O Deep Residual Shrinkage Network (DRSN) é unha variante mellorada da Deep Residual Network (ResNet). Esencialmente, é unha integración da Deep Residual Network, mecanismos de atención e funcións de limiarizado suave (soft thresholding).
Ata certo punto, o principio de funcionamento do Deep Residual Shrinkage Network pódese entender do seguinte xeito: utiliza mecanismos de atención para identificar características non importantes e emprega funcións de limiarizado suave para poñelas a cero; pola contra, identifica características importantes e consérvaas. Este proceso reforza a capacidade da rede neuronal profunda para extraer características útiles de sinais que conteñen ruído.
1. Motivación da investigación
En primeiro lugar, ao clasificar mostras, a presenza de ruído —como o ruído gaussiano, o ruído rosa e o ruído laplaciano— é inevitable. Nun sentido máis amplo, as mostras adoitan conter información irrelevante para a tarefa de clasificación actual, o que tamén se pode interpretar como ruído. Este ruído pode afectar negativamente ao rendemento da clasificación. (O limiarizado suave é un paso clave en moitos algoritmos de eliminación de ruído de sinais).
Por exemplo, durante unha conversa á beira da estrada, o audio pode mesturarse cos sons das bucinas e das rodas dos coches. Ao realizar o recoñecemento de voz nestes sinais, os resultados veranse inevitablemente afectados por estes sons de fondo. Desde a perspectiva do Deep Learning (aprendizaxe profunda), as características correspondentes ás bucinas e rodas deberían ser eliminadas dentro da rede neuronal profunda para evitar que afecten aos resultados do recoñecemento de voz.
En segundo lugar, mesmo dentro do mesmo conxunto de datos, a cantidade de ruído adoita variar dunha mostra a outra. (Isto comparte similitudes cos mecanismos de atención; tomando como exemplo un conxunto de datos de imaxes, a localización do obxecto obxectivo pode diferir entre as imaxes, e os mecanismos de atención poden centrarse na localización específica do obxecto obxectivo en cada imaxe).
Por exemplo, ao adestrar un clasificador de cans e gatos, consideremos cinco imaxes etiquetadas como “can”. A primeira imaxe pode conter un can e un rato, a segunda un can e un ganso, a terceira un can e unha galiña, a cuarta un can e un burro, e a quinta un can e un pato. Durante o adestramento, o clasificador verase inevitablemente sometido á interferencia de obxectos irrelevantes como ratos, gansos, galiñas, burros e patos, o que resultará nunha diminución da precisión (accuracy) da clasificación. Se podemos identificar estes obxectos irrelevantes e eliminar as súas características correspondentes, é posible mellorar a precisión do clasificador de cans e gatos.
2. Limiarizado Suave (Soft Thresholding)
O limiarizado suave é un paso fundamental en moitos algoritmos de eliminación de ruído de sinais. Elimina as características cuxo valor absoluto é inferior a un certo limiar e contrae cara a cero aquelas cuxo valor absoluto é superior a este limiar. Pódese implementar utilizando a seguinte fórmula:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]A derivada da saída do limiarizado suave con respecto á entrada é:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Como se mostra arriba, a derivada do limiarizado suave é 1 ou 0. Esta propiedade é idéntica á da función de activación ReLU. Polo tanto, o limiarizado suave tamén pode reducir o risco de que os algoritmos de Deep Learning atopen problemas de desaparición do gradiente (gradient vanishing) e explosión do gradiente (gradient exploding).
Na función de limiarizado suave, a configuración do limiar debe cumprir dúas condicións: primeira, o limiar debe ser un número positivo; segunda, o limiar non pode exceder o valor máximo do sinal de entrada, se non a saída será totalmente cero.
Ademais, é preferible que o limiar cumpra unha terceira condición: cada mostra debería ter o seu propio limiar independente baseado no seu contido de ruído.
Isto débese a que o contido de ruído adoita variar entre as mostras. Por exemplo, é común dentro do mesmo conxunto de datos que a Mostra A conteña menos ruído mentres que a Mostra B conteña máis ruído. Neste caso, ao realizar o limiarizado suave nun algoritmo de redución de ruído, a Mostra A debería utilizar un limiar máis pequeno, mentres que a Mostra B debería utilizar un limiar máis grande. Aínda que estas características e limiares perden as súas definicións físicas explícitas nas redes neuronais profundas, a lóxica subxacente básica segue a ser a mesma. É dicir, cada mostra debe ter o seu propio limiar independente determinado polo seu contido de ruído específico.
