Deep Residual Shrinkage Network គឺជាកំណែដែលបានកែលម្អនៃ Deep Residual Network (ResNet)។ តាមពិតទៅ វាគឺជាការរួមបញ្ចូលគ្នានៃ Deep Residual Network, Attention Mechanism និង Soft Thresholding function។
ជាគោលការណ៍ ដំណើរការរបស់ Deep Residual Shrinkage Network អាចយល់បានថា៖ តាមរយៈ Attention Mechanism វាអាចសម្គាល់ features ដែលមិនសំខាន់ ហើយប្រើប្រាស់ Soft Thresholding function ដើម្បីកំណត់តម្លៃពួកវាឱ្យស្មើសូន្យ។ ផ្ទុយទៅវិញ វាសម្គាល់ features ដែលសំខាន់ ហើយរក្សាទុកពួកវា។ ដំណើរការនេះជួយពង្រឹងសមត្ថភាពរបស់ Deep Neural Network ក្នុងការទាញយក features ដែលមានប្រយោជន៍ចេញពី signal ដែលមាន noise។
1. Research Motivation (មូលហេតុនៃការស្រាវជ្រាវ)
ទីមួយ នៅពេលធ្វើ classification លើ sample វាតែងតែជៀសមិនផុតពីការមាន noise មួយចំនួន ដូចជា Gaussian noise, Pink noise, និង Laplacian noise ជាដើម។ និយាយជារួម sample នីមួយៗតែងតែមានព័ត៌មានដែលមិនពាក់ព័ន្ធនឹង classification task បច្ចុប្បន្ន ហើយព័ត៌មានទាំងនេះអាចចាត់ទុកថាជា noise។ Noise ទាំងនេះអាចជះឥទ្ធិពលអាក្រក់ដល់លទ្ធផល classification។ (Soft Thresholding គឺជាជំហានស្នូលមួយនៅក្នុង algorithm កាត់បន្ថយ noise ឬ signal denoising ជាច្រើន)។
