Deep Residual Shrinkage Network (DRSN) ແມ່ນເວີຊັນທີ່ຖືກປັບປຸງມາຈາກ Deep Residual Network (ResNet). ໂດຍພື້ນຖານແລ້ວ, ມັນແມ່ນການປະສົມປະສານກັນລະຫວ່າງ Deep Residual Network, Attention Mechanism, ແລະ Soft Thresholding function.
ໃນລະດັບໃດໜຶ່ງ, ຫຼັກການເຮັດວຽກຂອງ Deep Residual Shrinkage Network ສາມາດເຂົ້າໃຈໄດ້ດັ່ງນີ້: ມັນໃຊ້ Attention Mechanism ເພື່ອສັງເກດເບິ່ງ Feature ທີ່ບໍ່ສຳຄັນ, ແລ້ວໃຊ້ຟັງຊັນ Soft Thresholding ປັບຄ່າຂອງພວກມັນໃຫ້ເປັນສູນ; ຫຼື ເວົ້າອີກຢ່າງໜຶ່ງແມ່ນ ໃຊ້ Attention Mechanism ເພື່ອສັງເກດ Feature ທີ່ສຳຄັນ ແລະ ເກັບຮັກສາພວກມັນໄວ້. ຂະບວນການນີ້ຊ່ວຍເພີ່ມຄວາມສາມາດຂອງ Deep Neural Network ໃນການສະກັດເອົາ Feature ທີ່ມີປະໂຫຍດອອກຈາກສັນຍານທີ່ມີ Noise ໄດ້ດີຂຶ້ນ.
1. ແຮງຈູງໃຈໃນການວິໄຈ (Research Motivation)
ທຳອິດ, ເວລາທີ່ເຮົາຈຳແນກປະເພດ (Classify) ຕົວຢ່າງຂໍ້ມູນ, ມັນຫລີກລ່ຽງບໍ່ໄດ້ທີ່ຈະມີ Noise ປົນຢູ່ນຳ, ເຊັ່ນ: Gaussian noise, Pink noise, ແລະ Laplacian noise. ໃນຄວາມໝາຍທີ່ກວ້າງກວ່ານັ້ນ, ຂໍ້ມູນຕົວຢ່າງມັກຈະມີຂໍ້ມູນທີ່ບໍ່ກ່ຽວຂ້ອງກັບວຽກງານການຈຳແນກປະເພດ (Classification Task) ໃນປັດຈຸບັນ, ເຊິ່ງຂໍ້ມູນເຫຼົ່ານີ້ກໍສາມາດເຂົ້າໃຈວ່າເປັນ Noise ໄດ້ເຊັ່ນກັນ. Noise ເຫຼົ່ານີ້ອາດຈະສົ່ງຜົນກະທົບທີ່ບໍ່ດີຕໍ່ປະສິດທິພາບຂອງການຈຳແນກ. (Soft Thresholding ແມ່ນຂັ້ນຕອນສຳຄັນໃນຫຼາຍໆ Algorithm ສຳລັບການກຳຈັດສຽງລົບກວນ ຫຼື Signal Denoising).
ຍົກຕົວຢ່າງ: ເວລາລົມກັນຢູ່ແຄມທາງ, ສຽງລົມກັນນັ້ນອາດຈະມີສຽງແກລົດ ຫຼື ສຽງລໍ້ລົດ ປົນຢູ່ນຳ. ເມື່ອນຳເອົາສັນຍານສຽງເຫຼົ່ານີ້ໄປຜ່ານລະບົບຈົດຈຳສຽງເວົ້າ (Speech Recognition), ຜົນໄດ້ຮັບທີ່ໄດ້ຍ່ອມຖືກລົບກວນຈາກສຽງແກ ແລະ ສຽງລໍ້ລົດຢ່າງຫລີກລ່ຽງບໍ່ໄດ້. ໃນມຸມມອງຂອງ Deep Learning, ບັນດາ Feature ທີ່ກ່ຽວຂ້ອງກັບສຽງແກ ແລະ ສຽງລໍ້ລົດ ຄວນຈະຖືກລຶບອອກໄປພາຍໃນ Deep Neural Network ເພື່ອບໍ່ໃຫ້ມັນສົ່ງຜົນກະທົບຕໍ່ການຈົດຈຳສຽງເວົ້າ.
