Deep Residual Shrinkage Network എന്നത് Deep Residual Network-ന്റെ മെച്ചപ്പെടുത്തിയ ഒരു പതിപ്പാണ് (improved version). ചുരുക്കത്തിൽ, ഇത് Deep Residual Network, Attention Mechanism, Soft Thresholding function എന്നിവയുടെ ഒരു integration ആണ്.
ഒരു പരിധിവരെ, Deep Residual Shrinkage Network-ന്റെ പ്രവർത്തനരീതി ഇങ്ങനെ മനസ്സിലാക്കാം: Attention mechanism ഉപയോഗിച്ച് അപ്രധാനമായ features-നെ (unimportant features) കണ്ടെത്തുകയും, soft thresholding function വഴി അവയെ zero ആക്കി മാറ്റുകയും ചെയ്യുന്നു. അതുപോലെ, പ്രധാനപ്പെട്ട features-നെ അത് തിരിച്ചറിയുകയും അവയെ നിലനിർത്തുകയും ചെയ്യുന്നു. Noise അടങ്ങിയ സിഗ്നലുകളിൽ (signals) നിന്ന് ഉപയോഗപ്രദമായ features വേർതിരിച്ചെടുക്കാനുള്ള Deep Neural Network-ന്റെ കഴിവ് ഇത് വർദ്ധിപ്പിക്കുന്നു.
1. Research Motivation (ഗവേഷണത്തിനുള്ള പ്രചോദനം)
ആദ്യമായി, samples classify ചെയ്യുമ്പോൾ, അവയിൽ ഒഴിവാക്കാനാകാത്ത വിധം ചില noise ഉണ്ടായിരിക്കും (ഉദാഹരണത്തിന് Gaussian noise, Pink noise, Laplacian noise തുടങ്ങിയവ). കുറച്ചുകൂടി വ്യക്തമായി പറഞ്ഞാൽ, നിലവിലെ classification task-മായി ബന്ധമില്ലാത്ത എന്തിനെയും noise ആയി കണക്കാക്കാം. ഈ noise, classification-ന്റെ കൃത്യതയെ (accuracy) ദോഷകരമായി ബാധിച്ചേക്കാം. (പല signal denoising algorithms-ലെയും ഒരു പ്രധാന ഘട്ടമാണ് Soft thresholding).
ഉദാഹരണത്തിന്, റോഡരികിൽ നിന്ന് സംസാരിക്കുമ്പോൾ, ആ സംഭാഷണത്തിൽ വണ്ടികളുടെ ഹോൺ ശബ്ദവും ചക്രങ്ങളുടെ ശബ്ദവും മറ്റും കലരാൻ സാധ്യതയുണ്ട്. ഈ ശബ്ദങ്ങളെ speech recognition ചെയ്യുമ്പോൾ, ഹോൺ ശബ്ദവും മറ്റും തിരിച്ചറിയൽ പ്രക്രിയയെ (recognition process) ബാധിക്കും. Deep learning-ന്റെ വീക്ഷണകോണിൽ നോക്കിയാൽ, speech recognition-നെ ബാധിക്കാതിരിക്കാൻ, ഹോൺ ശബ്ദങ്ങൾക്കും വണ്ടിയുടെ ശബ്ദങ്ങൾക്കും തുല്യമായ features, deep neural network-ന് ഉള്ളിൽ വെച്ച് തന്നെ നീക്കം ചെയ്യപ്പെടേണ്ടതുണ്ട്.
രണ്ടാമതായി, ഒരേ dataset-ൽ ആണെങ്കിൽ കൂടി, ഓരോ sample-ലും അടങ്ങിയിരിക്കുന്ന noise-ന്റെ അളവ് പലപ്പോഴും വ്യത്യസ്തമായിരിക്കും. (ഇത് attention mechanism-വുമായി സാമ്യമുള്ള കാര്യമാണ്; ഒരു image dataset ഉദാഹരണമായി എടുത്താൽ, ഓരോ ചിത്രത്തിലും target object ഇരിക്കുന്ന സ്ഥലം വ്യത്യസ്തമായിരിക്കാം. Attention mechanism-ത്തിന് ഓരോ ചിത്രത്തിലെയും target object ഇരിക്കുന്ന സ്ഥലം പ്രത്യേകം ശ്രദ്ധിക്കാൻ കഴിയും).
