Deep Residual Shrinkage Network એ Deep Residual Network નું એક સુધારેલું version છે. વાસ્તવમાં, તે Deep Residual Network, Attention Mechanisms અને Soft Thresholding functions નું એક integration (સંકલન) છે.
અમુક અંશે, Deep Residual Shrinkage Network ના working principle ને આ રીતે સમજી શકાય છે: તે Attention Mechanism દ્વારા unimportant features ને notice કરે છે અને Soft Thresholding function દ્વારા તેને zero બનાવી દે છે; અથવા તો, તે Attention Mechanism દ્વારા important features ને notice કરે છે અને તેમને retain કરે છે (જાળવી રાખે છે). આ process થી Deep Neural Network ની noisy signals માંથી useful features extract કરવાની ક્ષમતા વધે છે.
1. Research Motivation (સંશોધનનો હેતુ)
સૌથી પહેલા, જ્યારે samples નું classification કરવામાં આવે છે, ત્યારે samples માં Gaussian noise, pink noise, અને Laplacian noise જેવો noise હોવો અનિવાર્ય છે. વ્યાપક રીતે કહીએ તો, samples માં ઘણીવાર એવી માહિતી હોય છે જે current classification task સાથે સંબંધિત નથી હોતી, જેને પણ noise તરીકે ગણી શકાય. આ noise classification ના performance પર ખરાબ અસર કરી શકે છે. (Soft thresholding એ ઘણા signal denoising algorithms માં એક મહત્વનું step છે.)
ઉદાહરણ તરીકે, રોડની બાજુમાં વાતચીત કરતી વખતે, અવાજમાં વાહનોના horn અને પૈડાંનો અવાજ mix થઈ શકે છે. જ્યારે આ sound signals પર speech recognition કરવામાં આવે છે, ત્યારે તેનું result અનિવાર્યપણે horn અને પૈડાંના અવાજથી પ્રભાવિત થશે. Deep Learning ના perspective થી જોઈએ તો, આ horn અને પૈડાંના અવાજ સાથે સંકળાયેલા features ને Deep Neural Network ની અંદર જ eliminate કરી દેવા જોઈએ, જેથી speech recognition ના result પર અસર ન થાય.
બીજું, એક જ dataset માં પણ, દરેક sample માં noise નું પ્રમાણ અલગ અલગ હોઈ શકે છે. (આ બાબત attention mechanism સાથે મળતી આવે છે; જેમ કે એક image dataset માં, દરેક ફોટામાં target object નું સ્થાન અલગ અલગ હોઈ શકે છે; attention mechanism દરેક ફોટામાં target object ના સ્થાન પર focus કરી શકે છે.)
ઉદાહરણ તરીકે, જ્યારે આપણે Cat-Dog classifier ને train કરીએ છીએ, ત્યારે “Dog” ના લેબલ વાળા 5 ફોટા લઈએ. પહેલા ફોટામાં dog અને mouse હોઈ શકે, બીજામાં dog અને goose, ત્રીજામાં dog અને chicken, ચોથામાં dog અને donkey, અને પાંચમા ફોટામાં dog અને duck હોઈ શકે છે. જ્યારે આપણે classifier train કરીએ છીએ, ત્યારે mouse, goose, chicken, donkey અને duck જેવા irrelevant objects થી interference થવું અનિવાર્ય છે, જેનાથી classification accuracy ઘટી શકે છે. જો આપણે આ irrelevant objects (mouse, goose, વગેરે) ને notice કરી શકીએ અને તેમના features ને delete કરી શકીએ, તો Cat-Dog classifier ની accuracy વધી શકે છે.
2. Soft Thresholding
Soft thresholding એ ઘણા signal denoising algorithms નું core step છે. તે features કે જેની absolute value કોઈ ચોક્કસ threshold કરતાં ઓછી હોય તેને delete કરે છે, અને જેની absolute value threshold કરતાં વધારે હોય તેને zero તરફ shrink (સંકોચન) કરે છે. તેને નીચે મુજબના formula દ્વારા implement કરી શકાય છે:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Soft thresholding ના output નું input ની સાપેક્ષે derivative નીચે મુજબ છે:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]ઉપર બતાવ્યા મુજબ, Soft thresholding નું derivative કાં તો 1 હોય છે અથવા 0 હોય છે. આ property ReLU activation function જેવી જ છે. તેથી, Soft thresholding દ્વારા deep learning algorithms માં gradient vanishing અને gradient exploding ના risk ને ઘટાડી શકાય છે.
