Deep Residual Shrinkage Network (DRSN) yra patobulinta giliojo liekamojo tinklo (Deep Residual Network) versija. Iš esmės tai yra trijų komponentų – liekamųjų tinklų (ResNet), dėmesio mechanizmų ir švelniojo slenksčiavimo (soft thresholding) funkcijų – integracija.
Tam tikra prasme, Deep Residual Shrinkage Network veikimo principą galima suprasti taip: pasitelkiant dėmesio mechanizmą, tinklas „pastebi“ nesvarbius požymius ir, naudodamas švelnųjį slenksčiavimą, paverčia juos nuliais; ir atvirkščiai – pastebėjęs svarbius požymius, juos išlaiko. Šis procesas sustiprina giliojo neuroninio tinklo gebėjimą išgauti naudingus požymius iš signalų, kuriuose gausu triukšmo.
1. Tyrimo motyvacija
Visų pirma, klasifikuojant duomenų pavyzdžius, juose neišvengiamai pasitaiko tam tikro triukšmo, pavyzdžiui, Gauso, rožinio ar Laplaso triukšmo. Plačiąja prasme, duomenų pavyzdžiuose dažnai yra informacijos, kuri nėra susijusi su atliekama klasifikavimo užduotimi – tokią informaciją taip pat galima traktuoti kaip triukšmą. Šis triukšmas gali daryti neigiamą įtaką klasifikavimo rezultatams. (Verta paminėti, kad švelnusis slenksčiavimas yra pagrindinis daugelio signalų triukšmo šalinimo algoritmų žingsnis).
Paimkime pavyzdį: kalbantis šalia judrios gatvės, į pokalbio garsus gali įsimaišyti automobilių signalai, ratų ūžesys ir pan. Atliekant tokio garso signalo kalbos atpažinimą (speech recognition), rezultatams neišvengiamai pakenks šie pašaliniai garsai. Žvelgiant iš giliojo mokymo (Deep Learning) perspektyvos, požymiai, atitinkantys automobilių signalus ir ratų garsus, turėtų būti pašalinti giliojo neuroninio tinklo viduje, kad nepaveiktų galutinio atpažinimo tikslumo.
Antra, net ir tame pačiame duomenų rinkinyje triukšmo lygis skirtinguose pavyzdžiuose dažnai skiriasi. (Tai turi panašumų su dėmesio mechanizmu; pavyzdžiui, vaizdų rinkinyje tikslinis objektas gali būti skirtingose vietose, o dėmesio mechanizmas gali „sufokusuoti“ tinklą į konkrečią objekto vietą kiekviename vaizde atskirai).
Pavyzdžiui, mokant klasifikatorių atskirti kates nuo šunų, turime 5 vaizdus su žyme „šuo“. 1-ajame vaizde gali būti šuo ir pelė, 2-ajame – šuo ir žąsis, 3-ajame – šuo ir višta, 4-ajame – šuo ir asilas, o 5-ajame – šuo ir antis. Mokymo proceso metu klasifikatorius neišvengiamai susidurs su trikdžiais, kuriuos sukelia tokie nesusiję objektai kaip pelės, žąsys, vištos, asilai ir antys, todėl klasifikavimo tikslumas gali sumažėti. Jei sugebėtume „pastebėti“ šiuos nesusijusius objektus ir pašalinti juos atitinkančius požymius (features), galėtume padidinti klasifikatoriaus tikslumą.
2. Švelnusis slenksčiavimas (Soft Thresholding)
Švelnusis slenksčiavimas yra esminis daugelio signalų triukšmo šalinimo algoritmų žingsnis. Jo metu požymiai, kurių absoliuti vertė yra mažesnė už tam tikrą slenkstį, yra pašalinami (paverčiami nuliais), o požymiai, kurių absoliuti vertė viršija šį slenkstį, yra „sutraukiami“ nulio link. Tai galima įgyvendinti naudojant šią formulę:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Švelniojo slenksčiavimo išvestinė įvesties atžvilgiu yra:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Kaip matyti aukščiau, švelniojo slenksčiavimo išvestinė yra arba 1, arba 0. Ši savybė yra identiška ReLU aktyvacijos funkcijai. Todėl švelnusis slenksčiavimas taip pat padeda sumažinti riziką, kad giliojo mokymo algoritmai susidurs su gradiento nykimo (gradient vanishing) ar gradiento sprogimo (gradient exploding) problemomis.
