Deep Residual Shrinkage Networks (DRSN) je unapređena varijanta dubokih rezidualnih mreža (ResNet). U suštini, to je integracija ResNet-a, mehanizama pažnje (attention mechanisms) i funkcija mekog pragovanja (soft thresholding).
U određenoj meri, princip rada DRSN-a se može razumeti na sledeći način: pomoću mehanizma pažnje primećuje nevažna obeležja (features) i postavlja ih na nulu koristeći funkciju mekog pragovanja; ili, drugim rečima, primećuje važna obeležja i zadržava ih. Ovaj proces pojačava sposobnost duboke neuronske mreže da izvuče korisna obeležja iz signala koji sadrže šum.
1. Motivacija za istraživanje
Prvo, prilikom klasifikacije uzoraka, prisustvo šuma – kao što su Gausov šum, ružičasti šum i Laplasov šum – je neizbežno. Šire gledano, uzorci često sadrže informacije koje nisu relevantne za trenutni zadatak klasifikacije, što se takođe može tumačiti kao šum. Ovaj šum može negativno uticati na performanse klasifikacije. (Meko pragovanje je ključni korak u mnogim algoritmima za uklanjanje šuma).
Na primer, tokom razgovora pored puta, zvuk govora može biti pomešan sa zvukom automobilskih sirena i točkova. Kada se na ovim signalima vrši prepoznavanje govora, rezultati će neizbežno biti pod uticajem ovih pozadinskih zvukova. Iz perspektive dubokog učenja (Deep Learning), obeležja koja odgovaraju sirenama i točkovima treba da budu eliminisana unutar duboke neuronske mreže kako bi se sprečio njihov uticaj na rezultate prepoznavanja govora.
Drugo, čak i u okviru istog skupa podataka, količina šuma često varira od uzorka do uzorka. (Ovo ima sličnosti sa mehanizmima pažnje; uzimajući skup slika kao primer, lokacija ciljnog objekta može se razlikovati od slike do slike, a mehanizmi pažnje mogu da se fokusiraju na specifičnu lokaciju ciljnog objekta na svakoj slici).
Na primer, kada treniramo klasifikator za pse i mačke, zamislimo 5 slika označenih kao „pas“. Prva slika može sadržati psa i miša, druga psa i gusku, treća psa i kokošku, četvrta psa i magarca, a peta psa i patku. Tokom treninga, klasifikator će neizbežno trpeti ometanja od strane irelevantnih objekata kao što su miševi, guske, kokoške, magarci i patke, što dovodi do pada tačnosti klasifikacije. Ako bismo mogli da primetimo ove irelevantne objekte – miševe, guske, kokoške, magarce i patke – i eliminišemo njihova odgovarajuća obeležja, moguće je povećati tačnost klasifikatora za pse i mačke.
2. Meko pragovanje (Soft Thresholding)
Meko pragovanje je ključni korak u mnogim algoritmima za uklanjanje šuma (denoising). Ono eliminiše obeležja čija je apsolutna vrednost manja od određenog praga, a obeležja čija je apsolutna vrednost veća od tog praga „skuplja“ (shrinks) ka nuli. Ovo se može implementirati pomoću sledeće formule:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Izvod izlaza mekog pragovanja u odnosu na ulaz je:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Kao što se vidi iznad, izvod mekog pragovanja je ili 1 ili 0. Ovo svojstvo je identično kao kod ReLU aktivacione funkcije. Zbog toga, meko pragovanje takođe može smanjiti rizik da algoritmi dubokog učenja naiđu na problem nestajanja ili eksplozije gradijenta (gradient vanishing and exploding).
U funkciji mekog pragovanja, podešavanje praga mora da zadovolji dva uslova: prvo, prag mora biti pozitivan broj; drugo, prag ne sme biti veći od maksimalne vrednosti ulaznog signala, inače će izlaz biti u potpunosti nula.
Istovremeno, najbolje je da prag zadovoljava i treći uslov: svaki uzorak treba da ima svoj nezavisni prag zasnovan na sopstvenoj količini šuma.