3. Mecanismo de Atención
O mecanismo de atención é relativamente fácil de entender no campo da visión por computador (Computer Vision). Os sistemas visuais dos animais poden distinguir obxectivos escaneando rapidamente toda a área, centrando posteriormente a atención no obxecto obxectivo para extraer máis detalles mentres suprimen a información irrelevante. Para máis detalles, consulte a literatura sobre mecanismos de atención.
A Squeeze-and-Excitation Network (SENet) representa un método de Deep Learning relativamente novo que utiliza mecanismos de atención. Nas diferentes mostras, a contribución das diferentes canles de características á tarefa de clasificación a miúdo varía. A SENet emprega unha pequena subrede para obter un conxunto de pesos e logo multiplica estes pesos polas características das canles respectivas para axustar a magnitude das características en cada canle. Este proceso pódese ver como a aplicación de diferentes niveis de atención a diferentes canles de características.
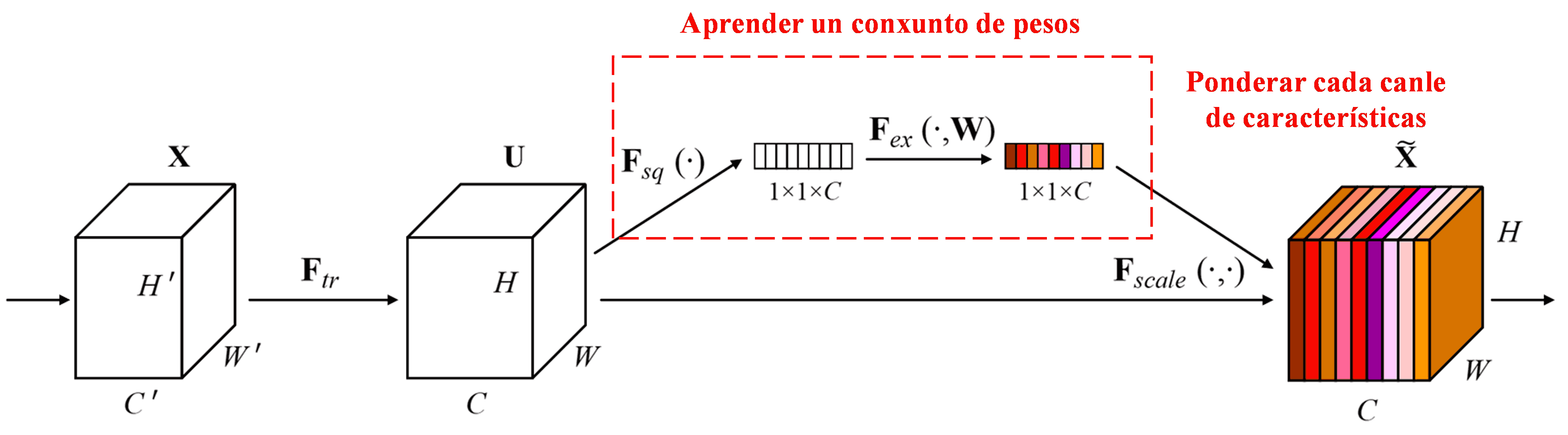
Neste enfoque, cada mostra posúe o seu propio conxunto independente de pesos. Noutras palabras, os pesos para dúas mostras arbitrarias calquera son diferentes. Na SENet, o camiño específico para obter os pesos é “Global Pooling → Capa Totalmente Conectada → Función ReLU → Capa Totalmente Conectada → Función Sigmoid”.
