Deep Residual Shrinkage Network la se yon vèsyon amelyore nan Deep Residual Network. Fondamantalman, li se yon entegrasyon ant Deep Residual Network, attention mechanisms, ak fonksyon soft thresholding.
Nan yon sèten mezi, nou ka konprann prensip fonksyònman Deep Residual Shrinkage Network la nan fason sa a: li itilize attention mechanisms pou remake karakteristik (features) ki pa enpòtan yo, epi li itilize fonksyon soft thresholding pou mete yo a zewo; yon lòt bò, li remake karakteristik ki enpòtan yo epi li konsève yo. Pwosesis sa a ranfòse kapasite deep neural network la pou li ekstrè karakteristik itil nan siyal ki gen bri.
1. Motivasyon Rechèch la
Premyèman, lè n ap klase echantiyon yo (samples), li inevitab ke echantiyon yo genyen kèk bri (noise), tankou Gaussian noise, pink noise, ak Laplacian noise. Nan yon sans ki pi laj, echantiyon yo souvan gen enfòmasyon ki pa gen rapò ak travay klasifikasyon aktyèl la, epi nou ka konsidere enfòmasyon sa yo kòm bri tou. Bri sa yo ka gen yon move efè sou rezilta klasifikasyon an. (Soft thresholding se yon etap kle nan anpil algorithm pou retire bri nan siyal.)
Pa egzanp, si w ap pale bò wout la, vwa a ka melanje ak son klakson machin oswa bri kawotchou. Lè n ap fè rekonesans vokal (speech recognition) sou siyal sa yo, rezilta a pral inevitableman afekte pa son klakson yo ak bri kawotchou yo. Nan pèspektiv deep learning, karakteristik (features) ki koresponn ak klakson ak kawotchou yo ta dwe efase andedan deep neural network la pou evite yo afekte rezilta rekonesans vokal la.
Dezyèmman, menm nan menm dataset la, kantite bri a souvan varye de yon echantiyon a yon lòt. (Sa a sanble ak attention mechanisms; si nou pran yon egzanp sou yon dataset imaj, pozisyon objè sib la ka diferan nan chak imaj; attention mechanisms ka konsantre sou pozisyon espesifik objè sib la nan chak imaj.)
Pa egzanp, lè n ap antrene yon klasifikatè chat-ak-chen, ann konsidere 5 imaj ki gen etikèt “chen”. Premye imaj la ka gen yon chen ak yon sourit, dezyèm nan yon chen ak yon zwa, twazyèm nan yon chen ak yon poul, katriyèm nan yon chen ak yon bourik, epi senkyèm nan yon chen ak yon kana. Lè n ap antrene klasifikatè a, nou pral inevitableman jwenn entèferans nan men objè ki pa gen rapò yo tankou sourit, zwa, poul, bourik ak kana, sa ki lakòz presizyon klasifikasyon an bese. Si nou kapab remake objè initil sa yo, epi efase karakteristik ki koresponn ak yo, li posib pou amelyore presizyon klasifikasyon chat-ak-chen an.
2. Soft Thresholding
Soft thresholding se yon etap santral nan anpil algorithm pou retire bri nan siyal. Li efase karakteristik ki gen valè absoli ki pi piti pase yon sèten papòt (threshold), epi li retresi karakteristik ki gen valè absoli ki pi gwo pase papòt sa a nan direksyon zewo. Li ka aplike avèk fòmil sa a:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Derivasyon pwodiksyon soft thresholding la parapò ak antre a se:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Jan nou wè l pi wo a, derivasyon soft thresholding la se swa 1, swa 0. Pwopriyete sa a idantik ak fonksyon aktivasyon ReLU. Se poutèt sa, soft thresholding kapab redwi risk pou algorithm deep learning yo rankontre pwoblèm gradient vanishing ak gradient exploding.
Nan fonksyon soft thresholding la, fason nou fikse papòt la (threshold) dwe respekte de kondisyon: Premyèman, papòt la dwe yon nimewo pozitif; Dezyèmman, papòt la pa dwe pi gwo pase valè maksimòm siyal antre a, sinon tout rezilta yo ap tounen zewo.