ഉദാഹരണത്തിന്, ഒരു cat-and-dog classifier പരിശീലിപ്പിക്കുമ്പോൾ (training), “dog” എന്ന ലേബൽ ഉള്ള 5 ചിത്രങ്ങൾ പരിഗണിക്കുക. ഒന്നാമത്തെ ചിത്രത്തിൽ പട്ടിയോടൊപ്പം ഒരു എലി (mouse) ഉണ്ടാകാം, രണ്ടാമത്തേതിൽ പട്ടിയോടൊപ്പം ഒരു വാത്ത (goose), മൂന്നാമത്തേതിൽ കോഴി (chicken), നാലാമത്തേതിൽ കഴുത (donkey), അഞ്ചാമത്തേതിൽ താറാവ് (duck) എന്നിങ്ങനെയാകാം. നമ്മൾ cat-and-dog classifier പരിശീലിപ്പിക്കുമ്പോൾ, എലി, വാത്ത, കോഴി, കഴുത, താറാവ് തുടങ്ങിയ അനാവശ്യ objects കാരണം classification accuracy കുറയാൻ സാധ്യതയുണ്ട്. ഈ അനാവശ്യ objects-നെ ശ്രദ്ധിക്കുകയും (notice), അവയ്ക്ക് തുല്യമായ features നീക്കം ചെയ്യുകയും ചെയ്താൽ, cat-and-dog classifier-ന്റെ accuracy വർദ്ധിപ്പിക്കാൻ സാധിക്കും.
2. Soft Thresholding
പല signal denoising algorithms-ലെയും ഒരു പ്രധാന ഘട്ടമാണ് Soft thresholding. ഇത് ഒരു നിശ്ചിത threshold-നേക്കാൾ കുറഞ്ഞ absolute value ഉള്ള features-നെ നീക്കം ചെയ്യുകയും (delete/set to zero), threshold-നേക്കാൾ കൂടിയ absolute value ഉള്ള features-നെ zero-യുടെ ദിശയിലേക്ക് ചുരുക്കുകയും (shrink) ചെയ്യുന്നു. താഴെ പറയുന്ന formula ഉപയോഗിച്ച് ഇത് നടപ്പിലാക്കാം:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Soft thresholding-ന്റെ output-ന് input-നെ അപേക്ഷിച്ച് ഉള്ള derivative താഴെ പറയുന്നതാണ്:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]മുകളിൽ കാണിച്ചിരിക്കുന്നത് പോലെ, soft thresholding-ന്റെ derivative ഒന്നുകിൽ 1 അല്ലെങ്കിൽ 0 ആയിരിക്കും. ഈ പ്രത്യേകത ReLU activation function-ന് സമാനമാണ്. അതുകൊണ്ട്, deep learning algorithms-ൽ ഉണ്ടായേക്കാവുന്ന gradient vanishing, gradient exploding തുടങ്ങിയ പ്രശ്നങ്ങൾ കുറയ്ക്കാൻ soft thresholding-ന് സാധിക്കും.
Soft thresholding function-ൽ, threshold തീരുമാനിക്കുമ്പോൾ രണ്ട് കാര്യങ്ങൾ നിർബന്ധമായും പാലിക്കേണ്ടതുണ്ട്: ഒന്ന്, threshold ഒരു positive number ആയിരിക്കണം. രണ്ട്, threshold എന്നത് input signal-ന്റെ maximum value-യേക്കാൾ വലുതാകാൻ പാടില്ല, അങ്ങനെയെങ്കിൽ output മുഴുവനും zero ആയിപ്പോകും.
അതോടൊപ്പം, threshold മൂന്നാമതൊരു കാര്യം കൂടി പാലിക്കുന്നത് നന്നായിരിക്കും: ഓരോ sample-നും അതിലെ noise-ന്റെ അളവ് അനുസരിച്ച് സ്വന്തമായി ഒരു independent threshold ഉണ്ടായിരിക്കണം.
