Deep Residual Shrinkage Network (DRSN) er endurbætt útgáfa af Deep Residual Network (ResNet). Í raun og veru er þetta samþætting af ResNet, athygliskerfum (attention mechanisms) og mjúkri þröskuldun (soft thresholding).
Að vissu leyti má skilja virkni Deep Residual Shrinkage Network á eftirfarandi hátt: Með hjálp athygliskerfa tekur netið eftir ómikilvægum eiginleikum og notar mjúka þröskuldun til að núlla þá út (setja þá í núll). Á sama hátt tekur það eftir mikilvægum eiginleikum og varðveitir þá. Þetta styrkir getu djúpra tauganeta til að draga gagnlega eiginleika úr merkjum sem innihalda suð.
1. Rannsóknarhvati (Motivation)
Í fyrsta lagi, þegar sýni eru flokkuð, er óhjákvæmilegt að þau innihaldi eitthvað suð, svo sem Gaussískt suð, bleikt suð (pink noise), Laplace-suð o.s.frv. Í víðari skilningi innihalda sýni oft upplýsingar sem koma núverandi flokkunarverkefni ekkert við, og þessar upplýsingar má einnig skilgreina sem suð. Þetta suð getur haft neikvæð áhrif á nákvæmni flokkunarinnar. (Mjúk þröskuldun er lykilskref í mörgum reikniritum fyrir suðhreinsun merkja).
Tökum dæmi: Ef fólk spjallar saman við vegkant, gætu hljóð eins og bílflautur og degnahvinur blandast inn í talið. Þegar talgreining er framkvæmd á þessum hljóðmerkjum munu þessi aukahljóð óhjákvæmilega hafa áhrif á niðurstöðuna. Frá sjónarhóli djúpnáms (deep learning) ætti að eyða þeim eiginleikum (features) sem samsvara bílflautunum og degnahvininum inni í djúpa tauganetinu, til að koma í veg fyrir að þeir skemmi fyrir talgreiningunni.
Í öðru lagi er magn suðs oft breytilegt milli sýna, jafnvel innan sama gagnasafns. (Þetta á sér samsvörun í athygliskerfum; ef við tökum gagnasafn af myndum sem dæmi, þá er staðsetning markhlutarins oft mismunandi eftir myndum. Athygliskerfi geta beint sjónum að staðsetningu markhlutarins í hverri mynd fyrir sig).
Til dæmis, þegar við þjálfum flokkara til að greina á milli hunda og katta, gætum við verið með 5 myndir merktar sem “hundur”. Fyrsta myndin gæti innihaldið hund og mús, önnur myndin hund og gæs, þriðja myndin hund og hænu, fjórða myndin hund og asna, og fimmta myndin hund og önd. Þegar við þjálfum hunda- og kattaflokkarann verðum við óhjákvæmilega fyrir truflun af óviðkomandi hlutum eins og músum, gæsum, hænum, ösnum og öndum, sem veldur því að nákvæmni flokkunar minnkar. Ef við gætum tekið eftir þessum óviðkomandi dýrum og eytt þeim eiginleikum sem þeim tilheyra, væri mögulegt að auka nákvæmni flokkarans.
2. Mjúk þröskuldun (Soft Thresholding)
Mjúk þröskuldun er kjarnaskref í mörgum reikniritum fyrir suðhreinsun merkja. Hún virkar þannig að eiginleikum, sem hafa tölugildi (absolute value) lægra en ákveðinn þröskuldur, er eytt. Eiginleikar sem hafa tölugildi hærra en þröskuldurinn dragast saman í átt að núlli. Þetta má setja fram með eftirfarandi formúlu:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Afleiða úttaksins með tilliti til inntaksins í mjúkri þröskuldun er:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Eins og sjá má er afleiða mjúkrar þröskuldunar annað hvort 1 eða 0. Þessi eiginleiki er sá sami og hjá ReLU virkjunarfallinu (activation function). Þess vegna getur mjúk þröskuldun einnig dregið úr hættunni á að djúpnámsreiknirit lendi í vandamálum vegna hvarfandi stigla (gradient vanishing) eða stigmögnunar stigla (gradient exploding).