To je zato što sadržaj šuma često varira među uzorcima. Na primer, uobičajeno je da unutar istog skupa podataka uzorak A sadrži manje šuma, dok uzorak B sadrži više šuma. U tom slučaju, kada se vrši meko pragovanje u algoritmu za uklanjanje šuma, uzorak A bi trebalo da koristi manji prag, dok bi uzorak B trebalo da koristi veći prag. Iako ova obeležja i pragovi gube svoje eksplicitne fizičke definicije u dubokim neuronskim mrežama, osnovna logika ostaje ista. Drugim rečima, svaki uzorak treba da ima sopstveni nezavisni prag određen njegovim specifičnim sadržajem šuma.
3. Mehanizam pažnje (Attention Mechanism)
Mehanizme pažnje je relativno lako razumeti u oblasti kompjuterskog vida (Computer Vision). Vizuelni sistemi životinja mogu razlikovati mete brzim skeniranjem čitavog područja, nakon čega fokusiraju pažnju na ciljni objekat kako bi izvukli više detalja, istovremeno potiskujući irelevantne informacije. Za detalje, molimo pogledajte literaturu o mehanizmima pažnje.
Squeeze-and-Excitation Network (SENet) predstavlja relativno nov metod dubokog učenja koji koristi mehanizme pažnje. Kod različitih uzoraka, doprinos različitih kanala obeležja (feature channels) zadatku klasifikacije često varira. SENet koristi malu pod-mrežu da dobije skup težina (weights), a zatim množi te težine sa obeležjima odgovarajućih kanala kako bi prilagodio veličinu obeležja u svakom kanalu. Ovaj proces se može posmatrati kao primena različitih nivoa pažnje na različite kanale obeležja.
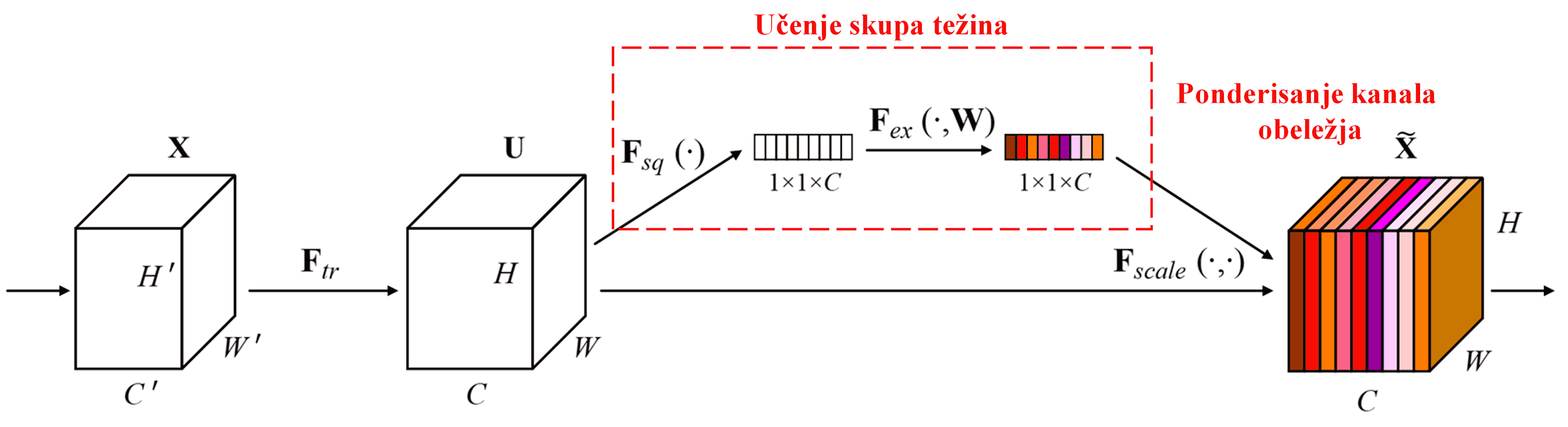
U ovom pristupu, svaki uzorak poseduje sopstveni nezavisni skup težina. Drugim rečima, težine za bilo koja dva proizvoljna uzorka su različite. U SENet-u, specifična putanja za dobijanje težina je „Globalno usrednjavanje (Global Pooling) → Potpuno povezani sloj (Fully Connected Layer) → ReLU funkcija → Potpuno povezani sloj → Sigmoid funkcija“.