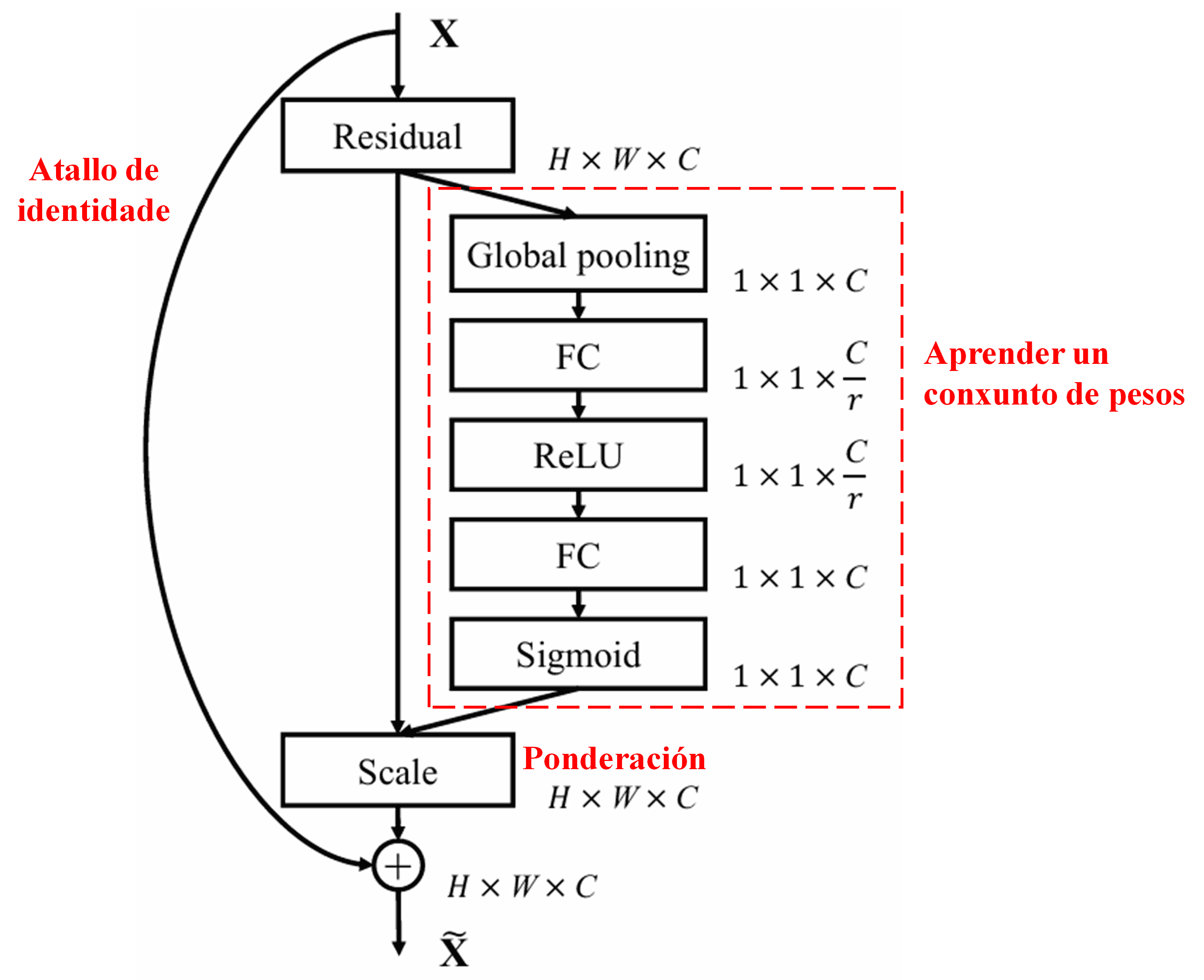
4. Limiarizado Suave baixo un Mecanismo de Atención Profunda
O Deep Residual Shrinkage Network inspírase na estrutura da subrede SENet antes mencionada para implementar o limiarizado suave baixo un mecanismo de atención profunda. A través da subrede (indicada dentro do cadro vermello), pódese aprender un conxunto de limiares para aplicar o limiarizado suave a cada canle de características.
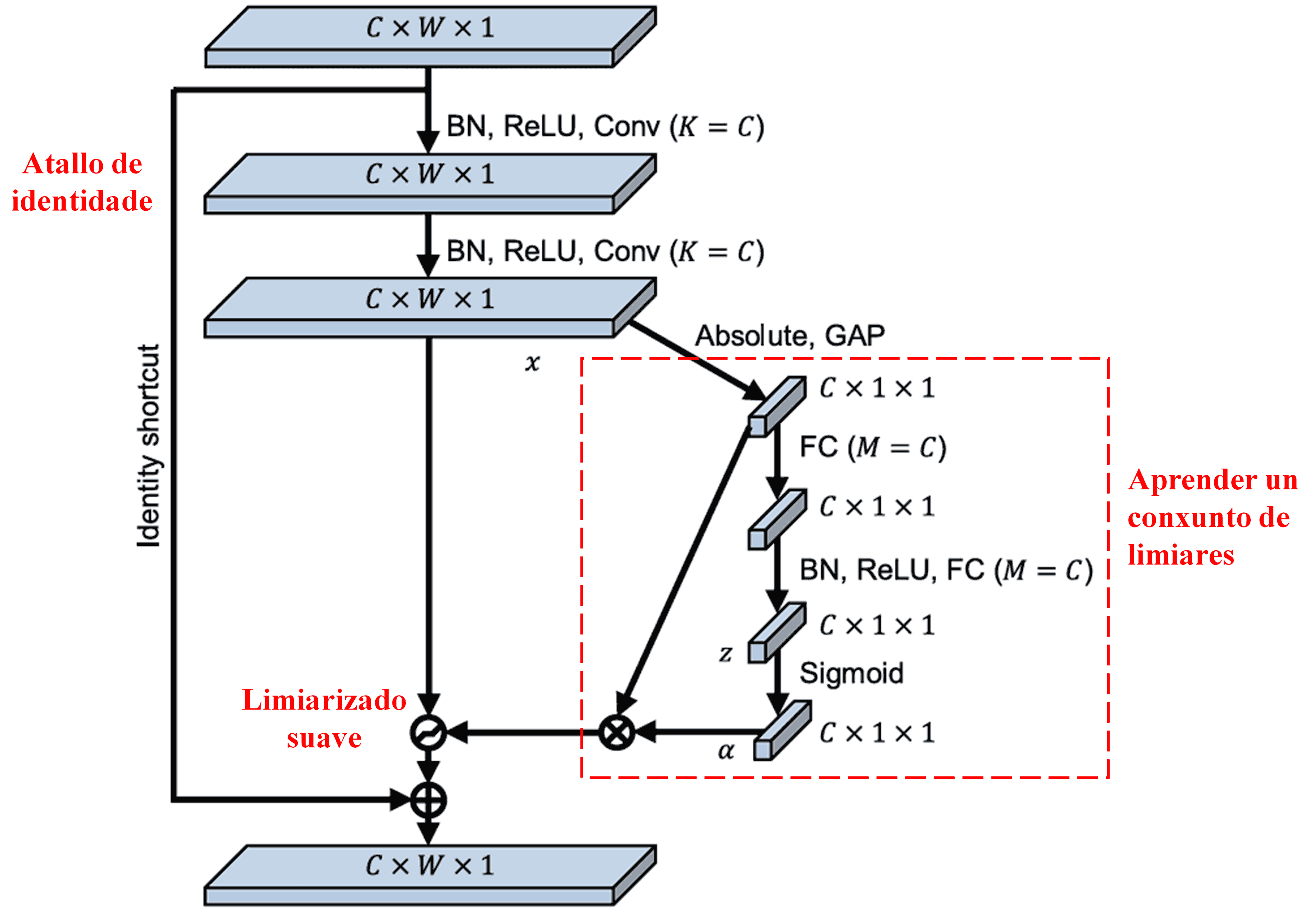
Nesta subrede, primeiro calcúlanse os valores absolutos de todas as características no mapa de características de entrada. Logo, a través do Global Average Pooling e a media, obtense unha característica, denotada como A. No outro camiño, o mapa de características despois do Global Average Pooling introdúcese nunha pequena rede totalmente conectada (Fully Connected network). Esta rede utiliza a función Sigmoid como a súa última capa para normalizar a saída entre 0 e 1, obtendo un coeficiente denotado como α. O limiar final pódese expresar como α × A. Polo tanto, o limiar é o produto dun número entre 0 e 1 e a media dos valores absolutos do mapa de características. Este método garante que o limiar non só sexa positivo, senón que tamén non sexa excesivamente grande.
Ademais, diferentes mostras dan lugar a diferentes limiares. En consecuencia, ata certo punto, isto pódese interpretar como un mecanismo de atención especializado: identifica características irrelevantes para a tarefa actual, transfórmaas en valores próximos a cero a través de dúas capas convolucionais e póñas a cero mediante o limiarizado suave; alternativamente, identifica características relevantes para a tarefa actual, transfórmaas en valores lonxe de cero a través de dúas capas convolucionais e presérvaas.
