Deep Residual Shrinkage Network (DRSN) е подобрена варијанта на Deep Residual Network (ResNet). Во суштина, тоа е интеграција на Deep Residual Network, механизми за внимание (attention mechanisms) и функции за меко прагување (soft thresholding).
До одреден степен, принципот на работа на Deep Residual Shrinkage Network може да се разбере на следниов начин: преку механизмите за внимание се забележуваат неважните карактеристики (features) и преку функциите за меко прагување тие се поставуваат на нула; или поинаку кажано, се забележуваат важните карактеристики и тие се задржуваат. Овој процес ја зајакнува способноста на длабоката невронска мрежа да екстрахира корисни карактеристики од сигнали кои содржат шум.
1. Мотивација за истражувањето
Прво, при класификација на примероци, неизбежно е присуството на шум, како што се Гаусов шум, розов шум, Лапласов шум итн. Пошироко кажано, примероците често содржат информации кои не се поврзани со тековната задача за класификација, и овие информации исто така може да се сфатат како шум. Овој шум може негативно да влијае на резултатите од класификацијата. (Мекото прагување е клучен чекор во многу алгоритми за отстранување на шум од сигнали).
На пример, за време на разговор покрај пат, звукот од разговорот може да се измеша со звуци од автомобилски сирени, тркала и слично. Кога се врши препознавање на говор врз овие звучни сигнали, резултатите неизбежно ќе бидат под влијание на овие звуци. Од перспектива на длабокото учење (Deep Learning), карактеристиките што одговараат на сирените и тркалата треба да бидат елиминирани внатре во длабоката невронска мрежа, за да се избегне нивното влијание врз препознавањето на говорот.
Второ, дури и во истото множеств на примероци (dataset), количината на шум често варира од примерок до примерок. (Ова има сличности со механизмите за внимание; земајќи множество слики како пример, локацијата на целниот објект може да биде различна во секоја слика; механизмот за внимание може да се фокусира на точната локација на целниот објект во секоја поединечна слика).
На пример, кога тренираме класификатор за мачки и кучиња, да земеме 5 слики со ознака „куче“. Првата слика може да содржи куче и глушец, втората куче и гуска, третата куче и кокошка, четвртата куче и магаре, а петтата куче и патка. При тренирање на класификаторот, неизбежно ќе се соочиме со пречки од ирелевантни објекти како глувци, гуски, кокошки, магариња и патки, што предизвикува пад на точноста на класификацијата. Ако можеме да ги забележиме овие ирелевантни објекти и да ги избришеме карактеристиките што им одговараат, можно е да се зголеми точноста на класификаторот за мачки и кучиња.
2. Меко прагување (Soft Thresholding)
Мекото прагување е основен чекор во многу алгоритми за отстранување на шум од сигнали. Тоа ги елиминира карактеристиките чија апсолутна вредност е помала од одреден праг (threshold), а карактеристиките чија апсолутна вредност е поголема од тој праг ги „собира“ (shrink) кон нула. Тоа може да се реализира преку следнава формула:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Изводот на излезот од мекото прагување во однос на влезот е:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Од горното може да се види дека изводот на мекото прагување е или 1 или 0. Ова својство е идентично со она на ReLU активациската функција. Затоа, мекото прагување исто така може да го намали ризикот алгоритмите за длабоко учење да се соочат со проблеми на исчезнување на градиентот (gradient vanishing) и експлозија на градиентот (gradient exploding).
Во функцијата за меко прагување, поставувањето на прагот мора да исполнува два услова: Прво, прагот мора да биде позитивен број; Второ, прагот не смее да биде поголем од максималната вредност на влезниот сигнал, инаку излезот ќе биде целосно нула.
Истовремено, најдобро е прагот да исполнува и трет услов: секој примерок треба да има свој независен праг базиран на сопствената содржина на шум.
Ова е затоа што количината на шум често се разликува кај примероците. На пример, честа е ситуацијата во исто множество податоци, примерокот А да содржи помалку шум, а примерокот Б да содржи повеќе шум. Тогаш, при меко прагување во алгоритам за отстранување шум, примерокот А треба да користи помал праг, додека примерокот Б треба да користи поголем праг. Во длабоките невронски мрежи, иако овие карактеристики и прагови ги губат своите експлицитни физички значења, основната логика останува иста. Тоа значи дека секој примерок треба да има свој независен праг, одреден според сопствената содржина на шум.