Naudojant švelniojo slenksčiavimo funkciją, slenksčio nustatymas turi atitikti dvi sąlygas: pirma, slenkstis turi būti teigiamas skaičius; antra, slenkstis negali būti didesnis už maksimalią įvesties signalo reikšmę, priešingu atveju visa išvestis bus lygi nuliui.
Taip pat pageidautina, kad slenkstis atitiktų trečią sąlygą: kiekvienas duomenų pavyzdys turėtų turėti savo individualų slenkstį, priklausomai nuo jame esančio triukšmo lygio.
Taip yra todėl, kad triukšmo kiekis pavyzdžiuose dažnai skiriasi. Pavyzdžiui, tame pačiame duomenų rinkinyje pavyzdys A gali turėti mažai triukšmo, o pavyzdys B – daug. Tokiu atveju, atliekant švelnųjį slenksčiavimą, pavyzdžiui A reikėtų taikyti mažesnį slenkstį, o pavyzdžiui B – didesnį. Nors giliuosiuose neuroniniuose tinkluose šie požymiai ir slenksčiai praranda tiesioginę fizikinę prasmę, pagrindinė logika išlieka ta pati. Kitaip tariant, kiekvienas pavyzdys turėtų turėti nepriklausomą slenkstį, nustatytą pagal jo specifinį triukšmo turinį.
3. Dėmesio mechanizmas
Dėmesio mechanizmą (Attention Mechanism) lengviausia suprasti kompiuterinės regos (Computer Vision) kontekste. Gyvūnų regos sistema gali greitai nuskaityti visą plotą, aptikti tikslinį objektą ir sutelkti dėmesį būtent į jį, kad išgautų daugiau detalių, tuo pačiu slopindama nesvarbią informaciją. Išsamesnės informacijos ieškokite literatūroje apie dėmesio mechanizmus.
Squeeze-and-Excitation Network (SENet) yra palyginti naujas giliojo mokymo metodas, naudojantis dėmesio mechanizmą. Skirtinguose pavyzdžiuose skirtingų požymių kanalų (feature channels) indėlis į klasifikavimo užduotį dažnai skiriasi. SENet naudoja nedidelį potinklį (sub-network), kad gautų svorių rinkinį, ir tada padaugina šiuos svorius iš atitinkamų kanalų požymių, taip koreguodamas kiekvieno kanalo požymių dydį. Šį procesą galima laikyti skirtingo stiprumo dėmesio sutelkimu į skirtingus požymių kanalus.
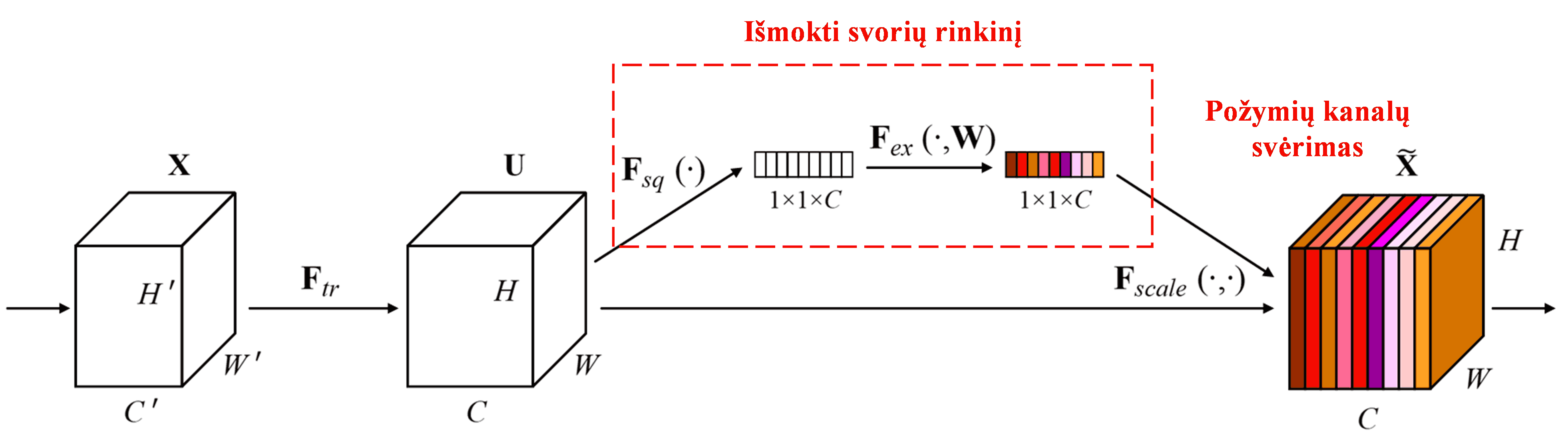
Taikant šį būdą, kiekvienas pavyzdys gauna savo nepriklausomą svorių rinkinį. Kitaip tariant, bet kurių dviejų pavyzdžių svoriai bus skirtingi. SENet architektūroje svoriai gaunami tokiu keliu: „Globalus vidurkinis telkimas (Global Pooling) → Pilnai sujungtas sluoksnis (FC) → ReLU funkcija → Pilnai sujungtas sluoksnis (FC) → Sigmoid funkcija“.