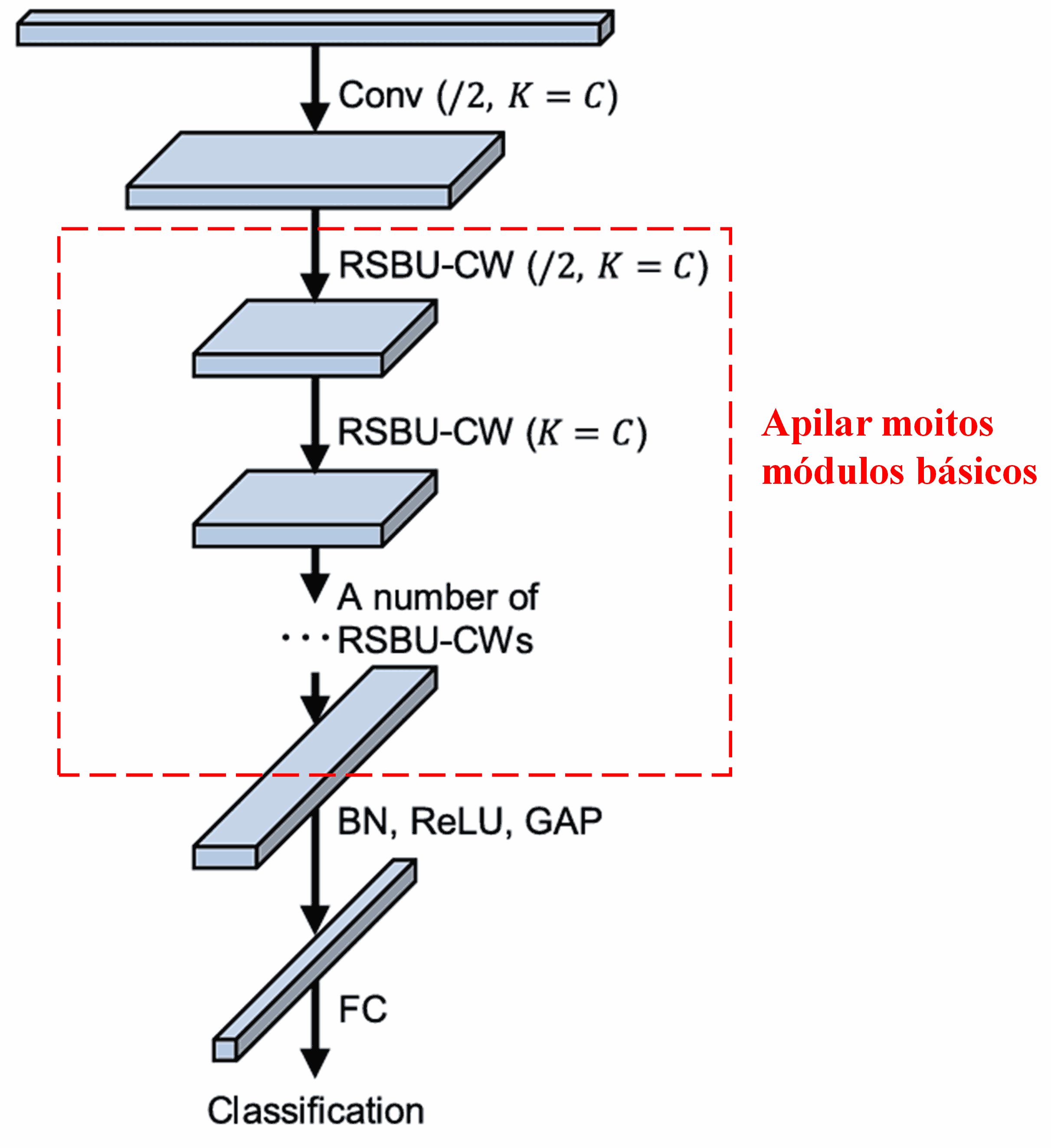
Finalmente, apilando un certo número de módulos básicos xunto con capas convolucionais, Batch Normalization, funcións de activación, Global Average Pooling e capas de saída totalmente conectadas, constrúese o Deep Residual Shrinkage Network completo.
5. Capacidade de Xeneralización
O Deep Residual Shrinkage Network é, de feito, un método xenérico de aprendizaxe de características. Isto débese a que, en moitas tarefas de aprendizaxe de características, as mostras conteñen máis ou menos algún ruído, así como información irrelevante. Este ruído e información irrelevante poden afectar ao rendemento da aprendizaxe de características. Por exemplo:
Na clasificación de imaxes, se unha imaxe contén simultaneamente moitos outros obxectos, estes obxectos pódense entender como “ruído”. O Deep Residual Shrinkage Network pode ser capaz de utilizar o mecanismo de atención para notar este “ruído” e logo empregar o limiarizado suave para poñer a cero as características correspondentes a este “ruído”, mellorando así potencialmente a precisión da clasificación de imaxes.
No recoñecemento de voz, especificamente en ambientes relativamente ruidosos como conversas á beira da estrada ou dentro do taller dunha fábrica, o Deep Residual Shrinkage Network pode mellorar a precisión do recoñecemento de voz ou, polo menos, ofrecer unha metodoloxía capaz de mellorar dita precisión.
Referencias
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Situación de Impacto
As citas deste artigo en Google Scholar superaron as 1400.
Segundo estimacións conservadoras, os Deep Residual Shrinkage Networks (DRSN) foron utilizados en máis de 1000 publicacións. Estes traballos aplicaron directamente ou melloraron a rede nunha ampla gama de campos, incluíndo a enxeñaría mecánica, a enerxía eléctrica, a visión por computador, a saúde, o procesamento de voz, a análise de textos, o radar e a teledetección.