Deep Residual Shrinkage Network (DRSN) wani nau’i ne na Deep Residual Network (ResNet) da aka inganta. A takaice, hadaka ce ta ResNet, attention mechanisms, da kuma soft thresholding functions.
Ta wani bangaren, ana iya fahimtar yadda Deep Residual Shrinkage Network ke aiki kamar haka: tana amfani da attention mechanism wajen lura da features din da ba su da muhimmanci, sannan ta yi amfani da soft thresholding function wajen mayar da su sifili (zero); ko kuma, ta lura da features masu muhimmanci ta kuma rike su. Wannan yana karfafa ikon deep neural network wajen ciro features masu amfani daga sigina (signals) masu dauke da noise.
1. Dalilan Yin Wannan Bincike (Research Motivation)
Da farko, yayin da ake classification na samples, babu makawa samples din za su kasance da wasu noise, kamar Gaussian noise, pink noise, da Laplacian noise. A ma’ana mafi fadi, samples na iya daukar bayanai da ba su da alaka da aikin classification na yanzu, wadanda suma ana iya daukarsu a matsayin noise. Wannan noise din zai iya shafar sakamakon classification din. (Soft thresholding babban mataki ne a yawancin algorithms na signal denoising).
Misali, yayin hira a bakin titi, sautin motoci da kahon mota na iya shiga cikin muryar da ake magana. Idan ana yin speech recognition a kan wadannan sigina, sakamakon zai samu matsala saboda wadannan karin sautukan na baya (background sounds). Idan muka kalli abin ta fuskar Deep Learning, ya kamata a cire features na sautin motocin da na tayoyin a cikin deep neural network din, don kada su bata aikin speech recognition din.
Na biyu, koda a cikin sample set daya ne, yawan noise din da ke cikin kowane sample yakan bambanta. (Wannan yana da alaka da attention mechanism; misali a hotuna, inda target object yake a kowane hoto na iya bambanta; attention mechanism na iya lura da inda object din yake a kowane hoto).
Misali, yayin training na ‘cat-and-dog classifier’ (na’urar rarrabe kule da kare), idan muna da hotuna 5 masu label din “kare”: Hoto na 1 yana iya daukar kare da bera, Hoto na 2 kare da ganswa (goose), Hoto na 3 kare da kaza, Hoto na 4 kare da jaki, Hoto na 5 kuma kare da agwagwa. Yayin da muke training, babu makawa za mu samu tangarda daga wadannan dabbobin da ba su da alaka (bera, ganswa, kaza, jaki, da agwagwa), wanda hakan zai rage accuracy na classification din. Idan za mu iya lura da wadannan abubuwan da ba su da alaka, mu kuma cire features dinsu, akwai yiwuwar accuracy na ‘cat-and-dog classifier’ din ya karu sosai.
2. Soft Thresholding
Soft thresholding mataki ne mai muhimmanci a yawancin signal denoising algorithms. Tana cire features din da absolute value dinsu bai kai wani threshold ba, sannan tana rage wadanda suka fi threshold din zuwa wajen sifili (towards zero). Ana iya aiwatar da shi ta amfani da wannan formula:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Derivative na output din soft thresholding dangane da input shine:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Kamar yadda aka nuna a sama, derivative din soft thresholding ko dai 1 ne ko kuma 0. Wannan yanayin yayi daidai da na ReLU activation function. Saboda haka, soft thresholding yana taimakawa wajen rage hadarin da deep learning algorithms ke fuskanta na ‘gradient vanishing’ da ‘gradient exploding’.
A cikin soft thresholding function, dole ne saita threshold ya cika sharudda biyu: Na daya, dole threshold ya zama positive number; na biyu, kada threshold ya fi karfin input signal din (maximum value), in ba haka ba output din zai zama zero gaba daya.
Bugu da kari, ya fi kyau threshold din ya cika sharadi na uku: Kowane sample ya kasance da nasa threshold din na daban dangane da yawan noise din da yake dauke da shi.