Epitou, li preferab pou papòt la respekte yon twazyèm kondisyon: chak echantiyon ta dwe gen pwòp papòt endepandan pa l ki baze sou kantite bri li genyen.
Rezon an se paske kantite bri a souvan diferan ant echantiyon yo. Pa egzanp, nan menm dataset la, li komen pou Echantiyon A gen mwens bri pandan Echantiyon B gen plis bri. Nan ka sa a, lè n ap fè soft thresholding nan yon algorithm pou netwaye bri, Echantiyon A ta dwe itilize yon papòt ki pi piti, tandiske Echantiyon B ta dwe itilize yon papòt ki pi gwo. Nan deep neural networks, byenke karakteristik sa yo ak papòt yo pèdi siyifikasyon fizik klè yo, lojik debaz la rete menm jan an. Sa vle di, chak echantiyon ta dwe gen pwòp papòt pa l ki detèmine pa kontni bri espesifik li.
3. Attention Mechanism
Attention mechanisms se yon konsèp ki fasil pou konprann nan domèn computer vision. Sistèm vizyèl bèt yo ka eskane tout zòn nan rapidman pou jwenn objè sib la, epi ansuit konsantre atansyon yo sou objè sib la pou ekstrè plis detay pandan y ap inyore enfòmasyon ki pa itil. Pou plis detay, tanpri gade literati ki pale sou attention mechanisms.
Squeeze-and-Excitation Network (SENet) se yon metòd deep learning ki relativman nouvo ki itilize attention mechanisms. Nan diferan echantiyon, kontribisyon diferan channels (chanèl karakteristik) nan travay klasifikasyon an souvan diferan. SENet itilize yon ti sou-rezo (sub-network) pou jwenn yon seri pwa (weights), epi ansuit li miltipliye pwa sa yo ak karakteristik chak channel pou ajiste grandè karakteristik yo. Pwosesis sa a ka konsidere kòm aplike diferan nivo atansyon sou diferan channels.
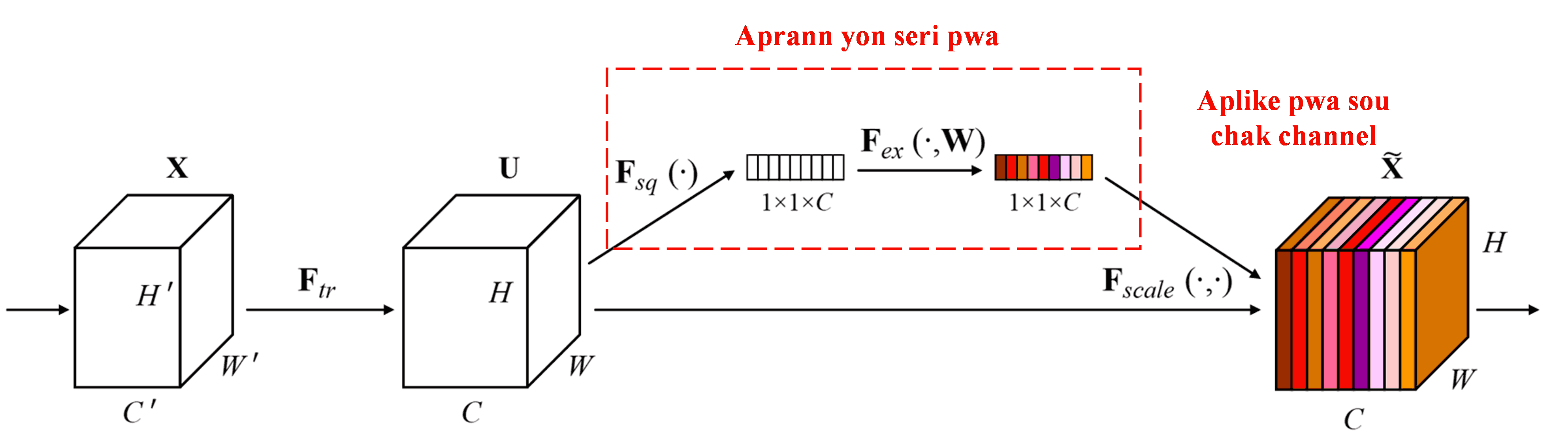
Nan metòd sa a, chak echantiyon gen pwòp seri pwa endepandan pa l. Sa vle di, pwa yo pou nenpòt de echantiyon diferan. Nan SENet, chemen espesifik pou jwenn pwa yo se “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”.