Soft thresholding function માં, threshold નક્કી કરતી વખતે બે શરતોનું પાલન થવું જોઈએ: પહેલું, threshold positive હોવો જોઈએ; બીજું, threshold ની value input signal ના maximum value કરતાં મોટી ન હોવી જોઈએ, નહીંતર output પૂરેપૂરું zero થઈ જશે.
સાથે સાથે, threshold માટે ત્રીજી શરત પણ હોવી જોઈએ: દરેક sample માટે તેના noise content ના આધારે તેનો પોતાનો independent threshold હોવો જોઈએ.
આનું કારણ એ છે કે ઘણા samples માં noise નું પ્રમાણ અલગ અલગ હોય છે. ઉદાહરણ તરીકે, એક જ dataset માં Sample A માં ઓછો noise હોઈ શકે અને Sample B માં વધારે noise હોઈ શકે. તો જ્યારે denoising algorithm માં soft thresholding કરવામાં આવે, ત્યારે Sample A માટે નાનો threshold અને Sample B માટે મોટો threshold વાપરવો જોઈએ. Deep Neural Networks માં, ભલે આ features અને thresholds તેમનો સ્પષ્ટ ભૌતિક અર્થ ગુમાવી બેસે, પણ મૂળભૂત તર્ક સમાન રહે છે. એટલે કે, દરેક sample માટે તેના noise content મુજબ અલગ threshold હોવો જોઈએ.
3. Attention Mechanism
Computer Vision ના field માં Attention Mechanism સમજવું સરળ છે. પ્રાણીઓની visual system ઝડપથી આખા વિસ્તારને scan કરી શકે છે અને target object ને શોધી શકે છે, અને પછી target object પર ધ્યાન કેન્દ્રિત (focus) કરી શકે છે જેથી વધારે details extract કરી શકાય અને irrelevant information ને ignore કરી શકાય. વધુ વિગતો માટે attention mechanism પરના લેખો જુઓ.
Squeeze-and-Excitation Network (SENet) એ attention mechanism નો ઉપયોગ કરતી એક નવી deep learning method છે. અલગ અલગ samples માં, classification task માં અલગ અલગ feature channels નું contribution (યોગદાન) અલગ અલગ હોય છે. SENet એક નાના sub-network નો ઉપયોગ કરીને weights (વજન) નું એક group મેળવે છે, અને પછી આ weights ને દરેક channel ના features સાથે multiply કરે છે, જેથી દરેક channel ના features ની size adjust કરી શકાય. આ process ને અલગ અલગ feature channels પર અલગ અલગ પ્રમાણમાં attention આપવા તરીકે જોઈ શકાય છે.
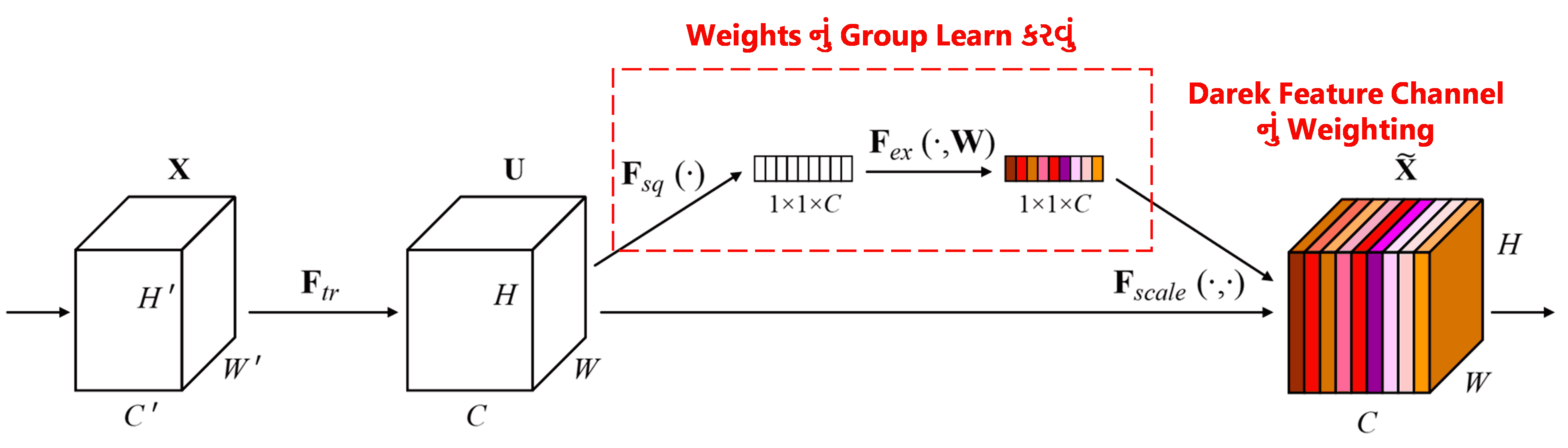
આ પદ્ધતિમાં, દરેક sample માટે weights નું પોતાનું independent group હોય છે. બીજા શબ્દોમાં કહીએ તો, કોઈપણ બે samples ના weights અલગ અલગ હોય છે. SENet માં, weights મેળવવાનો રસ્તો “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function” છે.