3. Механизам за внимание (Attention Mechanism)
Механизмите за внимание се релативно лесни за разбирање во областа на компјутерска визија (computer vision). Визуелниот систем кај животните може брзо да ја скенира целата област, да го открие целниот објект и потоа да го фокусира вниманието на него за да извлече повеќе детали, истовремено потиснувајќи ги ирелевантните информации. За детали, ве молиме погледнете ја литературата за механизми за внимание.
Squeeze-and-Excitation Network (SENet) е релативно нов метод за длабоко учење базиран на механизми за внимание. Кај различни примероци, придонесот на различни канали на карактеристики (feature channels) во задачата за класификација често е различен. SENet користи мала под-мрежа за да добие множество тежини, а потоа ги множи овие тежини со карактеристиките од соодветните канали за да ја прилагоди големината на карактеристиките. Овој процес може да се смета како примена на различно ниво на внимание на различни канали на карактеристики.
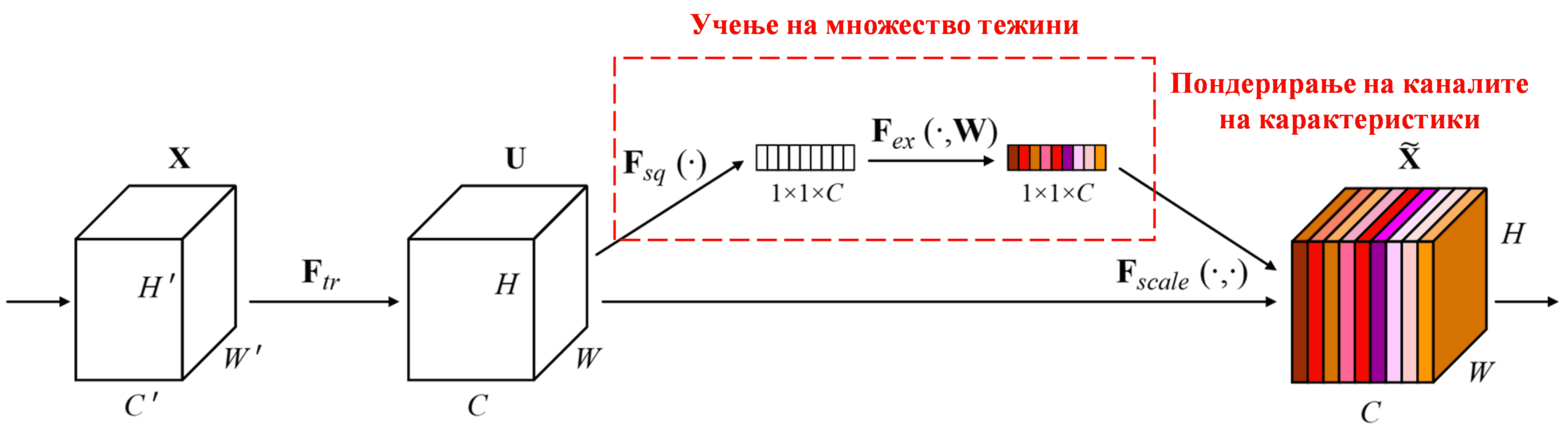
На овој начин, секој примерок ќе има свое независно множество тежини. Со други зборови, тежините за кои било два примерока се различни. Во SENet, специфичната патека за добивање на тежините е „Глобално порамнување (Global Pooling) → Целосно поврзан слој (Fully Connected Layer) → ReLU функција → Целосно поврзан слој → Sigmoid функција“.