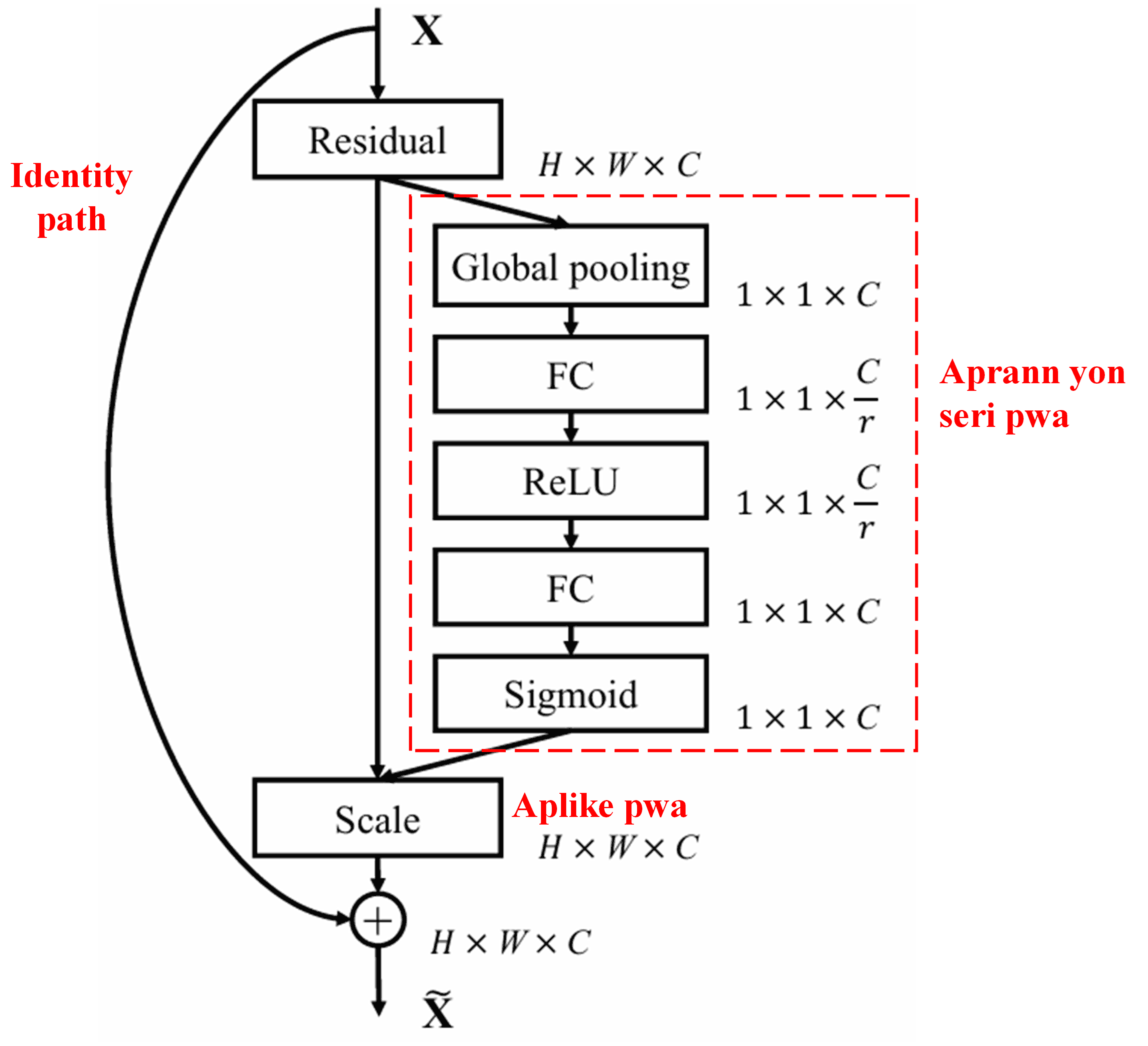
4. Soft Thresholding ak Deep Attention Mechanism
Deep Residual Shrinkage Network la enspire pa estrikti sou-rezo SENet la pou aplike soft thresholding anba yon deep attention mechanism. Atravè sou-rezo a (ki endike nan bwat wouj la), li ka aprann yon seri papòt pou aplike soft thresholding sou chak channel karakteristik.
