Deep Residual Shrinkage Network embuvaru Deep Residual Network-na ondu improved version aagide. Idu mukhyavaagi Deep Residual Network, Attention Mechanism mattu Soft Thresholding function-gala integration aagide.
Ondu mattige helbekandare, Deep Residual Shrinkage Network-na working principle annu heege arthamadikollabahudu: Attention mechanism mulaka unimportant features-galannu gamanisi, soft thresholding function balasi avugalannu zero maaduvudu; athava, attention mechanism mulaka important features-galannu gamanisi, avugalannu retain maaduvudu (ulisikolluvudu). Ee riteeyagi, noise iruva signals-galinda useful features-galannu extract maaduva Deep Neural Network-na samarthyavannu idu hechhisuttade.
1. Research Motivation
Modalaneyadaagi, samples-galannu classify maaduvaga, avugalalli Gaussian noise, Pink noise, matthu Laplacian noise-nanta kelavu noise-galu iruvudu sahajavaagide. Innu vyapakavaagi helbekandare, samples-galalli current classification task-ge sambandhavillada mahiti kooda irabahudu, idannu saha noise endu pariganisabahudu. Ee noise-galu classification performance mele ketta parinama birabahudu. (Soft thresholding embuvaru halavu signal denoising algorithm-galalli ondu key step aagide).
Udaharanege, raste badi matukathe aaduvaaga, a matukatheya sound-nalli vahana gala horn shabda, chakra gala shabda ellavu mix aagirabahudu. Ee audio signals-gala mele speech recognition maaduvaga, horn matthu chakra gala shabda dinda result mele parinama beereye beeruttade. Deep Learning drushtiyinda helbekandare, ee horn matthu chakra galige sambandhisida features-galannu Deep Neural Network-nalli delete maadabeku, aaga matra speech recognition mele aaguva tondare tappisabahudu.
Eradaneyadaagi, onde dataset-nalli idda paroo, prathi sample-nallina noise pramana bere bere aagiruttade. (Idu attention mechanism-ge thumba hattiravagide; ondu image dataset annu tegedukondare, prathi image-nalli target object iruva sthala bere bere aagirabahudu; attention mechanism prathi image-nalli target object ellide embudannu gamanisuttade).
Udaharanege, Cat-Dog classifier annu train maaduvaga, “Dog” label iruva 5 image-galannu tegedukollona. 1ne image-nalli nayi jothe ili irabahudu, 2ne image-nalli nayi jothe baatu koli, 3neyaddaralli koli, 4neyaddaralli katthe, matthu 5ne image-nalli nayi jothe baathu (duck) irabahudu. Naavu Cat-Dog classifier train maaduvaga, ee ili, baatu koli, koli, katthe, matthu duck-gala nanta sambandhavillada object-galinda tondare aaguvudu sahaja, idarinda classification accuracy kadime aaguttade. Naavu ee sambandhavillada object-galannu gamanisi, avugalige sambandhisida features-galannu delete madidre, Cat-Dog classifier-na accuracy hechhaguvudu sadhya.
2. Soft Thresholding
Soft Thresholding embudu halavu signal denoising algorithm-gala core step aagide. Idu nirdishta threshold-ginta kadime absolute value iruva features-galannu delete maaduttade, matthu threshold-ginta hechhu absolute value iruva features-galannu zero kadege shrink maaduttade. Idannu ee kelagina formula mulaka implement maadabahudu:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Soft thresholding output matthu input-na derivative heege iruttade:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Mele torisiruva haage, soft thresholding-na derivative 1 athava 0 aagiruttade. Ee gunalakshana ReLU activation function-ge samanavagide. Addarinda, Deep Learning algorithm-galalli gradient vanishing matthu gradient exploding samasyegalannu kadime maadaloo saha soft thresholding sahayakavagide.
Soft thresholding function-nalli, threshold set maaduvaaga eradu condition-galannu palisabeku: Modalaneyadaagi, threshold positive number aagirabeku; Eradaneyadaagi, threshold input signal-na maximum value-ginta doddadaagirabaaradu, illaandre output poorathi zero aagibiduttade.