ອັນທີສອງ, ເຖິງວ່າຈະຢູ່ໃນຊຸດຂໍ້ມູນ (Dataset) ດຽວກັນ, ປະລິມານ Noise ໃນແຕ່ລະຕົວຢ່າງ (Sample) ກໍມັກຈະແຕກຕ່າງກັນ. (ຈຸດນີ້ມີຄວາມຄ້າຍຄືກັນກັບ Attention Mechanism; ຖ້າຍົກຕົວຢ່າງຊຸດຂໍ້ມູນຮູບພາບ, ຕຳແໜ່ງຂອງວັດຖຸເປົ້າໝາຍໃນແຕ່ລະຮູບອາດຈະຢູ່ຕ່າງກັນ; Attention Mechanism ສາມາດໂຟກັດໄປທີ່ຕຳແໜ່ງຂອງວັດຖຸໃນຮູບນັ້ນໆໄດ້).
ຍົກຕົວຢ່າງ: ເມື່ອເຮົາຝຶກສອນ (Train) ໂມເດລ ຈຳແນກ ໝາ ແລະ ແມວ, ສຳລັບຮູບ 5 ຮູບ ທີ່ມີປ້າຍກຳກັບວ່າ “ໝາ”: ຮູບທີ 1 ອາດຈະມີໝາ ແລະ ໜູ, ຮູບທີ 2 ອາດຈະມີໝາ ແລະ ຫ່ານ, ຮູບທີ 3 ອາດຈະມີໝາ ແລະ ໄກ່, ຮູບທີ 4 ອາດຈະມີໝາ ແລະ ລາ, ແລະ ຮູບທີ 5 ອາດຈະມີໝາ ແລະ ເປັດ. ເວລາເຮົາຝຶກສອນໂມເດລ, ເຮົາຈະຖືກລົບກວນຈາກວັດຖຸທີ່ບໍ່ກ່ຽວຂ້ອງ ເຊັ່ນ: ໜູ, ຫ່ານ, ໄກ່, ລາ ແລະ ເປັດ, ເຮັດໃຫ້ຄວາມແມັ້ນຍຳ (Accuracy) ຫຼຸດລົງ. ຖ້າເຮົາສາມາດສັງເກດເຫັນວັດຖຸທີ່ບໍ່ກ່ຽວຂ້ອງເຫຼົ່ານີ້ ແລະ ລຶບ Feature ຂອງພວກມັນຖິ້ມ, ກໍຈະສາມາດເພີ່ມຄວາມແມັ້ນຍຳໃນການຈຳແນກ ໝາ ແລະ ແມວ ໄດ້.
2. Soft Thresholding
Soft Thresholding ແມ່ນຂັ້ນຕອນຫຼັກໃນຫຼາຍໆ Algorithm ສຳລັບການກຳຈັດສຽງລົບກວນ (Signal Denoising). ມັນຈະລຶບ Feature ທີ່ມີຄ່າ Absolute ນ້ອຍກວ່າ Threshold (ຄ່າຂອບເຂດ) ທີ່ກຳນົດໄວ້, ແລະ ຫົດ (Shrink) Feature ທີ່ມີຄ່າ Absolute ໃຫຍ່ກວ່າ Threshold ໃຫ້ຫຍັບເຂົ້າໃກ້ສູນ. ມັນສາມາດຂຽນເປັນສູດໄດ້ດັ່ງນີ້:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]ຜົນຕຳລາ (Derivative) ຂອງ Soft Thresholding ທຽບກັບ Input ແມ່ນ:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]ຈາກສູດຂ້າງເທິງຈະເຫັນວ່າ, ຜົນຕຳລາຂອງ Soft Thresholding ຈະມີຄ່າເປັນ 1 ຫຼື 0 ເທົ່ານັ້ນ. ຄຸນສົມບັດນີ້ຄືກັນກັບ ReLU Activation Function. ດັ່ງນັ້ນ, Soft Thresholding ຈຶ່ງສາມາດຊ່ວຍຫຼຸດຜ່ອນຄວາມສ່ຽງທີ່ Deep Learning Algorithm ຈະພົບບັນຫາ Gradient Vanishing ແລະ Gradient Exploding ໄດ້.
ໃນຟັງຊັນ Soft Thresholding, ການກຳນົດຄ່າ Threshold ຕ້ອງເປັນໄປຕາມ 2 ເງື່ອນໄຂຄື: ທີໜຶ່ງ, Threshold ຕ້ອງເປັນຄ່າບວກ (Positive); ທີສອງ, Threshold ຕ້ອງບໍ່ໃຫຍ່ກວ່າຄ່າສູງສຸດຂອງສັນຍານ Input, ຖ້າບໍ່ດັ່ງນັ້ນ Output ຈະກາຍເປັນສູນທັງໝົດ.
