Deep Residual Shrinkage Network (DRSN) je vylepšenou verziou architektúry ResNet. V podstate ide o integráciu sietí ResNet, mechanizmov pozornosti (attention mechanisms) a funkcií mäkkého prahovania (soft thresholding).
Princíp fungovania Deep Residual Shrinkage Network možno do určitej miery chápať takto: pomocou mechanizmu pozornosti si všíma nepodstatné príznaky (features) a prostredníctvom funkcie mäkkého prahovania ich nuluje; respektíve si všíma dôležité príznaky a ponecháva ich. Tým sa posilňuje schopnosť hlbokej neurónovej siete extrahovať užitočné informácie zo signálov obsahujúcich šum.
1. Motivácia výskumu
Po prvé, pri klasifikácii vzoriek je nevyhnutné, že budú obsahovať určitý šum, ako napríklad Gaussov šum, ružový šum alebo Laplaceov šum. V širšom zmysle vzorky často obsahujú informácie, ktoré nesúvisia s aktuálnou klasifikačnou úlohou, čo možno tiež chápať ako šum. Tento šum môže mať negatívny vplyv na výsledky klasifikácie. (Mäkké prahovanie je kľúčovým krokom v mnohých algoritmoch na odšumovanie signálu).
Ak sa napríklad rozprávate pri ceste, hlas môže byť zmiešaný so zvukmi klaksónov a kolies áut. Pri rozpoznávaní reči z týchto signálov bude výsledok nevyhnutne ovplyvnený týmito zvukmi. Z pohľadu hlbokého učenia (Deep Learning) by mali byť príznaky (features) zodpovedajúce klaksónom a kolesám vnútri neurónovej siete odstránené, aby sa predišlo ich vplyvu na rozpoznávanie reči.
Po druhé, aj v rámci tej istej dátovej sady sa miera šumu v jednotlivých vzorkách často líši. (Toto má spoločné črty s mechanizmom pozornosti; ak vezmeme ako príklad sadu obrázkov, poloha cieľového objektu môže byť na každom obrázku iná a mechanizmus pozornosti sa dokáže zamerať na polohu cieľového objektu v každom konkrétnom obrázku).
Napríklad pri trénovaní klasifikátora mačiek a psov máme 5 obrázkov s označením „pes“. Prvý obrázok môže obsahovať psa a myš, druhý psa a hus, tretí psa a sliepku, štvrtý psa a somára a piaty psa a kačicu. Pri trénovaní klasifikátora budeme nevyhnutne vystavení rušeniu zo strany irelevantných objektov, ako sú myši, husi, sliepky, somáre a kačice, čo spôsobí pokles presnosti klasifikácie. Ak dokážeme tieto irelevantné objekty zaznamenať a odstrániť príznaky, ktoré im zodpovedajú, môžeme zvýšiť presnosť klasifikátora.
2. Mäkké prahovanie (Soft Thresholding)
Mäkké prahovanie je kľúčovým krokom v mnohých algoritmoch na odšumovanie signálu. Odstraňuje príznaky, ktorých absolútna hodnota je menšia ako určitý prah (threshold), a príznaky s absolútnou hodnotou väčšou ako tento prah „zmršťuje“ (shrinks) smerom k nule. Možno ho realizovať pomocou nasledujúceho vzorca:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Derivácia výstupu mäkkého prahovania podľa vstupu je:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Z uvedeného vyplýva, že derivácia mäkkého prahovania je buď 1, alebo 0. Táto vlastnosť je zhodná s aktivačnou funkciou ReLU. Preto mäkké prahovanie dokáže znížiť riziko, že sa algoritmy hlbokého učenia stretnú s problémom zanikania gradientov (gradient vanishing) alebo explózie gradientov (gradient exploding).
Pri funkcii mäkkého prahovania musí nastavenie prahu spĺňať dve podmienky: po prvé, prah musí byť kladné číslo; po druhé, prah nesmie byť väčší ako maximálna hodnota vstupného signálu, inak budú všetky výstupy nulové.