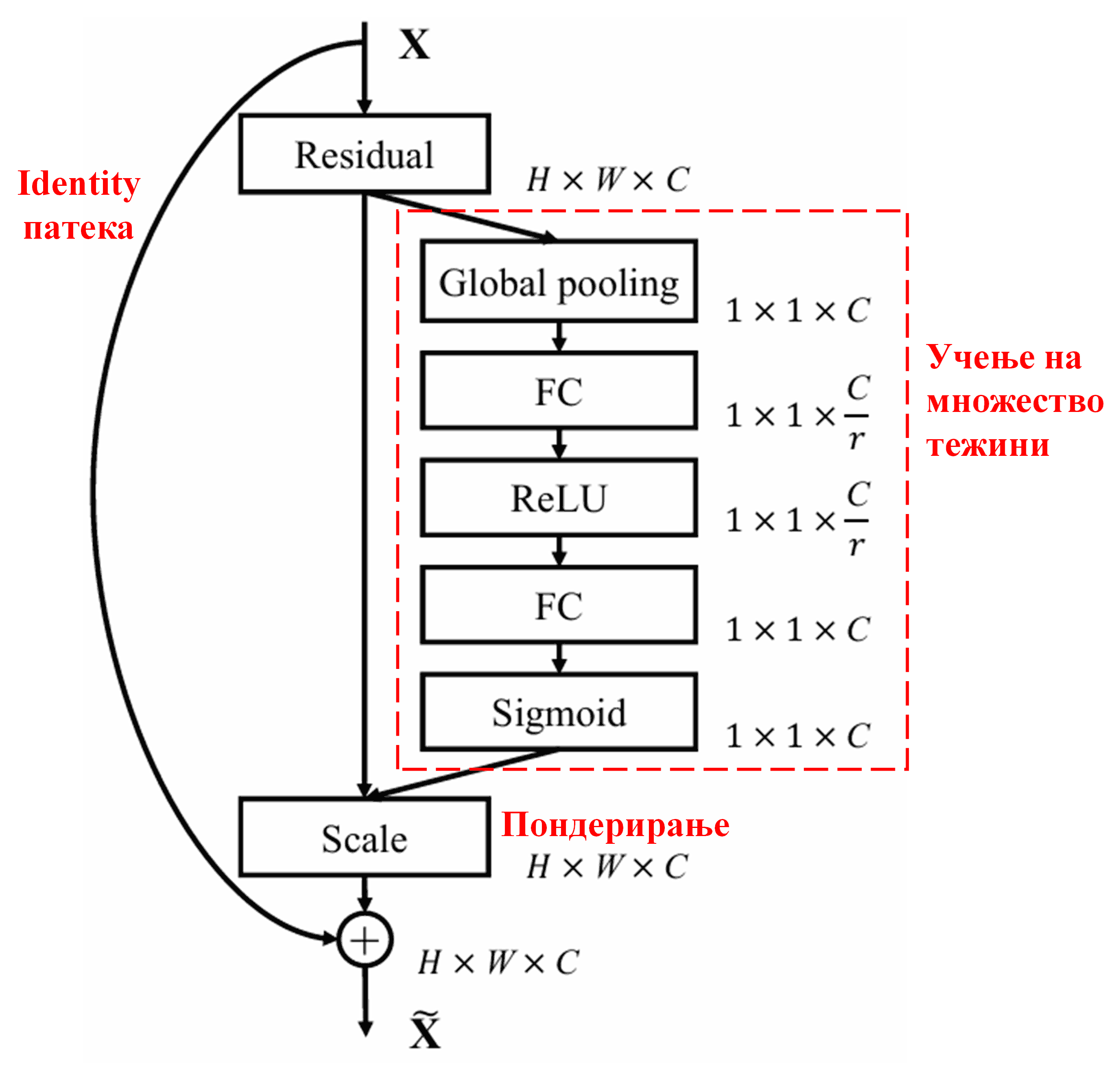
4. Меко прагување под длабок механизам за внимание
Deep Residual Shrinkage Network ја позајмува структурата на под-мрежата од SENet спомената погоре, за да реализира меко прагување под длабок механизам за внимание. Преку под-мрежата (означена во црвената рамка), може да се научи (learn) множество прагови за да се изврши меко прагување на секој канал на карактеристики.
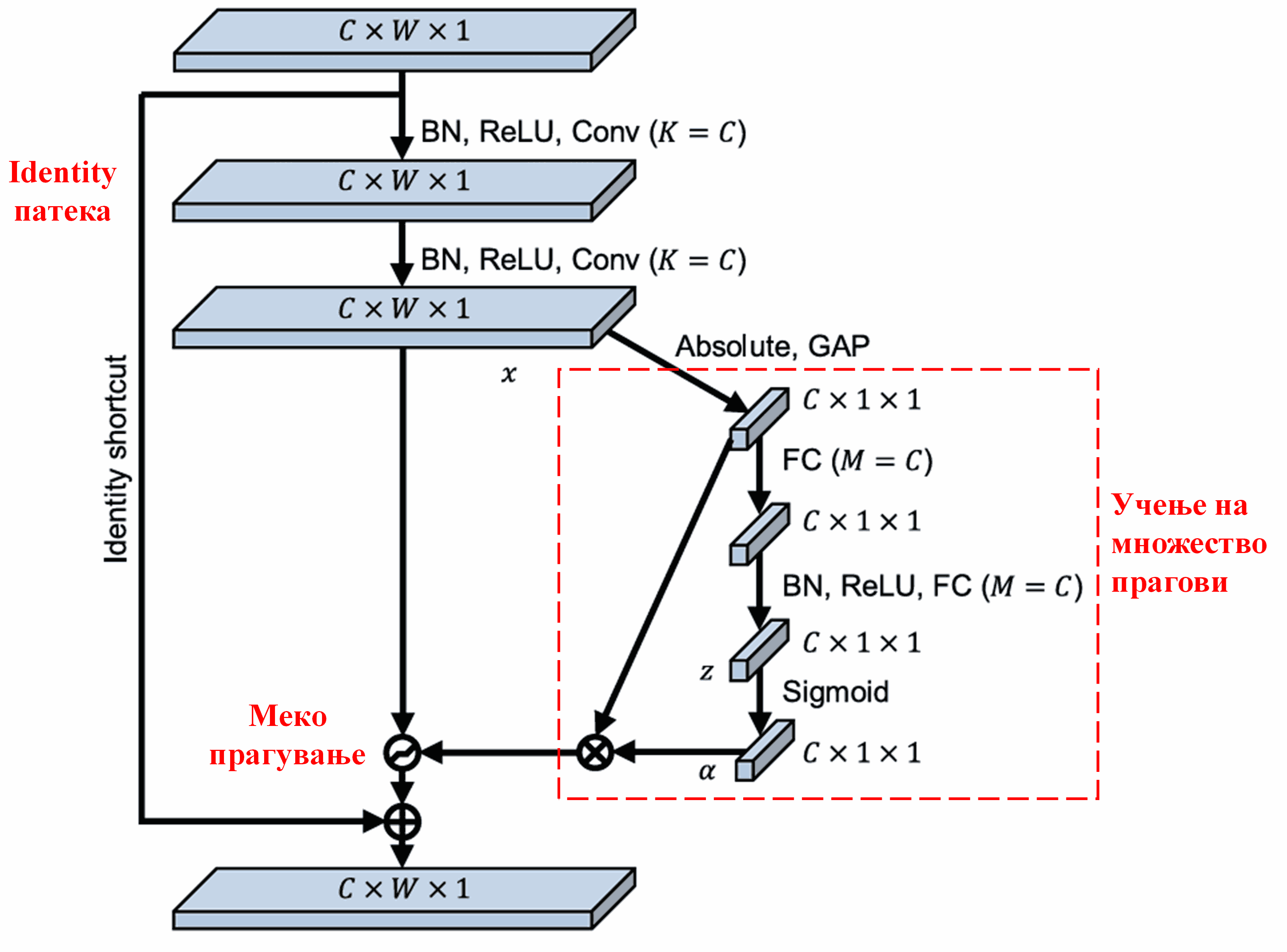
Во оваа под-мрежа, прво се пресметуваат апсолутните вредности на сите карактеристики во влезната мапа на карактеристики (feature map). Потоа, преку глобално просечно порамнување (Global Average Pooling) и усреднување, се добива една карактеристика, означена како A. Во другата патека, мапата на карактеристики по глобалното просечно порамнување се внесува во мала целосно поврзана мрежа (FC network). Оваа мрежа ја користи Sigmoid функцијата како последен слој за да го нормализира излезот помеѓу 0 и 1, добивајќи коефициент означен како α. Крајниот праг може да се изрази како α × A. Според тоа, прагот претставува број помеѓу 0 и 1 помножен со просекот на апсолутните вредности на мапата на карактеристики. Овој начин гарантира дека прагот не само што е позитивен, туку и дека не е премногу голем.
Покрај тоа, различни примероци добиваат различни прагови. Затоа, до одреден степен, ова може да се сфати како специјален механизам за внимание: се забележуваат карактеристиките што се ирелевантни за тековната задача, преку два конволуциски слоја се трансформираат во вредности блиски до 0, и преку меко прагување се поставуваат на нула; или поинаку кажано, се забележуваат карактеристиките релевантни за тековната задача, се трансформираат во вредности далеку од 0 и се задржуваат.
