e zhurmës ose signal denoising).
Për shembull, gjatë një bisede në anë të rrugës, zëri mund të përzihet me zhurmën e borive të makinave dhe rrotave. Kur kryhet njohja e zërit (speech recognition) mbi këto sinjale, rezultatet pashmangshmërisht do të ndikohen nga këto tinguj të sfondit. Nga këndvështrimi i Deep Learning, tiparet (features) që korrespondojnë me boritë dhe rrotat duhet të eliminohen brenda rrjetit neural, për të shmangur ndikimin në njohjen e zërit.
Së dyti, edhe brenda të njëjtit grup të dhënash (dataset), sasia e zhurmës shpesh ndryshon nga njëra mostër te tjetra. (Kjo ka ngjashmëri me mekanizmat e vëmendjes; marrim si shembull një dataset imazhesh, vendndodhja e objektit të synuar mund të ndryshojë midis imazheve, dhe mekanizmi i vëmendjes fokusohet te vendndodhja specifike në secilin imazh).
Për shembull, kur trajnojmë një klasifikues mace-qen, le të marrim 5 imazhe me etiketën “qen”. Imazhi i parë mund të përmbajë një qen dhe një mi, i dyti një qen dhe një patë, i treti një qen dhe një pulë, i katërti një qen dhe një gomar, dhe i pesti një qen dhe një rosë. Gjatë trajnimit të klasifikuesit, ne pashmangshmërisht do të ndikohemi nga objektet e parëndësishme si miu, pata, pula, gomari dhe rosa, duke shkaktuar rënie të saktësisë së klasifikimit. Nëse arrijmë t’i vëmë re këto objekte të parëndësishme dhe të eliminojmë tiparet që u korrespondojnë atyre, atëherë mund të rrisim saktësinë e klasifikuesit mace-qen.
2. Soft Thresholding
Soft Thresholding është një hap thelbësor në shumë algoritme të heqjes së zhurmës (denoising). Ai eliminon tiparet vlera absolute e të cilave është më e vogël se një prag (threshold) i caktuar, dhe i “tkurr” (shrinks) drejt zeros tiparet që janë më të mëdha se ky prag. Kjo mund të realizohet përmes formulës së mëposhtme:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Derivati i rezultatit të Soft Thresholding në lidhje me hyrjen është:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Siç shihet më sipër, derivati i Soft Thresholding është ose 1 ose 0. Kjo veti është identike me atë të funksionit të aktivizimit ReLU. Prandaj, Soft Thresholding gjithashtu ndihmon në reduktimin e rrezikut që algoritmet e Deep Learning të hasin probleme si gradient vanishing (zhdukja e gradientit) apo gradient exploding (shpërthimi i gradientit).
Në funksionin e Soft Thresholding, vendosja e pragut (threshold) duhet të plotësojë dy kushte: së pari, pragu duhet të jetë një numër pozitiv; së dyti, pragu nuk mund të jetë më i madh se vlera maksimale e sinjalit hyrës, përndryshe rezultati do të jetë tërësisht zero.
Gjithashtu, është e preferueshme që pragu të plotësojë një kusht të tretë: secila mostër duhet të ketë pragun e saj të pavarur, bazuar në sasinë e zhurmës që përmban vetë mostra.
Kjo ndodh sepse sasia e zhurmës shpesh ndryshon midis mostrave. Për shembull, është e zakonshme që brenda të njëjtit dataset, Mostra A të ketë më pak zhurmë, ndërsa Mostra B të ketë më shumë zhurmë. Në këtë rast, kur aplikojmë Soft Thresholding në algoritmet e heqjes së zhurmës, Mostra A duhet të përdorë një prag më të vogël, ndërsa Mostra B duhet të përdorë një prag më të madh. Në rrjetet neurale të thella (Deep Neural Networks), edhe pse këto tipare dhe pragje humbasin kuptimin e tyre të qartë fizik, logjika bazë mbetet e njëjtë. Me fjalë të tjera, secila mostër duhet të ketë pragun e saj të pavarur, të përcaktuar nga përmbajtja specifike e zhurmës së saj.