Zároveň je vhodné, aby prah spĺňal tretiu podmienku: každá vzorka by mala mať svoj vlastný nezávislý prah v závislosti od obsahu šumu.
Dôvodom je, že obsah šumu sa v rôznych vzorkách často líši. V tej istej dátovej sade sa napríklad bežne stáva, že vzorka A obsahuje menej šumu, zatiaľ čo vzorka B obsahuje viac šumu. Ak teda v odšumovacom algoritme vykonávame mäkké prahovanie, vzorka A by mala použiť menší prah a vzorka B väčší prah. Hoci v hlbokých neurónových sieťach tieto príznaky a prahy strácajú svoj explicitný fyzikálny význam, základná logika zostáva rovnaká. To znamená, že každá vzorka by mala mať svoj vlastný nezávislý prah určený na základe vlastného obsahu šumu.
3. Mechanizmus pozornosti (Attention Mechanism)
Mechanizmus pozornosti je v oblasti počítačového videnia pomerne ľahko pochopiteľný. Vizuálny systém zvierat dokáže rýchlo skenovať celú oblasť, objaviť cieľový objekt a následne sústrediť pozornosť na tento objekt, aby extrahoval viac detailov a zároveň potlačil irelevantné informácie. Podrobnosti nájdete v literatúre o mechanizmoch pozornosti.
Squeeze-and-Excitation Network (SENet) predstavuje novšiu metódu hlbokého učenia využívajúcu mechanizmus pozornosti. Rôzne kanály príznakov (feature channels) majú v rôznych vzorkách odlišný prínos pre klasifikačnú úlohu. SENet využíva malú podsieť na získanie sady váh (weights), ktorými následne vynásobí príznaky jednotlivých kanálov, čím upraví ich veľkosť. Tento proces možno považovať za aplikáciu rôznej miery pozornosti na jednotlivé kanály príznakov.
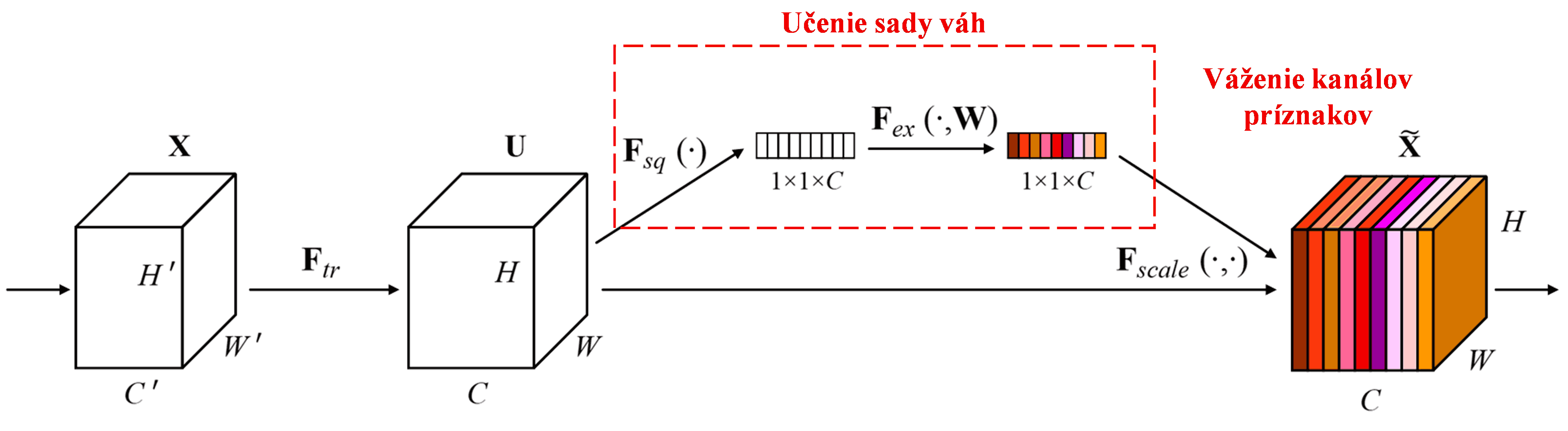
Týmto spôsobom má každá vzorka svoju vlastnú nezávislú sadu váh. Inými slovami, váhy pre ľubovoľné dve vzorky sú odlišné. V sieti SENet je konkrétna cesta na získanie váh nasledovná: „Globálny pooling → Plne prepojená vrstva → funkcia ReLU → Plne prepojená vrstva → funkcia Sigmoid“.
