Deep Residual Shrinkage Network (DRSN) kuwi versi sing wis dikembangake saka Deep Residual Network (ResNet). Sejatine, iki gabungan saka Deep Residual Network, attention mechanism, lan soft thresholding function.
Gampange, cara kerjane Deep Residual Shrinkage Network bisa dipahami kaya ngene: nggunakake attention mechanism kanggo niteni (notice) fitur-fitur sing ora penting, terus nggawe fitur kuwi dadi nol (0) liwat soft thresholding function; utawa sewalike, niteni fitur sing penting lan tetep nglestarekake fitur kasebut. Kanthi cara iki, kemampuan Deep Neural Network kanggo njupuk fitur sing migunani saka sinyal sing kebak noise (contain noise) dadi luwih ampuh.
1. Motivasi Panaliten (Research Motivation)
Sepisan, nalika ngelakokake klasifikasi sampel, mesthi wae sampel kuwi ngandhut noise, kayata Gaussian noise, pink noise, Laplacian noise, lan liyane. Secara umum, sampel asring ngemot informasi sing ora ana hubungane karo tugas klasifikasi saiki, lan informasi iki uga bisa dianggep minangka noise. Noise iki bisa ngganggu asil klasifikasi. (Soft thresholding kuwi langkah kunci ing akeh algoritma signal denoising).
Contone, pas lagi ngobrol neng pinggir dalan, swarane wong ngobrol bisa kecampur karo suara klakson mobil, suara ban, lan liyane. Nalika speech recognition dilakokake ing sinyal suara iki, asile mesthi bakal kena pengaruh suara klakson lan ban mau. Saka sudut pandang Deep Learning, fitur sing asale saka klakson lan ban kudu dibusak utawa diilangke ing jero Deep Neural Network, supaya ora ngrusak asil speech recognition.
Kapindho, senajan ana ing dataset sing padha, jumlah noise ing saben sampel biasane beda-beda. (Iki ana mirip-miripe karo attention mechanism; contone ing dataset gambar, posisi obyek target ing saben gambar bisa beda-beda; attention mechanism bisa fokus menyang posisi target ing saben gambar kasebut).
Contone, nalika nglatih klasifikasi kucing vs asu, kanggo 5 gambar sing diwenehi label “asu”: gambar ka-1 mungkin isine asu lan tikus, gambar ka-2 isine asu lan banyak (goose), gambar ka-3 isine asu lan pitik, gambar ka-4 isine asu lan kuldi, lan gambar ka-5 isine asu lan bebek. Nalika nglatih klasifikasi kucing vs asu, kita mesthi bakal keganggu karo obyek sing ora ana hubungane mau (tikus, banyak, pitik, kuldi, bebek), sing marakake akurasi klasifikasi mudhun. Yen kita bisa niteni obyek sing ora ana hubungane iki, lan mbusak fitur-fitur sing cocog karo obyek kasebut, akurasi klasifikasi kucing vs asu bisa ditingkatake.
2. Soft Thresholding
Soft thresholding kuwi langkah inti ing akeh algoritma signal denoising. Fitur sing absolute value-ne (nilai mutlak) kurang saka threshold (ambang batas) tartamtu bakal dibusak, lan fitur sing absolute value-ne luwih gedhe saka threshold bakal disusutke (shrunk) nyedhaki nol. Iki bisa diitung nggunakake rumus ing ngisor iki:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Turunan (derivative) saka output soft thresholding marang input-e yaiku:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Saka rumus ing dhuwur, bisa dideleng yen turunan saka soft thresholding kuwi mung 1 utawa 0. Sifat iki padha karo fungsi aktivasi ReLU. Mula, soft thresholding uga bisa nyuda risiko algoritma Deep Learning ngalami masalah gradient vanishing lan gradient exploding.
Ing fungsi soft thresholding, setelan threshold kudu nyukupi rong syarat: Pisanan, threshold kudu angka positif; Kapindho, threshold ora oleh luwih gedhe tinimbang nilai maksimal sinyal input, yen ora, output-e bakal dadi nol kabeh.