Í fallinu fyrir mjúka þröskuldun verður stilling þröskuldsins að uppfylla tvö skilyrði: Í fyrsta lagi verður þröskuldurinn að vera jákvæð tala. Í öðru lagi má þröskuldurinn ekki vera stærri en hæsta gildi inntaksmerkisins, annars verður úttakið allt núll.
Jafnframt er æskilegt að þröskuldurinn uppfylli þriðja skilyrðið: Hvert sýni ætti að hafa sinn eigin sjálfstæða þröskuld sem byggist á suðmagni sýnisins.
Ástæðan er sú að suðmagn er oft mismunandi milli sýna. Það er til dæmis algengt í sama gagnasafni að sýni A innihaldi lítið suð en sýni B mikið suð. Ef við beitum mjúkri þröskuldun í suðhreinsun, ætti sýni A því að nota lægri þröskuld, en sýni B ætti að nota hærri þröskuld. Í djúpum tauganetum, þó að þessir eiginleikar og þröskuldar missi sína skýru eðlisfræðilegu merkingu, gildir sama grundvallarlogík. Það er að segja, hvert sýni ætti að hafa sinn eigin þröskuld sem ræðst af eigin suðmagni.
3. Athygliskerfi (Attention Mechanism)
Athygliskerfi eru tiltölulega auðskilin á sviði tölvusjónar (computer vision). Sjónkerfi dýra getur skannað heildarsvæði hratt til að finna markhluti og síðan beint athyglinni að markhlutnum til að greina fleiri smáatriði, um leið og óviðkomandi upplýsingum er bælt niður. Nánari upplýsingar má finna í fræðigreinum um athygliskerfi.
Squeeze-and-Excitation Network (SENet) er tiltölulega nýleg djúpnámsaðferð sem byggir á athygliskerfum. Í mismunandi sýnum er framlag mismunandi eiginleikarása (feature channels) til flokkunarverkefnisins oft breytilegt. SENet notar lítið undirnet (sub-network) til að búa til sett af vægum (weights), og margfaldar síðan þessi vægi við eiginleika hverrar rásar til að stilla stærð eiginleikanna. Þetta ferli má líta á sem aðferð til að beina mismikilli athygli að mismunandi eiginleikarásum.
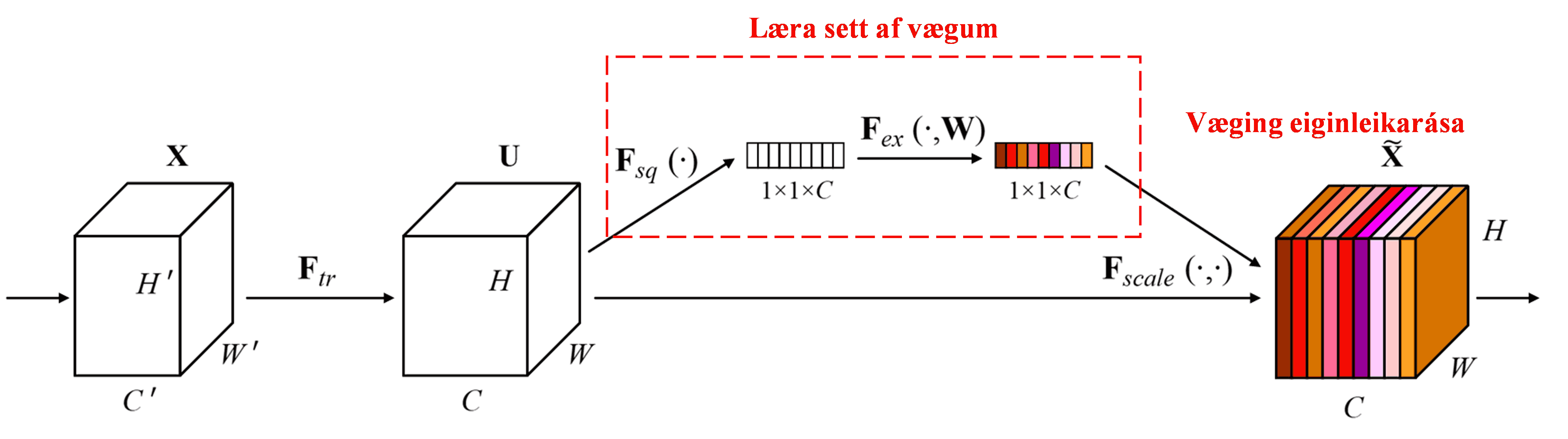
Með þessari aðferð fær hvert sýni sitt eigið sjálfstæða sett af vægum. Með öðrum orðum eru vægin fyrir tvö handahófskennd sýni ólík. Í SENet er leiðin til að finna vægin eftirfarandi: “Global Pooling → Altengt lag (FC Layer) → ReLU fall → Altengt lag (FC Layer) → Sigmoid fall”.