Wannan saboda yawan noise ya kan bambanta tsakanin samples. Misali, a cikin sample set daya, za a iya samun Sample A yana da noise kadan, yayin da Sample B yana da noise mai yawa. Saboda haka, a cikin denoising algorithm, ya kamata Sample A ya yi amfani da karamin threshold, shi kuma Sample B ya yi amfani da babban threshold. A cikin deep neural networks, koda yake wadannan features da thresholds ba su da ma’ana ta zahiri (physical meaning) kamar a sigina na yau da kullum, amma tsarin logik din daya ne. Wato, kowane sample ya kamata ya samu threshold dinsa na musamman dangane da noise dinsa.
3. Attention Mechanism
Attention mechanism yana da saukin fahimta a fannin computer vision. Tsarin gani na dabbobi (visual system) yana iya saurin duba duka wuri don gano target object, sannan ya maida hankali (attention) a kan object din don ciro karin bayanai, tare da yin watsi da bayanan da ba su da amfani. Don karin bayani, ana iya duba rubuce-rubuce akan attention mechanism.
Squeeze-and-Excitation Network (SENet) wata sabuwar hanyar deep learning ce da ke amfani da attention mechanism. A samples daban-daban, gudummawar feature channels daban-daban a aikin classification takan bambanta. SENet tana amfani da wani karamin sub-network don samun wasu weights, sannan ta yi multiplying wadannan weights da features na kowane channel don daidaita girman features din. Wannan tsarin ana iya daukarsa a matsayin sanya attention mai girma daban-daban akan feature channels daban-daban.
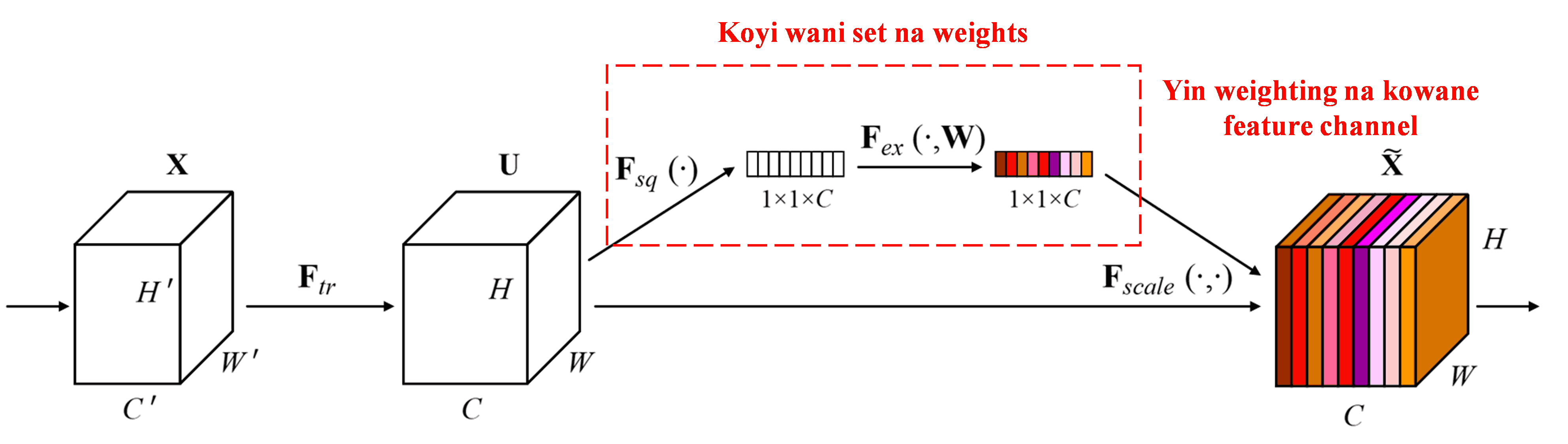
A wannan hanyar, kowane sample yana da nasa weights din na daban. A takaice, weights na kowane samples biyu sun bambanta. A cikin SENet, hanyar samun weights ita ce “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”.