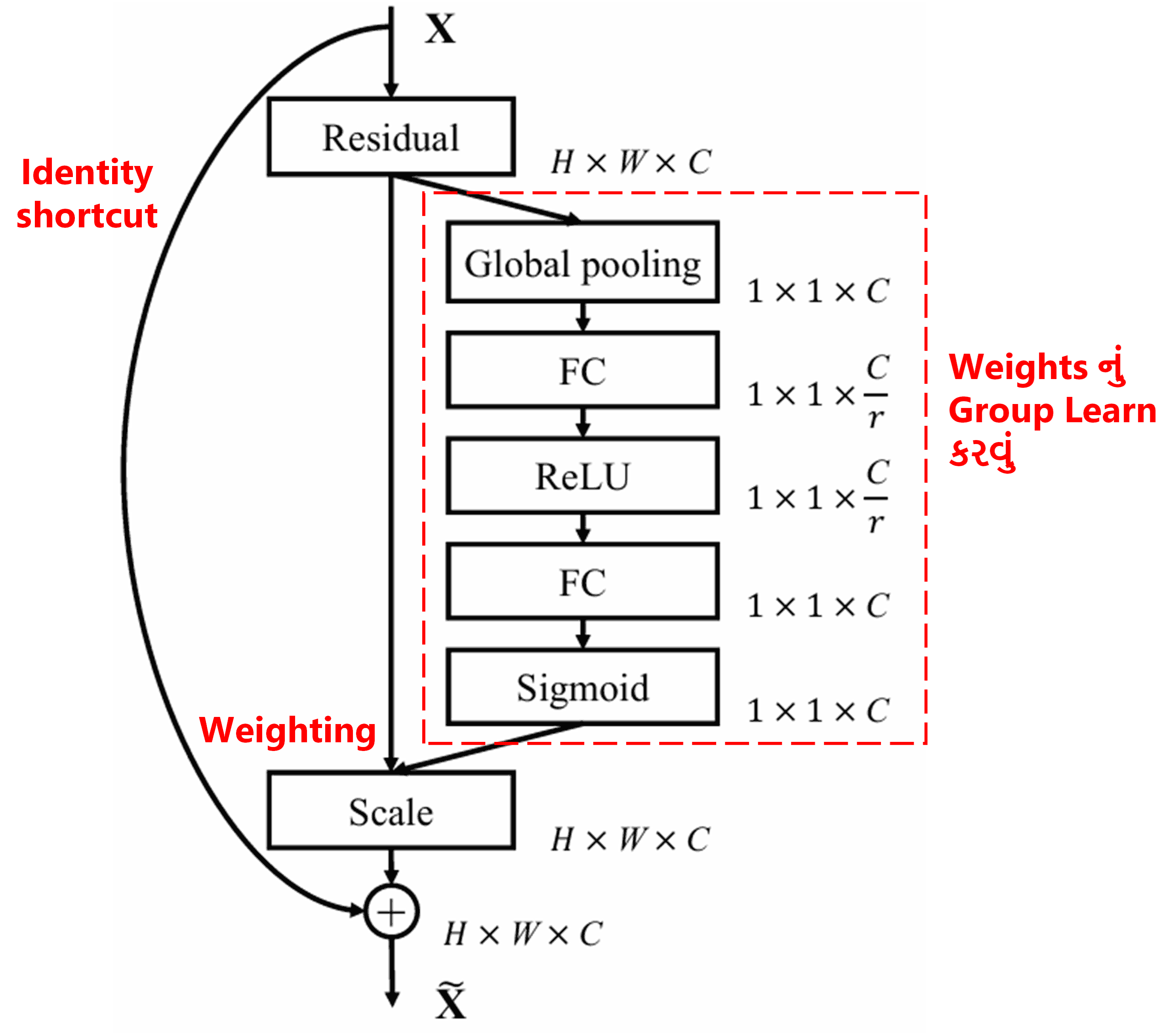
4. Deep Attention Mechanism based Soft Thresholding
Deep Residual Shrinkage Network ઉપર જણાવેલ SENet ના sub-network structure નો ઉપયોગ કરીને Deep Attention Mechanism હેઠળ Soft Thresholding implement કરે છે. લાલ બોક્સમાં બતાવેલ sub-network દ્વારા, thresholds નું એક group શીખી શકાય છે (learn કરી શકાય છે), જે દરેક feature channel પર soft thresholding લાગુ કરે છે.