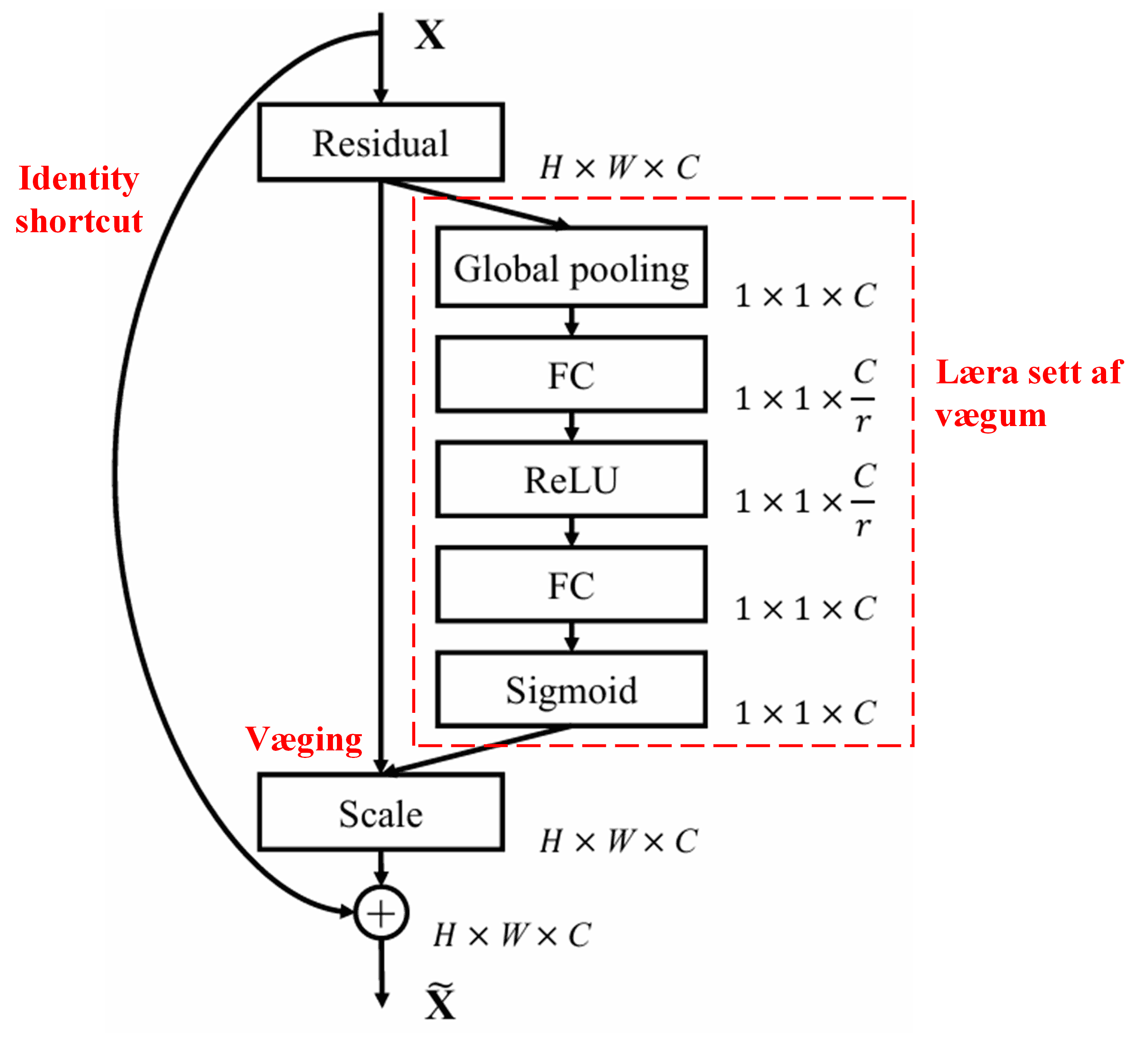
4. Mjúk þröskuldun með djúpu athygliskerfi
Deep Residual Shrinkage Network sækir innblástur í uppbyggingu undirnetsins í SENet, sem lýst var hér að ofan, til að framkvæma mjúka þröskuldun undir stjórn djúps athygliskerfis. Með undirnetinu (sem sýnt er í rauða rammanum) er hægt að læra sett af þröskuldum til að beita mjúkri þröskuldun á hverja eiginleikarás.