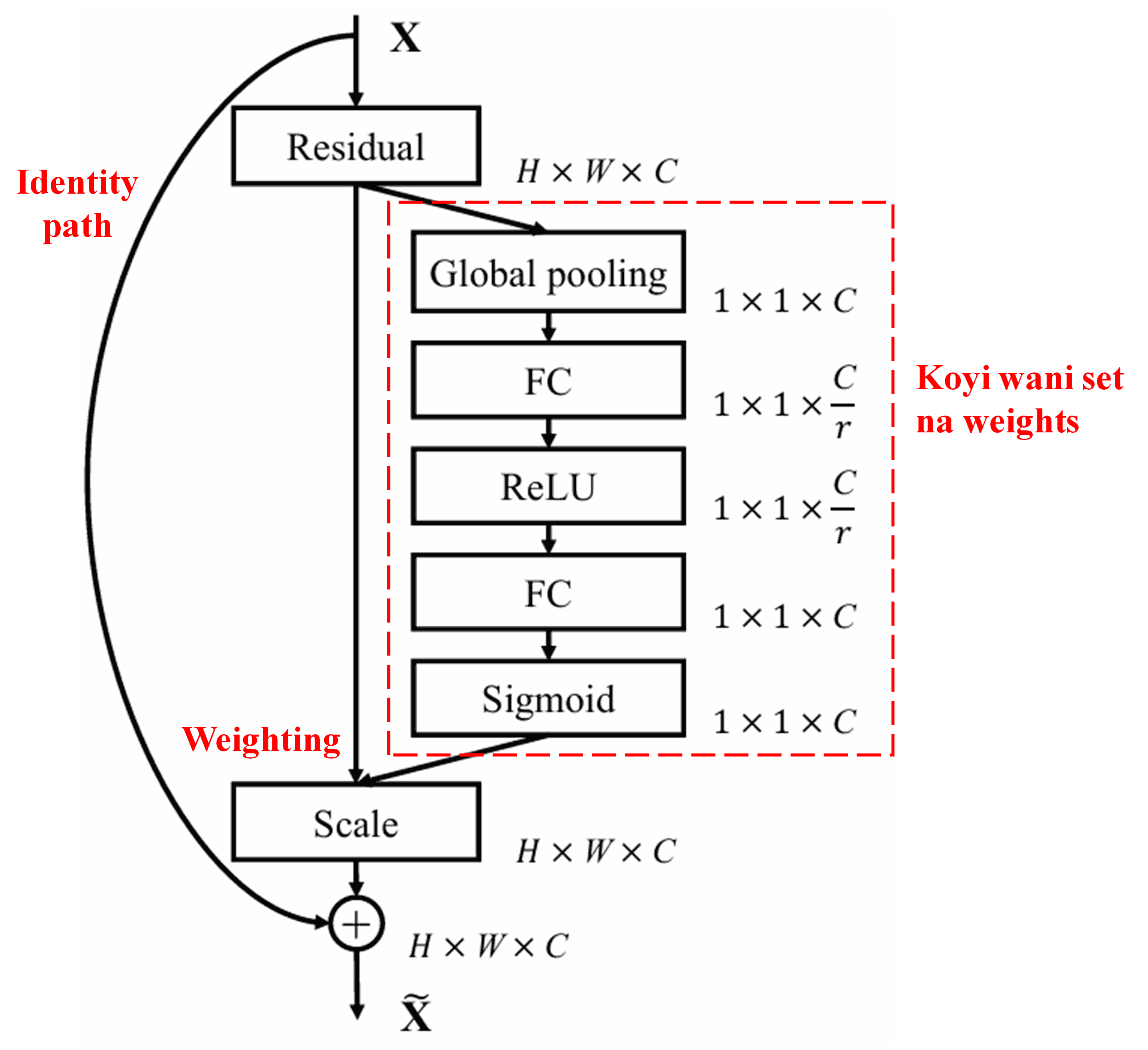
4. Soft Thresholding tare da Deep Attention Mechanism
Deep Residual Shrinkage Network ta yi koyi da tsarin sub-network na SENet da aka ambata a sama, don aiwatar da soft thresholding karkashin deep attention mechanism. Ta hanyar sub-network (wanda ke cikin jan akwati a hotunan architecture), za a iya koyon wasu thresholds don yin soft thresholding ga kowane feature channel.
