Die Deep Residual Shrinkage Network (DRSN) is ‘n verbeterde weergawe van die klassieke Deep Residual Network (ResNet). In wese is dit ‘n integrasie van die ResNet, aandagsmeganismes (attention mechanisms) en sagte drempelbepalingsfunksies (soft thresholding functions).
Tot ‘n sekere mate kan die werking van die Deep Residual Shrinkage Network soos volg verstaan word: dit gebruik aandagsmeganismes om onbelangrike kenmerke (features) raak te sien en gebruik dan sagte drempelbepaling om hulle nul te maak; andersyds merk dit belangrike kenmerke op en behou hulle. Hierdie proses versterk die diep neurale netwerk se vermoë om nuttige kenmerke uit seine wat geraas bevat, te onttrek.
1. Navorsingsmotivering
Eerstens, wanneer monsters (samples) geklassifiseer word, is die teenwoordigheid van geraas – soos Gaussian geraas, pienk geraas en Laplacian geraas – onvermydelik. In ‘n breër sin bevat monsters dikwels inligting wat irrelevant is vir die huidige klassifikansietaak, wat ook as “geraas” geïnterpreteer kan word. Hierdie geraas kan ‘n nadelige effek op die klassifikasieprestasie hê. (Sagte drempelbepaling is ‘n kernstap in baie sein-ruisonderdrukkingsalgoritmes.)
Byvoorbeeld, tydens ‘n gesprek langs die pad, kan die klank vermeng word met die geluide van motors se toeters en wiele. Wanneer spraakherkenning op hierdie seine uitgevoer word, sal die resultate onvermydelik deur hierdie agtergrondgeluide beïnvloed word. Vanuit ‘n diepleer-perspektief (deep learning perspective) behoort die kenmerke wat met die toeters en wiele ooreenstem, binne die diep neurale netwerk verwyder te word om te voorkom dat hulle die spraakherkenning beïnvloed.
Tweedens, selfs binne dieselfde datastel, wissel die hoeveelheid geraas dikwels van monster tot monster. (Dit toon ooreenkomste met aandagsmeganismes; as ons ‘n beelddatastel as voorbeeld neem, kan die posisie van die teikenvoorwerp van foto tot foto verskil, en aandagsmeganismes kan op die spesifieke posisie van die teikenvoorwerp in elke foto fokus.)
As voorbeeld: wanneer ‘n klassifiseerder vir katte en honde opgelei word, oorweeg 5 beelde met die etiket “hond”. Die 1ste beeld bevat dalk ‘n hond en ‘n muis, die 2de ‘n hond en ‘n gans, die 3de ‘n hond en ‘n hoender, die 4de ‘n hond en ‘n donkie, en die 5de ‘n hond en ‘n eend. Tydens opleiding sal die klassifiseerder onvermydelik gesteur word deur irrelevante voorwerpe soos muise, ganse, hoenders, donkies en eende, wat lei tot ‘n afname in akkuraatheid. As ons hierdie irrelevante voorwerpe kan identifiseer en hul ooreenstemmende kenmerke kan verwyder, is dit moontlik om die akkuraatheid van die kat-en-hond-klassifiseerder te verbeter.
2. Sagte Drempelbepaling (Soft Thresholding)
Sagte drempelbepaling is ‘n kernstap in baie sein-ruisonderdrukkingsalgoritmes. Dit verwyder kenmerke waarvan die absolute waardes laer as ‘n sekere drempel (threshold) is, en krimp kenmerke waarvan die absolute waardes hoër is as hierdie drempel in die rigting van nul. Dit kan geïmplementeer word met die volgende formule:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Die afgeleide van die sagte drempelbepaling se uitset met betrekking tot die inset is:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Soos hierbo getoon, is die afgeleide van sagte drempelbepaling óf 1 óf 0. Hierdie eienskap is identies aan dié van die ReLU-aktiveringsfunksie (ReLU activation function). Daarom kan sagte drempelbepaling ook die risiko verminder dat diepleer-algoritmes probleme soos gradient vanishing en gradient exploding ervaar.