ພ້ອມດຽວກັນນັ້ນ, Threshold ຄວນຈະເປັນໄປຕາມເງື່ອນໄຂທີສາມຄື: ແຕ່ລະ Sample ຄວນຈະມີ Threshold ທີ່ເປັນເອກະລາດຂອງໃຜລາວ ໂດຍອີງຕາມປະລິມານ Noise ຂອງຕົວມັນເອງ.
ເຫດຜົນກໍຄື ປະລິມານ Noise ຂອງແຕ່ລະ Sample ມັກຈະບໍ່ເທົ່າກັນ. ຕົວຢ່າງ: ໃນ Dataset ດຽວກັນ, Sample A ອາດຈະມີ Noise ໜ້ອຍ, ສ່ວນ Sample B ມີ Noise ຫຼາຍ. ດັ່ງນັ້ນ, ເວລາໃຊ້ Soft Thresholding, Sample A ຄວນໃຊ້ Threshold ທີ່ນ້ອຍ, ແລະ Sample B ຄວນໃຊ້ Threshold ທີ່ໃຫຍ່. ໃນ Deep Neural Network, ເຖິງວ່າ Feature ແລະ Threshold ເຫຼົ່ານີ້ຈະບໍ່ມີຄວາມໝາຍທາງຟີຊິກທີ່ຊັດເຈນ, ແຕ່ຫຼັກການພື້ນຖານແມ່ນຄືກັນ. ນັ້ນໝາຍຄວາມວ່າ ແຕ່ລະ Sample ຄວນມີ Threshold ສະເພາະຕົວ ຕາມປະລິມານ Noise ຂອງມັນ.
3. Attention Mechanism
Attention Mechanism ໃນຂົງເຂດ Computer Vision ແມ່ນຂ້ອນຂ້າງເຂົ້າໃຈງ່າຍ. ລະບົບການເບິ່ງເຫັນຂອງສັດ ສາມາດກວາດສາຍຕາເບິ່ງພື້ນທີ່ທັງໝົດໄດ້ຢ່າງໄວວາ ເພື່ອຄົ້ນຫາວັດຖຸເປົ້າໝາຍ, ຈາກນັ້ນກໍຈະໂຟກັດຄວາມສົນໃຈ (Attention) ໄປທີ່ວັດຖຸນັ້ນ ເພື່ອເບິ່ງລາຍລະອຽດເພີ່ມເຕີມ ແລະ ຕັດຂໍ້ມູນທີ່ບໍ່ກ່ຽວຂ້ອງອອກໄປ. ສຳລັບລາຍລະອຽດເພີ່ມເຕີມ, ສາມາດອ່ານໄດ້ຈາກບົດຄວາມກ່ຽວກັບ Attention Mechanism.
Squeeze-and-Excitation Network (SENet) ແມ່ນວິທີການ Deep Learning ແບບໃໝ່ທີ່ໃຊ້ Attention Mechanism. ໃນແຕ່ລະ Sample, ແຕ່ລະ Feature Channel ມັກຈະມີສ່ວນຮ່ວມໃນວຽກງານ Classification ບໍ່ເທົ່າກັນ. SENet ໃຊ້ໂຄງຂ່າຍຍ່ອຍ (Sub-network) ຂະໜາດນ້ອຍ ເພື່ອສ້າງກຸ່ມຂອງ Weight (ນ້ຳໜັກ), ຈາກນັ້ນນຳ Weight ເຫຼົ່ານີ້ໄປຄູນກັບ Feature ຂອງແຕ່ລະ Channel ເພື່ອປັບຂະໜາດຂອງ Feature. ຂະບວນການນີ້ ສາມາດປຽບໄດ້ກັບການໃສ່ໃຈ (Attention) ໃນລະດັບທີ່ຕ່າງກັນ ໃຫ້ກັບແຕ່ລະ Feature Channel.