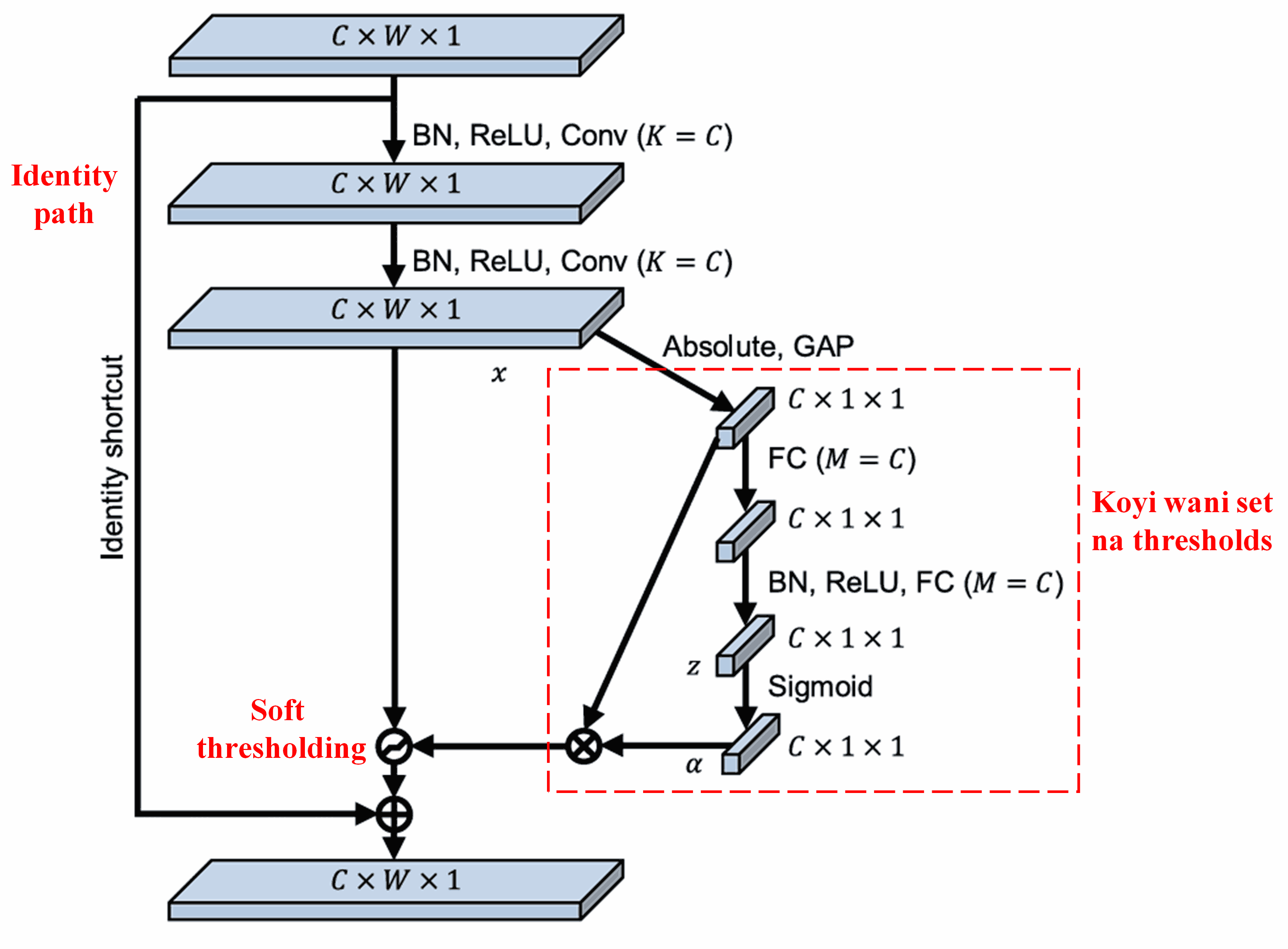
A cikin wannan sub-network, da farko ana lissafin absolute values na duka features da ke cikin input feature map. Sannan ta hanyar global average pooling da averaging, sai a samu wani feature daya, wanda za mu kira A. A wata hanyar kuma, feature map din da aka yi global average pooling a kansa, ana shigar da shi cikin wani karamin fully connected network. Wannan network din yana amfani da Sigmoid function a matsayin layer na karshe don daidaita output din tsakanin 0 da 1, wanda zai ba mu coefficient mai suna α. Threshold din karshe shine α × A. Saboda haka, threshold din shine sakamakon lissafin wata lamba tsakanin 0 da 1 wacce aka yi multiplying da average na absolute values na feature map din. Wannan hanyar tana tabbatar da cewa threshold din positive ne, kuma bai yi girma da yawa ba.
Haka kuma, samples daban-daban suna samun thresholds daban-daban. Saboda haka, ana iya fahimtar wannan a matsayin wani nau’i na musamman na attention mechanism: yana lura da