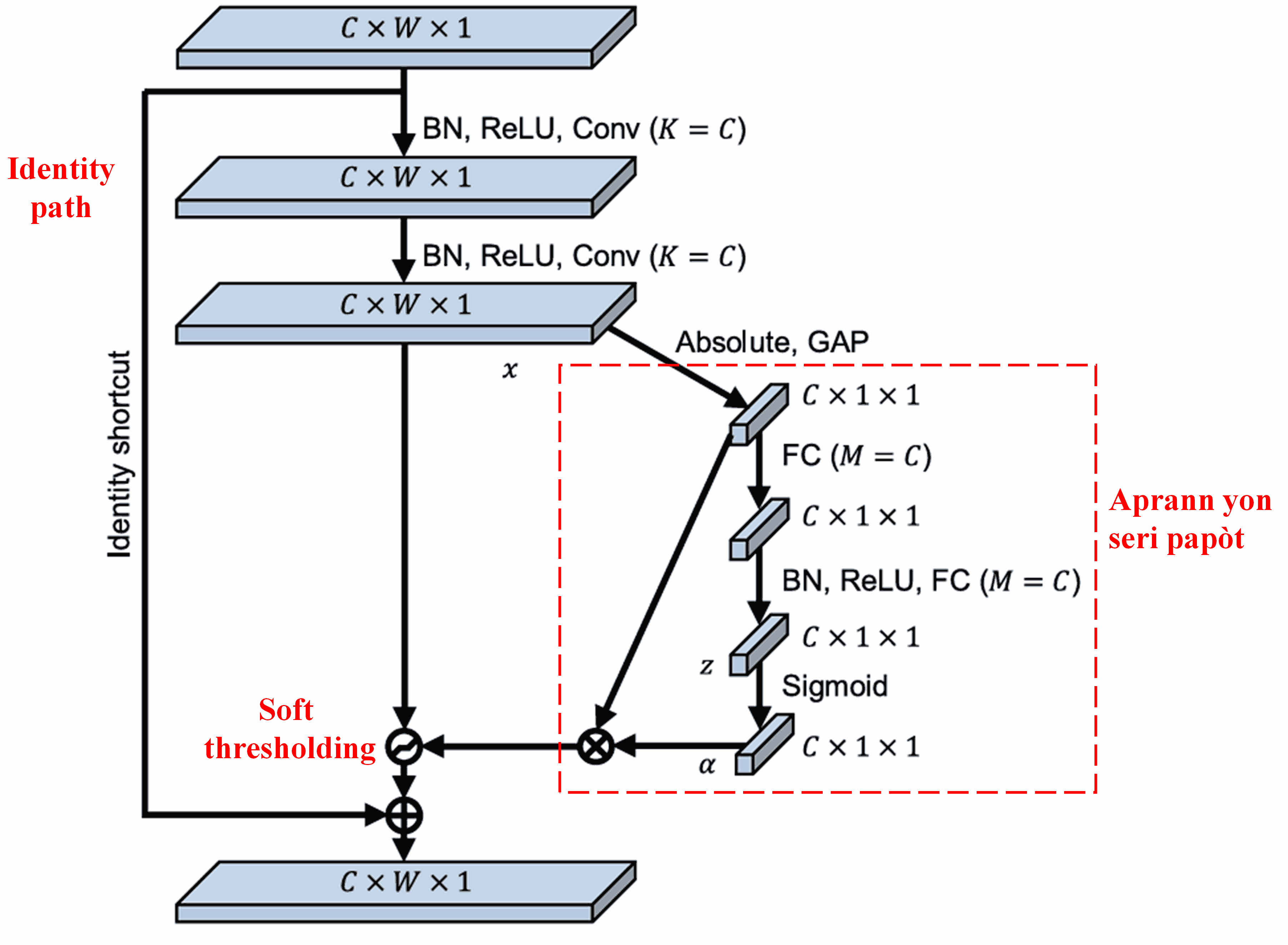
Nan sou-rezo sa a, dabò nou kalkile valè absoli tout karakteristik yo nan feature map la. Apre sa, atravè global average pooling ak mwayèn, nou jwenn yon karakteristik, ke nou rele A. Nan lòt chemen an, feature map la apre global average pooling antre nan yon ti rezo ki konplètman konekte (fully connected network). Rezo sa a itilize fonksyon Sigmoid kòm dènye kouch li pou nòmalize rezilta a ant 0 ak 1, sa ki ban nou yon koyefisyan nou rele α. Papòt final la ka eksprime kòm α × A. Kidonk, papòt la se yon nimewo ant 0 ak 1 miltipliye pa mwayèn valè absoli feature map la. Metòd sa a garanti ke papòt la pa sèlman pozitif, men li pa twò gwo tou.
Anplis de sa, diferan echantiyon ap gen diferan papòt. Konsekan, nan yon sèten mezi, sa ka konprann kòm yon attention mechanism espesyal: li remake karakteristik ki pa gen rapò ak travay aktyèl la, li transfòme yo an valè ki pre zewo atravè de kouch konvolisyon (convolutional layers), epi li mete yo a zewo lè l sèvi avèk soft thresholding; oswa, li remake karakteristik ki gen rapò ak travay la, li transfòme yo an valè ki lwen zewo atravè de kouch konvolisyon, epi li konsève yo.
Finalman, lè nou anpile yon sèten kantite modil debaz ansanm ak kouch konvolisyon, batch normalization, fonksyon aktivasyon, global average pooling, ak kouch pwodiksyon konplètman konekte (fully connected output layers), nou jwenn Deep Residual Shrinkage Network la konplè.
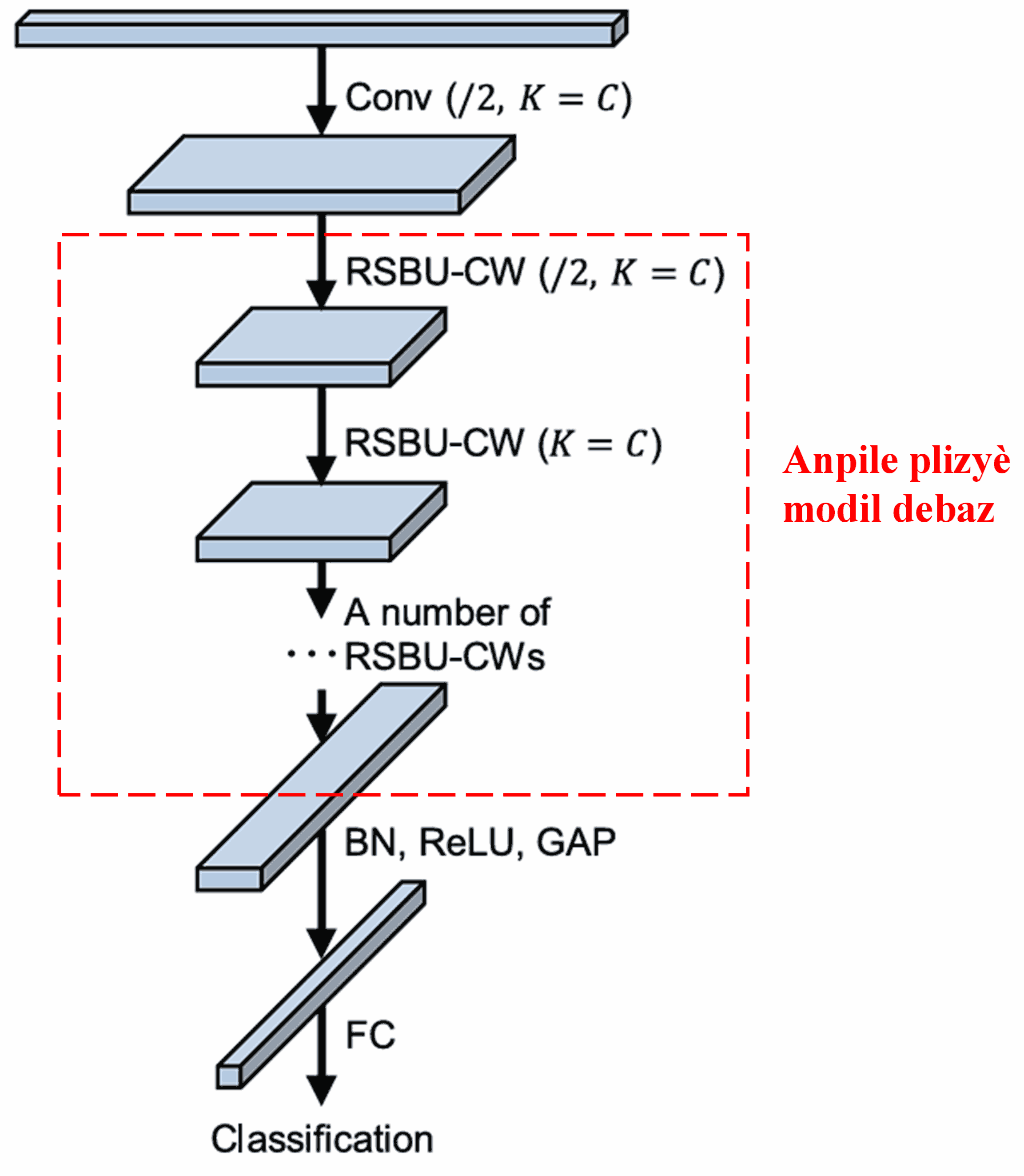
5. Kapasite Jeneralizasyon
An reyalite, Deep Residual Shrinkage Network la se yon metòd aprantisaj karakteristik (feature learning) jenerik. Sa se paske nan anpil travay aprantisaj karakteristik, echantiyon yo gen plis oswa mwens bri ak enfòmasyon ki pa enpòtan. Bri ak enfòmasyon sa yo ka afekte rezilta aprantisaj la. Pa egzanp:
Nan klasifikasyon imaj, si yon imaj gen anpil lòt objè ladan l anmenmtan, objè sa yo ka konsidere kòm “bri”. Deep Residual Shrinkage Network la ka kapab itilize attention mechanism nan pou remake “bri” sa yo, epi ansuit itilize soft thresholding pou mete karakteristik ki koresponn ak “bri” sa yo a zewo, sa ki ka amelyore presizyon klasifikasyon imaj la.
Nan rekonesans vokal, espesifikman nan anviwònman ki gen anpil bri tankou bò wout oswa andedan yon izin, Deep Residual Shrinkage Network la ka amelyore presizyon rekonesans vokal la, oswa omwen, ofri yon metodoloji ki kapab amelyore presizyon an.
Referans
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Enpak Akademik
Papye sa a gen plis pase 1400 sitasyon sou Google Scholar.
Dapre estimasyon konsèvatè, Deep Residual Shrinkage Networks (DRSN) te itilize nan plis pase 1000 piblikasyon. Travay sa yo te swa aplike dirèkteman oswa amelyore rezo a nan anpil domèn, tankou jeni mekanik, elektrisite, computer vision, swen medikal, tretman vwa, analiz tèks, rada, ak teledeteksyon (remote sensing).