Deep Residual Shrinkage Network (DRSN) ဆိုတာက Deep Residual Network (ResNet) ကို improvement လုပ်ထားတဲ့ version တစ်ခုဖြစ်ပါတယ်။ တကယ်တော့ သူက Deep Residual Network၊ Attention Mechanism နဲ့ Soft Thresholding Function သုံးခုကို ပေါင်းစပ်ထားတာ ဖြစ်ပါတယ်။
အတိုင်းအတာတစ်ခုအထိ ပြောရမယ်ဆိုရင် Deep Residual Shrinkage Network ရဲ့ အလုပ်လုပ်ပုံက ဒီလိုပါ- Attention Mechanism ကနေတဆင့် အရေးမကြီးတဲ့ Feature တွေကို Soft Thresholding Function သုံးပြီး Zero ဖြစ်သွားအောင် လုပ်ပစ်လိုက်တာပါ (သို့မဟုတ်) အရေးကြီးတဲ့ Feature တွေကိုတော့ ဆက်ပြီး သိမ်းထားလိုက်တာပါ။ ဒီနည်းအားဖြင့် Deep Neural Network တွေက Noise ပါတဲ့ Signal တွေထဲကနေ အသုံးဝင်တဲ့ Feature တွေကို ထုတ်ယူနိုင်စွမ်း ပိုကောင်းလာစေပါတယ်။
1. Research Motivation
နံပါတ် (၁) အချက်ကတော့ Sample တွေကို Classify လုပ်တဲ့အခါ Sample တွေထဲမှာ Gaussian Noise၊ Pink Noise၊ Laplacian Noise စတဲ့ Noise တွေ ရှောင်လွှဲမရဘဲ ပါလာတတ်လို့ပါ။ ပိုကျယ်ကျယ်ပြန့်ပြန့် ပြောရရင် Classification Task နဲ့ မဆိုင်တဲ့ Information တွေ ပါလာတတ်ပြီး အဲဒါတွေကိုလည်း Noise လို့ပဲ သတ်မှတ်နိုင်ပါတယ်။ ဒီ Noise တွေက Classification ရလဒ်ကို ထိခိုက်စေနိုင်ပါတယ်။ (Soft Thresholding ဆိုတာ Signal Denoising Algorithm တော်တော်များများရဲ့ အဓိက အဆင့်တစ်ခု ဖြစ်ပါတယ်)။
ဥပမာ - လမ်းဘေးမှာ စကားပြောနေတယ်ဆိုပါစို့။ စကားသံထဲမှာ ကားဟွန်းသံတွေ၊ ဘီးလိမ့်သံတွေ ပါလာနိုင်ပါတယ်။ အဲဒီ Signal တွေကို Speech Recognition လုပ်တဲ့အခါ ဟွန်းသံ၊ ဘီးသံတွေကြောင့် အနှောင့်အယှက် ဖြစ်စေပါတယ်။ Deep Learning ရှုထောင့်က ကြည့်မယ်ဆိုရင် ဒီလို ဟွန်းသံ၊ ဘီးသံတွေနဲ့ သက်ဆိုင်တဲ့ Feature တွေကို Deep Neural Network အတွင်းပိုင်းမှာတင် ဖယ်ရှားပစ်သင့်ပါတယ်။ ဒါမှ Speech Recognition ရဲ့ ရလဒ်ကို မထိခိုက်မှာ ဖြစ်ပါတယ်။
နံပါတ် (၂) အချက်ကတော့ Sample Set တစ်ခုတည်းမှာတောင် Sample အချင်းချင်း မတူညီတဲ့ Noise ပမာဏတွေ ပါဝင်နေတာမို့လို့ပါ။ (ဒါက Attention Mechanism သဘောတရားနဲ့ ဆင်တူပါတယ်။ Image Dataset တစ်ခုကို ဥပမာပေးရရင် ပုံတစ်ပုံချင်းစီမှာ Target Object ရှိတဲ့နေရာ မတူသလိုမျိုး Attention Mechanism က သက်ဆိုင်ရာနေရာကို အာရုံစိုက်ပေးနိုင်ပါတယ်)။
ဥပမာ - ကြောင်နဲ့ခွေး ခွဲခြားတဲ့ Classifier ကို Train တဲ့အခါ “ခွေး” လို့ Label တပ်ထားတဲ့ ပုံ ၅ ပုံ ရှိတယ် ဆိုပါစို့။ ပထမပုံမှာ ခွေးနဲ့ကြွက်၊ ဒုတိယပုံမှာ ခွေးနဲ့ငန်း၊ တတိယပုံမှာ ခွေးနဲ့ကြက်၊ စတုတ္ထပုံမှာ ခွေးနဲ့မြည်း၊ ပဉ္စမပုံမှာ ခွေးနဲ့ဘဲ.. စသည်ဖြင့် ပါနိုင်ပါတယ်။ ဒီလို ကြွက်၊ ငန်း၊ ကြက်၊ မြည်း နဲ့ ဘဲ စတဲ့ မဆိုင်တဲ့အရာတွေ (Irrelevant Objects) က Classifier ရဲ့ Accuracy ကို ကျစေပါတယ်။ တကယ်လို့ ဒီမဆိုင်တဲ့ အရာတွေကို သတိပြုမိပြီး ဖယ်ရှားပစ်နိုင်မယ်ဆိုရင် Cat-Dog Classifier ရဲ့ Accuracy တက်လာနိုင်ပါတယ်။
2. Soft Thresholding
Soft Thresholding ဆိုတာ Signal Denoising Algorithm တွေရဲ့ အဓိကကျတဲ့ အဆင့်တစ်ခုပါ။ သူက သတ်မှတ်ထားတဲ့ Threshold ထက် Absolute Value ငယ်တဲ့ Feature တွေကို ဖယ်ရှားပစ်ပြီး၊ Threshold ထက်ကြီးတဲ့ Feature တွေကိုတော့ Zero ဘက်ကို ကျုံ့သွားအောင် (Shrink ဖြစ်အောင်) လုပ်ပေးပါတယ်။ သူ့ကို အောက်ပါ Formula နဲ့ တွက်ချက်နိုင်ပါတယ်-
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Input အပေါ်မူတည်ပြီး Soft Thresholding ရဲ့ Output ပြောင်းလဲမှုနှုန်း (Derivative) ကတော့ ဒီလိုပါ-
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]အပေါ်က Formula အရ Soft Thresholding ရဲ့ Derivative က 1 သို့မဟုတ် 0 ပဲ ဖြစ်ပါတယ်။ ဒီဂုဏ်သတ္တိက ReLU Activation Function နဲ့ အတူတူပါပဲ။ ဒါကြောင့် Soft Thresholding က Deep Learning Algorithm တွေမှာ ဖြစ်တတ်တဲ့ Gradient Vanishing နဲ့ Gradient Exploding ပြဿနာတွေကို လျှော့ချပေးနိုင်ပါတယ်။