ឧទាហរណ៍ នៅពេលជជែកគ្នានៅក្បែរផ្លូវ សំឡេងនៃការជជែកអាចនឹងលាយឡំជាមួយនឹងសំឡេងស៊ីផ្លេឡាន ឬសំឡេងកង់ឡាន។ នៅពេលធ្វើ speech recognition លើ signal សំឡេងទាំងនេះ លទ្ធផលនឹងទទួលរងការរំខានដោយជៀសមិនរួច។ បើមើលពីជ្រុងរបស់ Deep Learning វិញ features ដែលតំណាងឱ្យសំឡេងស៊ីផ្លេនិងសំឡេងកង់ឡានទាំងនោះ គួរតែត្រូវបានលុបបំបាត់ចោលនៅខាងក្នុង Deep Neural Network ដើម្បីជៀសវាងកុំឱ្យប៉ះពាល់ដល់ប្រសិទ្ធភាពនៃ speech recognition។
ទីពីរ សូម្បីតែនៅក្នុង sample set តែមួយ បរិមាណ noise នៃ sample នីមួយៗក៏តែងតែខុសគ្នាដែរ។ (ចំណុចនេះមានភាពស្រដៀងគ្នាទៅនឹង Attention Mechanism។ ឧទាហរណ៍នៅក្នុង image dataset ទីតាំងរបស់វត្ថុគោលដៅនៅក្នុងរូបភាពនីមួយៗអាចខុសគ្នា ហើយ Attention Mechanism អាចផ្តោតទៅលើទីតាំងជាក់លាក់នៃវត្ថុនោះនៅក្នុងរូបភាពនីមួយៗ)។
ឧទាហរណ៍ នៅពេល train model សម្រាប់បែងចែកឆ្កែនិងឆ្មា (cat-and-dog classifier) ចំពោះរូបភាពចំនួន ៥ ដែលមាន label ជា “ឆ្កែ”៖ រូបភាពទី ១ អាចមានឆ្កែនិងកណ្តុរ, រូបភាពទី ២ អាចមានឆ្កែនិងក្ងាន, រូបភាពទី ៣ អាចមានឆ្កែនិងមាន់, រូបភាពទី ៤ អាចមានឆ្កែនិងលា, ហើយរូបភាពទី ៥ អាចមានឆ្កែនិងទា។ នៅពេលយើង train classifier នេះ យើងជៀសមិនផុតពីការរំខានដោយវត្ថុដែលមិនពាក់ព័ន្ធដូចជា កណ្តុរ, ក្ងាន, មាន់, លា, និងទា ដែលធ្វើឱ្យ classification accuracy ធ្លាក់ចុះ។ ប្រសិនបើយើងអាចសម្គាល់ឃើញវត្ថុដែលមិនពាក់ព័ន្ធទាំងនេះ ហើយលុប features របស់ពួកវាចោល នោះយើងនឹងអាចបង្កើន accuracy នៃ model បែងចែកឆ្កែនិងឆ្មាបាន។
2. Soft Thresholding