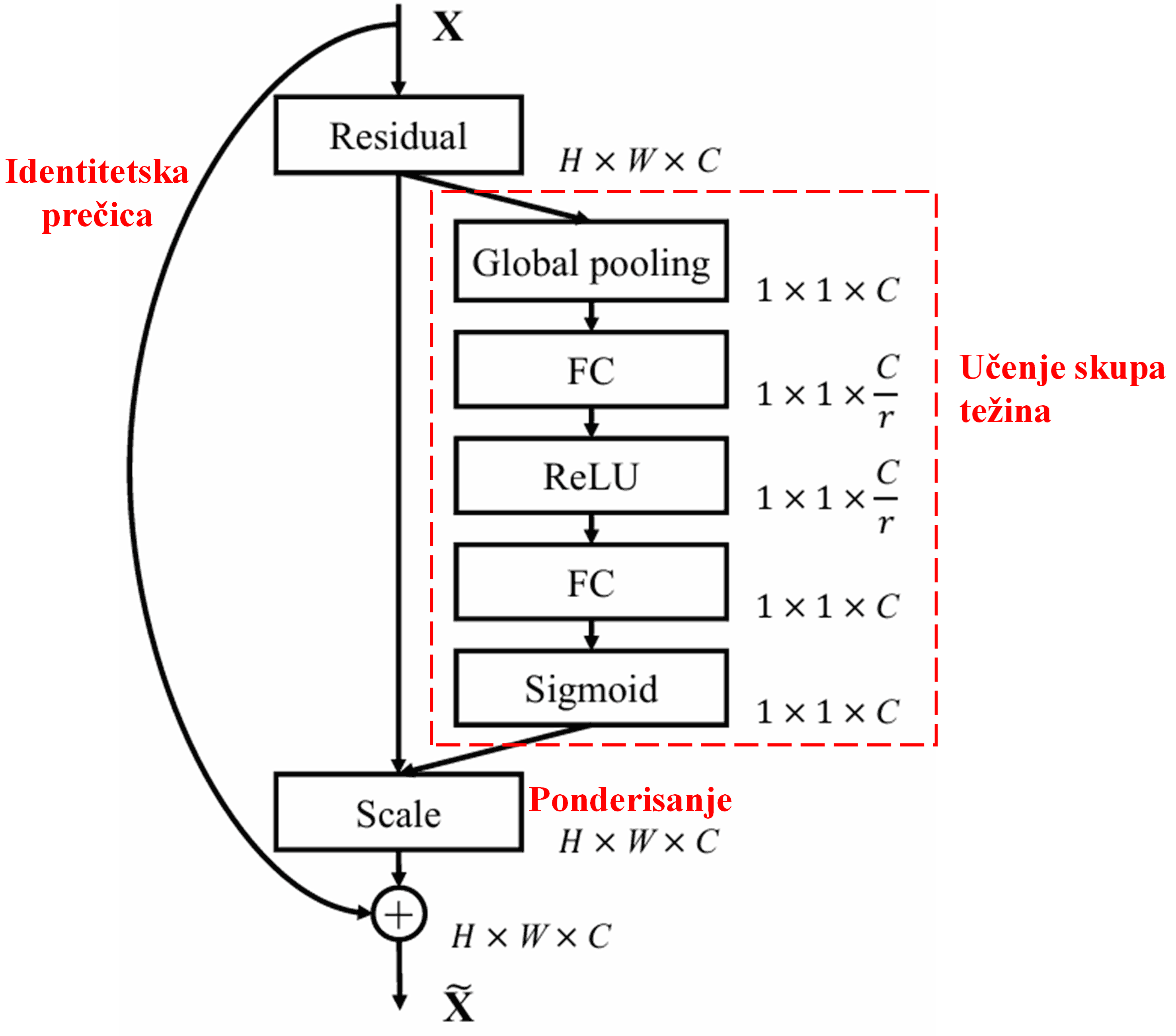
4. Meko pragovanje sa dubokim mehanizmom pažnje
Deep Residual Shrinkage Network crpi inspiraciju iz gorepomenute strukture SENet pod-mreže kako bi implementirao meko pragovanje pod dubokim mehanizmom pažnje. Kroz pod-mrežu (prikazanu unutar crvenog okvira), može se naučiti skup pragova kako bi se primenilo meko pragovanje na svaki kanal obeležja.