3. Mekanizmi i Vëmendjes (Attention Mechanism)
Mekanizmat e vëmendjes janë relativisht të lehtë për t’u kuptuar në fushën e vizionit kompjuterik (Computer Vision). Sistemi vizual i kafshëve mund të skanojë me shpejtësi të gjithë zonën për të zbuluar objektin e synuar, dhe më pas të përqendrojë vëmendjen tek ai objekt për të nxjerrë më shumë detaje, duke injoruar informacionin e parëndësishëm. Për detaje, ju lutemi referojuni literaturës mbi mekanizmat e vëmendjes.
Squeeze-and-Excitation Network (SENet) është një metodë relativisht e re e Deep Learning që përdor mekanizmat e vëmendjes. Në mostra të ndryshme, kontributi i kanaleve të ndryshme të tipareve (feature channels) në detyrën e klasifikimit është shpesh i ndryshëm. SENet përdor një nën-rrjet (sub-network) të vogël për të përftuar një grup peshash (weights), dhe më pas i shumëzon këto pesha me tiparet e kanaleve përkatëse për të rregulluar madhësinë e tipareve në çdo kanal. Ky proces mund të konsiderohet si aplikim i niveleve të ndryshme të vëmendjes në kanale të ndryshme të tipareve.
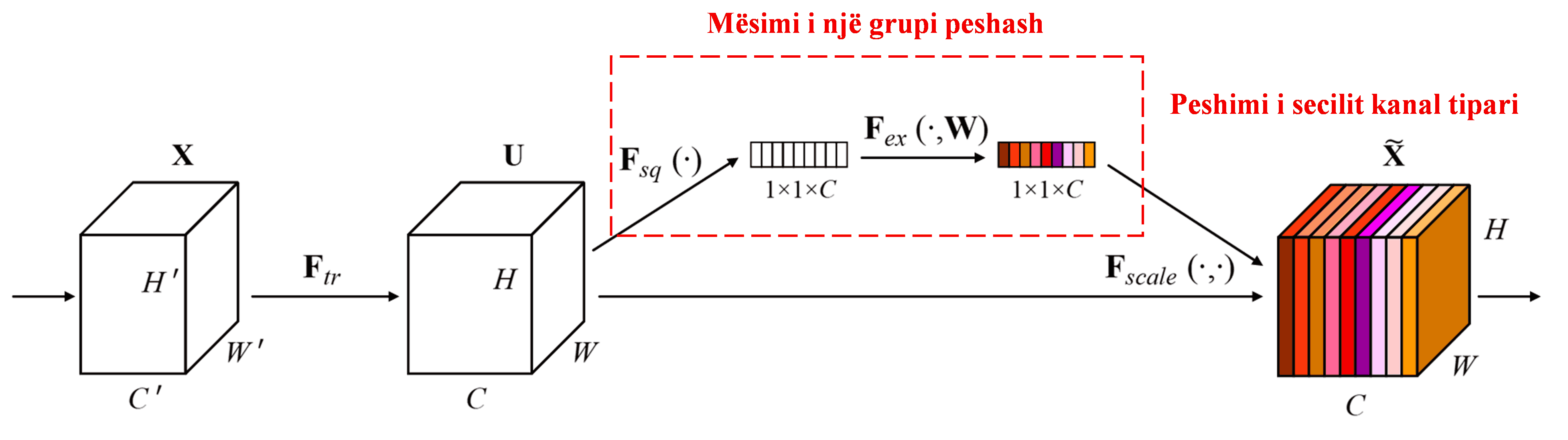
Në këtë mënyrë, çdo mostër ka grupin e saj të pavarur të peshave. Me fjalë të tjera, peshat për çdo dy mostra të çfarëdoshme janë të ndryshme. Në SENet, rruga specifike për marrjen e peshave është “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”.