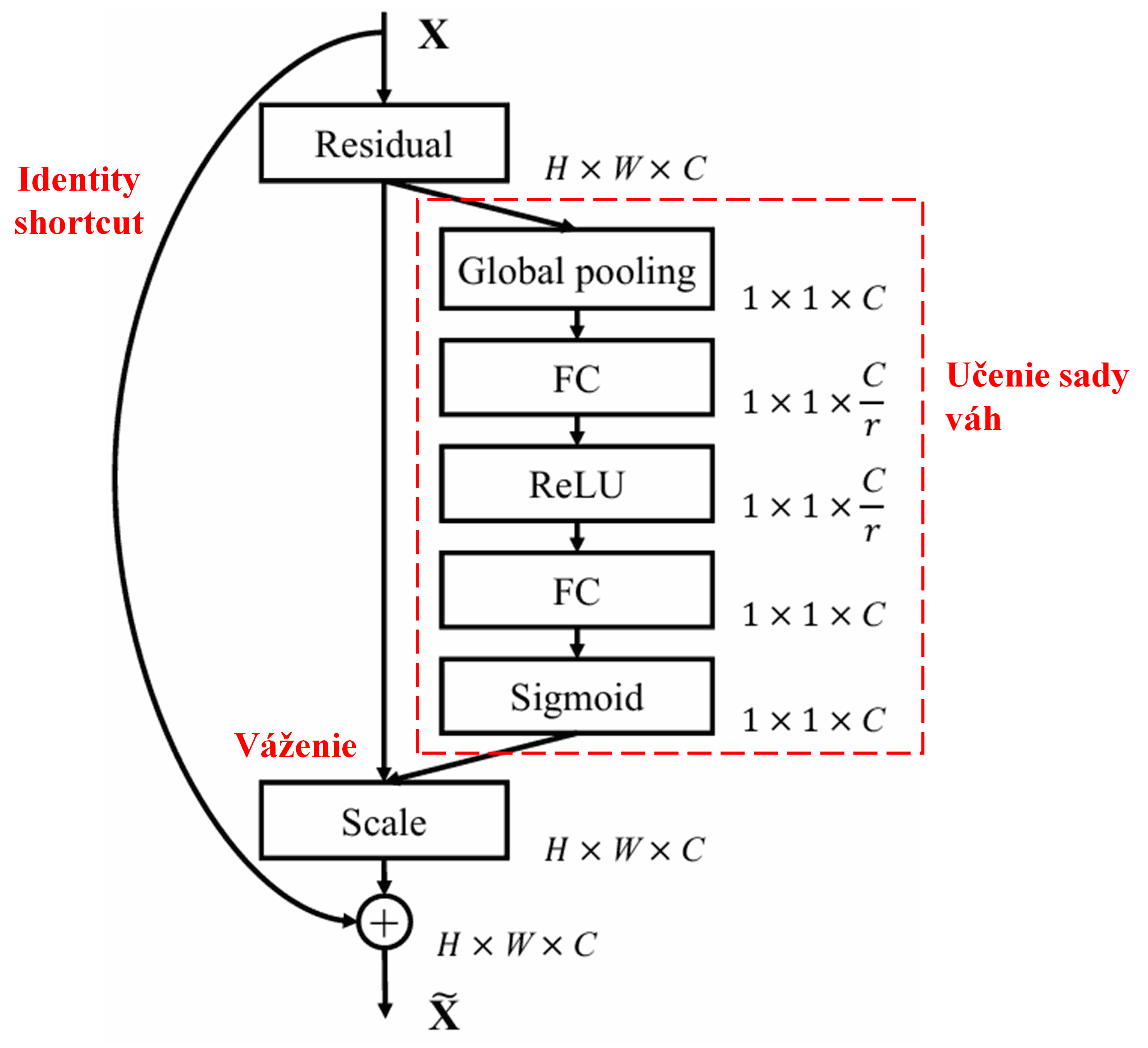
4. Mäkké prahovanie v rámci hlbokého mechanizmu pozornosti
Deep Residual Shrinkage Network sa inšpiruje spomínanou štruktúrou podsiete SENet na implementáciu mäkkého prahovania v rámci mechanizmu pozornosti. Prostredníctvom podsiete (zobrazenej v červenom rámčeku) sa dokáže naučiť sadu prahov, pomocou ktorých vykoná mäkké prahovanie pre každý kanál príznakov.