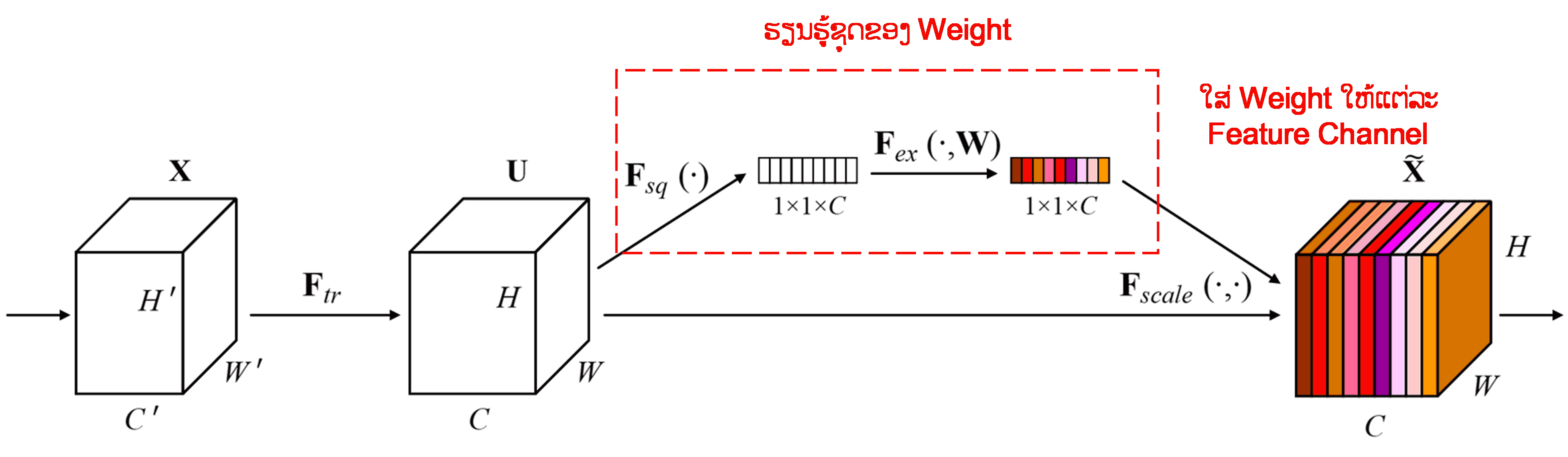
ດ້ວຍວິທີນີ້, ແຕ່ລະ Sample ຈະມີຊຸດ Weight ທີ່ເປັນເອກະລາດຂອງໃຜລາວ. ເວົ້າງ່າຍໆກໍຄື, Sample ສອງອັນໃດໆ ກໍຈະມີ Weight ທີ່ບໍ່ຄືກັນ. ໃນ SENet, ເສັ້ນທາງການສ້າງ Weight ແມ່ນ: “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”.
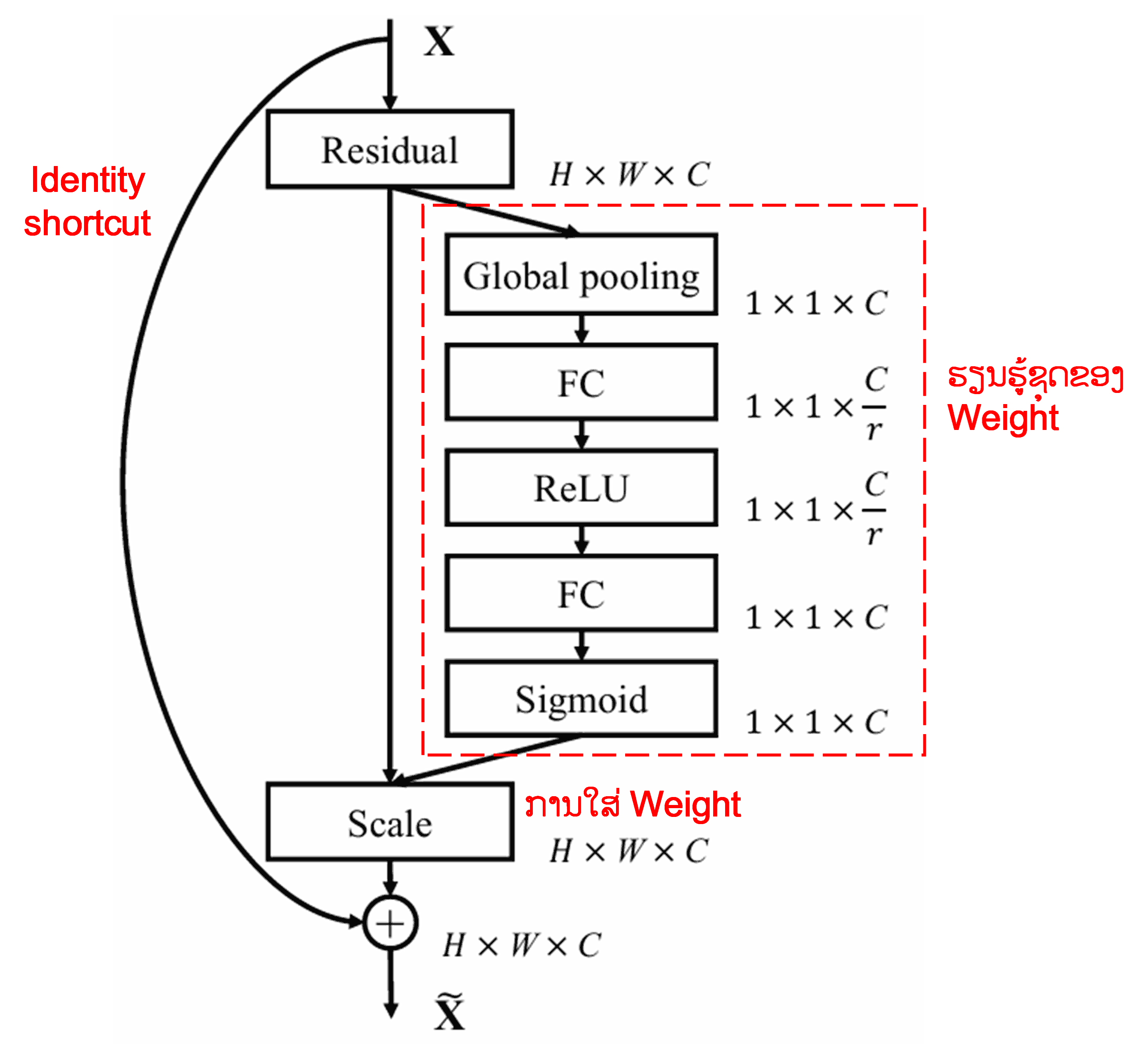
4. Soft Thresholding ພາຍໃຕ້ Deep Attention Mechanism
Deep Residual Shrinkage Network ໄດ້ນຳເອົາໂຄງສ້າງຍ່ອຍຂອງ SENet ທີ່ກ່າວມາຂ້າງເທິງ ມາປະຍຸກໃຊ້ ເພື່ອສ້າງ Soft Thresholding ພາຍໃຕ້ Deep Attention Mechanism. ຜ່ານ Sub-network ທີ່ຢູ່ໃນກອບສີແດງ, ລະບົບຈະສາມາດຮຽນຮູ້ (Learn) ເພື່ອສ້າງຊຸດຂອງ Threshold ສຳລັບນຳໄປໃຊ້ Soft Thresholding ກັບແຕ່ລະ Feature Channel ໄດ້.
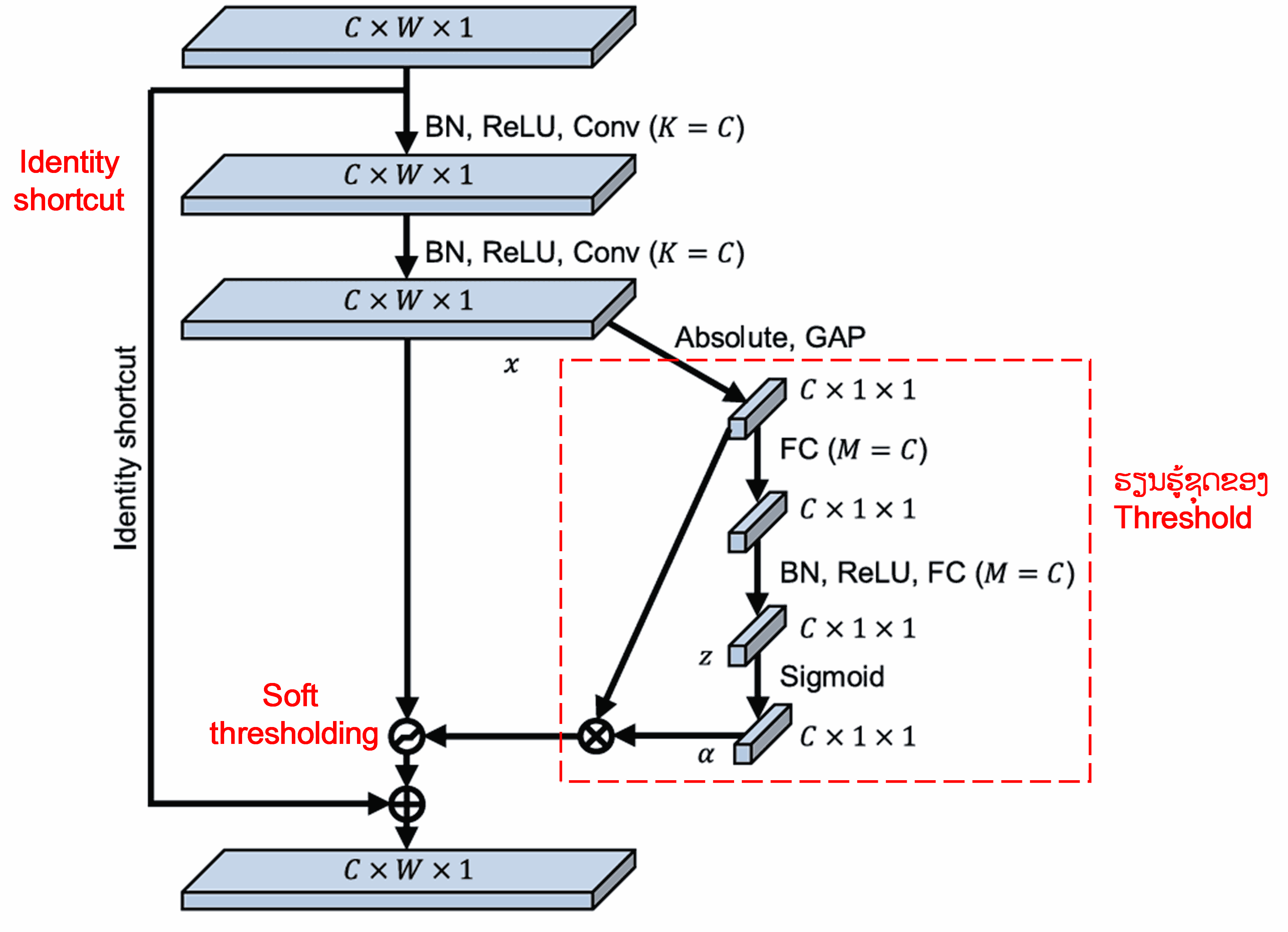
ໃນ Sub-network ນີ້, ທຳອິດລະບົບຈະຄິດໄລ່ຄ່າ Absolute ຂອງທຸກໆ Feature ໃນ Input Feature Map. ຈາກນັ້ນຜ່ານການເຮັດ Global Average Pooling ແລະ ຊອກຫາຄ່າສະເລ່ຍ ເພື່ອໃຫ້ໄດ້ Feature ໂຕໜຶ່ງ ເຊິ່ງໝາຍດ້ວຍ A. ໃນອີກເສັ້ນທາງໜຶ່ງ, Feature