Soft Thresholding គឺជាជំហានស្នូលនៅក្នុង algorithm កាត់បន្ថយ noise (signal denoising) ជាច្រើន។ វាលុបបំបាត់ features ដែលមាន absolute value តូចជាង threshold ណាមួយ និងធ្វើឱ្យ features ដែលមាន absolute value ធំជាង threshold នេះ “រួញ” (shrink) ខិតទៅរកសូន្យ។ វាអាចអនុវត្តបានតាមរយៈរូបមន្តខាងក្រោម៖
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]ន័យធៀប (derivative) នៃ output របស់ Soft Thresholding ធៀបនឹង input គឺ៖
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]ដូចដែលបានបង្ហាញខាងលើ derivative របស់ Soft Thresholding គឺស្មើ 1 ឬ 0។ លក្ខណៈសម្បត្តិនេះគឺដូចគ្នាទៅនឹង ReLU activation function ដែរ។ ដូច្នេះ Soft Thresholding ក៏អាចកាត់បន្ថយហានិភ័យដែល Deep Learning algorithm ជួបប្រទះបញ្ហា gradient vanishing និង gradient exploding ផងដែរ។
នៅក្នុង Soft Thresholding function ការកំណត់តម្លៃ threshold ត្រូវតែគោរពតាមលក្ខខណ្ឌពីរ៖ ទីមួយ threshold ត្រូវតែជាចំនួនវិជ្ជមាន។ ទីពីរ threshold មិនត្រូវធំជាងតម្លៃអតិបរមារបស់ input signal ឡើយ បើមិនដូច្នេះទេ output នឹងស្មើសូន្យទាំងអស់។
ទន្ទឹមនឹងនេះ threshold គួរតែគោរពតាមលក្ខខណ្ឌទីបីផងដែរ៖ sample នីមួយៗគួរតែមាន threshold ផ្ទាល់ខ្លួន ដោយផ្អែកលើកម្រិត noise របស់វា។
នេះគឺដោយសារតែបរិមាណ noise តែងតែមានភាពខុសគ្នារវាង sample នីមួយៗ។ ឧទាហរណ៍ នៅក្នុង sample set តែមួយ វាជារឿងធម្មតាទេដែល Sample A មាន noise តិច រីឯ Sample B មាន noise ច្រើន។ ដូច្នេះ នៅពេលអនុវត្ត Soft Thresholding នៅក្នុង