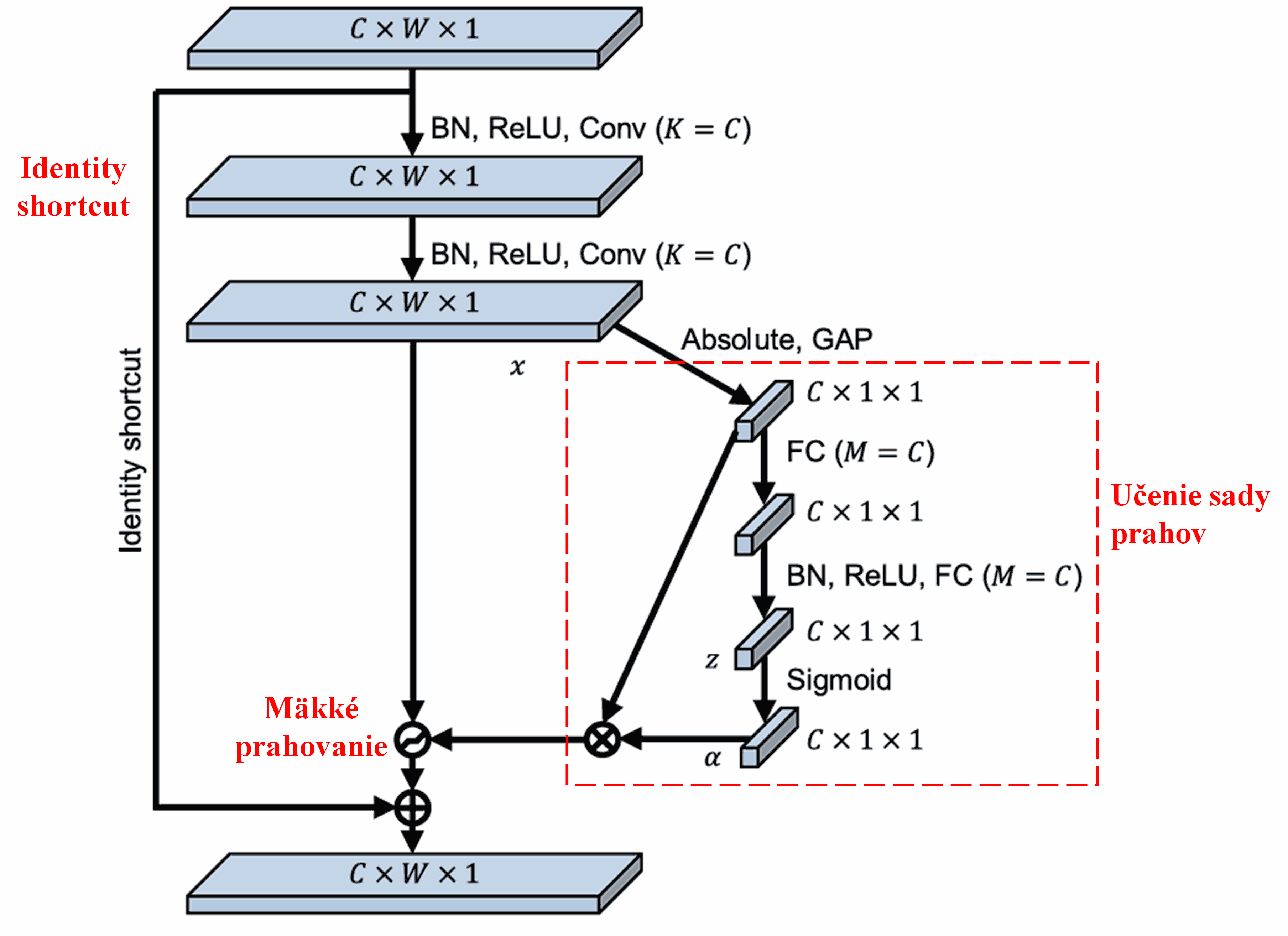
V tejto podsieti sa najprv vypočítajú absolútne hodnoty všetkých príznakov na vstupnej mape príznakov. Potom sa pomocou globálneho priemerného poolingu (Global Average Pooling - GAP) získa jeden príznak, označme ho ako A. V druhej vetve sa mapa príznakov po globálnom priemernom poolingu privedie do malej plne prepojenej siete. Táto plne prepojená sieť používa ako poslednú vrstvu funkciu Sigmoid, ktorá normalizuje výstup do rozsahu 0 až 1, čím vznikne koeficient, označme ho ako α. Výsledný prah možno vyjadriť ako α × A. Prahom je teda číslo medzi 0 a 1 vynásobené priemerom absolútnych hodnôt mapy príznakov. Tento spôsob zaručuje, že prah je nielen kladný, ale zároveň nie je príliš veľký.
Navyše, rôzne vzorky majú rôzne prahy. Do určitej miery to teda možno chápať ako špeciálny mechanizmus pozornosti: sieť si všimne príznaky, ktoré nesúvisia s aktuálnou úlohou, a prostredníctvom