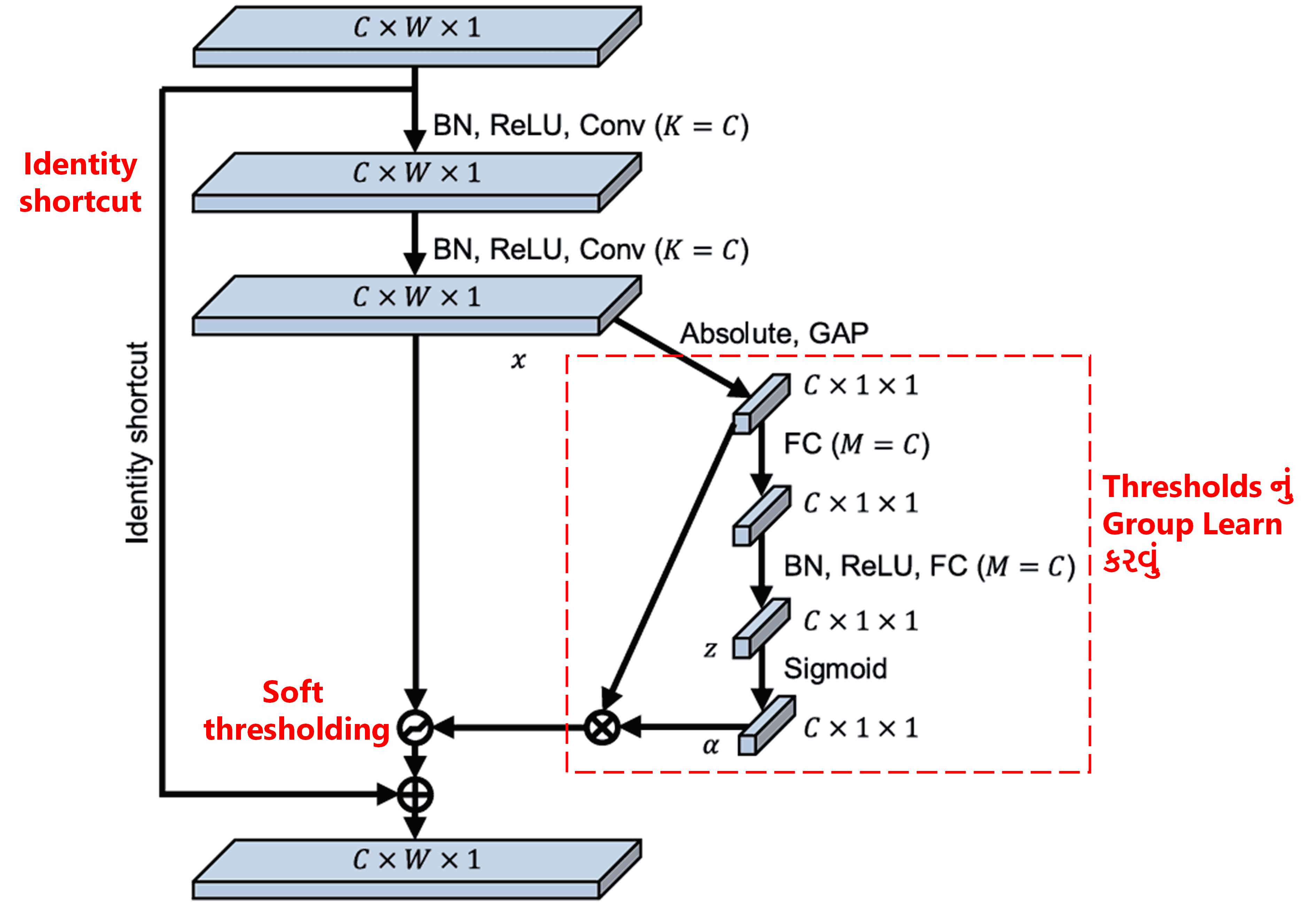
આ sub-network માં, સૌથી પહેલા input feature map ના બધા features ની absolute value લેવામાં આવે છે. પછી Global Average Pooling અને averaging દ્વારા એક feature મેળવવામાં આવે છે, જેને A કહીશું. બીજા રસ્તામાં, Global Average Pooling પછીના feature map ને એક નાના Fully Connected Network માં input કરવામાં આવે છે. આ Fully Connected Network છેલ્લા layer તરીકે Sigmoid function નો ઉપયોગ કરે છે અને output ને 0 અને 1 ની વચ્ચે normalize કરે છે, જેનાથી એક coefficient મળે છે, જેને α કહીશું. અંતિમ threshold ને α×A તરીકે દર્શાવી શકાય. તેથી, threshold એટલે “0 અને 1 વચ્ચેનો એક નંબર” × “feature map ની absolute value ની average”. આ રીત ખાતરી કરે છે કે threshold positive રહે અને બહુ મોટો ન થઈ જાય.
વળી, અલગ અલગ samples માટે અલગ અલગ thresholds મળે છે. તેથી, અમુક અંશે, આને એક ખાસ પ્રકારની Attention Mechanism તરીકે સમજી શકાય: જે current task સાથે સંબંધિત ન હોય તેવા features ને notice કરે છે, બે convolutional