algorithm កាត់បន្ថយ noise, Sample A គួរតែប្រើប្រាស់ threshold តូច រីឯ Sample B គួរតែប្រើប្រាស់ threshold ធំ។ នៅក្នុង Deep Neural Network ទោះបីជា features និង threshold ទាំងនេះលែងមាននិយមន័យរូបវន្តច្បាស់លាស់ដូចមុនក៏ដោយ ប៉ុន្តែតក្កវិជ្ជាមូលដ្ឋានគឺនៅតែដូចគ្នា។ ពោលគឺ sample នីមួយៗគួរតែមាន threshold ឯករាជ្យរៀងៗខ្លួនដែលកំណត់ដោយកម្រិត noise ជាក់លាក់របស់វា។
3. Attention Mechanism
Attention Mechanism គឺងាយស្រួលយល់នៅក្នុងវិស័យ Computer Vision។ ប្រព័ន្ធចក្ខុវិស័យរបស់សត្វអាចស្កេនមើលតំបន់ទាំងមូលយ៉ាងរហ័ស ដើម្បីស្វែងរកវត្ថុគោលដៅ ហើយបន្ទាប់មកផ្តោតការយកចិត្តទុកដាក់ (attention) ទៅលើវត្ថុនោះដើម្បីទាញយកព័ត៌មានលម្អិតបន្ថែម ដោយមិនខ្វល់ពីព័ត៌មានដែលមិនពាក់ព័ន្ធ។ សូមស្វែងរកអត្ថបទអំពី Attention Mechanism សម្រាប់ព័ត៌មានលម្អិត។
Squeeze-and-Excitation Network (SENet) គឺជាវិធីសាស្ត្រ Deep Learning ថ្មីមួយដែលប្រើប្រាស់ Attention Mechanism។ នៅក្នុង sample ផ្សេងៗគ្នា features channel នីមួយៗតែងតែរួមចំណែកក្នុងកម្រិតខុសៗគ្នាចំពោះ classification task។ SENet ប្រើប្រាស់ sub-network តូចមួយដើម្បីទទួលបាន weights មួយសំណុំ ហើយបន្ទាប់មកយក weights ទាំងនោះទៅគុណនឹង features នៃ channel នីមួយៗដើម្បីកែតម្រូវទំហំ (magnitude) នៃ features ទាំងនោះ។ ដំណើរការនេះអាចចាត់ទុកថាជាការផ្តល់កម្រិត attention ផ្សេងៗគ្នាទៅលើ features channel នីមួយៗ។