Soft Thresholding Function မှာ Threshold သတ်မှတ်တဲ့အခါ အချက် (၂) ချက်နဲ့ ကိုက်ညီရပါမယ်။ ပထမအချက်က Threshold ဟာ အပေါင်းကိန်း (Positive) ဖြစ်ရပါမယ်။ ဒုတိယအချက်က Threshold ဟာ Input Signal ရဲ့ Maximum Value ထက် မကြီးရပါဘူး။ မဟုတ်ရင် Output တွေ အကုန်လုံး Zero ဖြစ်သွားပါလိမ့်မယ်။
ဒါ့အပြင် တတိယအချက်အနေနဲ့ - Sample တစ်ခုချင်းစီမှာ ပါဝင်တဲ့ Noise ပမာဏအပေါ် မူတည်ပြီး ကိုယ်ပိုင် Threshold တစ်ခုစီ ရှိသင့်ပါတယ်။
ဘာကြောင့်လဲဆိုတော့ Sample တွေမှာ ပါဝင်တဲ့ Noise ပမာဏက မတူကြလို့ပါ။ ဥပမာ - Sample Set တစ်ခုတည်းမှာပဲ Sample A က Noise နည်းပြီး Sample B က Noise များနေတာမျိုး ဖြစ်နိုင်ပါတယ်။ ဒီအခါ Denoising Algorithm ထဲမှာ Soft Thresholding လုပ်ရင် Sample A အတွက် Threshold အနည်းငယ်သာသုံးပြီး Sample B အတွက် Threshold များများသုံးသင့်ပါတယ်။ Deep Neural Network မှာတော့ ဒီ Feature တွေနဲ့ Threshold တွေက ရူပဗေဒသဘောတရားအရ တိတိကျကျ အဓိပ္ပာယ်ဖွင့်ဖို့ ခက်ပေမယ့် အခြေခံသဘောတရားကတော့ အတူတူပါပဲ။ ဆိုလိုတာက Sample တစ်ခုချင်းစီက သူ့ Noise ပမာဏအလိုက် သီးသန့် Threshold ရှိနေသင့်တာ ဖြစ်ပါတယ်။
3. Attention Mechanism
Attention Mechanism ကို Computer Vision နယ်ပယ်မှာ နားလည်ရ လွယ်ကူပါတယ်။ တိရစ္ဆာန်တွေရဲ့ အမြင်အာရုံစနစ်က နေရာတစ်ခုလုံးကို အမြန် Scan ဖတ်ပြီး Target Object ကို ရှာဖွေပါတယ်၊ ပြီးမှ Target ပေါ် အာရုံစိုက် (Focus) ပါတယ်။ အသေးစိတ်အချက်အလက်ကို ပိုရယူပြီး မဆိုင်တာတွေကို လျစ်လျူရှုလိုက်တာပါ။ အသေးစိတ်ကိုတော့ Attention Mechanism ဆိုင်ရာ Paper တွေမှာ ဖတ်ရှုနိုင်ပါတယ်။
Squeeze-and-Excitation Network (SENet) ဆိုတာ Attention Mechanism ကို သုံးထားတဲ့ Deep Learning Method အသစ်တစ်ခု ဖြစ်ပါတယ်။ Sample တွေမတူရင် Classification Task အတွက် Feature Channel တစ်ခုချင်းစီရဲ့ အရေးပါမှု (Contribution) ကလည်း ကွဲပြားနိုင်ပါတယ်။ SENet က သီးသန့် Sub-network အသေးစားလေးတစ်ခုကို သုံးပြီး Weight တစ်စုံကို တွက်ထုတ်ပါတယ်။ ပြီးရင် ဒီ Weight တွေကို သက်ဆိုင်ရာ Channel က Feature တွေနဲ့ မြှောက်ပေးပြီး Adjust လုပ်ပါတယ်။ ဒီဖြစ်စဉ်ကို Feature Channel တစ်ခုချင်းစီအပေါ် Attention (အာရုံစိုက်မှု) အနည်းအများ ပေးတယ်လို့ ယူဆနိုင်ပါတယ်။
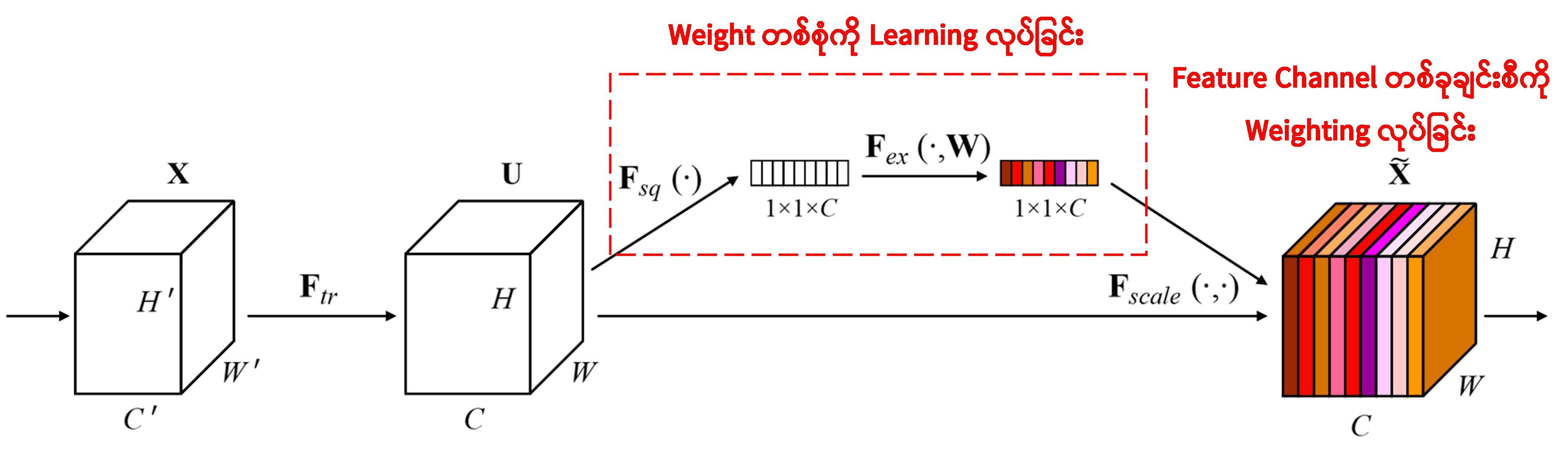
ဒီနည်းလမ်းမှာ Sample တစ်ခုချင်းစီအတွက် မတူညီတဲ့ Weight တွေ ရှိနေမှာပါ။ တစ်နည်းအားဖြင့် Sample နှစ်ခုက Weight တွေ မတူနိုင်ပါဘူး။ SENet မှာ Weight ရဖို့အတွက် “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function” ဆိုတဲ့ လမ်းကြောင်းအတိုင်း တွက်ချက်ပါတယ်။
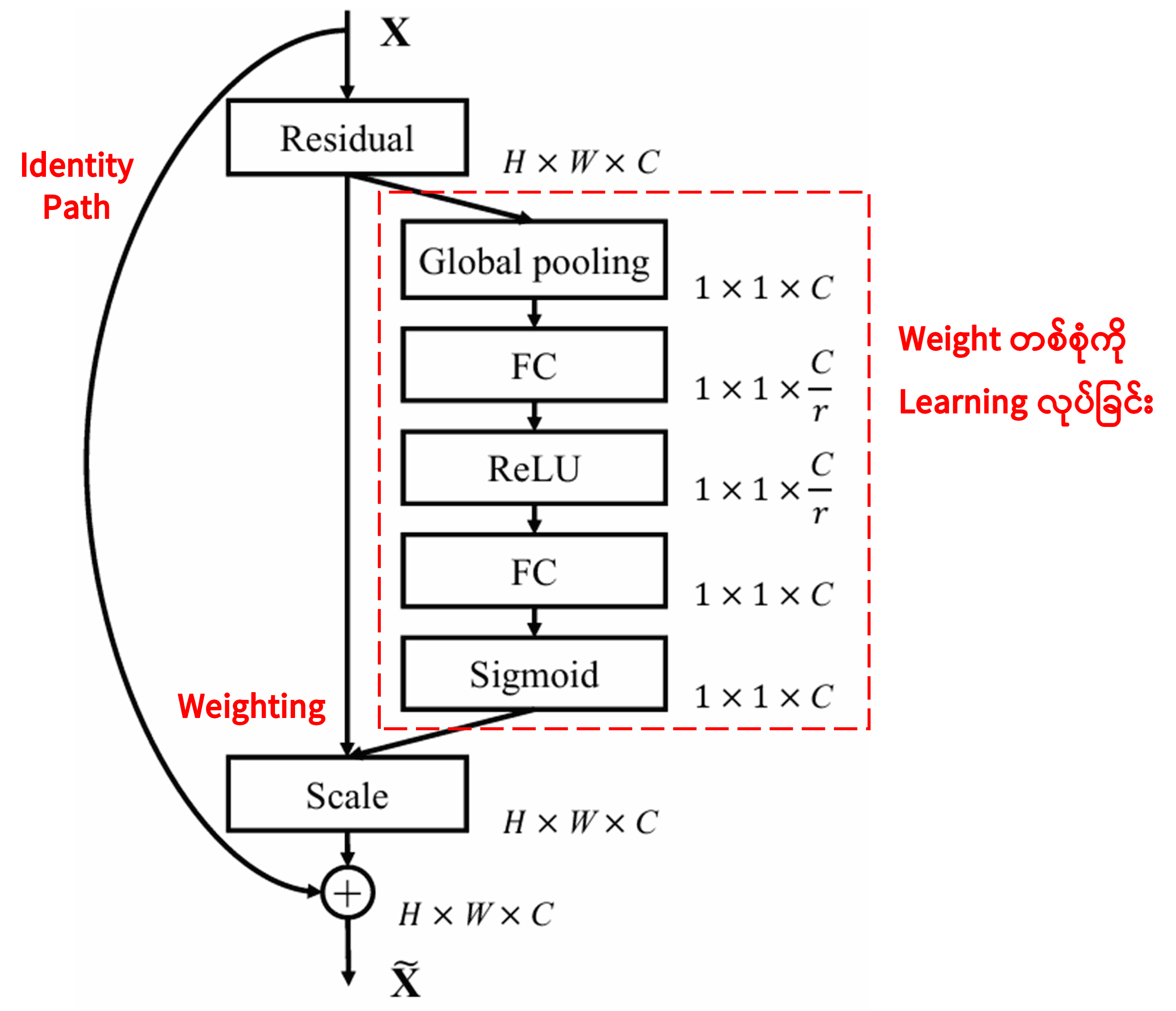
4. Deep Attention Mechanism အောက်မှ Soft Thresholding