layers દ્વારા આ features ને 0 ની નજીક લઈ જાય છે, અને soft thresholding દ્વારા તેમને zero બનાવી દે છે; અથવા તો, જે features current task માટે important છે તેમને notice કરે છે અને તેમને જાળવી રાખે છે.
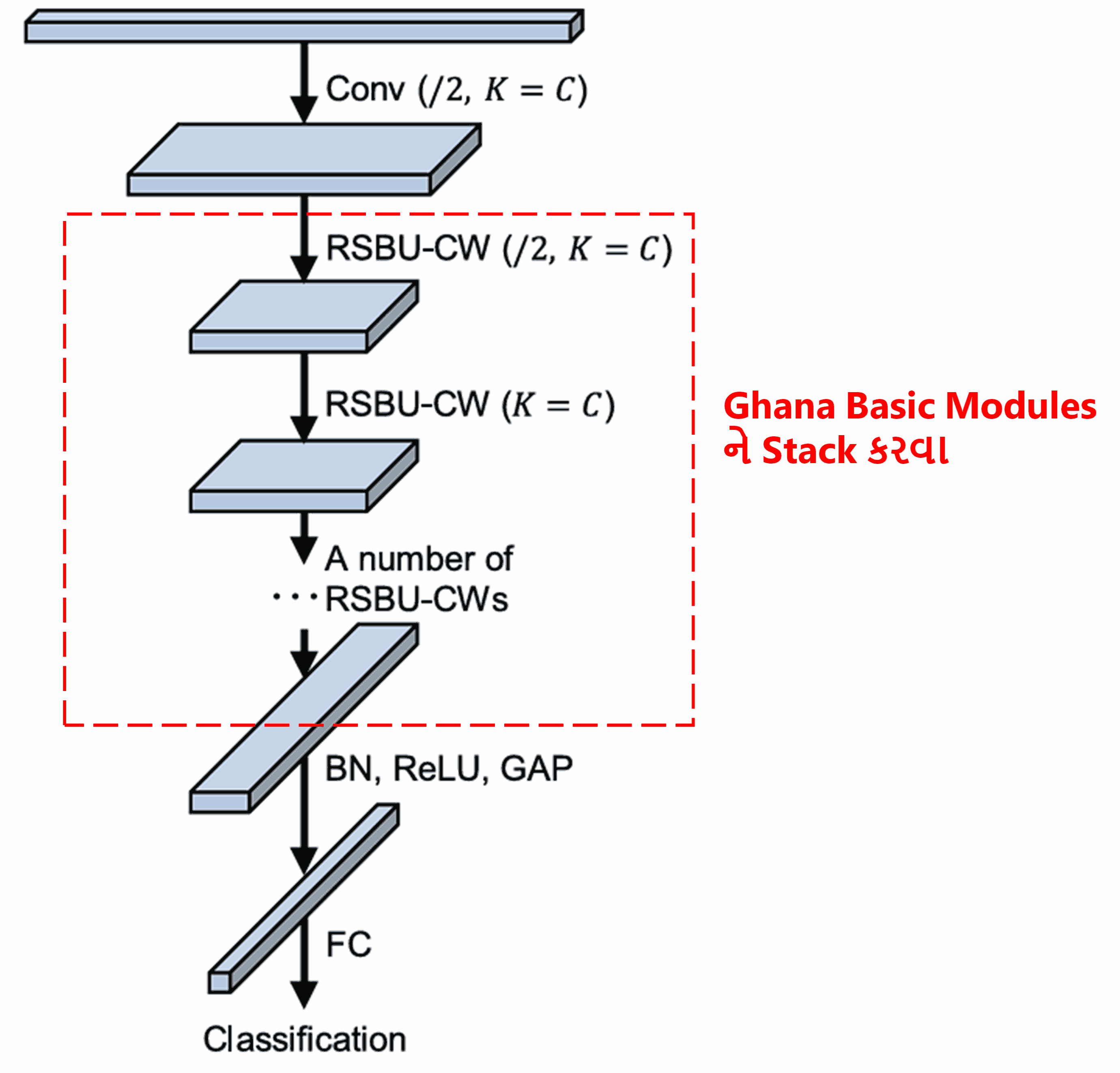
અંતે, અમુક ચોક્કસ સંખ્યામાં basic modules, convolutional layers, Batch Normalization, activation functions, Global Average Pooling અને Fully Connected output layers ને stack કરવાથી (એકબીજા પર ગોઠવવાથી) સંપૂર્ણ Deep Residual Shrinkage Network તૈયાર થાય છે.
5. Generalization Capability (સામાન્ય ઉપયોગિતા)
Deep Residual Shrinkage Network વાસ્તવમાં એક general feature learning method છે. કારણ કે ઘણા feature learning tasks માં, samples માં થોડો ઘણો noise અથવા irrelevant information હોય જ છે. આ noise અને irrelevant information, feature learning ના performance પર અસર કરી શકે છે. ઉદાહરણ તરીકે:
Image classification માં, જો ફોટામાં બીજા ઘણા objects હોય, તો આ objects ને “noise” તરીકે ગણી શકાય; Deep Residual Shrinkage Network કદાચ attention mechanism ની મદદથી આ “noise” ને notice કરી શકે છે, અને પછી soft thresholding દ્વારા આ “noise” ના features ને zero બનાવી શકે છે, જેનાથી image classification ની accuracy વધી શકે છે.
Speech recognition માં, જો અવાજવાળા વાતાવરણમાં (જેમ કે રોડની બાજુમાં કે factory માં) વાતચીત થતી હોય, તો Deep Residual Shrinkage Network કદાચ speech recognition ની accuracy વધારી શકે છે, અથવા ચોકસાઈ વધારવા માટેનો એક નવો વિચાર પૂરો પાડી શકે છે.
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Academic Impact (શૈક્ષણિક પ્રભાવ)
આ રિસર્ચ પેપરને Google Scholar પર 1400 થી વધુ citations મળ્યા છે.
એક અંદાજ મુજબ, Deep Residual Shrinkage Network (DRSN) નો ઉપયોગ 1000 થી વધુ publications માં કરવામાં આવ્યો છે. આ પદ્ધતિનો સીધો ઉપયોગ અથવા તેમાં સુધારો કરીને Mechanical, Electric Power, Computer Vision, Healthcare, Speech Processing, Text Analysis, Radar, અને Remote Sensing જેવા અનેક ક્ષેત્રોમાં ઉપયોગ કરવામાં આવ્યો છે.