In die sagte drempelbepalingsfunksie moet die stelling van die drempel aan twee voorwaardes voldoen: eerstens moet die drempel ‘n positiewe getal wees; tweedens mag die drempel nie groter wees as die maksimum waarde van die insetsein nie, anders sal die uitset heeltemal nul wees.
Daarbenewens is dit wenslik dat die drempel aan ‘n derde voorwaarde voldoen: elke monster (sample) moet sy eie onafhanklike drempel hê, gebaseer op sy eie geraasinhoud.
Dit is omdat die geraasinhoud dikwels tussen monsters verskil. Dit gebeur byvoorbeeld gereeld binne dieselfde datastel dat Monster A minder geraas bevat, terwyl Monster B meer geraas bevat. In hierdie geval, wanneer sagte drempelbepaling in ‘n ruisonderdrukkingsalgoritme toegepas word, behoort Monster A ‘n kleiner drempel te gebruik, terwyl Monster B ‘n groter drempel moet gebruik. Alhoewel hierdie kenmerke en drempels hul eksplisiete fisiese definisies in diep neurale netwerke verloor, bly die basiese logika dieselfde. Met ander woorde, elke monster behoort sy eie onafhanklike drempel te hê wat deur sy spesifieke geraasinhoud bepaal word.
3. Aandagsmeganisme (Attention Mechanism)
Aandagsmeganismes is redelik maklik om te verstaan in die veld van rekenaarvisie (computer vision). Diere se visuele stelsels kan vinnig ‘n hele area skandeer om teikenvoorwerpe te vind, en dan hul aandag op die teiken fokus om meer detail te onttrek, terwyl irrelevante inligting onderdruk word. Vir meer besonderhede, verwys asseblief na literatuur oor aandagsmeganismes.
Die Squeeze-and-Excitation Network (SENet) is ‘n relatief nuwe diepleer-metode wat van aandagsmeganismes gebruik maak. Oor verskillende monsters heen is die bydrae van verskillende kenmerk-kanale (feature channels) tot die klassifikansietaak dikwels verskillend. SENet gebruik ‘n klein sub-netwerk om ‘n stel gewigte te verkry, en vermenigvuldig dan hierdie gewigte met die kenmerke van die onderskeie kanale om die grootte van die kenmerke aan te pas. Hierdie proses kan gesien word as die toepassing van verskillende vlakke van aandag op verskillende kenmerk-kanale.
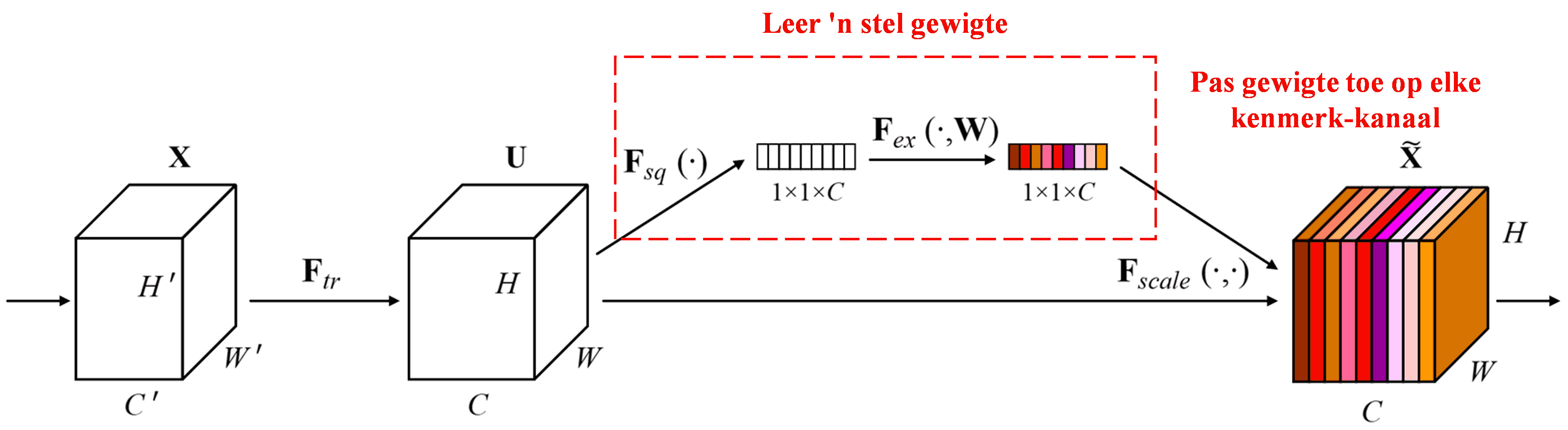
In hierdie benadering besit elke monster sy eie onafhanklike stel gewigte. Met ander woorde, die gewigte vir enige twee willekeurige monsters is verskillend. In SENet is die spesifieke pad om gewigte te verkry: “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”.