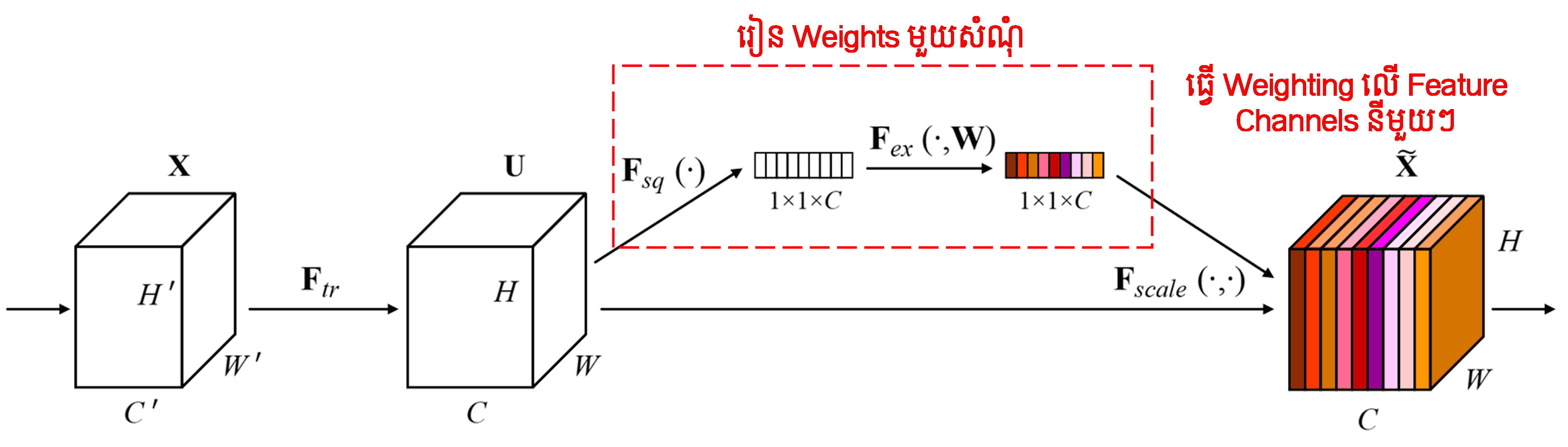
នៅក្នុងវិធីសាស្ត្រនេះ sample នីមួយៗនឹងមានសំណុំ weights ផ្ទាល់ខ្លួន។ មានន័យថា weights សម្រាប់ sample ពីរផ្សេងគ្នាគឺមិនដូចគ្នាទេ។ នៅក្នុង SENet ផ្លូវសម្រាប់ទទួលបាន weights គឺ “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”។
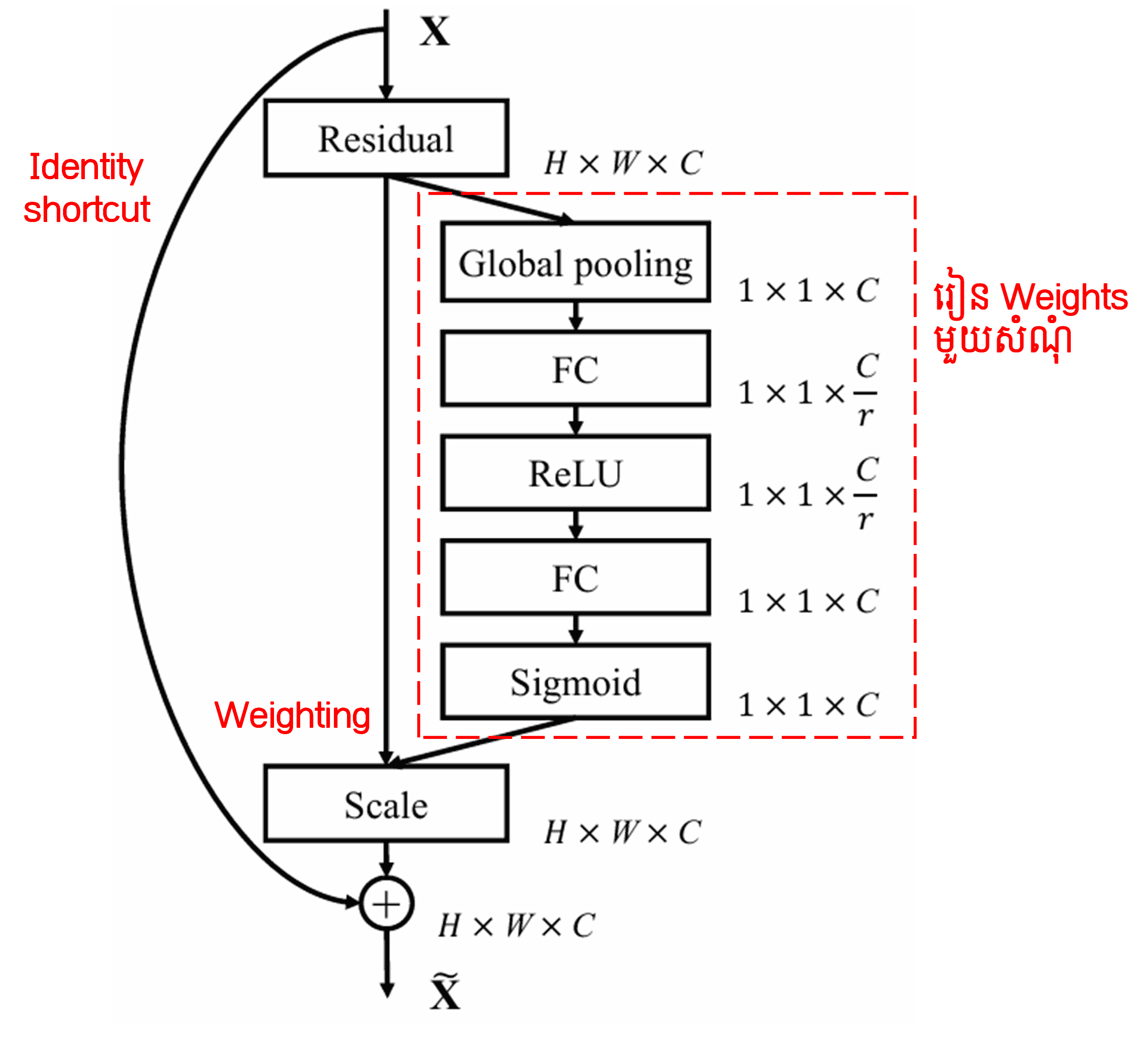
4. Soft Thresholding with Deep Attention Mechanism
Deep Residual Shrinkage Network យកគំរូតាមរចនាសម្ព័ន្ធ sub-network របស់ SENet ខាងលើ ដើម្បីអនុវត្ត Soft Thresholding ក្រោមយន្តការ Deep Attention Mechanism។ តាមរយៈ sub-network (ដែលបង្ហាញនៅក្នុងប្រអប់ក្រហម) យើងអាចរៀនបង្កើត threshold មួយសំណុំ ដើម្បីធ្វើ Soft Thresholding ទៅលើ features channel នីមួយៗ។
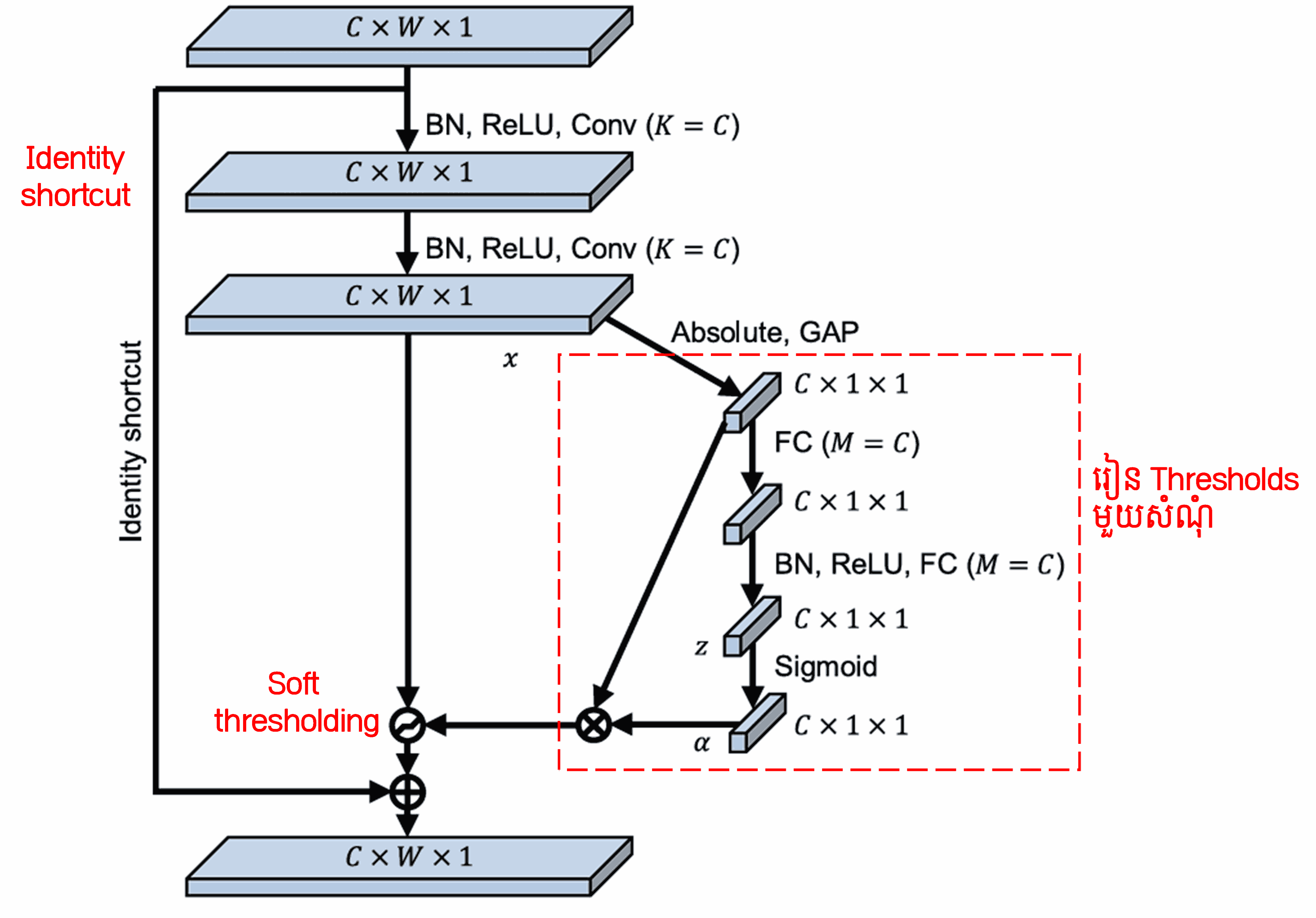
នៅក្នុង sub-network នេះ ជាដំបូងយើងគណនា absolute value នៃ features ទាំងអស់នៅក្នុង input feature map។ បន្ទាប់មក តាមរយៈ Global Average Pooling និងការគណនាមធ្យមភាគ យើងទទួលបាន feature មួយ តាងដោយ A។ នៅលើផ្លូវមួយទៀត feature map ដែលឆ្លងកាត់ Global Average Pooling រួច ត្រូវបានបញ្ជូនចូលទៅក្នុង Fully Connected Network តូចមួយ។ Fully Connected Network នេះប្រើប្រាស់ Sigmoid function ជា layer ចុងក្រោយដើម្បី normalize output ឱ្យនៅចន្លោះ 0 និង 1 ដោយទទួលបាន coefficient មួយ តាងដោយ α។ Threshold ចុងក្រោយអាចសរសេរបានថា α × A។ ដូច្នេះ threshold