കാരണം, പല samples-ലും noise-ന്റെ അളവ് വ്യത്യസ്തമായിരിക്കും. ഉദാഹരണത്തിന്, ഒരേ dataset-ൽ ഉള്ള Sample A-യിൽ noise കുറവും, Sample B-യിൽ noise കൂടുതലും ആയിരിക്കാം. അങ്ങനെയെങ്കിൽ, denoising algorithm-ൽ soft thresholding ചെയ്യുമ്പോൾ, Sample A-ക്ക് ചെറിയ threshold-ഉം Sample B-ക്ക് വലിയ threshold-ഉം ആണ് നൽകേണ്ടത്. Deep neural network-ൽ ഈ features-നും thresholds-നും കൃത്യമായ ഭൗതിക അർത്ഥം (physical definition) ഇല്ലെങ്കിലും, ഇതിന്റെ അടിസ്ഥാന തത്വം ഒന്നുതന്നെയാണ്. അതായത്, ഓരോ sample-നും അതിലെ noise-ന് അനുസരിച്ചുള്ള threshold ഉണ്ടായിരിക്കണം.
3. Attention Mechanism
Computer Vision രംഗത്ത് Attention mechanism എന്നത് മനസ്സിലാക്കാൻ എളുപ്പമുള്ള ഒന്നാണ്. ജന്തുക്കളുടെ കാഴ്ചാ സംവിധാനത്തിന് (visual system) പെട്ടെന്നുതന്നെ മുഴുവൻ സ്ഥലവും scan ചെയ്യാനും, target object-നെ കണ്ടെത്താനും സാധിക്കും. തുടർന്ന് അനാവശ്യമായ വിവരങ്ങളെ ഒഴിവാക്കി, target object-ൽ മാത്രം ശ്രദ്ധ കേന്ദ്രീകരിച്ച് (focus attention) കൂടുതൽ വിവരങ്ങൾ ശേഖരിക്കുന്നു. ഇതിനെക്കുറിച്ച് കൂടുതൽ അറിയാൻ attention mechanism-വുമായി ബന്ധപ്പെട്ട ലേഖനങ്ങൾ നോക്കാവുന്നതാണ്.
Squeeze-and-Excitation Network (SENet) എന്നത് attention mechanism ഉപയോഗിക്കുന്ന ഒരു പുതിയ deep learning രീതിയാണ്. Classification task-ൽ, വ്യത്യസ്ത samples-ൽ, വ്യത്യസ്ത feature channels നൽകുന്ന contribution പലപ്പോഴും വ്യത്യസ്തമായിരിക്കും. SENet ഒരു ചെറിയ sub-network ഉപയോഗിച്ച് ഒരു കൂട്ടം weights കണ്ടെത്തുന്നു. ഈ weights ഓരോ channel-ലെയും features-മായി multiply ചെയ്ത്, ആ channel-ന്റെ features-ന്റെ വലിപ്പം (magnitude) ക്രമീകരിക്കുന്നു. ഓരോ feature channel-നും വ്യത്യസ്ത അളവിലുള്ള attention നൽകുന്നതായി ഇതിനെ കണക്കാക്കാം.