Kajaba kuwi, luwih becik yen threshold nyukupi syarat katelu: saben sampel kudu duwe threshold dhewe sing independen, adhedhasar kandungan noise ing sampel kasebut.
Alesane yaiku, kandungan noise ing akeh sampel asring beda-beda. Contone, asring kedadeyan ing dataset sing padha, sampel A duwe noise sithik, dene sampel B duwe noise akeh. Dadi, nalika nindakake soft thresholding ing algoritma denoising, sampel A kudu nggunakake threshold sing cilik, lan sampel B kudu nggunakake threshold sing gedhe. Ing Deep Neural Network, senajan fitur lan threshold iki kelangan makna fisik sing eksplisit, nanging logika dasare tetep padha. Tegese, saben sampel kudu duwe threshold dhewe-dhewe miturut kandungan noise-e.
3. Attention Mechanism
Attention mechanism ing bidang Computer Vision kuwi gampang dipahami. Sistem visual kewan bisa cepet mindai kabeh area, nemokake obyek target, lan banjur fokus (memusatkan perhatian) marang obyek target kanggo njupuk detail luwih akeh, karo nglirwakake informasi sing ora penting. Kanggo detail luwih lengkap, mangga maca artikel babagan attention mechanism.
Squeeze-and-Excitation Network (SENet) kuwi metode Deep Learning sing rada anyar sing nggunakake attention mechanism. Ing sampel sing beda-beda, kontribusi saka feature channels sing beda-beda ing tugas klasifikasi, asring ora padha. SENet nggunakake sub-network cilik kanggo entuk sakumpulan bobot (weights), banjur ngalikake bobot kasebut karo fitur saka saben channel kanggo nyetel gedhene fitur ing saben channel. Proses iki bisa dianggep minangka menehi attention (perhatian) sing beda-beda marang saben feature channel.
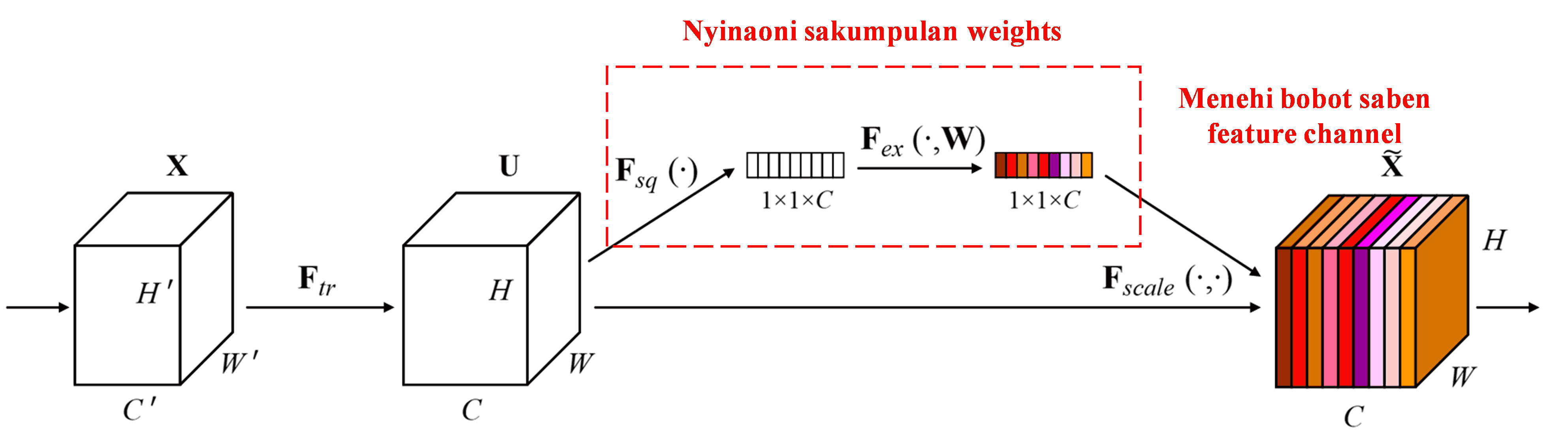
Kanthi cara iki, saben sampel bakal duwe sakumpulan bobot sing independen. Tegese, bobot kanggo rong sampel apa wae mesthi beda. Ing SENet, jalur kanggo entuk bobot yaiku: “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”.