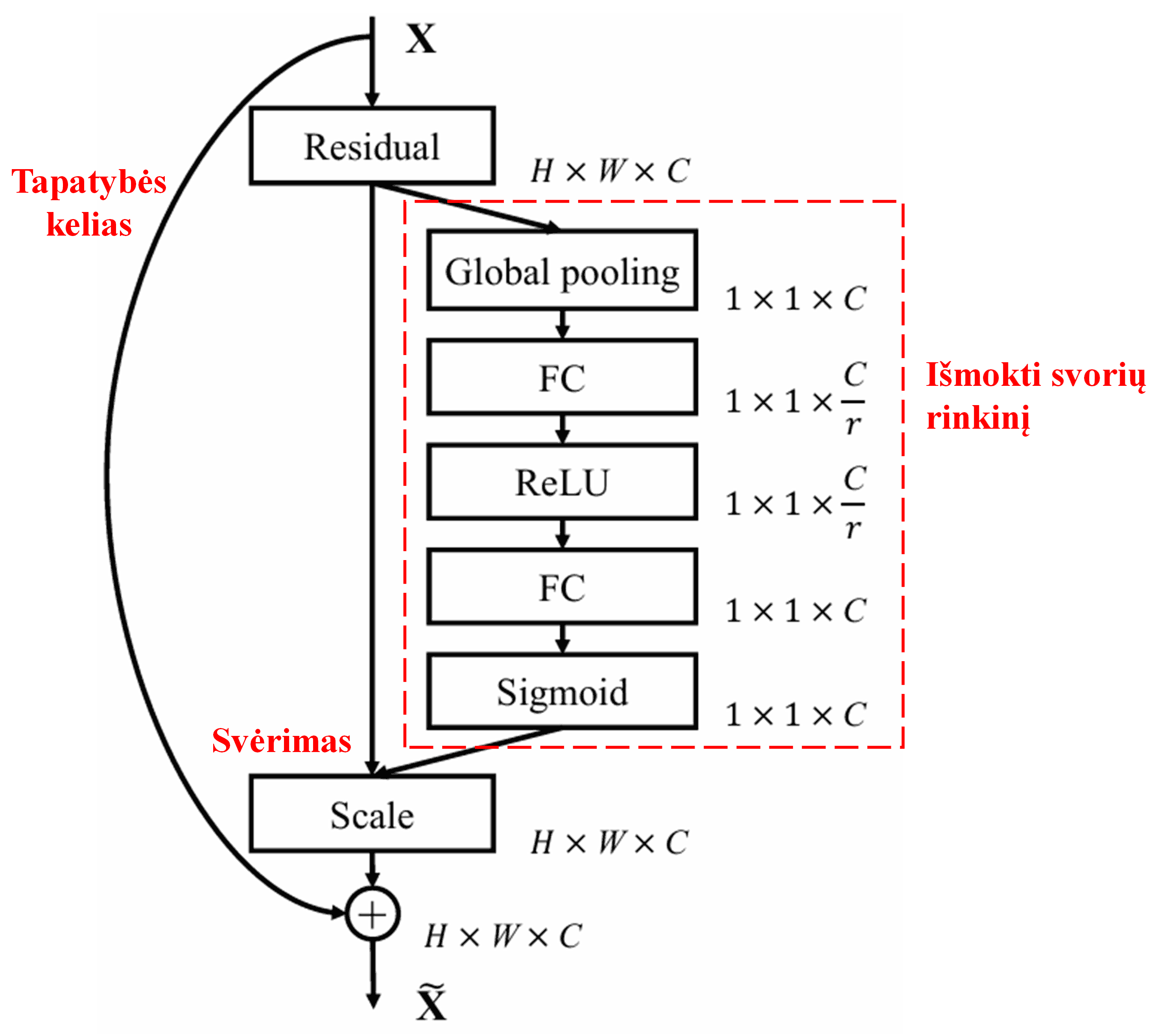
4. Švelnusis slenksčiavimas su giliuoju dėmesio mechanizmu
Deep Residual Shrinkage Network (DRSN) perima minėtą SENet potinklio struktūrą, kad įgyvendintų švelnųjį slenksčiavimą, valdomą giliojo dėmesio mechanizmo. Naudojant specialų potinklį (paveiksle pažymėtą raudonu rėmeliu), galima išmokti slenksčių rinkinį ir pritaikyti švelnųjį slenksčiavimą kiekvienam požymių kanalui atskirai.