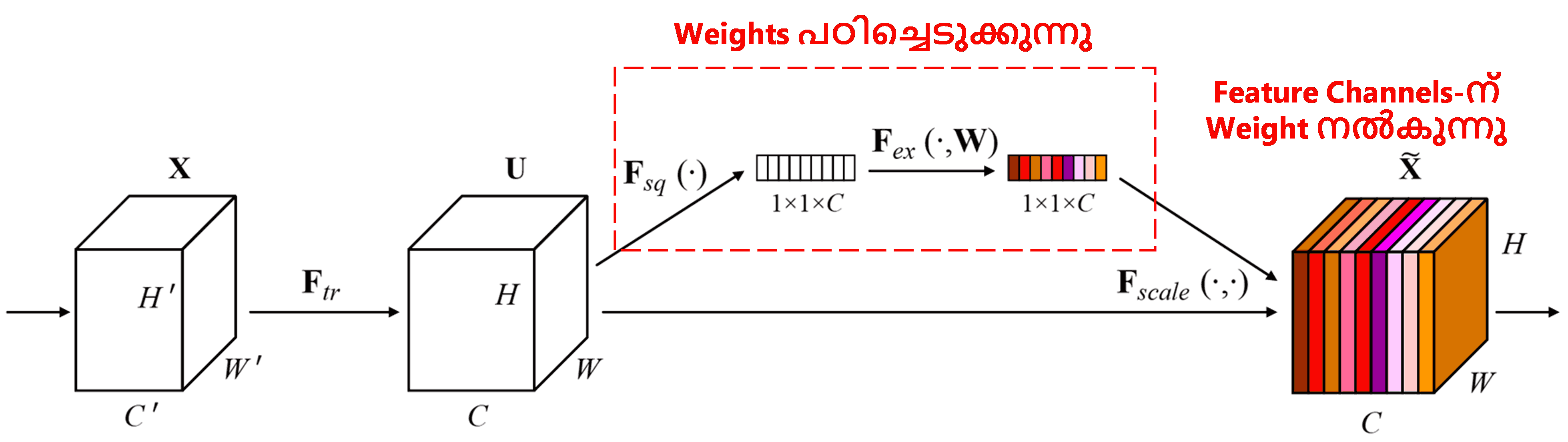
ഈ രീതിയിൽ, ഓരോ sample-നും അതിന്റേതായ independent weights ഉണ്ടായിരിക്കും. മറ്റൊരു രീതിയിൽ പറഞ്ഞാൽ, ഏതെങ്കിലും രണ്ട് samples-ന്റെ weights വ്യത്യസ്തമായിരിക്കും. SENet-ൽ weights ലഭിക്കുന്ന വഴിയെ “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function” എന്ന് വിളിക്കാം.
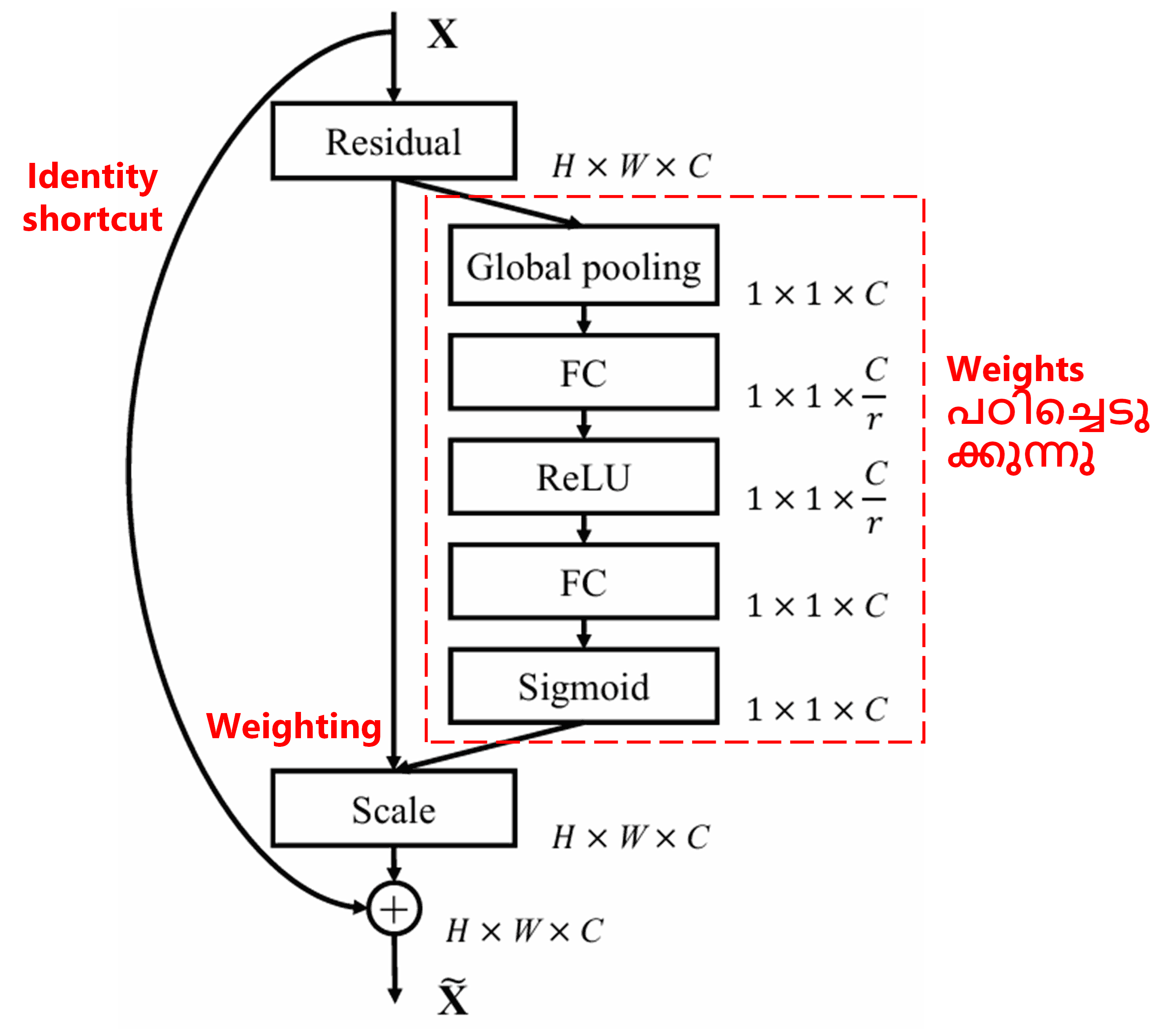
4. Deep Attention Mechanism ഉപയോഗിച്ചുള്ള Soft Thresholding
Deep Attention Mechanism ഉപയോഗിച്ച് soft thresholding നടപ്പിലാക്കാൻ, Deep Residual Shrinkage Network