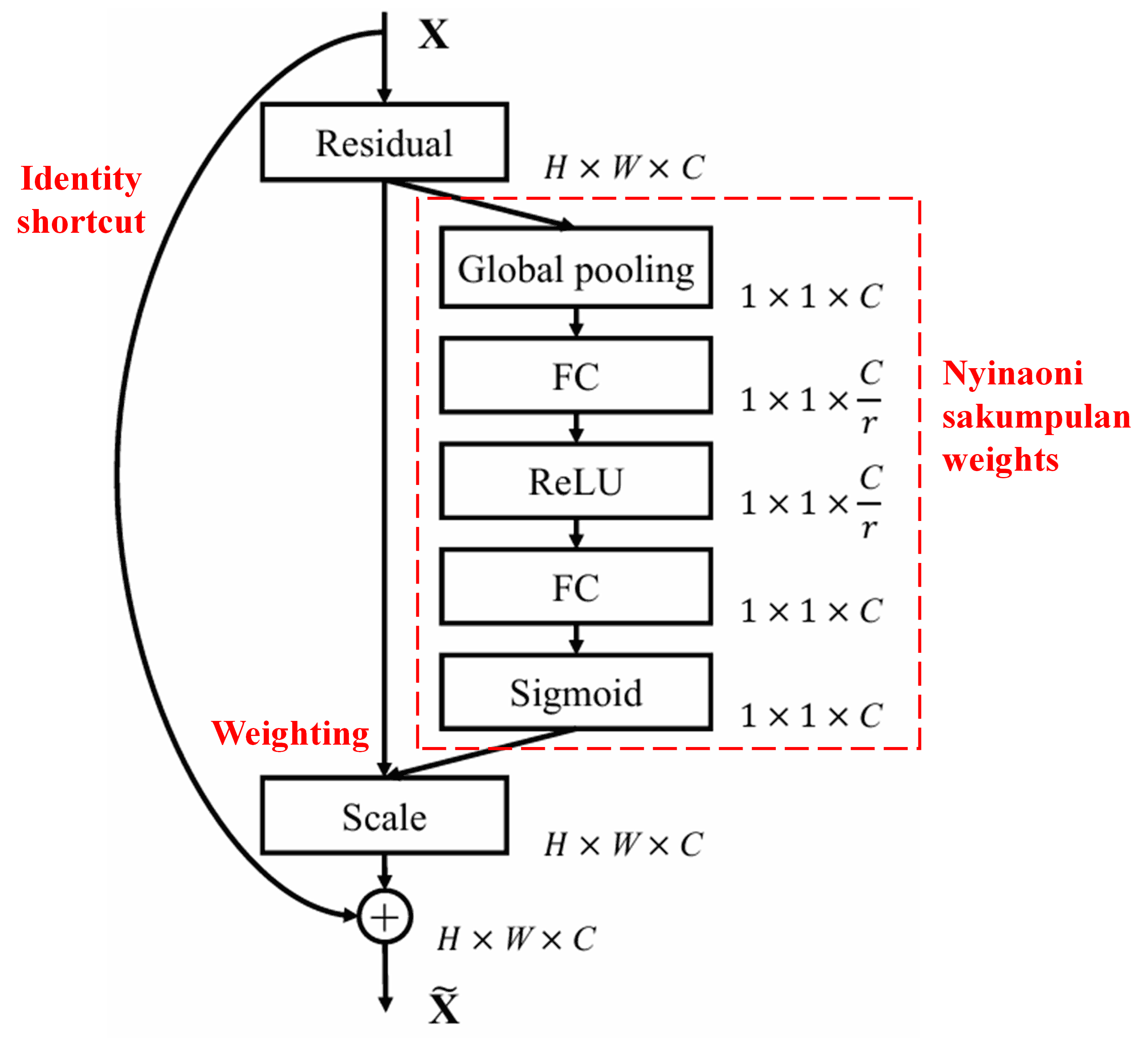
4. Soft Thresholding miturut Deep Attention Mechanism
Deep Residual Shrinkage Network njupuk inspirasi saka struktur sub-network SENet sing kasebut ing dhuwur, kanggo nerapake soft thresholding nggunakake deep attention mechanism. Liwat sub-network ing njero kothak abang, bisa disinaoni sakumpulan thresholds kanggo nerapake soft thresholding ing saben feature channel.