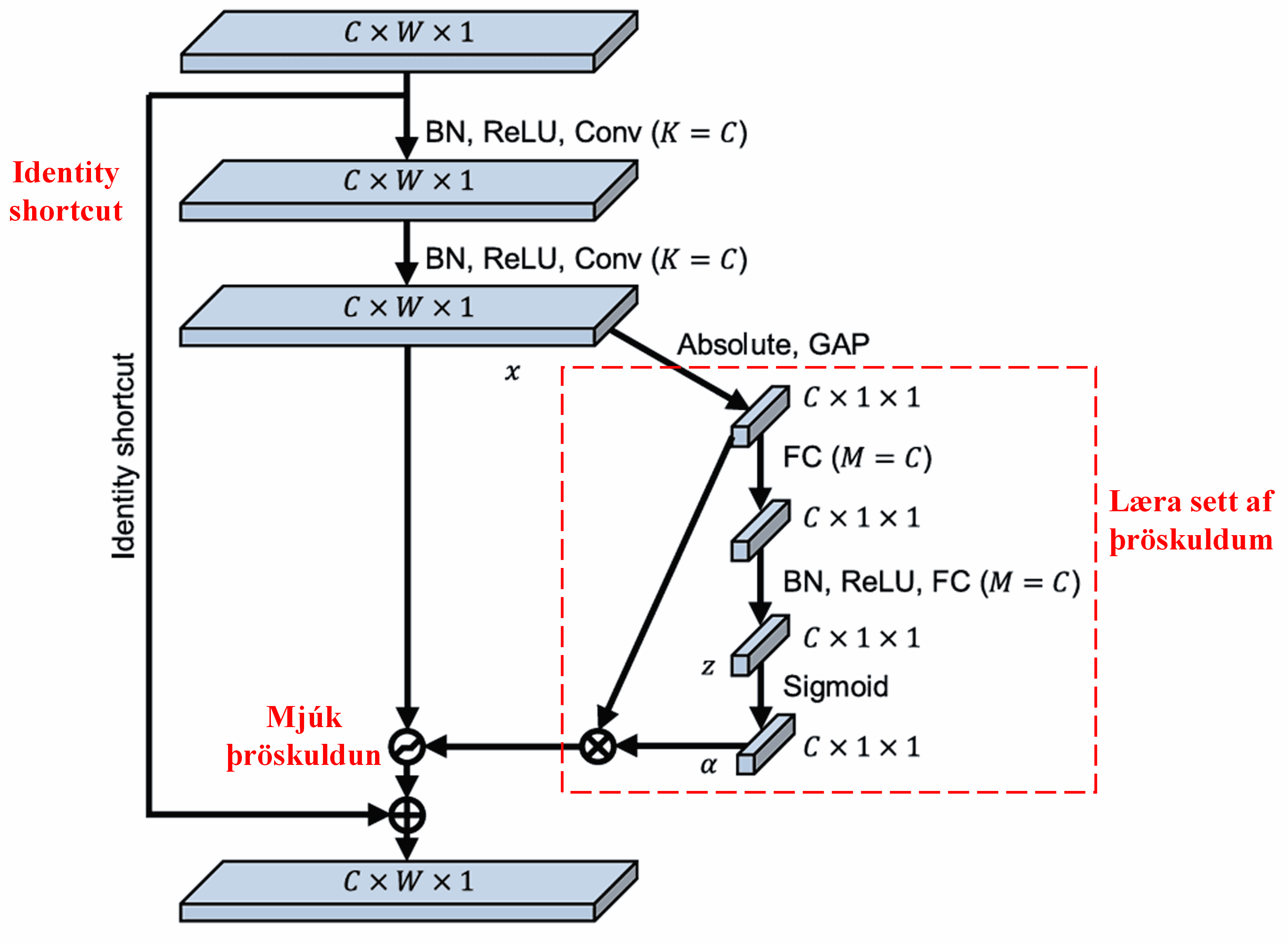
Í þessu undirneti eru tölugildi (absolute values) allra eiginleika í inntakseiginleikakortinu (input feature map) fyrst reiknuð. Síðan er beitt “Global Average Pooling” og meðaltalsreikningi til að fá einn eiginleika, sem við köllum A. Í hinni leiðinni fer eiginleikakortið, eftir “Global Average Pooling”, inn í lítið altengt net (fully connected network). Þetta altengda net notar Sigmoid fallið sem sitt síðasta lag til að varpa úttakinu á bilið 0 til 1, og úr verður stuðull sem við köllum α. Endanlegur þröskuldur má þá tákna sem α×A. Þess vegna er þröskuldurinn margfeldi af tölu milli 0 og 1 og meðaltali tölugilda eiginleikakortsins. Þessi aðferð tryggir ekki aðeins að þröskuldurinn sé jákvæður, heldur líka að hann verði ekki of stór.
Enn fremur fá mismunandi sýni mismunandi þröskulda. Þess vegna má, að vissu leyti, skilja þetta sem sérstaka tegund af athygliskerfi: Það tekur eftir eiginleikum sem koma núverandi verkefni ekki