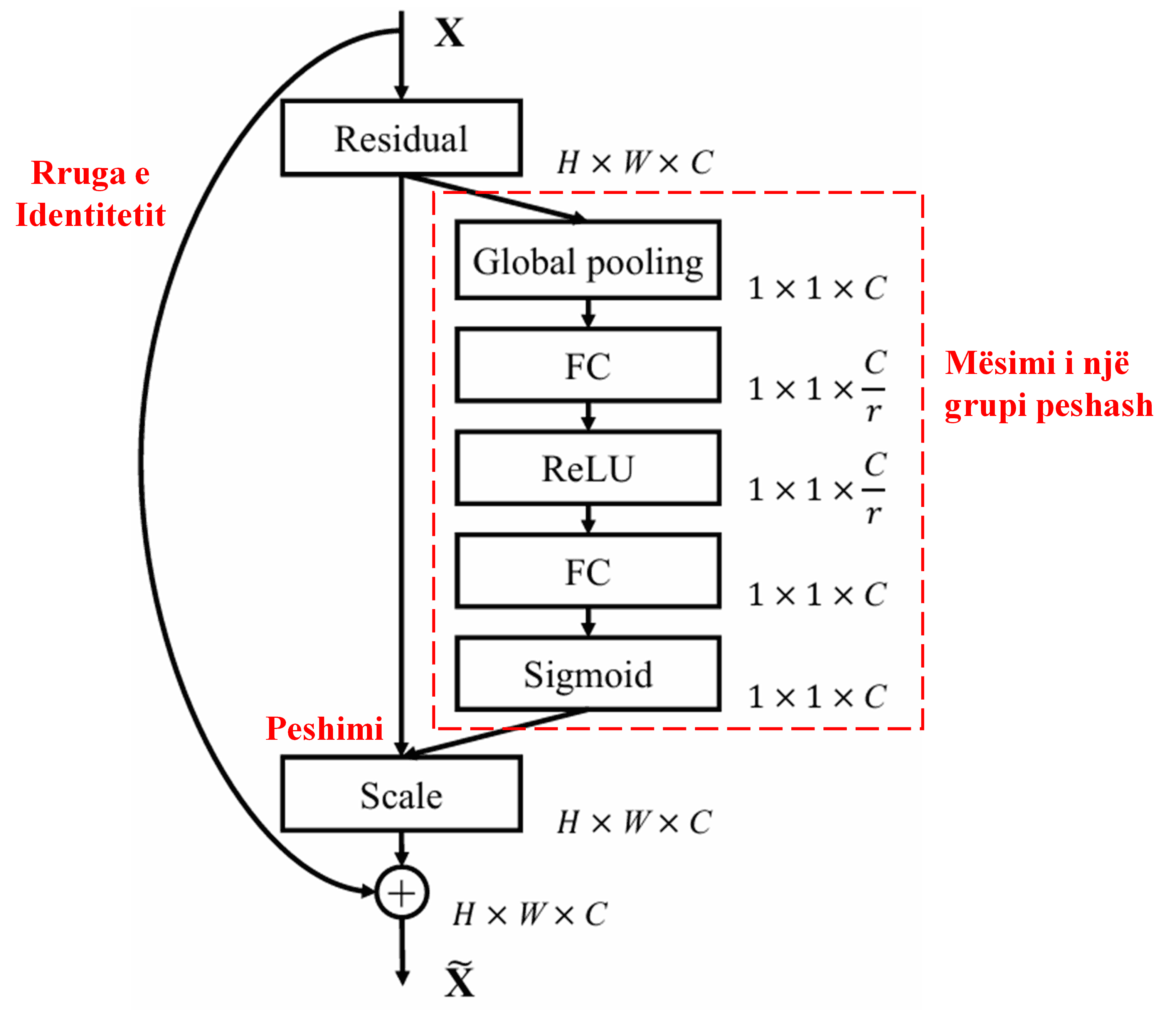
4. Soft Thresholding me Mekanizëm Vëmendjeje të Thellë
Deep Residual Shrinkage Network merr frymëzim nga struktura e nën-rrjetit të SENet (përmendur më sipër) për të realizuar Soft Thresholding nën një mekanizëm vëmendjeje të thellë. Përmes nën-rrjetit brenda kornizës së kuqe, mund të mësohet një grup pragjesh (thresholds) për të aplikuar Soft Thresholding në çdo kanal tipari.