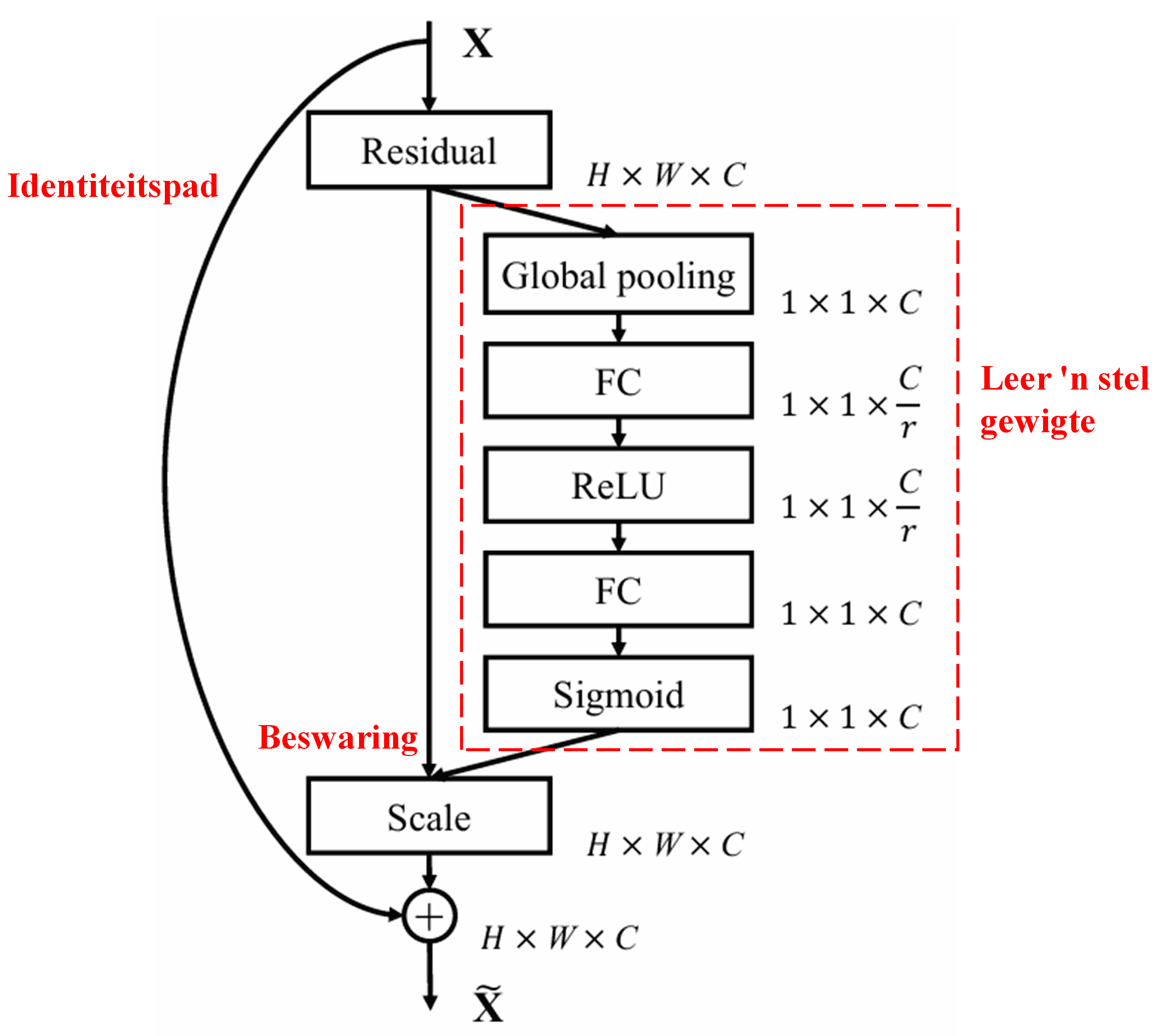
4. Sagte Drempelbepaling met ‘n Diep Aandagsmeganisme
Die Deep Residual Shrinkage Network put inspirasie uit die bogenoemde SENet-substruktuur om sagte drempelbepaling onder ‘n diep aandagsmeganisme te implementeer. Deur middel van die sub-netwerk (aangedui binne die rooi blok), kan ‘n stel drempels aangeleer word om sagte drempelbepaling op elke kenmerk-kanaal toe te pas.