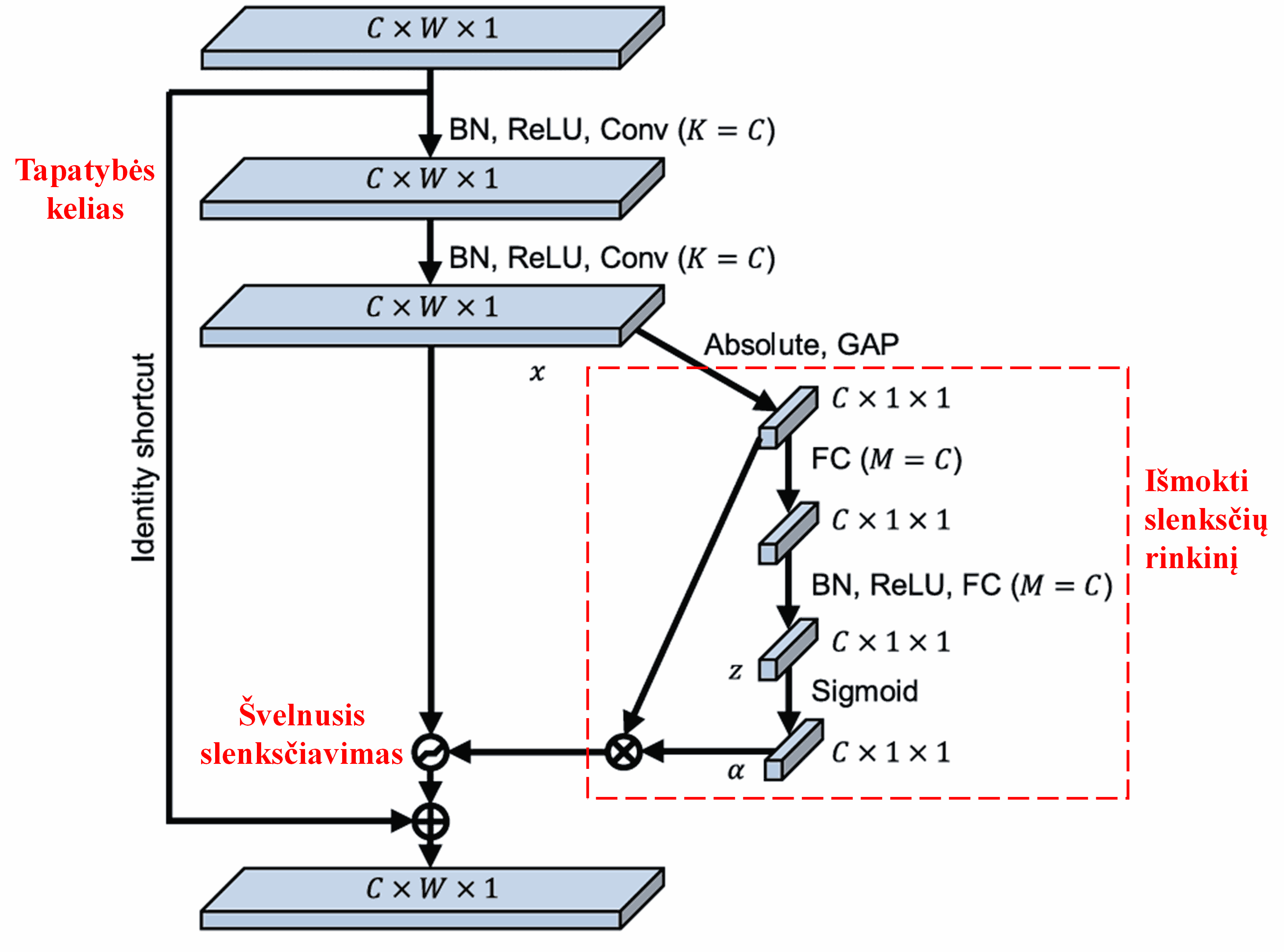
Šiame potinklyje pirmiausia apskaičiuojamos visų įvesties požymių žemėlapio (feature map) reikšmių absoliučios vertės. Tada, pritaikius globalų vidurkinį telkimą (GAP), gaunamas vienas požymis, kurį pažymėkime A. Kitoje atšakoje požymių žemėlapis po globalaus vidurkinio telkimo perduodamas į nedidelį pilnai sujungtą tinklą. Šio tinklo paskutinis sluoksnis naudoja Sigmoid funkciją, kuri normalizuoja išvestį intervale nuo 0 iki 1, taip gaunamas koeficientas, kurį pažymėkime α. Galutinis slenkstis gali būti išreikštas kaip α×A. Taigi, slenkstis yra skaičiaus tarp 0 ir 1 sandauga su požymių žemėlapio absoliučių verčių vidurkiu. Šis metodas užtikrina, kad slenkstis būtų ne tik teigiamas, bet ir ne per didelis.
Be to, skirtingi pavyzdžiai turės skirtingus slenksčius. Todėl tam tikru mastu tai galima suprasti kaip specializuotą dėmesio mechanizmą: tinklas pastebi su esama užduotimi nesusijusius požymius, per du konvoliucinius sluoksnius transformuoja juos