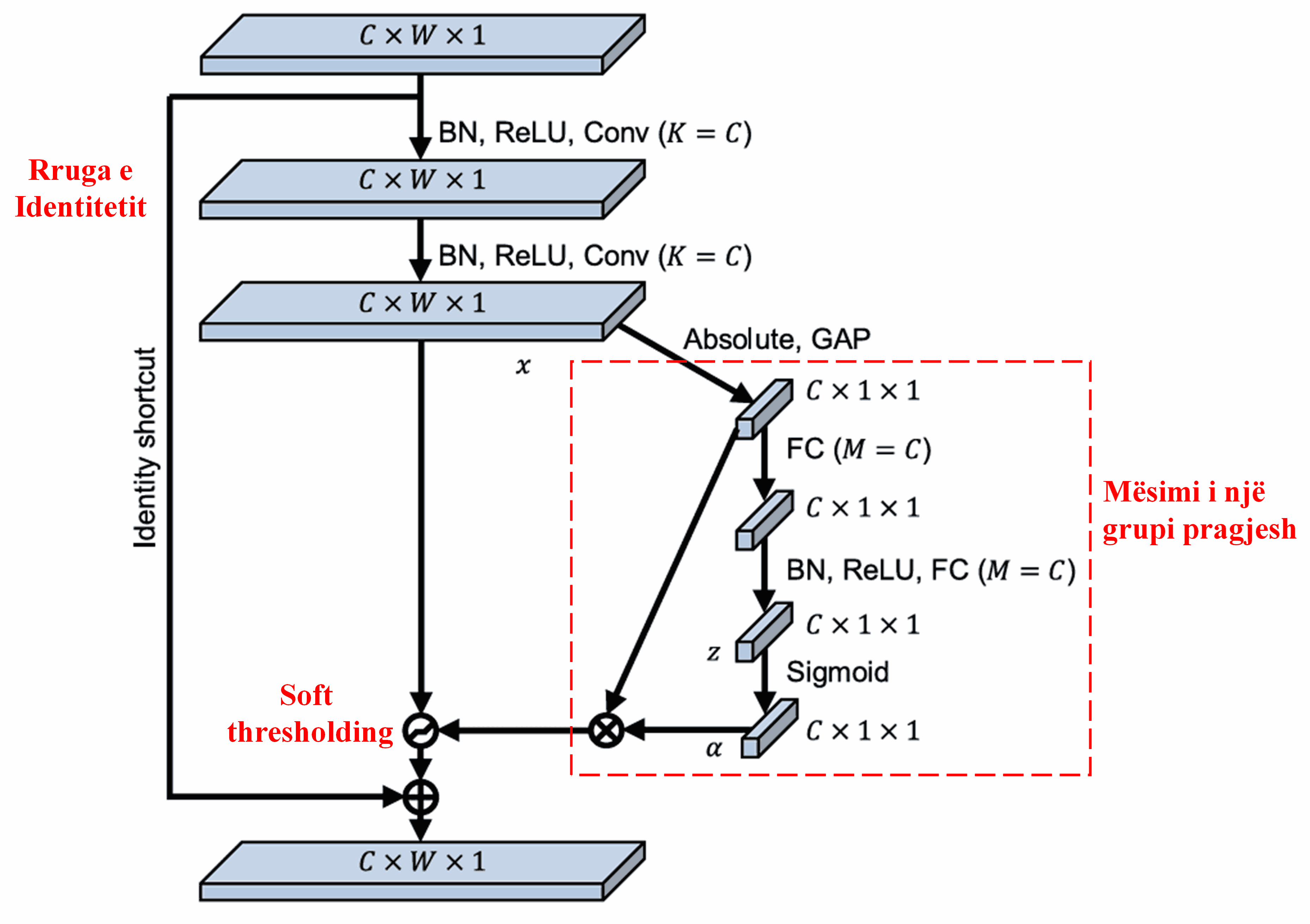
Në këtë nën-rrjet, fillimisht llogariten vlerat absolute të të gjitha tipareve në hartën e tipareve hyrëse (input feature map). Më pas, përmes Global Average Pooling dhe mesatares, përftohet një tipar, i cili shënohet si A. Në rrugën tjetër, harta e tipareve pas Global Average Pooling futet në një rrjet të vogël plotësisht të lidhur (fully connected network). Ky rrjet përdor funksionin Sigmoid si shtresë të fundit për të normalizuar rezultatin midis 0 dhe 1, duke dhënë një koeficient të shënuar si α. Pragu përfundimtar mund të shprehet si α×A. Pra, pragu është prodhimi i një numri midis 0 dhe 1 me mesataren e vlerave absolute të hartës së tipareve. Kjo metodë garanton që pragu jo vetëm të jetë pozitiv, por gjithashtu të mos jetë tepër i madh.
