Deep Residual Shrinkage Network (DRSN) este o versiune îmbunătățită a Deep Residual Network (ResNet). În esență, aceasta reprezintă o integrare între ResNet, mecanismele de atenție (attention mechanisms) și funcțiile de soft thresholding.
Într-o oarecare măsură, principiul de funcționare al Deep Residual Shrinkage Network poate fi înțeles astfel: prin intermediul mecanismului de atenție, rețeaua observă caracteristicile neimportante și le reduce la zero folosind funcția de soft thresholding; sau, altfel spus, observă caracteristicile importante și le păstrează. Acest proces îmbunătățește capacitatea rețelelor neuronale profunde de a extrage caracteristici utile din semnalele care conțin zgomot.
1. Motivația Cercetării
În primul rând, atunci când clasificăm eșantioane, prezența zgomotului este inevitabilă, fie că vorbim de zgomot Gaussian, zgomot roz sau zgomot Laplacian. În sens larg, eșantioanele conțin adesea informații irelevante pentru sarcina curentă de clasificare, informații care pot fi, de asemenea, interpretate ca zgomot. Acest zgomot poate afecta negativ performanța clasificării. (Soft thresholding-ul este un pas cheie în mulți algoritmi de reducere a zgomotului, cunoscuți ca signal denoising).
De exemplu, într-o conversație pe marginea drumului, sunetul vocii poate fi amestecat cu claxoane și zgomotul roților. Atunci când efectuăm recunoașterea vocală pe aceste semnale, rezultatele vor fi inevitabil afectate de aceste sunete de fundal. Din perspectiva Deep Learning, caracteristicile (features) corespunzătoare claxoanelor și roților ar trebui eliminate în interiorul rețelei neuronale profunde pentru a nu afecta rezultatele recunoașterii vocale.
În al doilea rând, chiar și în cadrul aceluiași set de date, cantitatea de zgomot diferă adesea de la un eșantion la altul. (Acest lucru este similar cu principiul mecanismelor de atenție; de exemplu, luând un set de date cu imagini, poziția obiectului țintă poate diferi de la o imagine la alta, iar mecanismele de atenție se pot concentra pe locația specifică a obiectului țintă în fiecare imagine).
De exemplu, atunci când antrenăm un clasificator pentru câini și pisici, să luăm în considerare 5 imagini etichetate ca “câine”. Prima imagine ar putea conține un câine și un șoarece, a doua un câine și o gâscă, a treia un câine și o găină, a patra un câine și un măgar, iar a cincea un câine și o rață. În timpul antrenării, clasificatorul va fi inevitabil supus interferențelor cauzate de obiecte irelevante precum șoareci, gâște, găini, măgari și rațe, ceea ce duce la o scădere a acurateței clasificării. Dacă am putea identifica aceste obiecte irelevante și am elimina caracteristicile corespunzătoare lor, ar fi posibil să îmbunătățim acuratețea clasificatorului.
2. Soft Thresholding
Soft thresholding-ul este un pas esențial în mulți algoritmi de prelucrare a semnalului pentru reducerea zgomotului. Acesta elimină caracteristicile a căror valoare absolută este mai mică decât un anumit prag (threshold) și „contractă” spre zero caracteristicile a căror valoare absolută depășește acest prag. Poate fi implementat folosind următoarea formulă:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Derivata ieșirii funcției de soft thresholding în raport cu intrarea este:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Așa cum se observă mai sus, derivata soft thresholding-ului este fie 1, fie 0. Această proprietate este identică cu cea a funcției de activare ReLU. Prin urmare, soft thresholding-ul poate reduce, de asemenea, riscul ca algoritmii de Deep Learning să se confrunte cu problemele de dispariție a gradientului (gradient vanishing) sau explozie a gradientului (gradient exploding).