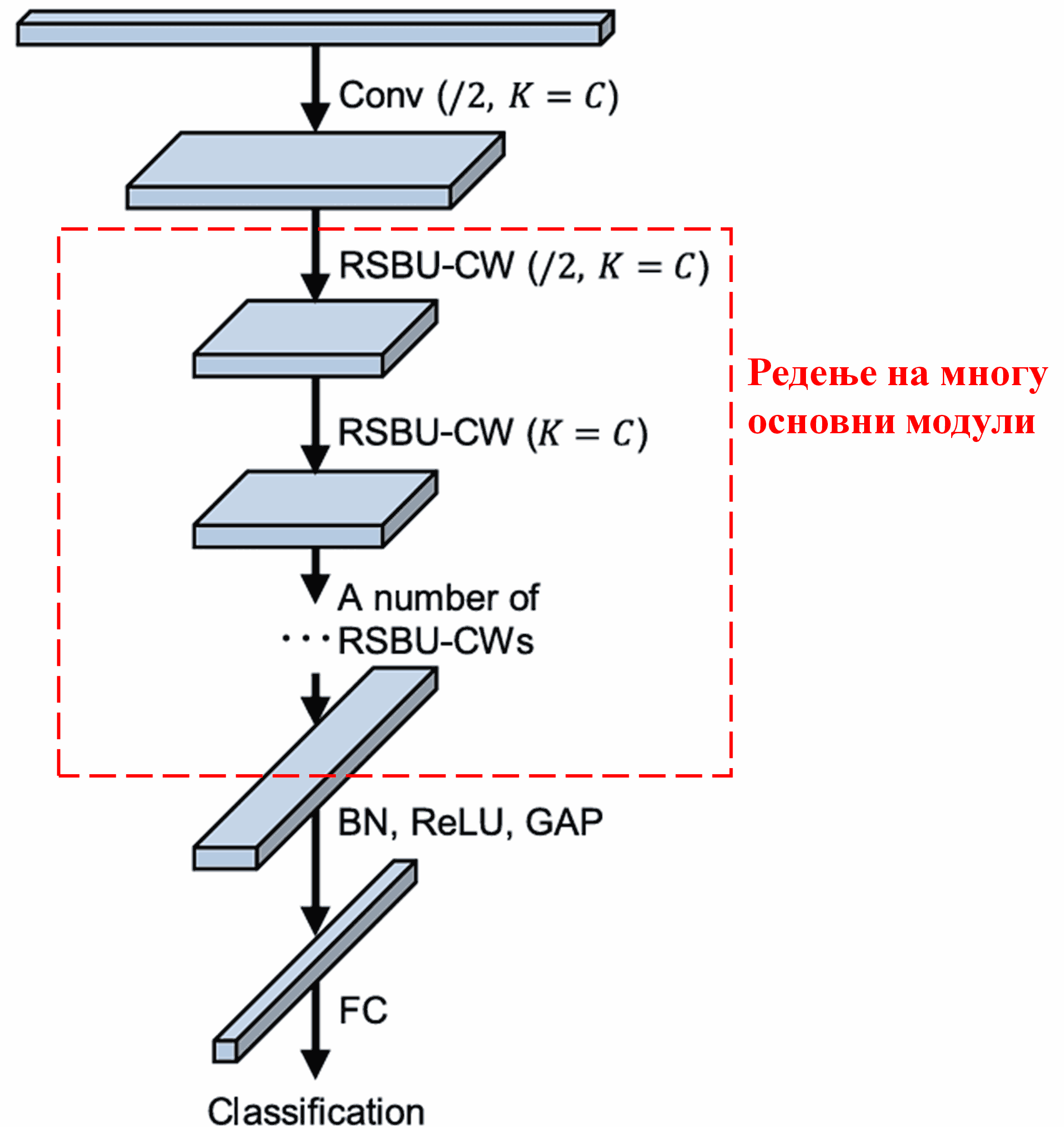
Конечно, со редење на одреден број основни модули заедно со конволуциски слоеви, Batch Normalization, активациски функции, Global Average Pooling и излезни целосно поврзани слоеви, се добива комплетната Deep Residual Shrinkage Network.
5. Универзалност
Deep Residual Shrinkage Network всушност е универзален метод за учење карактеристики. Тоа е затоа што во многу задачи за учење карактеристики, примероците повеќе или помалку содржат шум и ирелевантни информации. Овој шум и ирелевантните информации можат да влијаат на ефектот на учењето карактеристики. На пример:
При класификација на слики, ако сликата истовремено содржи многу други објекти, тие објекти може да се сфатат како „шум“; Deep Residual Shrinkage Network можеби ќе може да го искористи механизмот за внимание за да го забележи овој „шум“, а потоа преку меко прагување да ги постави карактеристиките што одговараат на тој „шум“ на нула, со што може да се зголеми точноста на класификацијата на слики.
При препознавање на говор, особено во пошучни средини, како на пример разговор покрај пат или во фабричка хала, Deep Residual Shrinkage Network можеби ќе може да ја зголеми точноста на препознавањето на говор, или барем да даде идеја за пристап кој може да ја зголеми таа точност.
Референци
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Влијание
Трудот има повеќе од 1400 цитати на Google Scholar.
Според нецелосна статистика, Deep Residual Shrinkage Network е директно применет или подобрен во повеќе од 1000 трудови во бројни области, вклучувајќи машинство, енергетика, компјутерска визија, медицина, говор, текст, радар, далечинско набљудување (remote sensing) итн.