Deep Residual Shrinkage Network က အထက်မှာ ပြောခဲ့တဲ့ SENet ရဲ့ Sub-network တည်ဆောက်ပုံကို ယူသုံးထားပြီး Deep Attention Mechanism အောက်မှာ Soft Thresholding လုပ်ဆောင်တာ ဖြစ်ပါတယ်။ (အနီရောင် box ထဲက) Sub-network ကနေတဆင့် Feature Channel တစ်ခုချင်းစီအတွက် သင့်တော်မယ့် Threshold တွေကို Learning လုပ်ယူပါတယ်။
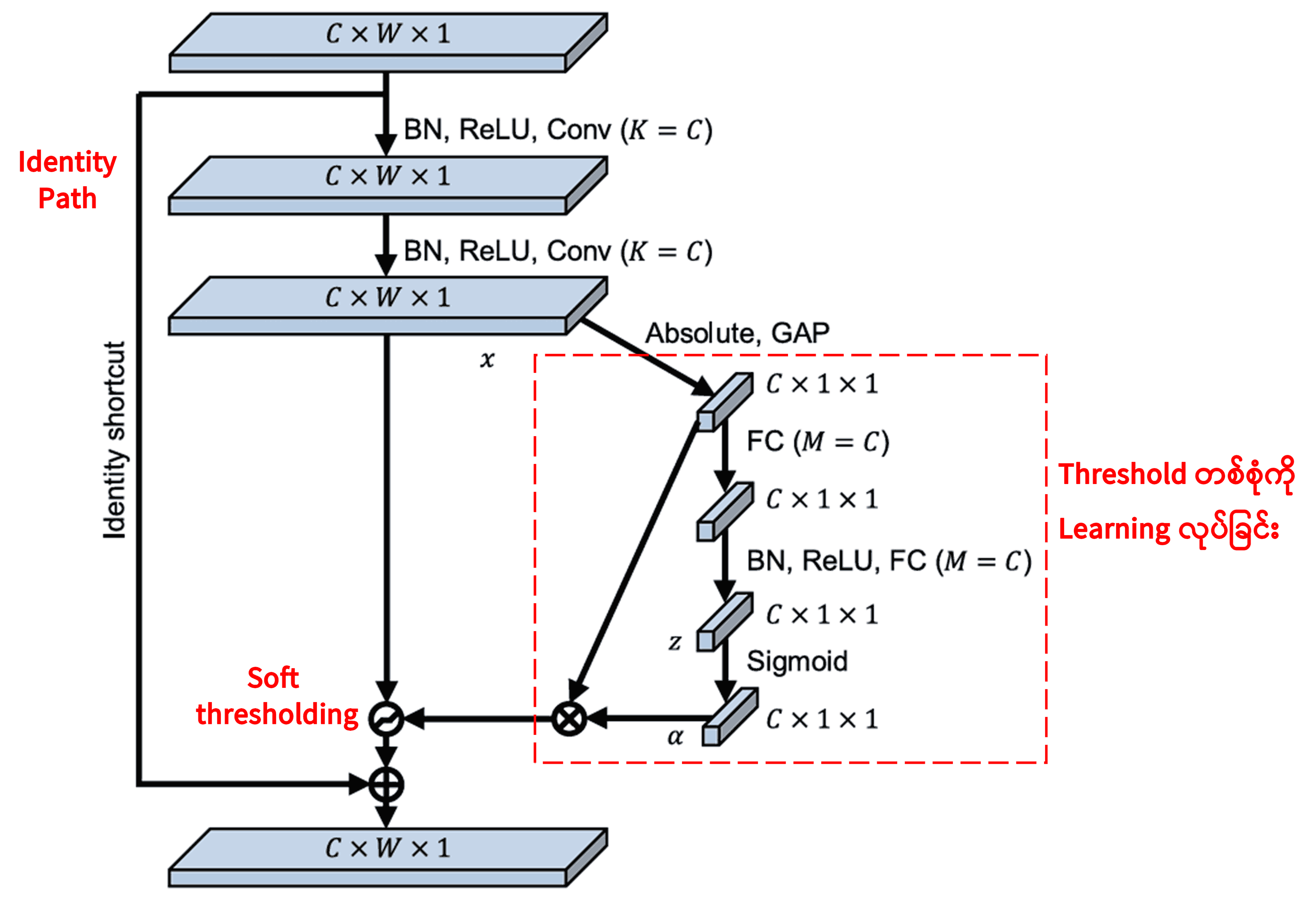
ဒီ Sub-network ထဲမှာ ပထမဆုံး Input Feature Map ရဲ့ Feature အားလုံးကို Absolute Value ရှာပါတယ်။ ပြီးရင် Global Average Pooling လုပ်ပြီး Average တန်ဖိုးတစ်ခု ယူပါတယ် (ဒါကို A လို့ သတ်မှတ်ပါမယ်)။ နောက်လမ်းကြောင်းတစ်ခုမှာတော့ Global Average Pooling လုပ်ပြီးသား Feature Map ကို Fully Connected Network အငယ်စားတစ်ခုထဲ ထည့်ပါတယ်။ ဒီ Network ရဲ့ နောက်ဆုံး Layer မှာ Sigmoid Function ခံထားတဲ့အတွက် Output က 0 နဲ့ 1 ကြားမှာပဲ ရှိပါမယ် (ဒါကို Coefficient α လို့ သတ်မှတ်ပါမယ်)။ နောက်ဆုံးရလာမယ့် Threshold ကတော့ α နဲ့ A မြှောက်လဒ် (α × A) ဖြစ်ပါတယ်။ ဒါကြောင့် Threshold ဆိုတာ 0 နဲ့ 1 ကြားက ဂဏန်းတစ်ခုနဲ့ Feature Map Absolute Value တို့ရဲ့ ပျမ်းမျှတန်ဖိုးကို မြှောက်ထားတာ ဖြစ်ပါတယ်။ ဒီနည်းလမ်းက Threshold ကို အပေါင်းကိန်း (Positive) ဖြစ်စေသလို၊ တန်ဖိုး သိပ်မကြီးအောင်လည်း ထိန်းပေးပါတယ်။