În funcția de soft thresholding, setarea pragului trebuie să îndeplinească două condiții: în primul rând, pragul trebuie să fie un număr pozitiv; în al doilea rând, pragul nu poate fi mai mare decât valoarea maximă a semnalului de intrare, altfel ieșirea va fi complet zero.
În plus, este de preferat ca pragul să îndeplinească o a treia condiție: fiecare eșantion ar trebui să aibă propriul prag independent, bazat pe cantitatea sa de zgomot.
Acest lucru se datorează faptului că nivelul de zgomot variază adesea între eșantioane. De exemplu, este comun ca în același set de date, Eșantionul A să conțină mai puțin zgomot, în timp ce Eșantionul B conține mai mult zgomot. În acest caz, atunci când aplicăm soft thresholding într-un algoritm de reducere a zgomotului, Eșantionul A ar trebui să utilizeze un prag mai mic, în timp ce Eșantionul B ar trebui să utilizeze un prag mai mare. Deși în rețelele neuronale profunde aceste caracteristici și praguri își pierd definițiile fizice explicite, logica de bază rămâne aceeași. Cu alte cuvinte, fiecare eșantion ar trebui să aibă propriul prag independent, determinat de conținutul său specific de zgomot.
3. Mecanismul de Atenție (Attention Mechanism)
Mecanismele de atenție sunt relativ ușor de înțeles în domeniul Computer Vision. Sistemul vizual al animalelor poate distinge țintele scanând rapid întreaga zonă, concentrându-și ulterior atenția asupra obiectului țintă pentru a extrage mai multe detalii, suprimând în același timp informațiile irelevante. Pentru detalii specifice, vă rugăm să consultați literatura de specialitate privind mecanismele de atenție.
Squeeze-and-Excitation Network (SENet) reprezintă o metodă relativ nouă de Deep Learning care utilizează mecanisme de atenție. În diferite eșantioane, contribuția diferitelor canale de caracteristici (feature channels) la sarcina de clasificare variază adesea. SENet folosește o sub-rețea mică pentru a obține un set de ponderi (weights) și apoi înmulțește aceste ponderi cu caracteristicile canalelor respective pentru a ajusta magnitudinea caracteristicilor din fiecare canal. Acest proces poate fi privit ca aplicarea unor niveluri diferite de atenție asupra canalelor de caracteristici.
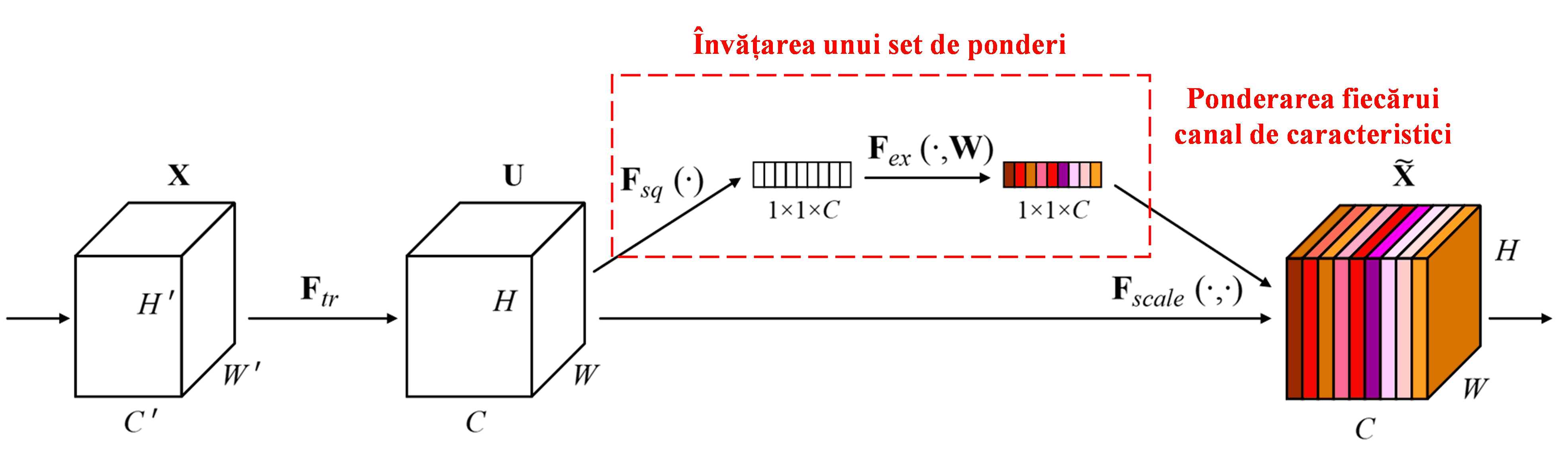
În această abordare, fiecare eșantion posedă propriul set independent de ponderi. Cu alte cuvinte, ponderile pentru oricare două eșantioane arbitrare sunt diferite. În SENet, calea specifică pentru obținerea ponderilor este: „Global Pooling → Strat Fully Connected → Funcția ReLU → Strat Fully Connected → Funcția Sigmoid”.