គឺជាលទ្ធផលគុណរវាងលេខមួយ (ចន្លោះពី 0 ទៅ 1) និងមធ្យមភាគនៃ absolute value របស់ feature map។ វិធីសាស្ត្រនេះមិនត្រឹមតែធានាថា threshold មានតម្លៃវិជ្ជមានប៉ុណ្ណោះទេ ប៉ុន្តែវាក៏ធានាថា threshold មិនមានតម្លៃធំពេកដែរ។
លើសពីនេះ sample ផ្សេងគ្នា នឹងទទួលបាន threshold ផ្សេងគ្នា។ ដូច្នេះ ក្នុងកម្រិតមួយ យើងអាចយល់ថាវាជា Attention Mechanism ពិសេសមួយ៖ វាចាប់អារម្មណ៍លើ features ដែលមិនពាក់ព័ន្ធនឹង task បច្ចុប្បន្ន ហើយបំប្លែង features ទាំងនេះតាមរយៈ Convolutional layer ពីរ ឱ្យទៅជាតម្លៃក្បែរសូន្យ រួចប្រើ Soft Thresholding ដើម្បីកំណត់ពួកវាឱ្យស្មើសូន្យ។ ផ្ទុយទៅវិញ វាចាប់អារម្មណ៍លើ features ដែលពាក់ព័ន្ធនឹង task បច្ចុប្បន្ន ហើយបំប្លែង features ទាំងនេះតាមរយៈ Convolutional layer ពីរ ឱ្យទៅជាតម្លៃដែលឆ្ងាយពីសូន្យ ដើម្បីរក្សាពួកវាទុក។
ចុងក្រោយ ដោយការតម្រៀប (stacking) ចំនួន basic module រួមជាមួយ Convolutional layer, Batch Normalization, Activation function, Global Average Pooling និង Fully Connected output layer យើងនឹងទទួលបាន Deep Residual Shrinkage Network ពេញលេញ។
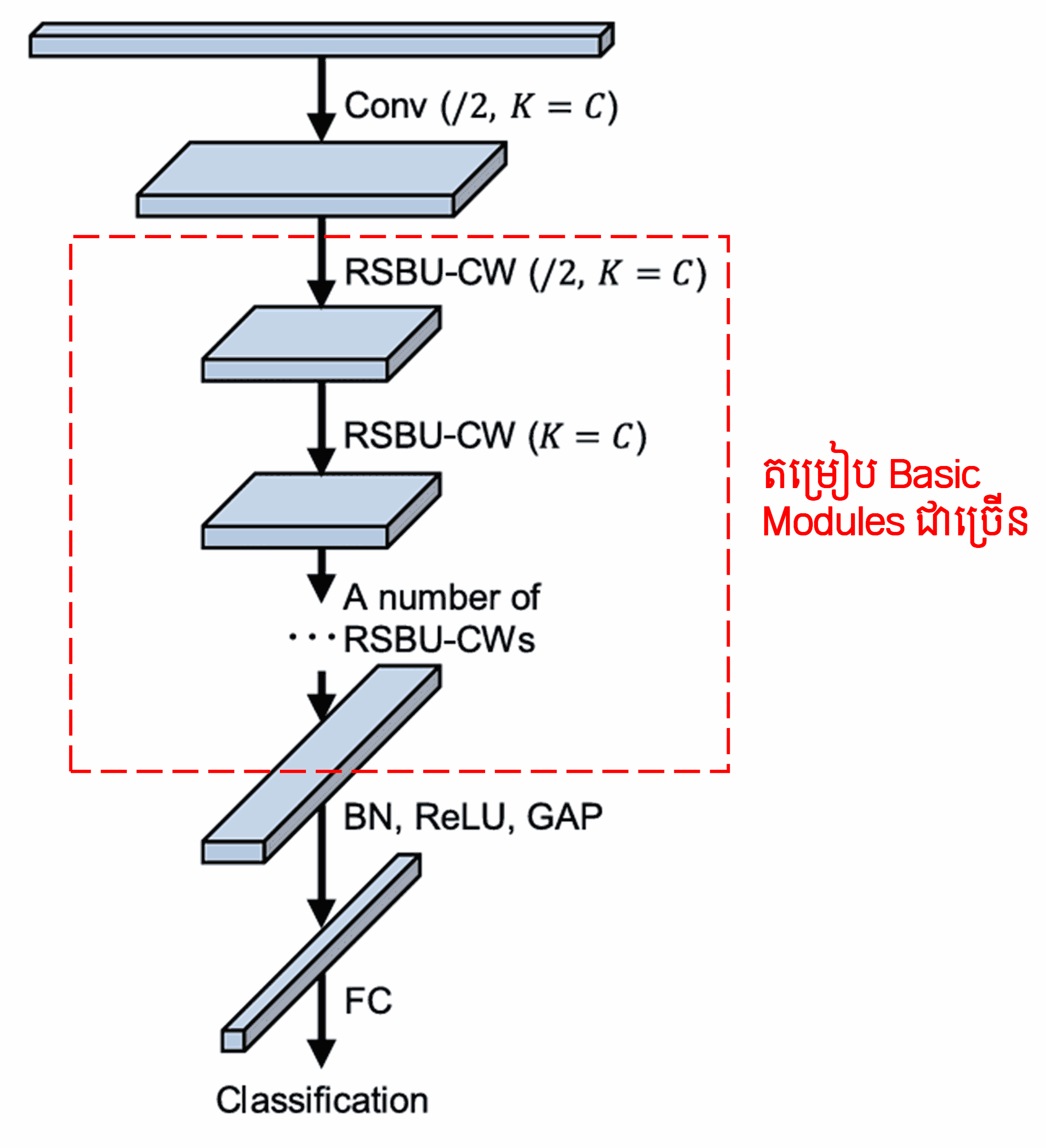
5. Generalization Capability (ភាពអាចប្រើប្រាស់បានជាទូទៅ)
Deep Residual Shrinkage Network តាមពិតគឺជាវិធីសាស្ត្រ feature learning ដ៏មានប្រសិទ្ធភាពទូទៅមួយ។ នេះគឺដោយសារតែនៅក្នុង feature learning tasks ភាគច្រើន sample តែងតែមាន noise ឬព័ត៌មានដែលមិនពាក់ព័ន្ធខ្លះៗ។ Noise និងព័ត៌មានមិនពាក់ព័ន្ធទាំងនេះអាចប៉ះពាល់ដល់ប្រសិទ្ធភាពនៃ feature learning។ ឧទាហរណ៍៖