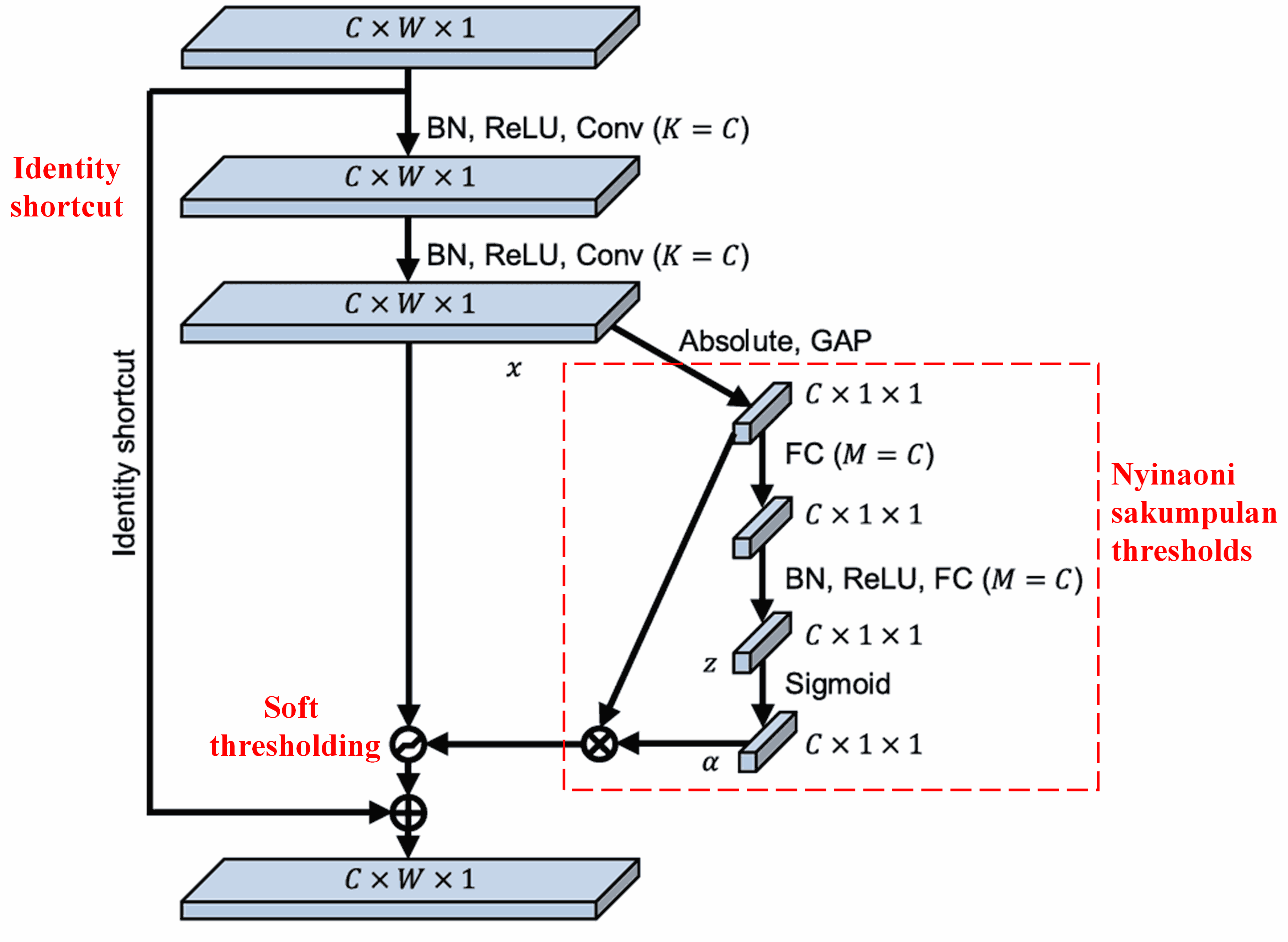
Ing sub-network iki, pisanan, kabeh fitur ing input feature map diitung nilai mutlake (absolute value). Banjur liwat global average pooling lan dirata-rata, entuk siji fitur, sing diarani A. Ing jalur liyane, feature map sawise global average pooling dilebokake menyang fully connected network cilik. Fully connected network iki nggunakake fungsi Sigmoid minangka lapisan pungkasan, kanggo nggawe output dadi antarane 0 lan 1, lan entuk koefisien, sing diarani α. Threshold pungkasan bisa ditulis minangka α×A. Dadi, threshold kuwi asile perkalian antarane angka 0 nganti 1 karo rata-rata absolute value saka feature map. Cara iki njamin yen threshold ora mung positif, nanging uga ora kegedhen.
Kajaba kuwi, sampel sing beda bakal duwe threshold sing beda. Mula, iki bisa dipahami minangka jinis attention mechanism sing khusus: niteni fitur sing ora ana hubungane karo tugas saiki, ngubah fitur kasebut dadi cedhak nol liwat rong convolutional layers, lan nggawe