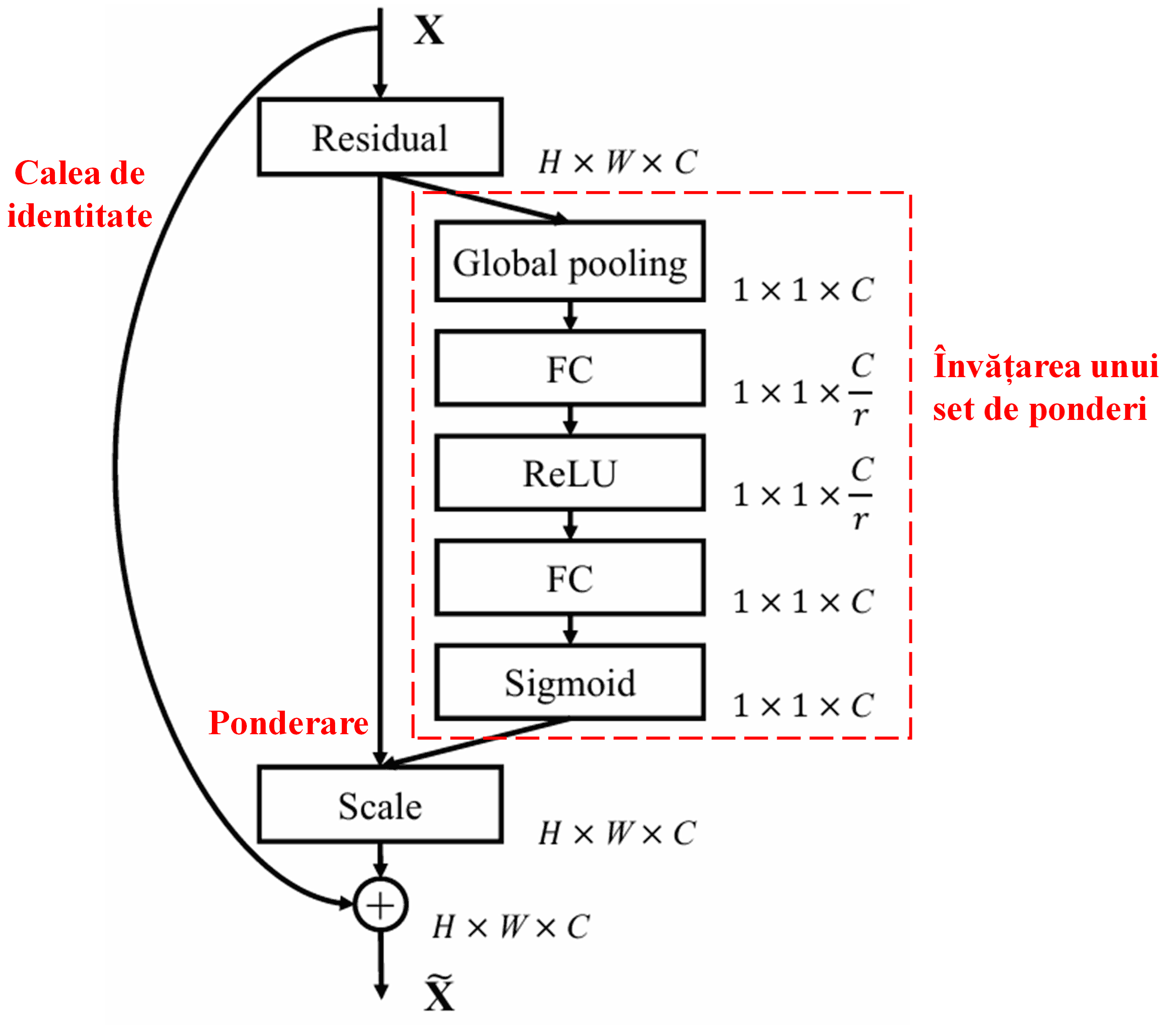
4. Soft Thresholding sub Mecanism de Atenție Profundă
Deep Residual Shrinkage Network se inspiră din structura sub-rețelei SENet menționată mai sus pentru a implementa soft thresholding-ul sub un mecanism de atenție profundă. Prin intermediul sub-rețelei (indicată de obicei în diagramele arhitecturale), se poate învăța un set de praguri pentru a aplica soft thresholding pe fiecare canal de caracteristici.
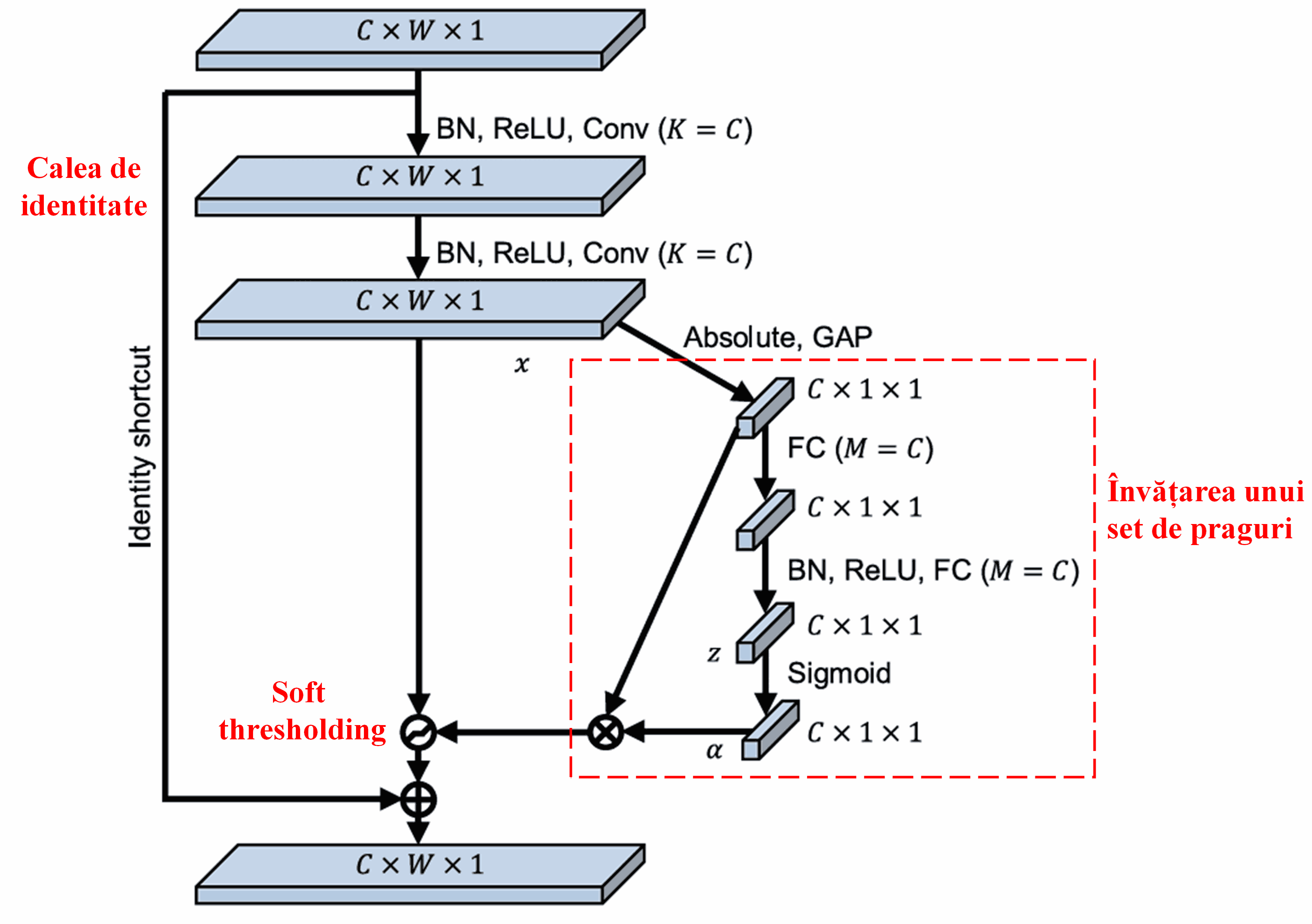
În această sub-rețea, mai întâi se calculează valorile absolute ale tuturor caracteristicilor din harta de caracteristici (feature map) de intrare. Apoi, prin Global Average Pooling și mediere, se obține o caracteristică, notată cu A. Pe cealaltă cale, harta de caracteristici de după Global Average Pooling este introdusă într-o mică rețea complet conectată (fully connected network). Această rețea folosește funcția Sigmoid ca ultim strat pentru a normaliza ieșirea între 0 și 1, obținând un coeficient notat cu α. Pragul final poate fi exprimat ca α × A. Astfel, pragul este produsul dintre un număr între 0 și 1 și media valorilor absolute ale hărții de caracteristici. Această metodă asigură că pragul este nu doar pozitiv, dar nici nu este excesiv de mare.
Mai mult, eșantioane diferite vor rezulta în praguri diferite. Prin urmare, într-o anumită măsură, acest lucru poate fi interpretat ca un mecanism special de atenție: rețeaua identifică caracteristicile irelevante pentru sarcina curentă, le transformă în valori apropiate de zero prin intermediul a două straturi convoluționale și le setează la zero folosind soft thresholding; alternativ, identifică caracteristicile relevante pentru sarcina curentă, le transformă în valori îndepărtate de zero și le păstrează.