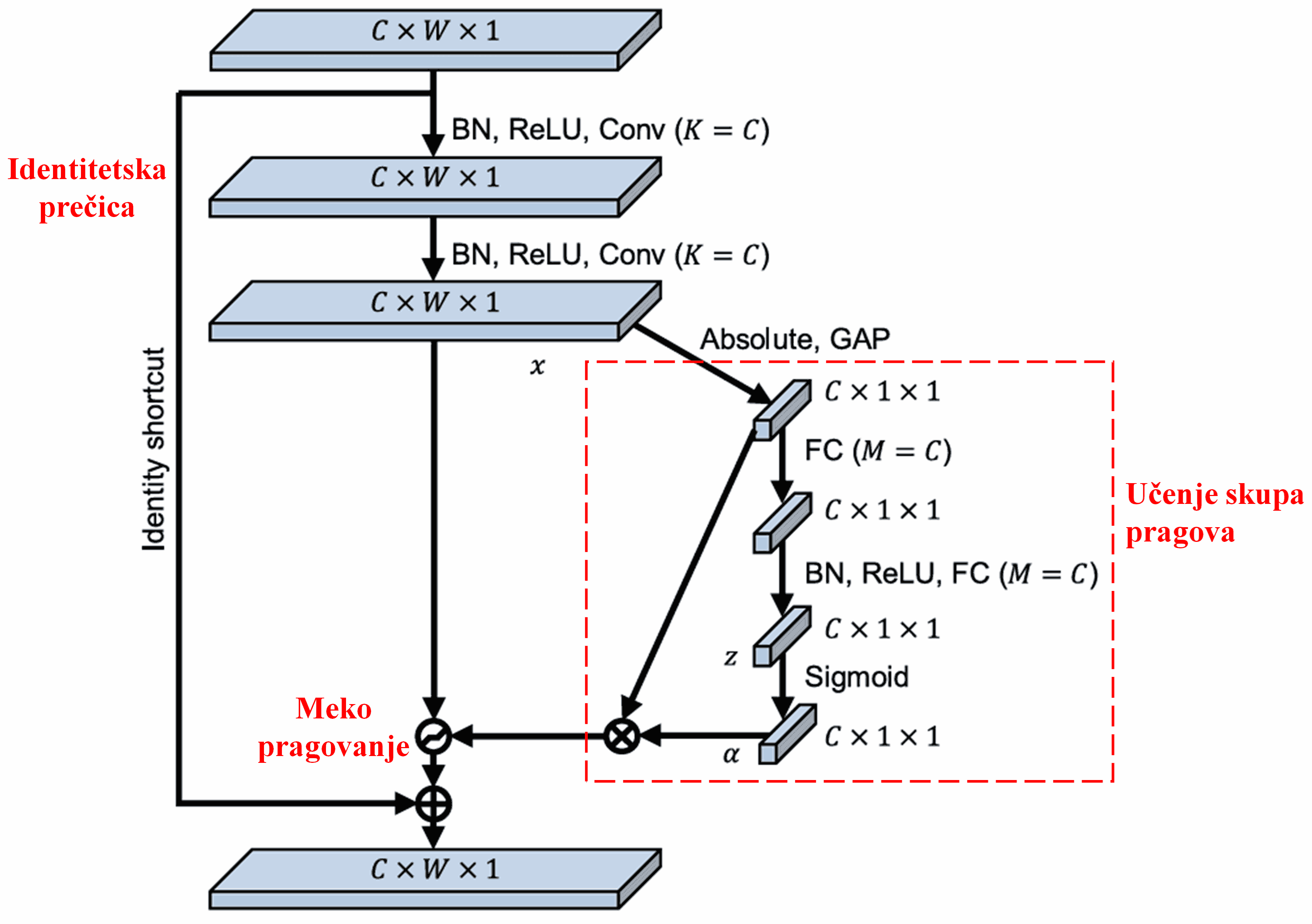
U ovoj pod-mreži, prvo se izračunavaju apsolutne vrednosti svih obeležja na ulaznoj mapi obeležja (feature map). Zatim se, kroz globalno prosečno sažimanje (Global Average Pooling - GAP) i usrednjavanje, dobija jedno obeležje, označeno kao A. U drugoj putanji, mapa obeležja nakon globalnog usrednjavanja se uvodi u malu potpuno povezanu mrežu. Ova potpuno povezana mreža koristi Sigmoid funkciju kao svoj poslednji sloj za normalizaciju izlaza između 0 i 1, dajući koeficijent označen kao α. Konačni prag se može izraziti kao α × A. Dakle, prag je proizvod broja između 0 i 1 i proseka apsolutnih vrednosti mape obeležja. Ovaj metod osigurava da prag nije samo pozitivan, već i da nije prevelik.
Štaviše, različiti uzorci rezultiraju različitim pragovima. Posledično, u određenoj meri, ovo se može tumačiti kao specijalizovani mehanizam pažnje: on primećuje obeležja irelevantna za trenutni zadatak, transformiše ih u vrednosti bliske nuli putem dva