Adara jothege, threshold moorane condition annu palisuvudu utthama: Prathi sample-gu adara noise pramana (content) ge anugunavaagi, adakke sigo bekaada independent threshold irabeku.
Ekendare, halavu bari sample-galalli noise pramana bere bere aagiruttade. Udaharanege, onde dataset-nalli Sample A-nalli kadime noise irabahudu, Sample B-nalli jasthi noise irabahudu. Haagiruvaga, denoising algorithm-nalli soft thresholding maaduvaga, Sample A-ge chikka threshold matthu Sample B-ge dodda threshold balasabeku. Deep Neural Network-galalli ee features matthu threshold-galige nirdishta physical meaning illadiddaru, moola tarkavantu (logic) onde aagiruttade. Endare, prathi sample-gu adara noise content-ge takkante swantha threshold irabeku.
3. Attention Mechanism
Attention Mechanism annu Computer Vision kshetradalli arthamadikolluvudu sulabha. Prani gala drushti vyavasthe (visual system) ellavannu scan maadi, target object annu huduki, adara mele attention focus maaduttade. Idarinda hecchu details extract maadi, irrelevant mahitiyannu bittubiduttade. Hecchina mahitigaagi attention mechanism-ge sambandhisida lekhana galannu nodi.
Squeeze-and-Excitation Network (SENet) embudu attention mechanism adharita ondu hosadaada Deep Learning method aagide. Bere bere sample-galalli, classification task-ge bere bere feature channels-gala contribution pramana bere bere aagiruttade. SENet ondu sanna sub-network balasi, ondu set weights galannu aaydukolluttade. Nantara ee weights galannu aa channels-gala features jothe multiply maadi, feature-gala maulyavannu adjust maaduttade. Ee process annu, bere bere feature channels-gala mele bere bere pramanada attention koduva kriya endu bhavisabahudu.
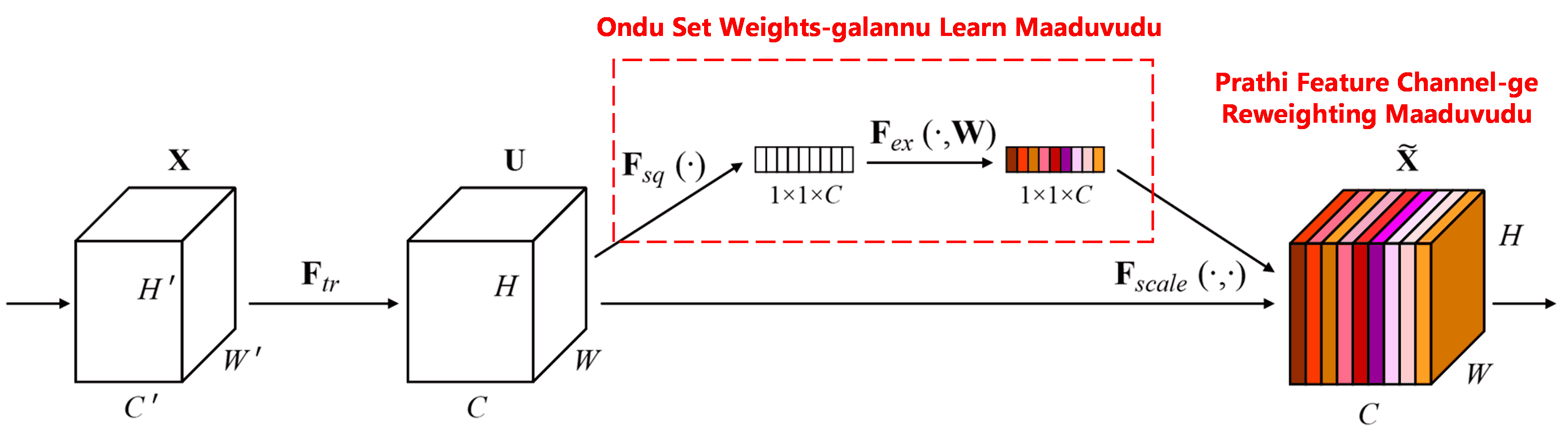
Ee vidhanadalli, prathi sample-gu adara swantha independent weights iruttade. Endare, yavude eradu sample-gala weights bere bere aagiruttade. SENet-nalli weights padeyuva path heege iruttade: “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”.