മുകളിൽ പറഞ്ഞ SENet-ന്റെ sub-network ഘടന ഉപയോഗിക്കുന്നു. ചുവന്ന ബോക്സിനുള്ളിൽ കാണിച്ചിരിക്കുന്ന sub-network വഴി, ഓരോ feature channel-നും soft thresholding ചെയ്യാൻ ആവശ്യമായ ഒരു കൂട്ടം thresholds പഠിച്ചെടുക്കാൻ സാധിക്കും.
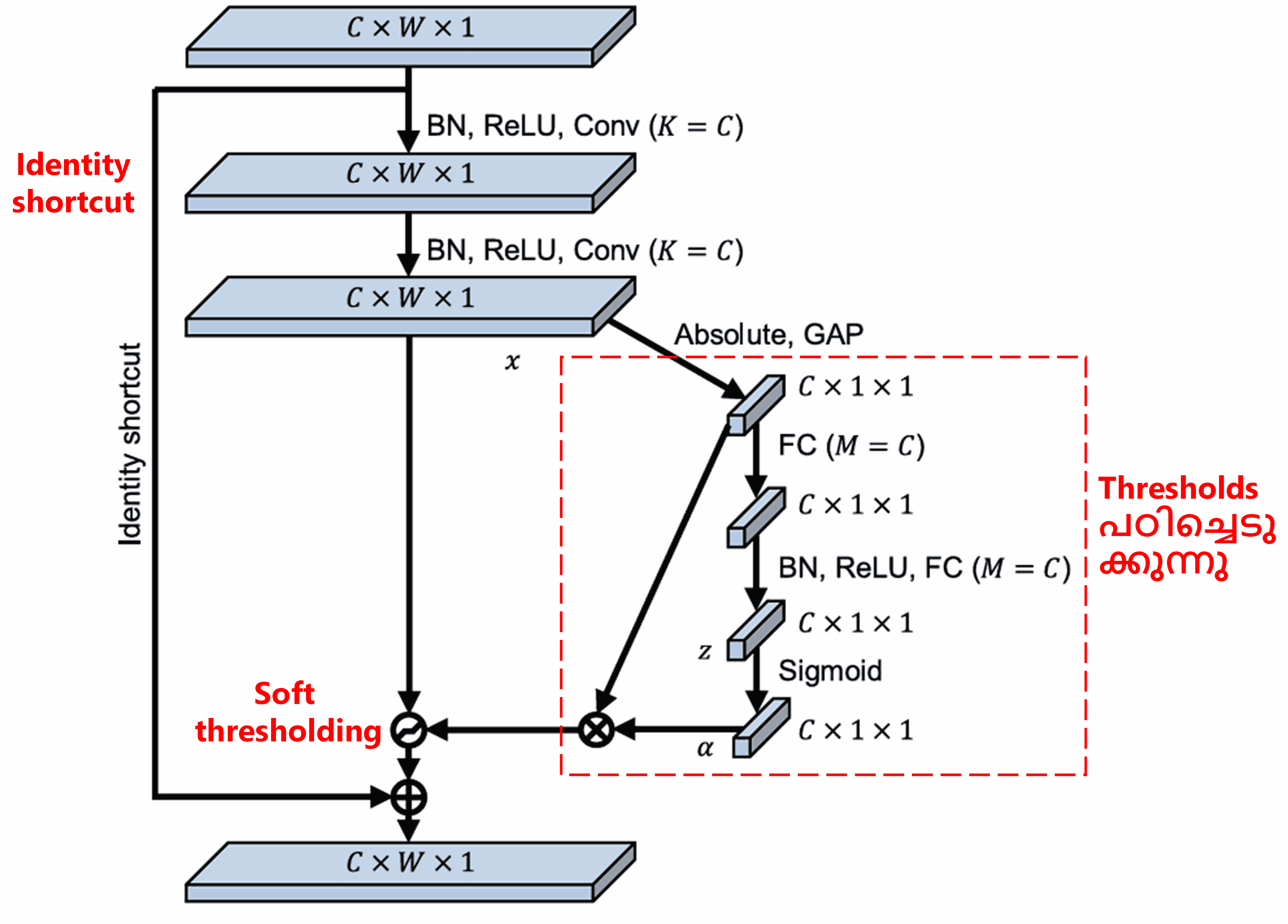
ഈ sub-network-ൽ, ആദ്യം input feature map-ലെ എല്ലാ features-ന്റെയും absolute value കണക്കാക്കുന്നു. പിന്നീട് global average pooling വഴി average ചെയ്ത് ‘A’ എന്ന ഒരു feature ലഭിക്കുന്നു. മറ്റൊരു വഴിയിൽ (path), global average pooling കഴിഞ്ഞ feature map-നെ ഒരു ചെറിയ fully connected network-ലേക്ക് നൽകുന്നു. ഈ fully connected network-ന്റെ അവസാന layer ആയി Sigmoid function ഉപയോഗിക്കുന്നു, ഇത് output-നെ 0-നും 1-നും ഇടയിലുള്ള ഒരു സംഖ്യയായി മാറ്റുന്നു. ഈ co-efficient-നെ ‘α’ (alpha) എന്ന് വിളിക്കാം. അന്തിമമായ threshold എന്നത് α × A ആയിരിക്കും. ചുരുക്കത്തിൽ, threshold എന്നത് 0-നും 1-നും ഇടയിലുള്ള ഒരു സംഖ്യയും feature map-ന്റെ absolute values-ന്റെ average-ഉം തമ്മിലുള്ള ഗുണനഫലമാണ് (product). ഈ രീതി, threshold എപ്പോഴും positive ആണെന്നും, അത് അമിതമായി വലുതല്ലെന്നും ഉറപ്പാക്കുന്നു.