fitur kasebut dadi nol tenan nggunakake soft thresholding; utawa sewalike, niteni fitur sing ana hubungane karo tugas saiki, ngubah fitur kasebut dadi adoh saka nol, lan nglestarekake fitur kasebut.
Pungkasane, kanthi numpuk sawetara modul dhasar (basic modules) bareng karo convolutional layers, Batch Normalization, activation function, global average pooling, lan fully connected output layer, kita entuk Deep Residual Shrinkage Network sing wutuh.
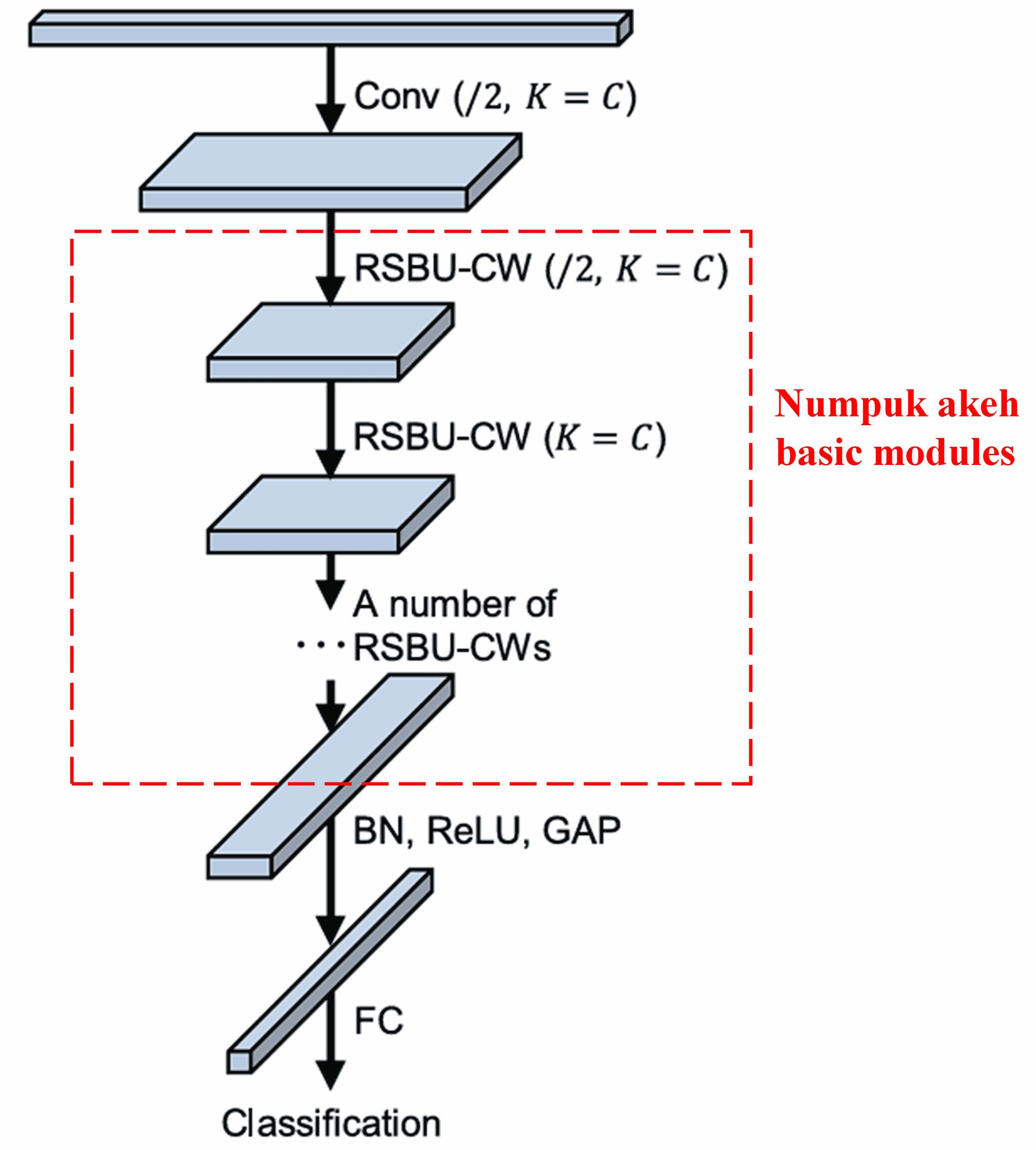
5. Sifat Umum (Generalization Capability)
Deep Residual Shrinkage Network sejatine minangka metode feature learning sing umum (general). Iki amarga ing akeh tugas feature learning, sampel-sampel mesthi ngandhut sethithik utawa akeh noise, sarta informasi sing ora relevan. Noise lan informasi sing ora relevan iki bisa ngganggu asil feature learning. Contone:
Ing klasifikasi gambar, yen gambar ngemot akeh obyek liyane, obyek-obyek iki bisa dianggep minangka “noise”; Deep Residual Shrinkage Network mbokmenawa bisa nggunakake attention mechanism kanggo niteni “noise” iki, banjur nggunakake soft thresholding kanggo nggawe fitur sing cocog karo “noise” iki dadi nol, sing pungkasane bisa ningkatake akurasi klasifikasi gambar.
Ing speech recognition, yen ana ing lingkungan sing suarane rame (noisy environment), contone ngobrol ing pinggir dalan utawa ing pabrik, Deep Residual Shrinkage Network bisa wae ningkatake akurasi speech recognition, utawa paling ora menehi ide kanggo ningkatake akurasi kasebut.
Referensi (References)
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Pengaruh Akademik (Academic Impact)
Paper iki wis disitasi luwih saka 1400 kali miturut Google Scholar.
Miturut statistik sing ora lengkap, Deep Residual Shrinkage Network wis digunakake utawa dikembangake maneh ing luwih saka 1000 publikasi ing macem-macem bidang, kalebu teknik mesin (mechanical), tenaga listrik (electric power), computer vision, medis (medical), swara (speech), teks, radar, lan penginderaan jauh (remote sensing).