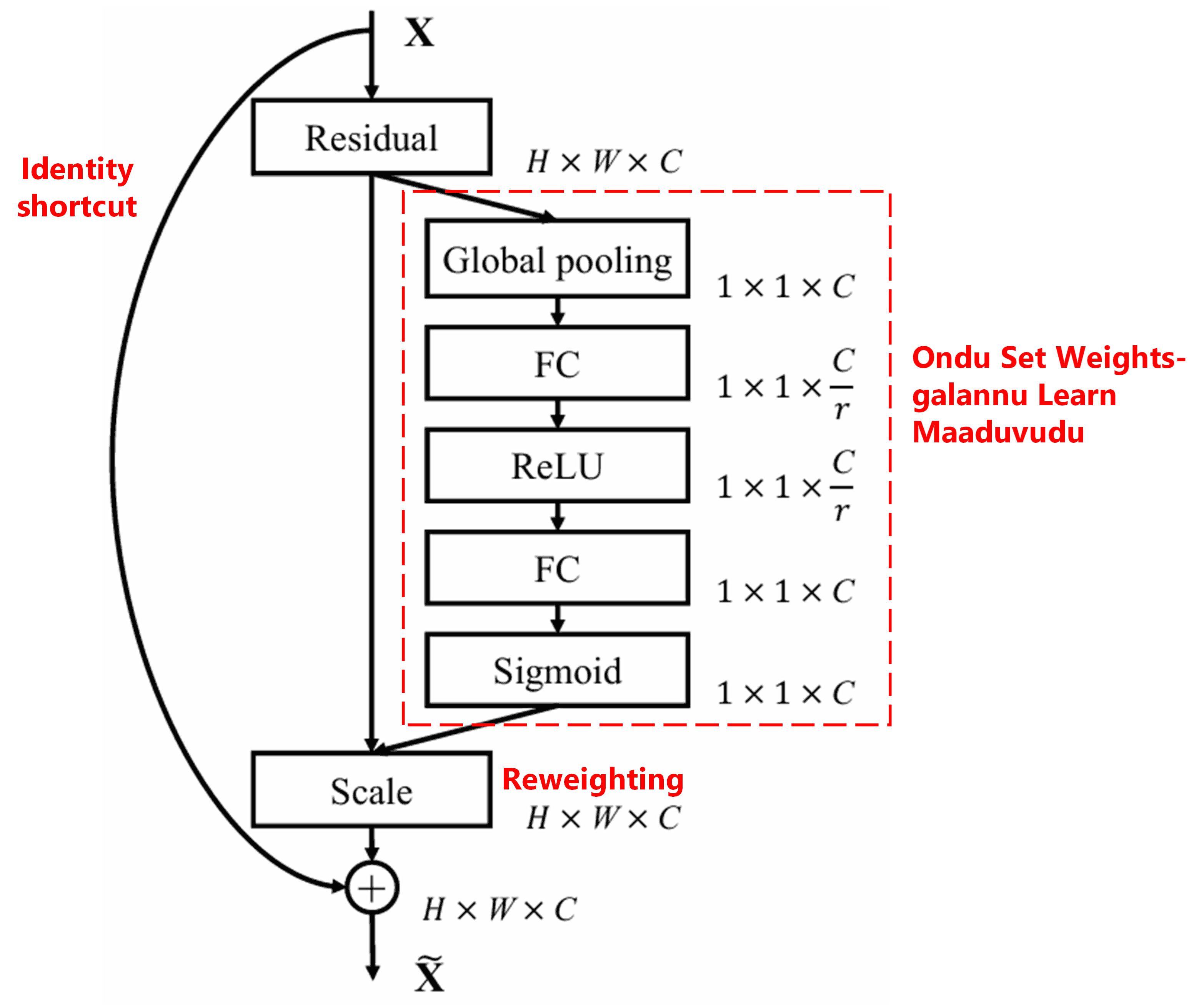
4. Deep Attention Mechanism adiya Soft Thresholding
Deep Residual Shrinkage Network mele helida SENet-na sub-network structure annu balasikondu, Deep Attention Mechanism adiya soft thresholding annu sadhisuttade. Kempu box-nalli torisiruva sub-network mulaka, ondu set thresholds galannu learn maadi, prathi feature channel-ge soft thresholding apply maadabahudu.