Për më tepër, mostra të ndryshme rezultojnë në pragje të ndryshme. Si rrjedhojë, në njëfarë mase, kjo mund të kuptohet si një mekanizëm i veçantë vëmendjeje: ai vëren tiparet e parëndësishme për detyrën aktuale, i transformon ato përmes dy shtresave konvolucionale në vlera afër zeros, dhe i bën ato zero përmes Soft Thresholding; ose anasjelltas, ai vëren tiparet e rëndësishme për detyrën, i transformon ato në vlera larg zeros, dhe i ruan ato.
Së fundmi, duke mbivendosur (stacking) një numër të caktuar modulesh bazë së bashku me shtresat konvolucionale, Batch Normalization, funksionet e aktivizimit, Global Average Pooling, dhe shtresat dalëse Fully Connected, ndërtohet i plotë Deep Residual Shrinkage Network.
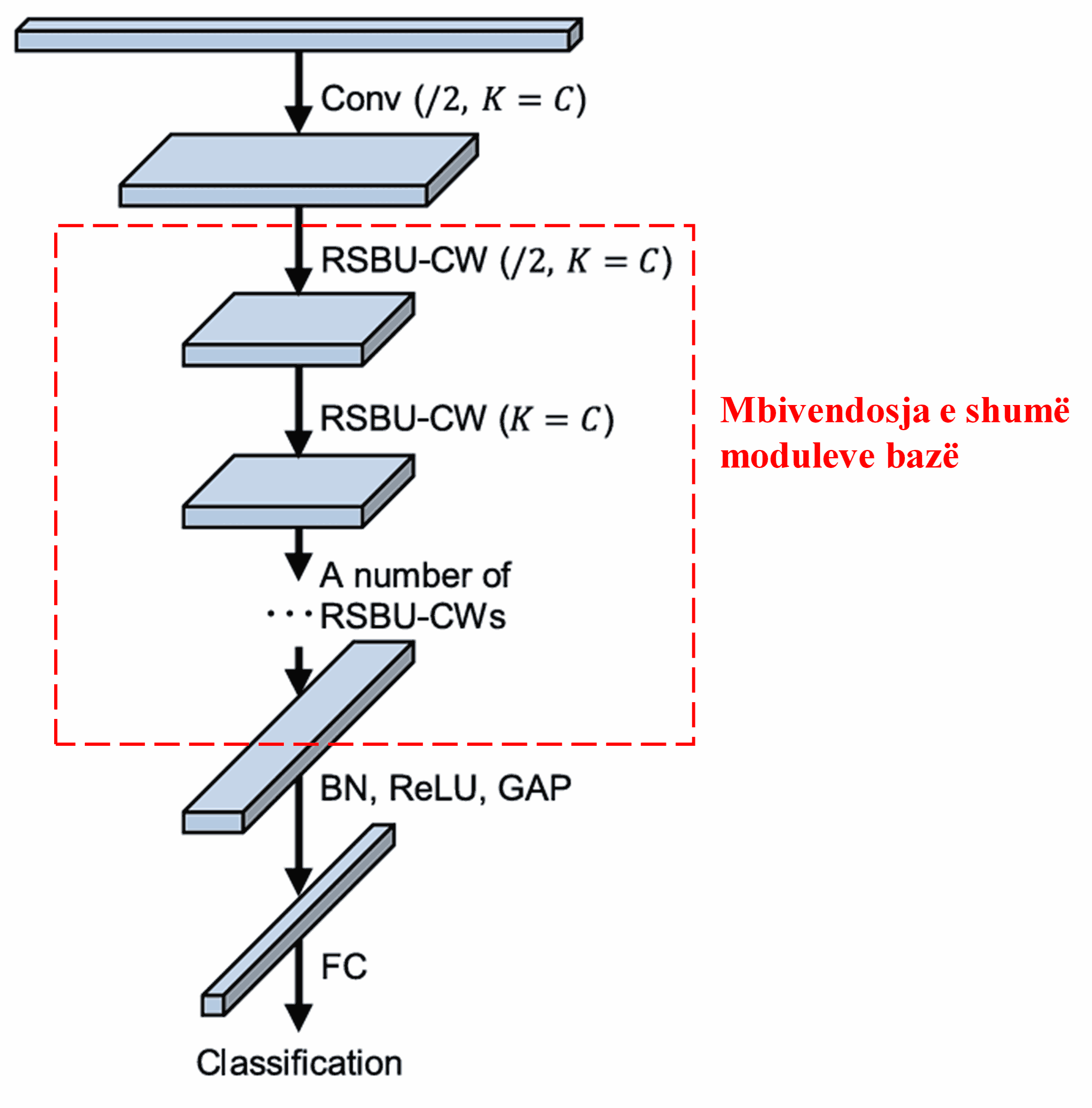
5. Aftësia e Përgjithësimit (Generalization Capability)
Deep Residual Shrinkage Network është, në fakt, një metodë e përgjithshme për mësimin e tipareve (feature learning). Kjo sepse në shumë detyra të mësimit të tipareve, mostrat përmbajnë pak a shumë zhurmë si dhe informacione të parëndësishme. Kjo zhurmë dhe ky informacion i parëndësishëm mund të ndikojnë në performancën e mësimit të tipareve. Për shembull:
Në klasifikimin e imazheve, nëse një imazh përmban njëkohësisht shumë objekte të tjera, këto objekte mund të kuptohen si “zhurmë”. Deep Residual Shrinkage Network mund të jetë në gjendje të përdorë mekanizmin e vëmendjes për të vënë re këtë “zhurmë” dhe më pas të përdorë Soft Thresholding për t’i bërë zero tiparet që korrespondojnë me këtë “zhurmë”, duke rritur kështu potencialisht saktësinë e klasifikimit të imazheve.
Në njohjen e zërit (speech recognition), veçanërisht në mjedise me zhurmë si bisedat në anë të rrugës ose brenda një punishteje fabrike, Deep Residual Shrinkage Network mund të përmirësojë saktësinë e njohjes së zërit, ose të paktën, të ofrojë një metodologji të aftë për të rritur saktësinë e njohjes së zërit.
Referenca
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Ndikimi Akademik
Ky punim ka marrë mbi 1400 citime në Google Scholar.
Sipas vlerësimeve jo të plota, Deep Residual Shrinkage Networks (DRSN) janë përdorur në më shumë se 1000 publikime. Këto punime kanë aplikuar drejtpërdrejt ose kanë përmirësuar këtë rrjet në një gamë të gjerë fushash, përfshirë inxhinierinë mekanike, energjinë elektrike, vizionin kompjuterik, kujdesin shëndetësor, përpunimin e zërit, analizën e tekstit, radarin dhe ndijimin në distancë (remote sensing).