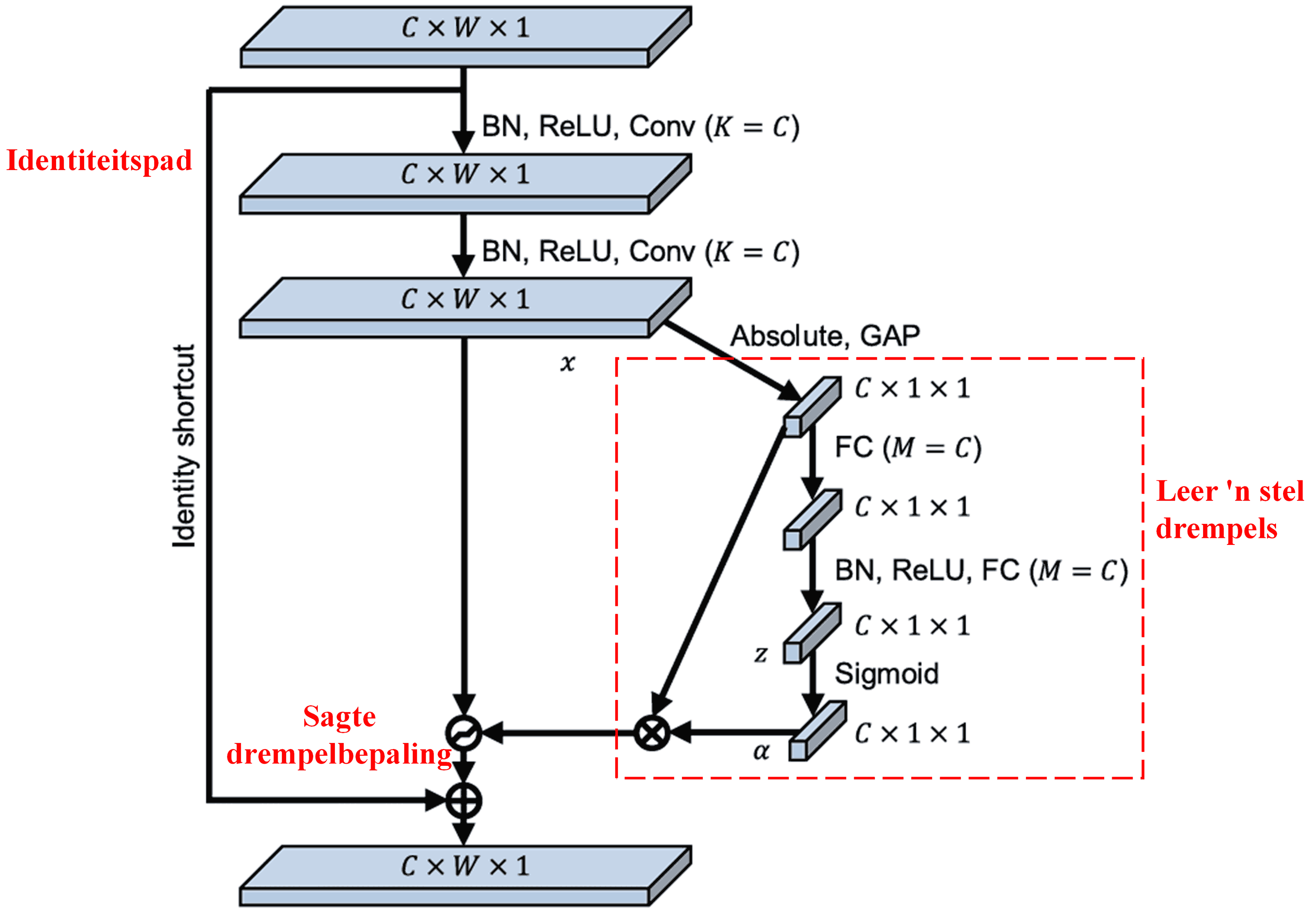
In hierdie sub-netwerk word die absolute waardes van alle kenmerke in die inset-kenmerkkaart (input feature map) eers bereken. Daarna, deur middel van Global Average Pooling en middeling, word ‘n kenmerk verkry, aangedui as A. In die ander pad word die kenmerkkaart ná Global Average Pooling in ‘n klein Fully Connected Network ingevoer. Hierdie netwerk gebruik die Sigmoid-funksie as sy laaste laag om die uitset tussen 0 en 1 te normaliseer, wat ‘n koëffisiënt lewer, aangedui as α. Die finale drempel kan uitgedruk word as α × A. Daarom is die drempel die produk van ‘n getal tussen 0 en 1 en die gemiddelde van die absolute waardes van die kenmerkkaart. Hierdie metode verseker dat die drempel nie net positief is nie, maar ook nie buitensporig groot is nie.
Verder het verskillende monsters verskillende drempels. Gevolglik kan dit tot ‘n sekere mate as ‘n gespesialiseerde aandagsmeganisme geïnterpreteer word: dit merk kenmerke op wat irrelevant is vir die huidige taak, transformeer hulle na waardes naby aan nul via