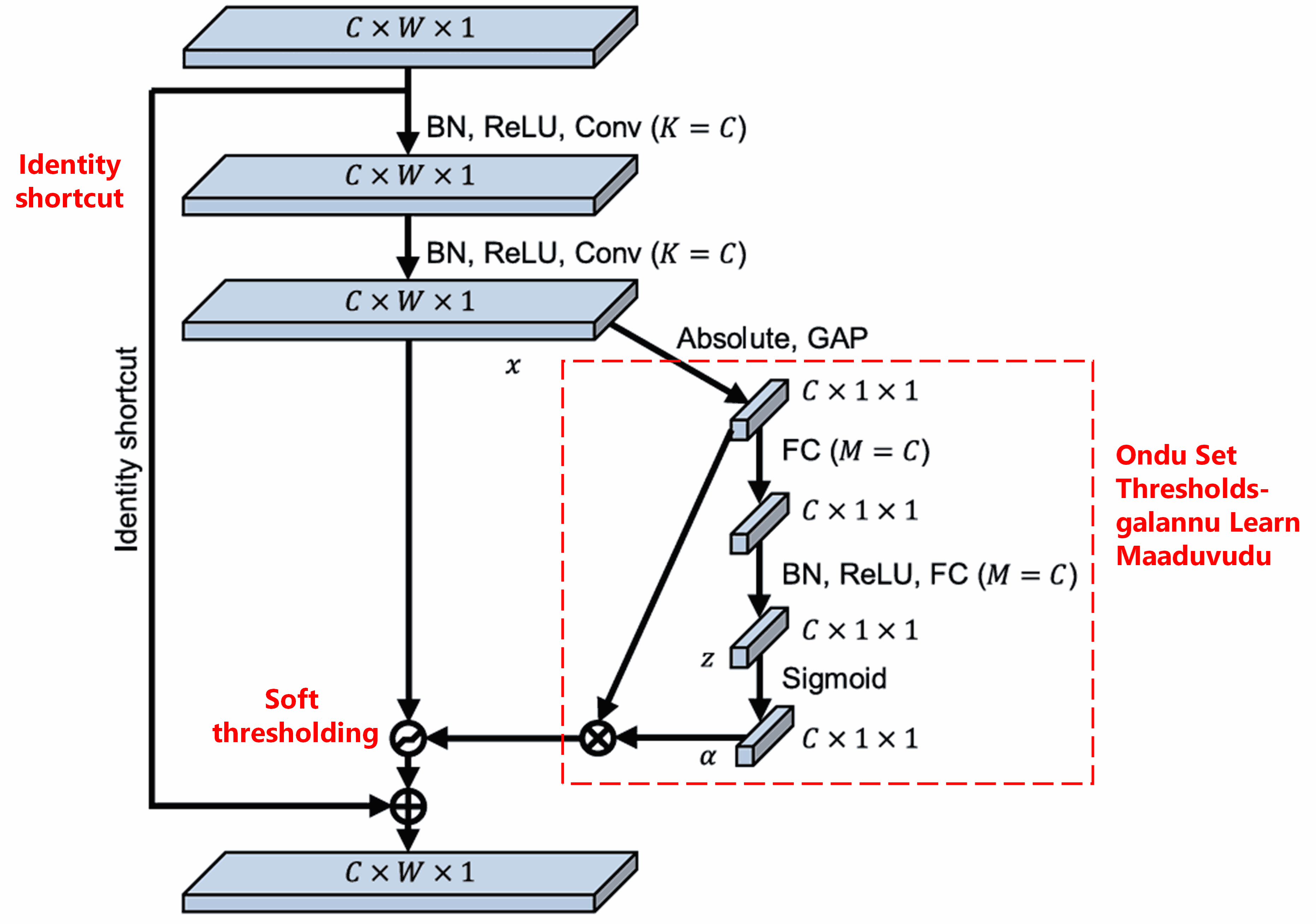
Ee sub-network-nalli, modalu input feature map-na ella features-gala absolute value-galannu calculate maadalaguttade. Nantara Global Average Pooling matthu averaging maadi, ondu feature padeyalaguttade, idannu A endu kareyona. Innondu kade, Global Average Pooling nantara feature map annu ondu sanna Fully Connected Network-ge kalsalaguttade. Ee network-na koneya layer-nalli Sigmoid function iddu, idu output annu 0 matthu 1 ra madhye normalize maadi, ondu coefficient koduttade, idannu α endu kareyona. Final threshold annu α × A endu bariyabahudu. Addarinda, threshold embudu 0 matthu 1 ra madhyina ondu samkhye × feature map-na absolute value-gala average aagiruttade. Ee vidhana threshold positive aagiruvudannu matra alla, adu bahala dodda sankhye aagadiruvudannu khaatri padisuttade.
Matthu, bere bere sample-galige bere bere threshold-galu siguttave. Addarinda, idannu ondu vishesha attention mechanism endu arthamadikollabahudu: Current task-ge sambandhavillada