við, breytir þeim í gildi nálægt núlli með tveimur foldunarlögum (convolutional layers), og notar mjúka þröskuldun til að setja þá í núll. Eða, það tekur eftir eiginleikum sem skipta máli fyrir verkefnið, breytir þeim í gildi sem eru fjarri núlli með tveimur foldunarlögum, og varðveitir þá.
Að lokum, með því að stafla saman ákveðnum fjölda af þessum grunneiningum ásamt foldunarlögum, Batch Normalization, virkjunarföllum, Global Average Pooling og altengdu úttakslagi, fæst hið fullbúna Deep Residual Shrinkage Network.
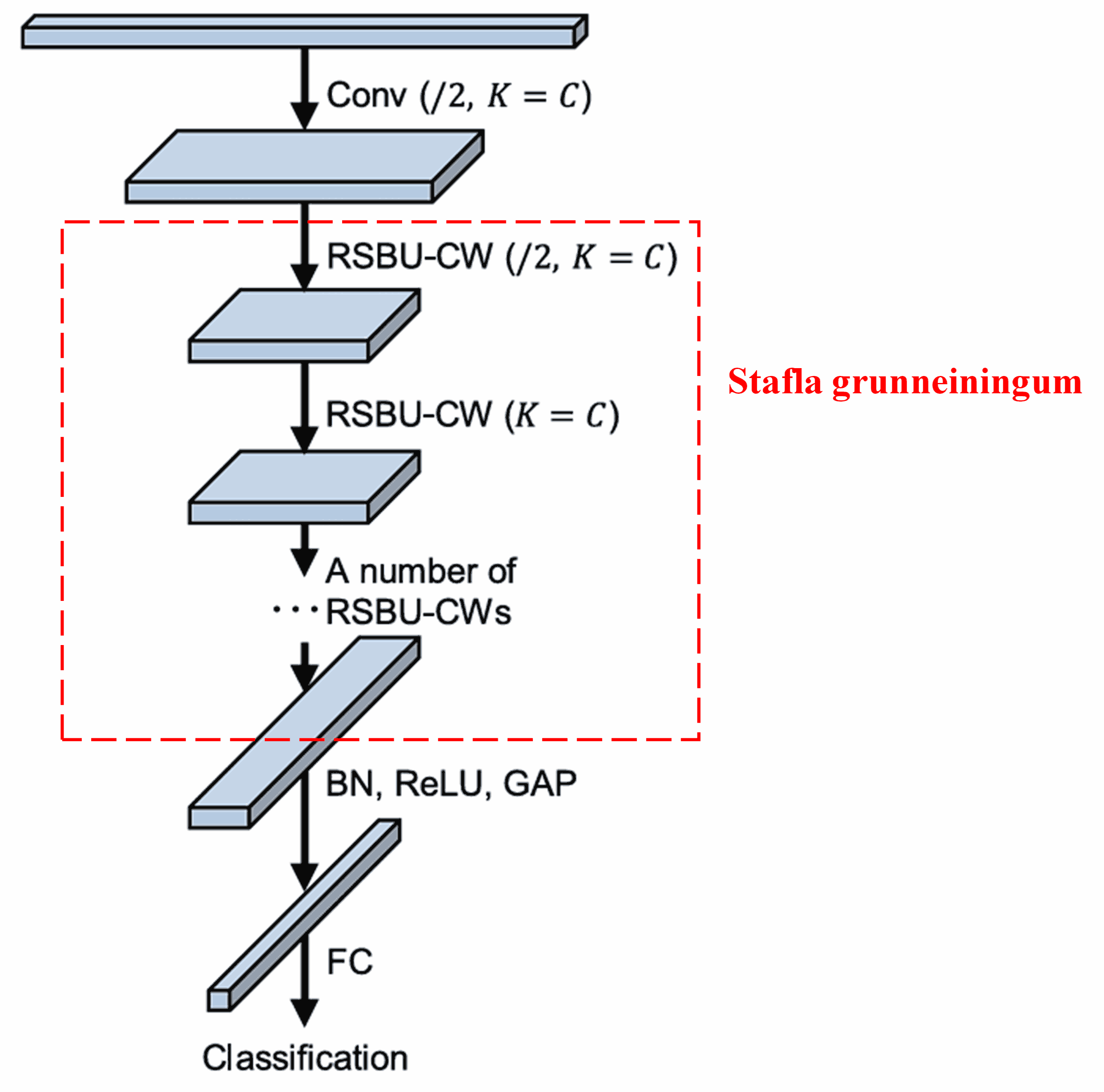
5. Almennt notagildi (Generalization)
Deep Residual Shrinkage Network er í raun almenn aðferð fyrir eiginleikanám (feature learning). Ástæðan er sú að í mörgum verkefnum þar sem eiginleikanám kemur við sögu innihalda sýnin meira eða minna suð, ásamt óviðkomandi upplýsingum. Þetta suð og þessar óviðkomandi upplýsingar geta haft áhrif á gæði eiginleikanámsins. Til dæmis:
Við myndflokkun, ef mynd inniheldur marga aðra hluti samhliða markhlutnum, má skilja þessa hluti sem “suð”. Deep Residual Shrinkage Network gæti nýtt athygliskerfið til að taka eftir þessu “suði” og síðan notað mjúka þröskuldun til að núlla út þá eiginleika sem svara til “suðsins”, sem gæti aukið nákvæmni myndflokkunarinnar.
Við talgreiningu, sérstaklega í umhverfi með miklum hávaða, t.d. við vegkant eða inni í verksmiðju, gæti Deep Residual Shrinkage Network hugsanlega aukið nákvæmni talgreiningar, eða að minnsta kosti veitt nýja nálgun til að bæta nákvæmni í slíkum aðstæðum.
Heimildir:
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Áhrif í fræðasamfélaginu
Tilvitnanir í þessa grein á Google Scholar eru orðnar fleiri en 1400.
Samkvæmt ófullkominni tölfræði hefur Deep Residual Shrinkage Network verið notað í meira en 1000 fræðigreinum, annaðhvort með beinni beitingu eða endurbótum, á fjölmörgum sviðum eins og vélaverkfræði, raforkukerfum, tölvusjón, heilbrigðistækni, talgreiningu, textagreiningu, ratsjártækni og fjarkönnun.