ဒါ့အပြင် Sample မတူရင် Threshold လည်း မတူတော့ပါဘူး။ ဒါကြောင့် ဒါကို အထူးပြုလုပ်ထားတဲ့ Attention Mechanism တစ်ခုအနေနဲ့ နားလည်နိုင်ပါတယ်။ လက်ရှိ Task နဲ့ မဆိုင်တဲ့ Feature တွေကို သတိပြုမိပြီး Convolutional Layer နှစ်ခုကတဆင့် 0 နားကပ်သွားအောင် ပြောင်းလဲလိုက်မယ်၊ ပြီးတော့ Soft Thresholding နဲ့ လုံးဝ 0 ဖြစ်အောင် လုပ်ပစ်လိုက်မယ်။ တကယ်လို့ Task နဲ့ ဆိုင်တဲ့ Feature ဆိုရင်တော့ 0 နဲ့ ဝေးရာကို ပို့ပြီး ဆက်သိမ်းထားမယ်.. ဒီလိုသဘောတရား ဖြစ်ပါတယ်။
နောက်ဆုံးမှာတော့ ဒီ Basic Module တွေအပြင် Convolution Layer၊ Batch Normalization၊ Activation Function၊ Global Average Pooling နဲ့ Fully Connected Output Layer တွေကို ထပ်ဆင့် တည်ဆောက်လိုက်ရင် ပြည့်စုံတဲ့ Deep Residual Shrinkage Network ကို ရရှိမှာ ဖြစ်ပါတယ်။
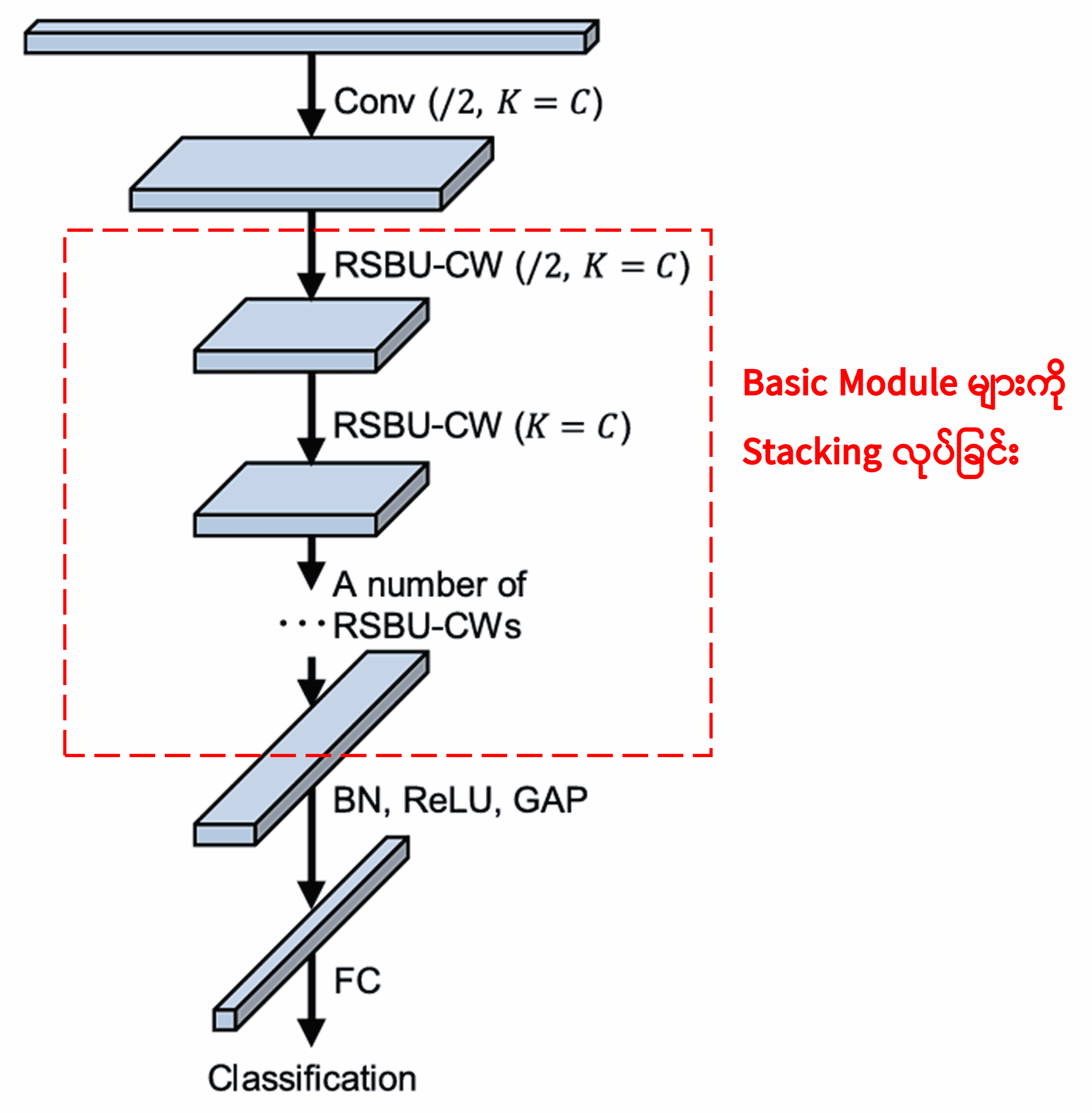
5. Generalization Capability (ဘက်စုံအသုံးဝင်မှု)
Deep Residual Shrinkage Network ဟာ General ဖြစ်တဲ့ Feature Learning Method တစ်ခု ဖြစ်ပါတယ်။ ဘာလို့လဲဆိုတော့ Feature Learning Task တော်တော်များများမှာ Sample တွေထဲ Noise တွေ၊ မဆိုင်တဲ့ Information တွေ နည်းနဲ့များ ဆိုသလို ပါလာတတ်လို့ပါ။ ဒီ Noise တွေက Feature Learning ကို အနှောင့်အယှက် ဖြစ်စေပါတယ်။ ဥပမာအားဖြင့် -