នៅក្នុង Image Classification ប្រសិនបើរូបភាពមានវត្ថុផ្សេងៗជាច្រើនទៀតនៅលាយឡំគ្នា វត្ថុទាំងនោះអាចចាត់ទុកថាជា “noise”។ Deep Residual Shrinkage Network អាចប្រើប្រាស់ Attention Mechanism ដើម្បីសម្គាល់ “noise” ទាំងនេះ រួចប្រើប្រាស់ Soft Thresholding ដើម្បីកំណត់ features របស់ពួកវាឱ្យស្មើសូន្យ ដែលអាចជួយបង្កើន accuracy នៃ Image Classification បាន។
នៅក្នុង Speech Recognition ជាពិសេសនៅក្នុងបរិយាកាសដែលមានសំឡេងរំខាន ដូចជានៅក្បែរផ្លូវ ឬនៅក្នុងរោងចក្រ Deep Residual Shrinkage Network អាចជួយបង្កើន accuracy នៃ Speech Recognition ឬយ៉ាងហោចណាស់ក៏ផ្តល់ជាគំនិតមួយដែលអាចជួយដោះស្រាយបញ្ហានេះបាន។
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
ស្ថានភាពនៃឥទ្ធិពលការងារស្រាវជ្រាវ (Academic Impact)
ឯកសារស្រាវជ្រាវនេះត្រូវបានគេ cite ជាង ១៤០០ ដងនៅលើ Google Scholar។
យោងតាមស្ថិតិមិនផ្លូវការ Deep Residual Shrinkage Network (DRSN) ត្រូវបានយកទៅប្រើប្រាស់ក្នុងឯកសារស្រាវជ្រាវជាង ១០០០ ដោយផ្ទាល់ ឬត្រូវបានកែលម្អដើម្បីប្រើប្រាស់ក្នុងវិស័យជាច្រើនដូចជា វិស្វកម្មមេកានិច (mechanical), ថាមពលអគ្គិសនី (electric power), computer vision, វេជ្ជសាស្ត្រ (medical), សំឡេង (speech), អត្ថបទ (text), រ៉ាដា (radar), និង remote sensing ជាដើម។