dvoch konvolučných vrstiev ich transformuje na hodnoty blízke nule, ktoré následne pomocou mäkkého prahovania vynuluje; alebo naopak, všimne si príznaky relevantné pre aktuálnu úlohu, transformuje ich na hodnoty vzdialené od nuly a zachová ich.
Nakoniec, navrstvením určitého počtu týchto základných modulov spolu s konvolučnými vrstvami, Batch Normalization (BN), aktivačnými funkciami, globálnym priemerným poolingom a plne prepojenou výstupnou vrstvou vznikne kompletná sieť Deep Residual Shrinkage Network.
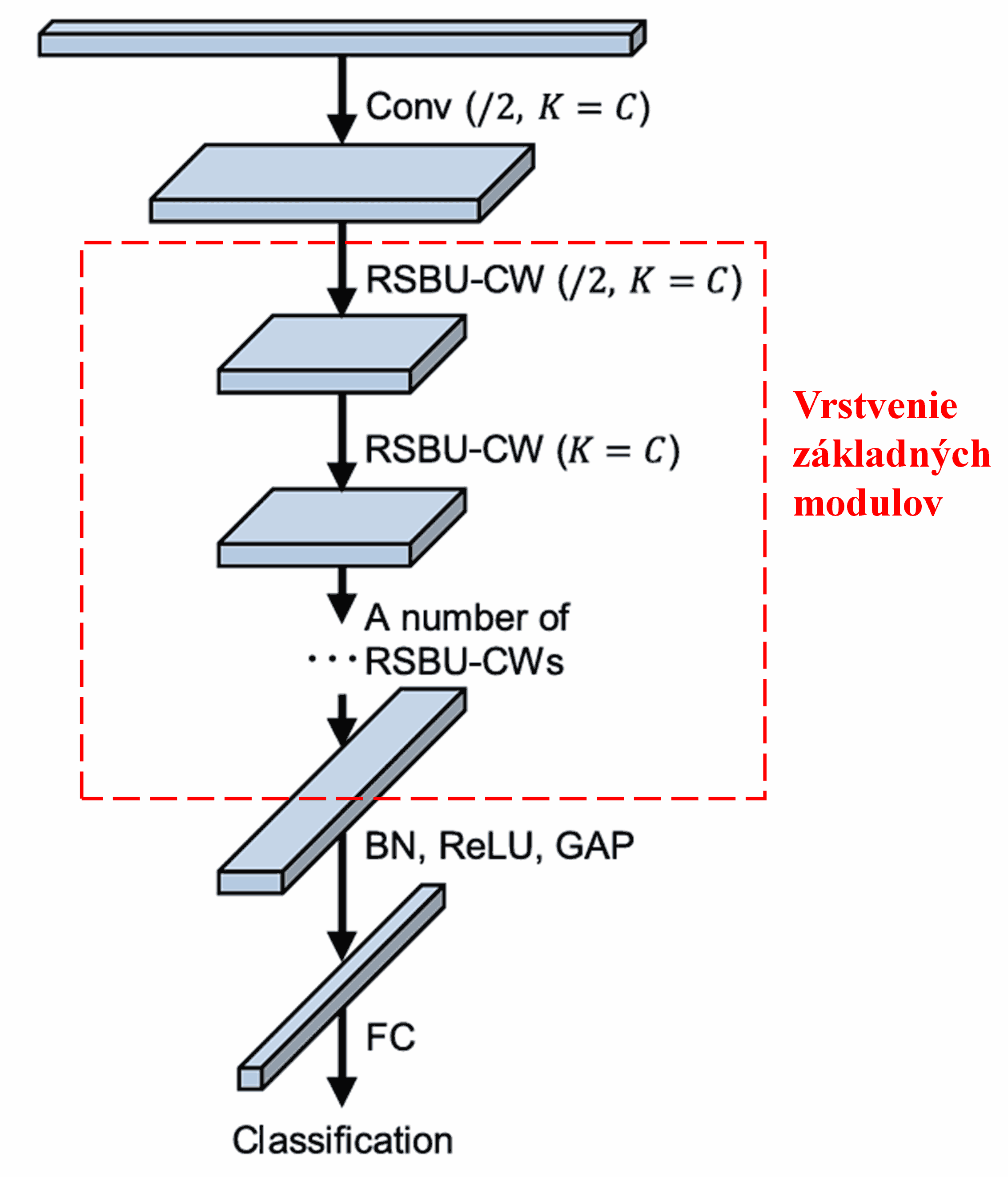
5. Univerzálnosť
Deep Residual Shrinkage Network je v skutočnosti univerzálnou metódou na učenie príznakov. Je to preto, že v mnohých úlohách učenia príznakov obsahujú vzorky viac či menej šumu, ako aj nerelevantné informácie. Tento šum a nerelevantné informácie môžu ovplyvniť efektivitu učenia. Napríklad:
Pri klasifikácii obrázkov, ak obrázok obsahuje mnoho iných objektov, možno tieto objekty chápať ako „šum“. Deep Residual Shrinkage Network dokáže pomocou mechanizmu pozornosti tento „šum“ zaznamenať a následne pomocou mäkkého prahovania vynulovať príznaky, ktoré mu zodpovedajú, čím sa môže zvýšiť presnosť klasifikácie obrázkov.
Pri rozpoznávaní reči, najmä v hlučnom prostredí, ako je rozhovor pri ceste alebo v továrenskej hale, môže Deep Residual Shrinkage Network zvýšiť presnosť rozpoznávania, alebo prinajmenšom ponúka myšlienku, ako túto presnosť zlepšiť.
Literatúra
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Vplyv a citácie
Tento článok má na Google Scholar už viac ako 1400 citácií.
Podľa neúplných štatistík bola sieť Deep Residual Shrinkage Network (DRSN) priamo použitá alebo vylepšená vo viac ako 1000 publikáciách v mnohých oblastiach vrátane strojárstva, energetiky, počítačového videnia, medicíny, spracovania hlasu a textu, radarových systémov a diaľkového prieskumu Zeme.