Map ທີ່ຜ່ານ Global Average Pooling ແລ້ວ ຈະຖືກສົ່ງເຂົ້າໄປໃນ Fully Connected Network ຂະໜາດນ້ອຍ. Network ນີ້ຈະໃຊ້ຟັງຊັນ Sigmoid ເປັນ Layer ສຸດທ້າຍ ເພື່ອປັບຄ່າ Output ໃຫ້ຢູ່ໃນຊ່ວງ 0 ຫາ 1, ເຊິ່ງຈະໄດ້ຄ່າສຳປະສິດ ໝາຍດ້ວຍ α. ດັ່ງນັ້ນ, Threshold ສຸດທ້າຍຈະມີຄ່າເທົ່າກັບ α×A. ສະຫຼຸບແລ້ວ, Threshold ກໍຄື ຕົວເລກລະຫວ່າງ 0 ຫາ 1 ຄູນກັບ ຄ່າສະເລ່ຍ Absolute ຂອງ Feature Map. ວິທີການນີ້ ບໍ່ພຽງແຕ່ຮັບປະກັນວ່າ Threshold ເປັນຄ່າບວກເທົ່ານັ້ນ, ແຕ່ຍັງຮັບປະກັນວ່າມັນຈະບໍ່ມີຄ່າໃຫຍ່ເກີນໄປ.