കൂടാതെ, വ്യത്യസ്ത samples-ന് വ്യത്യസ്ത thresholds ആയിരിക്കും ലഭിക്കുക. അതിനാൽ, ഒരു പരിധിവരെ, ഇതിനെ ഒരു പ്രത്യേകതരം attention mechanism ആയി കാണാം: ഇത് current task-മായി ബന്ധമില്ലാത്ത features-നെ ശ്രദ്ധിക്കുകയും (notice), രണ്ട് convolutional layers വഴി അവയെ 0-ന് അടുത്തുള്ള features ആക്കി മാറ്റുകയും, തുടർന്ന് soft thresholding വഴി അവയെ പൂർണ്ണമായും zero ആക്കുകയും ചെയ്യുന്നു. അല്ലെങ്കിൽ, current task-മായി ബന്ധമുള്ള features-നെ ശ്രദ്ധിക്കുകയും, അവയെ 0-ൽ നിന്നും അകലെയുള്ള features ആക്കി മാറ്റി നിലനിർത്തുകയും ചെയ്യുന്നു.
അവസാനമായി, നിശ്ചിത എണ്ണം basic modules, convolutional layers, batch normalization, activation functions, global average pooling, fully connected output layer എന്നിവ stack ചെയ്താണ് പൂർണ്ണമായ Deep Residual Shrinkage Network നിർമ്മിക്കുന്നത്.
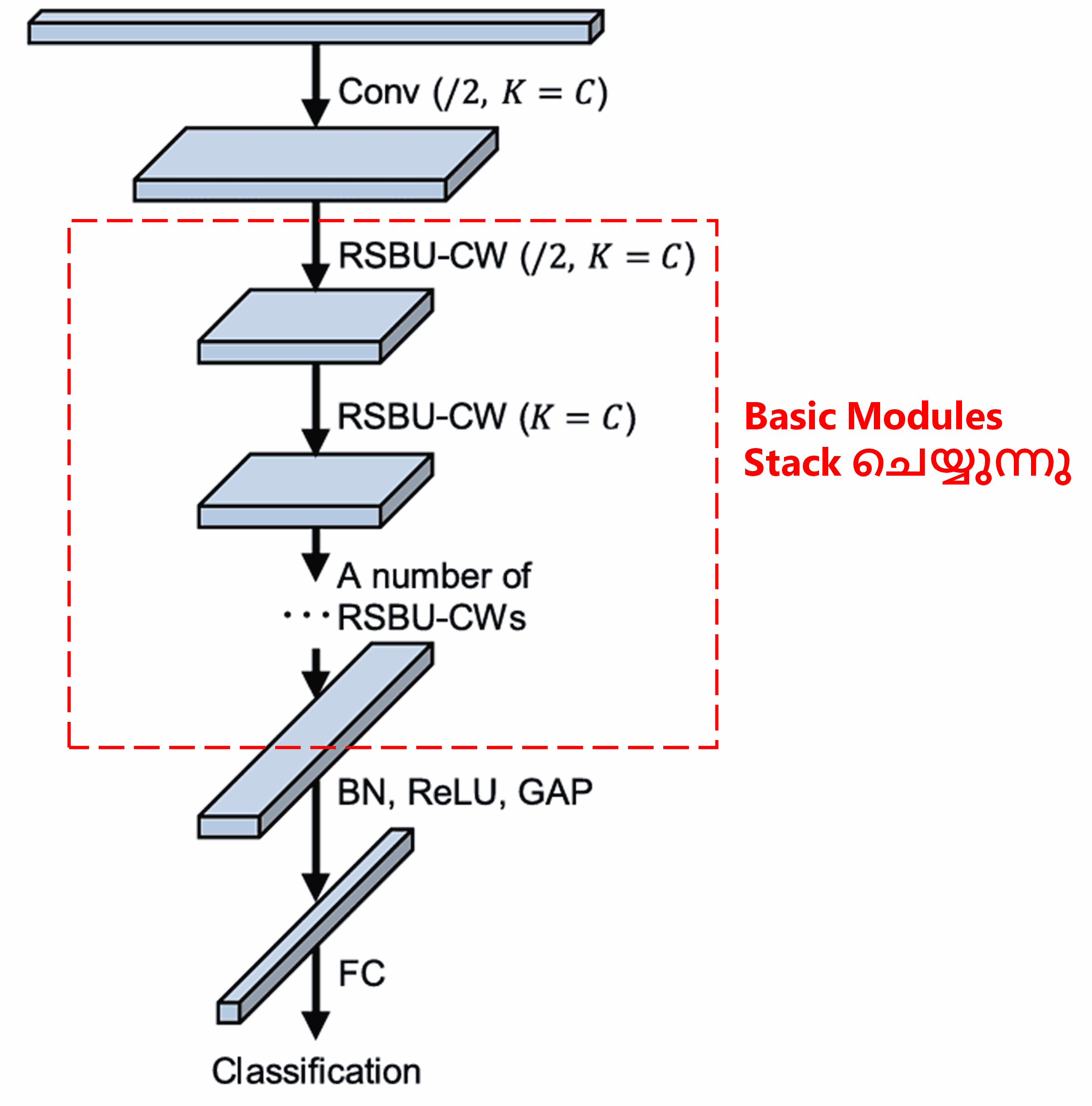
5. Generalization Capability (പൊതുവായ പ്രയോഗക്ഷമത)
യഥാർത്ഥത്തിൽ, Deep Residual Shrinkage Network എന്നത് ഒരു general feature learning method ആണ്. കാരണം, പല feature learning tasks-ലും, samples-ൽ കുറച്ചെങ്കിലും noise-ഉം അനാവശ്യമായ വിവരങ്ങളും (irrelevant information) അടങ്ങിയിട്ടുണ്ടാകും. ഈ noise-ഉം അനാവശ്യ വിവരങ്ങളും feature learning-ന്റെ ഫലത്തെ ബാധിച്ചേക്കാം. ഉദാഹരണത്തിന്:
Image classification ചെയ്യുമ്പോൾ, ഒരു ചിത്രത്തിൽ മറ്റ് പല വസ്തുക്കളും ഉണ്ടെങ്കിൽ, അവയെ “noise” ആയി കണക്കാക്കാം. Deep Residual Shrinkage Network-ന് attention mechanism വഴി ഈ “noise”-നെ ശ്രദ്ധിക്കാനും, soft thresholding വഴി അവയ്ക്ക് തുല്യമായ features-നെ zero ആക്കി മാറ്റാനും സാധിക്കും. ഇത് image classification-ന്റെ accuracy വർദ്ധിപ്പിക്കാൻ സഹായിക്കും.
Speech recognition ചെയ്യുമ്പോൾ, ശബ്ദകോലാഹലമുള്ള സാഹചര്യങ്ങളിൽ (ഉദാഹരണത്തിന് റോഡരികിലോ ഫാക്ടറിയിലോ സംസാരിക്കുമ്പോൾ), Deep Residual Shrinkage Network-ന് speech recognition accuracy വർദ്ധിപ്പിക്കാൻ സാധിച്ചേക്കാം, അല്ലെങ്കിൽ accuracy വർദ്ധിപ്പിക്കാനുള്ള ഒരു പുതിയ വഴി (methodology) ഇത് നൽകുന്നു.
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Academic Impact (അക്കാദമിക് സ്വാധീനം)
Google Scholar-ൽ ഈ പേപ്പറിന് 1400-ലധികം citations ലഭിച്ചിട്ടുണ്ട്.
ലഭ്യമായ കണക്കുകൾ പ്രകാരം, 1000-ലധികം മറ്റ് പഠനങ്ങളിൽ (publications) Deep Residual Shrinkage Networks (DRSN) നേരിട്ട് ഉപയോഗിക്കുകയോ അല്ലെങ്കിൽ മെച്ചപ്പെടുത്തി ഉപയോഗിക്കുകയോ ചെയ്തിട്ടുണ്ട്. Mechanical, Electrical, Computer Vision, Medical, Speech, Text analysis, Radar, Remote Sensing തുടങ്ങി നിരവധി മേഖലകളിൽ ഇത് പ്രയോഗിക്കപ്പെടുന്നു.