twee konvolusionele lae (convolutional layers), en stel hulle op nul deur middel van sagte drempelbepaling; alternatiewelik merk dit kenmerke op wat relevant is vir die huidige taak, transformeer hulle na waardes ver van nul, en behou hulle.
Laastens, deur ‘n sekere aantal basiese modules saam met konvolusionele lae, Batch Normalization, aktiveringsfunksies, Global Average Pooling en Fully Connected uitsetlae te stapel, word die volledige Deep Residual Shrinkage Network gevorm.
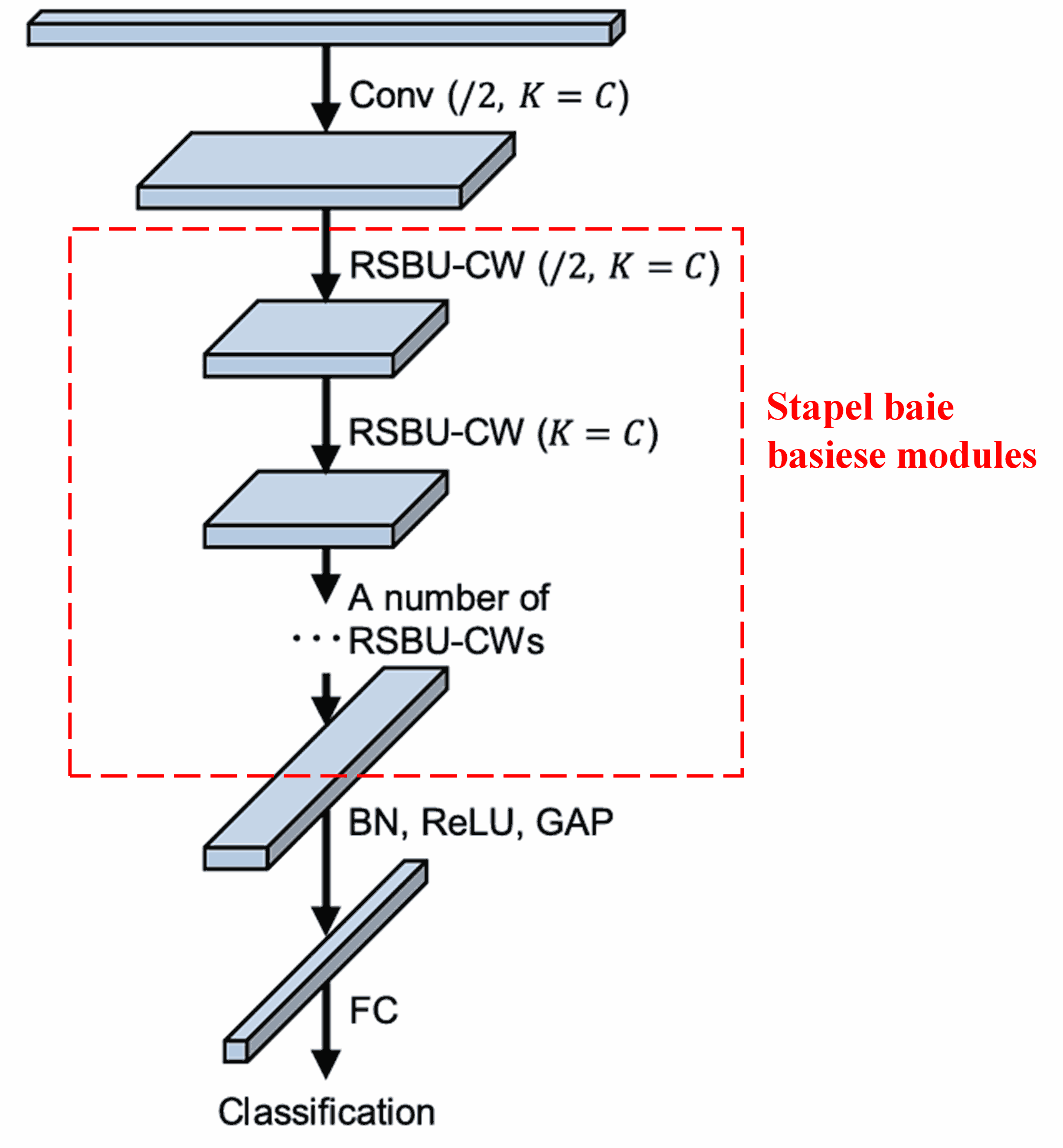
5. Algemene Toepasbaarheid
Die Deep Residual Shrinkage Network is in werklikheid ‘n algemene kenmerk-leer-metode (feature learning method). Dit is omdat monsters in baie kenmerk-leer-take min of meer geraas sowel as irrelevante inligting bevat. Hierdie geraas en irrelevante inligting kan die prestasie van kenmerk-leer beïnvloed. Byvoorbeeld:
In beeldklassifikasie, as ‘n beeld gelyktydig baie ander voorwerpe bevat, kan hierdie voorwerpe as “geraas” verstaan word. Die Deep Residual Shrinkage Network mag in staat wees om die aandagsmeganisme te gebruik om hierdie “geraas” op te merk, en dan sagte drempelbepaling te gebruik om die kenmerke wat met hierdie “geraas” ooreenstem, op nul te stel, wat moontlik die akkuraatheid van beeldklassifikasie kan verbeter.
In spraakherkenning, spesifiek in omgewings met relatief baie geraas soos tydens ‘n gesprek langs die pad of binne ‘n fabriek, kan die Deep Residual Shrinkage Network die akkuraatheid van spraakherkenning verbeter, of ten minste ‘n benadering bied wat die potensiaal het om akkuraatheid te verhoog.
Verwysings
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Akademiese Impak
Hierdie artikel het reeds meer as 1400 sitasies op Google Scholar ontvang.
Volgens onvolledige statistiek is Deep Residual Shrinkage Networks (DRSN) reeds in meer as 1000 publikasies gebruik. Hierdie werke het die netwerk óf direk toegepas óf verbeter vir gebruik in ‘n wye verskeidenheid velde, insluitend meganiese ingenieurswese, elektriese krag, rekenaarvisie, mediese toepassings, spraakverwerking, teksanalise, radar en afstandswaarneming (remote sensing).