ຍິ່ງໄປກວ່ານັ້ນ, Sample ທີ່ຕ່າງກັນ ກໍຈະໄດ້ Threshold ທີ່ຕ່າງກັນ. ດັ່ງນັ້ນ, ໃນລະດັບໃດໜຶ່ງ, ມັນສາມາດເຂົ້າໃຈໄດ້ວ່າເປັນ Attention Mechanism ແບບພິເສດ: ມັນຈະສັງເກດ Feature ທີ່ບໍ່ກ່ຽວຂ້ອງກັບວຽກງານປັດຈຸບັນ, ແລ້ວແປງ Feature ເຫຼົ່ານັ້ນໃຫ້ມີຄ່າໃກ້ຄຽງ 0 ຜ່ານ Convolutional Layer ສອງຊັ້ນ, ແລະ ສຸດທ້າຍກໍໃຊ້ Soft Thresholding ປັບໃຫ້ເປັນສູນ; ຫຼື ໃນທາງກົງກັນຂ້າມ, ມັນຈະສັງເກດ Feature ທີ່ກ່ຽວຂ້ອງ, ແປງໃຫ້ມີຄ່າຫ່າງຈາກ 0, ແລະ ເກັບຮັກສາ Feature ເຫຼົ່ານັ້ນໄວ້.
ສຸດທ້າຍ, ເມື່ອນຳເອົາ Basic Module ເຫຼົ່ານີ້ມາຊ້ອນກັນ (Stack) ຮ່ວມກັບ Convolutional Layer, Batch Normalization, Activation Function, Global Average Pooling ແລະ Fully Connected Output Layer, ເຮົາກໍຈະໄດ້ Deep Residual Shrinkage Network ທີ່ສົມບູນ.
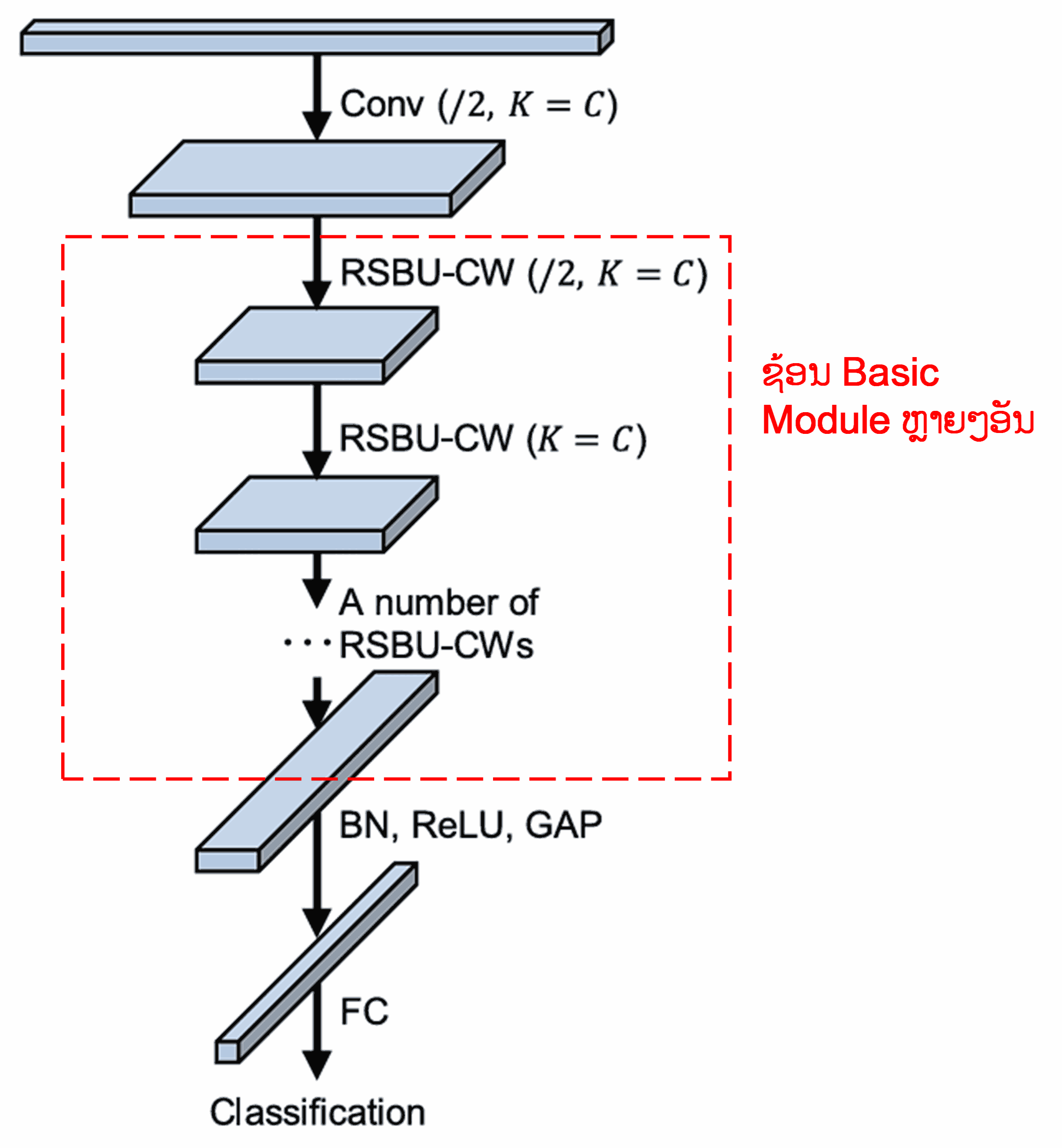
5. ຄວາມສາມາດໃນການນຳໄປໃຊ້ທົ່ວໄປ (Generalization Capability)
Deep Residual Shrinkage Network ໃນຄວາມເປັນຈິງແລ້ວແມ່ນວິທີການຮຽນຮູ້ Feature (Feature Learning) ແບບທົ່ວໄປ. ນັ້ນແມ່ນຍ້ອນວ່າ ໃນຫຼາຍໆວຽກງານ Feature Learning, ຂໍ້ມູນຕົວຢ່າງມັກຈະມີ Noise ຫຼື ຂໍ້ມູນທີ່ບໍ່ກ່ຽວຂ້ອງປົນຢູ່ນຳບໍ່ຫຼາຍກໍໜ້ອຍ. Noise ແລະ ຂໍ້ມູນທີ່ບໍ່ກ່ຽວຂ້ອງເຫຼົ່ານີ້ ອາດສົ່ງຜົນກະທົບຕໍ່ປະສິດທິພາບຂອງການຮຽນຮູ້. ຕົວຢ່າງເຊັ່ນ:
ໃນການຈຳແນກຮູບພາບ (Image Classification), ຖ້າຮູບພາບມີວັດຖຸອື່ນໆປົນຢູ່ນຳຫຼາຍຢ່າງ, ວັດຖຸເຫຼົ່ານັ້ນກໍສາມາດເຂົ້າໃຈວ່າເປັນ “Noise”; Deep Residual Shrinkage Network ອາດຈະສາມາດໃຊ້ Attention Mechanism ເພື່ອສັງເກດເຫັນ “Noise” ເຫຼົ່ານີ້, ແລ້ວໃຊ້ Soft Thresholding ປັບ Feature ທີ່ກ່ຽວຂ້ອງກັບ Noise ໃຫ້ເປັນສູນ, ເຊິ່ງຈະຊ່ວຍເພີ່ມຄວາມແມັ້ນຍຳໃນການຈຳແນກຮູບພາບໄດ້.
ໃນການຈົດຈຳສຽງເວົ້າ (Speech Recognition), ຖ້າຢູ່ໃນສະພາບແວດລ້ອມທີ່ມີສຽງລົບກວນຫຼາຍ ເຊັ່ນ: ລົມກັນຢູ່ແຄມທາງ ຫຼື ໃນໂຮງງານ, Deep Residual Shrinkage Network ອາດຈະຊ່ວຍເພີ່ມຄວາມແມັ້ນຍຳໃນການຈົດຈຳສຽງ, ຫຼື ຢ່າງໜ້ອຍກໍເປັນແນວທາງໜຶ່ງທີ່ສາມາດນຳໄປສູ່ການປັບປຸງຄວາມແມັ້ນຍຳໄດ້.
ເອກະສານອ້າງອີງ (Reference):
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
ຜົນກະທົບທາງວິຊາການ (Academic Impact)
ບົດວິໄຈນີ້ມີການອ້າງອີງ (Citation) ໃນ Google Scholar ຫຼາຍກວ່າ 1400 ຄັ້ງ.
ອີງຕາມສະຖິຕິທີ່ຍັງບໍ່ສົມບູນ, Deep Residual Shrinkage Network ໄດ້ຖືກນຳໄປໃຊ້ໂດຍກົງ ຫຼື ຖືກນຳໄປປັບປຸງເພື່ອໃຊ້ງານໃນຫຼາຍກວ່າ 1000 ບົດວິໄຈ ໃນຫຼາກຫຼາຍຂົງເຂດ ເຊັ່ນ: ວິສະວະກຳເຄື່ອງຈັກ (Mechanical), ໄຟຟ້າ (Electric Power), Computer Vision, ການແພດ, ສຽງ, ຂໍ້ຄວາມ (Text), Radar, ແລະ Remote Sensing.