konvoluciona sloja i postavlja ih na nulu koristeći meko pragovanje; ili alternativno, primećuje obeležja relevantna za trenutni zadatak, transformiše ih u vrednosti daleko od nule putem dva konvoluciona sloja i zadržava ih.
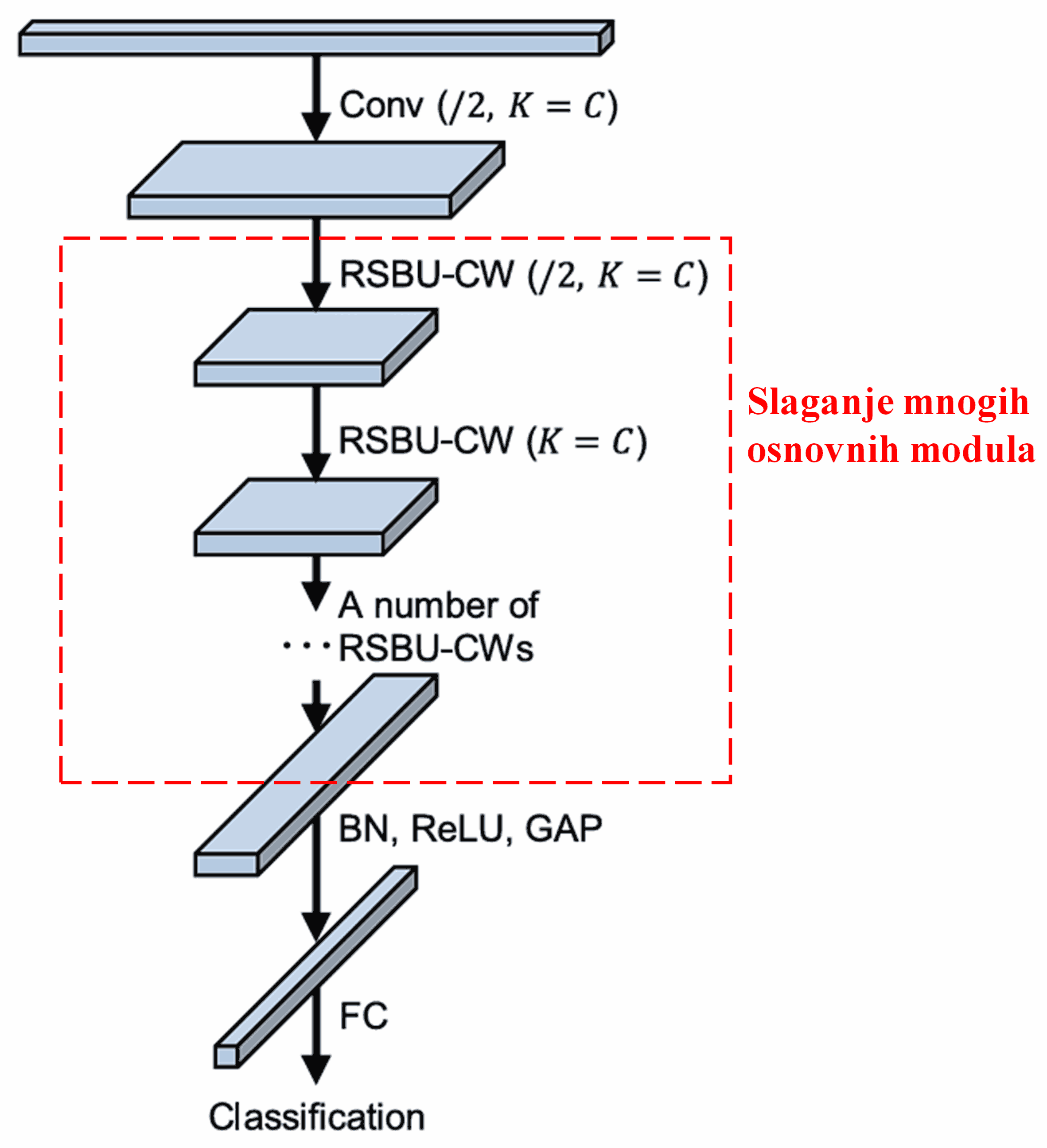
Konačno, slaganjem određenog broja osnovnih modula zajedno sa konvolucionim slojevima, Batch normalizacijom (BN), aktivacionim funkcijama, globalnim prosečnim sažimanjem (GAP) i potpuno povezanim izlaznim slojevima, konstruiše se kompletan Deep Residual Shrinkage Network.
5. Mogućnost generalizacije
Deep Residual Shrinkage Network je, zapravo, opšta metoda za učenje obeležja. To je zato što u mnogim zadacima učenja obeležja, uzorci manje ili više sadrže određeni šum kao i irelevantne informacije. Ovaj šum i irelevantne informacije mogu uticati na performanse učenja obeležja. Na primer:
U klasifikaciji slika, ako slika istovremeno sadrži mnogo drugih objekata, ovi objekti se mogu razumeti kao „šum“. Deep Residual Shrinkage Network bi mogao biti u stanju da iskoristi mehanizam pažnje da primeti ovaj „šum“, a zatim upotrebi meko pragovanje da postavi obeležja koja odgovaraju ovom „šumu“ na nulu, čime se potencijalno poboljšava tačnost klasifikacije slika.
U prepoznavanju govora, specifično u relativno bučnim okruženjima kao što su razgovori pored puta ili unutar fabričkih hala, Deep Residual Shrinkage Network može poboljšati tačnost prepoznavanja govora, ili barem ponuditi metodologiju sposobnu za poboljšanje tačnosti prepoznavanja govora.
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Uticaj u akademskoj zajednici
Ovaj rad je citiran više od 1400 puta na Google Scholar-u.
Prema nepotpunim statistikama, Deep Residual Shrinkage Networks (DRSN) su korišćene u više od 1000 publikacija. Ovi radovi su ili direktno primenili ili unapredili mrežu kroz širok spektar oblasti, uključujući mašinstvo, elektroenergetiku, kompjuterski vid, zdravstvo, obradu govora, analizu teksta, radar i daljinsku detekciju.