Image Classification လုပ်တဲ့အခါ ပုံထဲမှာ တခြားမဆိုင်တဲ့ အရာဝတ္ထုတွေ အများကြီး ပါနေတယ်ဆိုရင် အဲဒါတွေကို “Noise” လို့ သတ်မှတ်နိုင်ပါတယ်။ Deep Residual Shrinkage Network က Attention Mechanism ကိုသုံးပြီး ဒီ “Noise” တွေကို သတိပြုမိနိုင်သလို၊ Soft Thresholding ကတဆင့် ဒီ “Noise” တွေရဲ့ Feature တွေကို Zero ဖြစ်အောင် လုပ်ပေးနိုင်တဲ့အတွက် Classification Accuracy ကို တက်လာစေနိုင်ပါတယ်။
Speech Recognition လုပ်တဲ့အခါမှာလည်း လမ်းဘေးမှာ၊ စက်ရုံထဲမှာ စကားပြောသလိုမျိုး ဆူညံတဲ့ ပတ်ဝန်းကျင်တွေမှာဆိုရင် Deep Residual Shrinkage Network က Accuracy ကို တက်လာစေနိုင်ပါတယ် (သို့မဟုတ်) Accuracy တက်လာစေမယ့် နည်းလမ်းတစ်ခု ဖြစ်လာနိုင်ပါတယ်။
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Academic Impact (သက်ရောက်မှုများ)
ဒီ Paper ရဲ့ Google Scholar Citation က ၁၄၀၀ ကျော် ရှိနေပါပြီ။
စာရင်းဇယားတွေအရ Deep Residual Shrinkage Network ကို Mechanical, Electric Power, Vision, Medical, Speech, Text, Radar, Remote Sensing စတဲ့ နယ်ပယ်ပေါင်းစုံက Paper ပေါင်း ၁၀၀၀ ကျော်မှာ တိုက်ရိုက် အသုံးပြုတာမျိုး (သို့မဟုတ်) ပြန်လည်မွမ်းမံပြီး အသုံးပြုတာမျိုးတွေ လုပ်ဆောင်ထားကြပါတယ်။