į reikšmes, artimas nuliui, ir per švelnųjį slenksčiavimą paverčia tiksliais nuliais; arba atvirkščiai – pastebi su užduotimi susijusius požymius, transformuoja juos į reikšmes, nutolusias nuo nulio, ir juos išsaugo.
Galiausiai, sujungus tam tikrą skaičių šių bazinių modulių kartu su konvoliuciniais sluoksniais, paketų normalizavimu (Batch Normalization), aktyvacijos funkcijomis, globaliu vidurkiniu telkimu ir pilnai sujungtu išvesties sluoksniu, gaunamas pilnas Deep Residual Shrinkage Network.
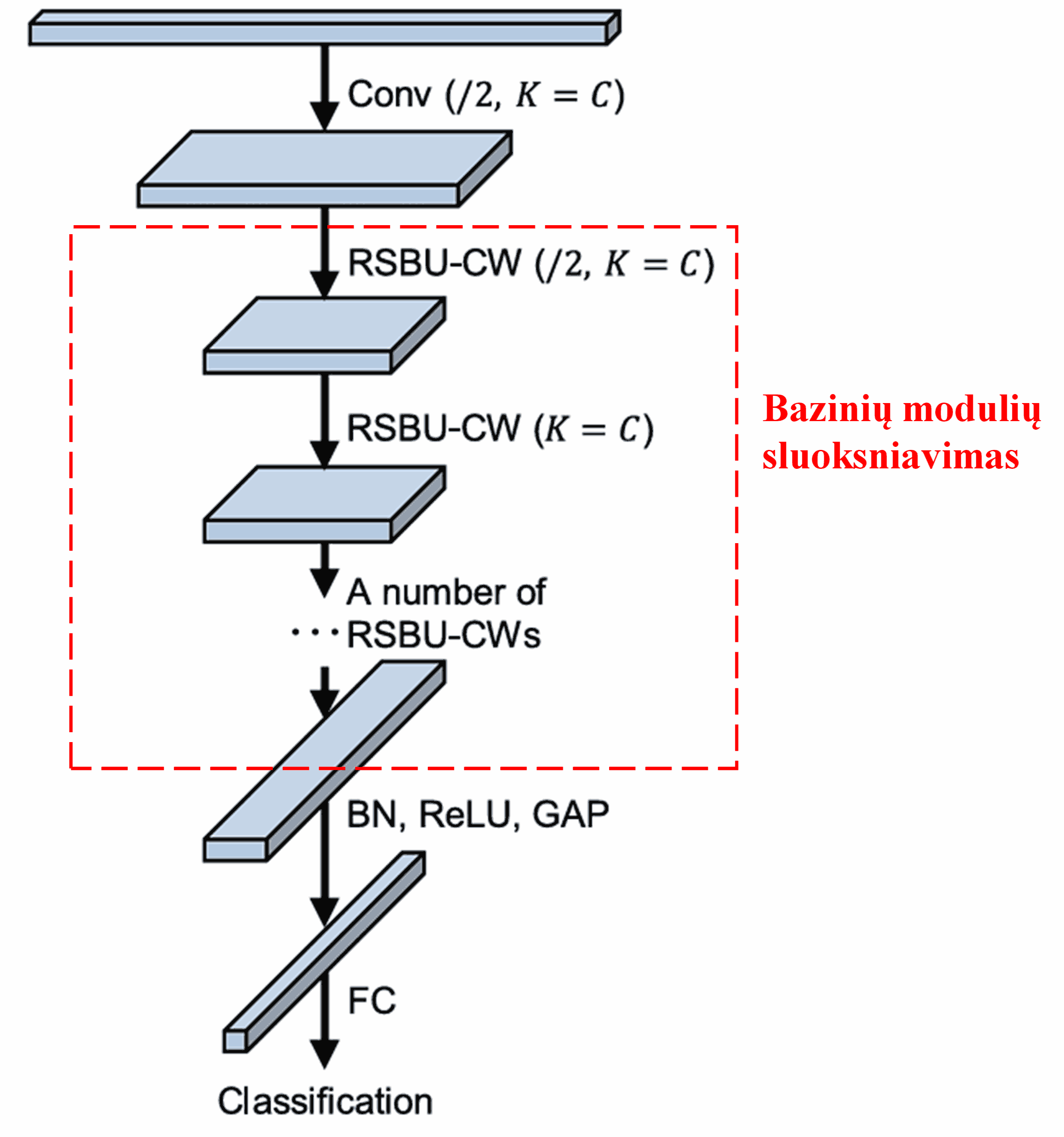
5. Universalumas
Deep Residual Shrinkage Network iš tikrųjų yra universalus požymių mokymosi (feature learning) metodas. Taip yra todėl, kad daugelyje požymių mokymosi užduočių duomenų pavyzdžiai turi šiek tiek triukšmo ar nereikalingos informacijos. Šis triukšmas ir nesusijusi informacija gali paveikti mokymosi kokybę. Pavyzdžiui:
Vaizdų klasifikavime: jei vaizde kartu su pagrindiniu objektu yra daug kitų objektų, juos galima traktuoti kaip „triukšmą“. Deep Residual Shrinkage Network, pasitelkdamas dėmesio mechanizmą, gali pastebėti šį „triukšmą“ ir, naudodamas švelnųjį slenksčiavimą, paversti šį triukšmą atitinkančius požymius nuliais, taip potencialiai padidindamas vaizdų klasifikavimo tikslumą.
Kalbos atpažinime: esant triukšmingai aplinkai, pavyzdžiui, kalbantis prie kelio ar gamyklos ceche, Deep Residual Shrinkage Network gali padidinti kalbos atpažinimo tikslumą arba bent jau pasiūlyti metodologiją, leidžiančią spręsti šią problemą.
Literatūra
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Akademinis poveikis
Šis straipsnis Google Scholar sistemoje cituotas daugiau nei 1400 kartų.
Remiantis nepilna statistika, Deep Residual Shrinkage Network (DRSN) metodas buvo tiesiogiai pritaikytas arba patobulintas ir panaudotas daugiau nei 1000 mokslinių publikacijų įvairiose srityse, įskaitant mechanikos inžineriją, energetiką, kompiuterinę regą, mediciną, kalbos apdorojimą, tekstų analizę, radarų technologijas, nuotolinį stebėjimą ir kt.