features da ba su da alaka da aikin yanzu, yana mayar da su zuwa lambobi kusa da sifili ta hanyar convolutional layers biyu, sannan soft thresholding ya mayar da su zero gaba daya; ko kuma, yana lura da features masu muhimmanci, yana mayar da su nesa da sifili, kuma yana rike su.
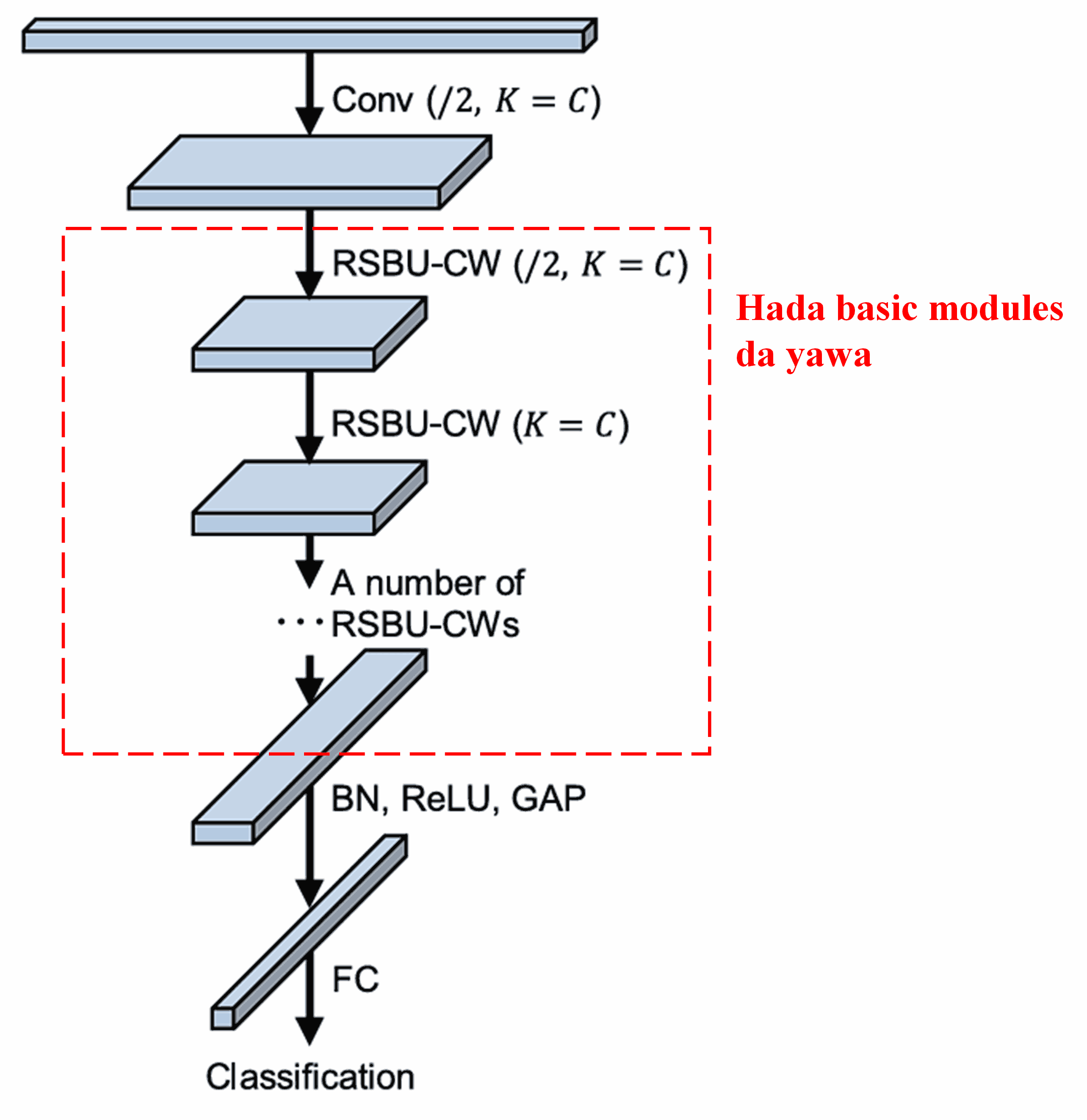
A karshe, ta hanyar hada basic modules da dama, tare da convolutional layers, batch normalization, activation functions, global average pooling, da fully connected output layers, sai a samu cikakken Deep Residual Shrinkage Network.
5. Ikon Aiki a Fannoni Daban-daban (Generalization Capability)
A hakikanin gaskiya, Deep Residual Shrinkage Network hanya ce ta “generic feature learning”. Wannan saboda a ayyuka da yawa na koyon features (feature learning tasks), samples suna dauke da noise ko bayanai marasa alaka. Wadannan noise da bayanan na iya shafar aikin koyon features din. Misali:
A wajen image classification, idan hoto yana dauke da wasu abubuwa daban da yawa, ana iya daukar wadannan abubuwan a matsayin “noise”; Deep Residual Shrinkage Network na iya amfani da attention mechanism don lura da wannan “noise” din, sannan ta yi amfani da soft thresholding wajen mayar da features na wannan “noise” din zuwa zero, wanda hakan zai iya kara accuracy na image classification.
A wajen speech recognition, musamman a wurare masu hayaniya (kamar bakin titi ko cikin masana’antu), Deep Residual Shrinkage Network na iya kara accuracy na speech recognition, ko kuma ta bayar da wata hanyar da za ta iya inganta sakamakon.
References
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Tasiri a Fannin Ilimi (Academic Impact)
Wannan takarda (paper) ta samu citations sama da 1400 a Google Scholar.
Bisa kididdiga, an yi amfani da Deep Residual Shrinkage Network a cikin rubuce-rubucen ilimi (publications) sama da 1000, ko dai ta hanyar amfani da shi kai tsaye ko kuma inganta shi, a fannoni da dama kamar mechanical engineering, electric power, computer vision, medical, speech, text, radar, da remote sensing.