features-galannu gamanisi, eradu convolutional layer-gala mulaka avugalannu 0 ge hattira baruvante maadi, soft thresholding mulaka avugalannu zero maaduvudu; athava, current task-ge sambandhisida features-galannu gamanisi, eradu convolutional layer-gala mulaka avugalannu 0 inda doora hoguvante maadi, avugalannu retain maaduvudu (ulisikolluvudu).
Konege, nirdishta sankhyeya basic module-galu, Convolutional layers, Batch Normalization, Activation function, Global Average Pooling matthu Fully Connected output layer-galannu stack maadidaga sampoorna Deep Residual Shrinkage Network srishti aaguttade.
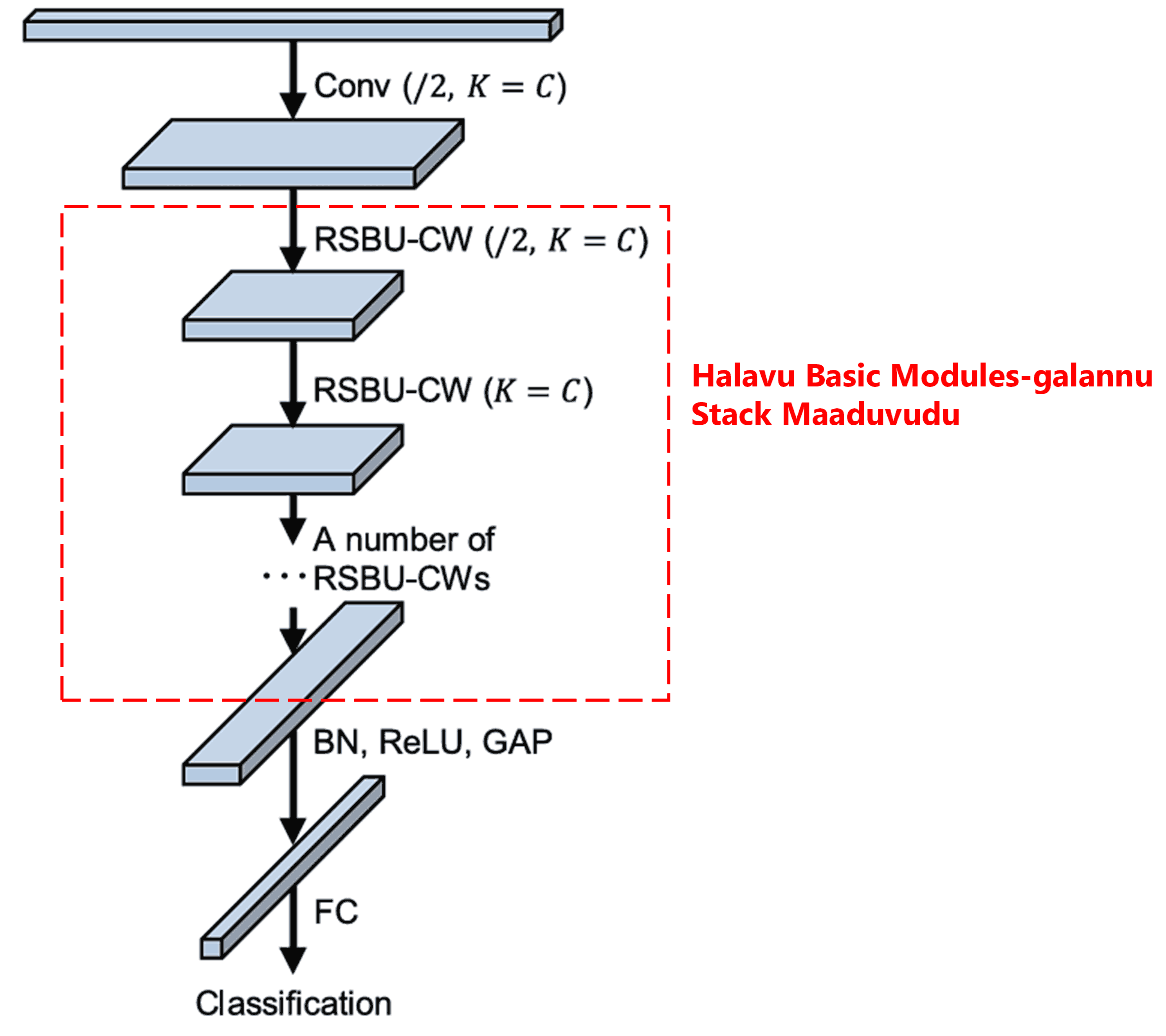
5. Generalization Capability
Deep Residual Shrinkage Network vastavadaagi ondu general feature learning method aagide. Ekendare halavu feature learning tasks-galalli, samples-galalli noise matthu irrelevant mahiti iruvudu sahaja. Ee noise matthu irrelevant mahiti feature learning performance mele prabhava beerabahudu. Udaharanege:
Image classification maaduvaga, ondu image-nalli halavu bere vasthugalu iddare, avugalannu “noise” endu kareyabahudu; Deep Residual Shrinkage Network, attention mechanism balasi ee “noise” annu gamanisi, soft thresholding mulaka ee “noise” ge sambandhisida features-galannu zero maaduvudarinda, image classification accuracy hechhaguva sadhyate ide.
Speech recognition maaduvaga, raste badi athava factory nanta noisy environment-nalli maathanaduvaga, Deep Residual Shrinkage Network speech recognition accuracy-yannu sudharisabahudu, athava accuracy hechhisuva ondu hosa dariyannu torisabahudu.
References
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Academic Impact
Ee paper-ge Google Scholar-nalli 1400 kkum hecchu citations doretive.
Labhyaviruva mahitiya prakara, Deep Residual Shrinkage Network annu 1000 kkum hecchu publications-galalli balasalagide athava improve maadalagide. Idu Mechanical, Electric power, Vision, Medical, Speech, Text, Radar, matthu Remote sensing nanta halavu kshetragallalli prayoga aagide.