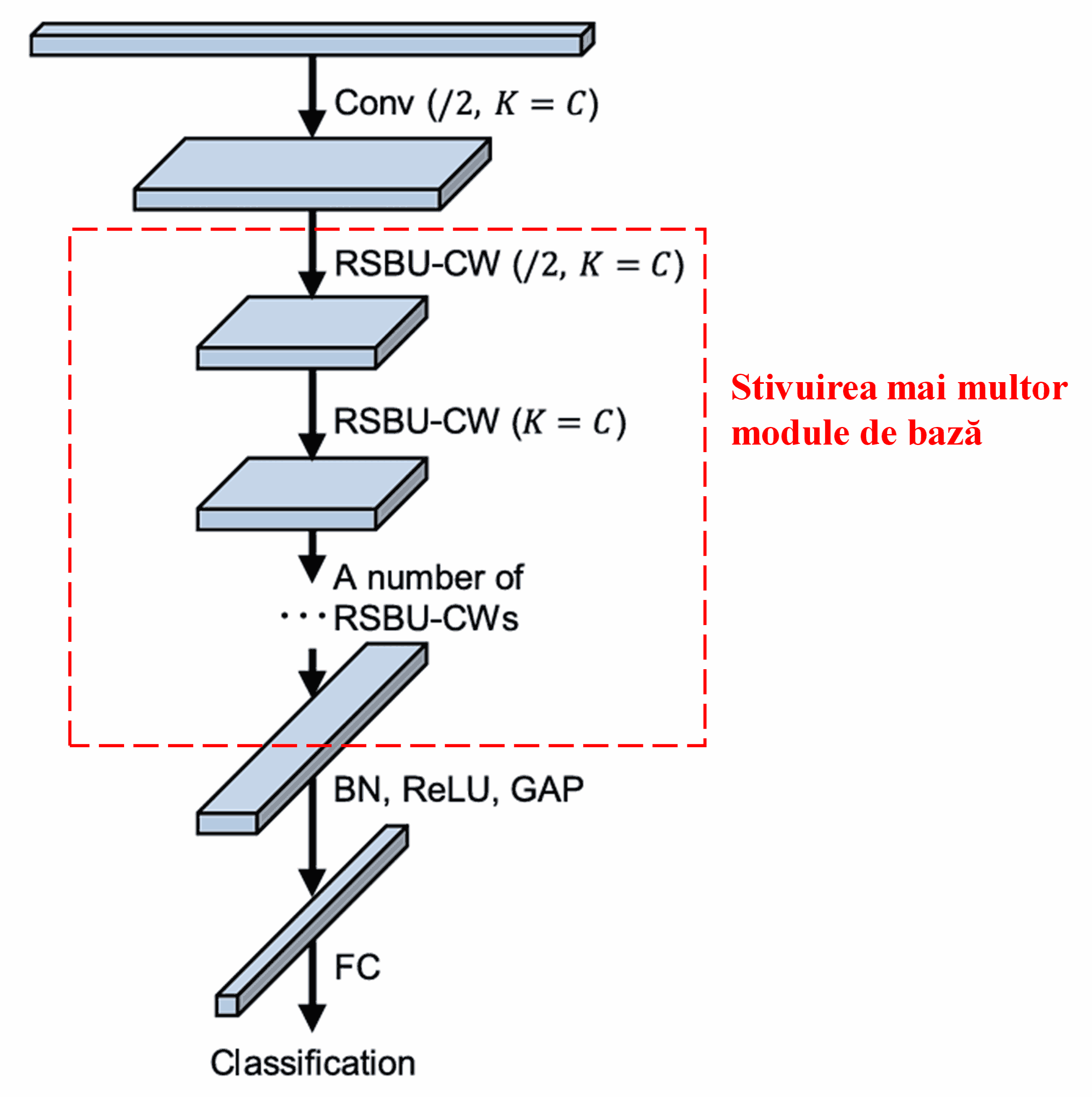
În final, prin stivuirea unui anumit număr de module de bază alături de straturi convoluționale, Batch Normalization, funcții de activare, Global Average Pooling și straturi de ieșire Fully Connected, se construiește arhitectura completă a Deep Residual Shrinkage Network.
5. Capacitatea de Generalizare
Deep Residual Shrinkage Network este, de fapt, o metodă generală de învățare a caracteristicilor (feature learning). Acest lucru se datorează faptului că, în multe sarcini de învățare a caracteristicilor, eșantioanele conțin mai mult sau mai puțin zgomot, precum și informații irelevante. Acest zgomot și informațiile irelevante pot afecta performanța procesului de învățare. De exemplu:
În clasificarea imaginilor, dacă o imagine conține simultan multe alte obiecte, aceste obiecte pot fi înțelese ca „zgomot”. Deep Residual Shrinkage Network ar putea utiliza mecanismul de atenție pentru a observa acest „zgomot” și apoi ar putea folosi soft thresholding-ul pentru a seta la zero caracteristicile corespunzătoare acestui „zgomot”, îmbunătățind astfel potențial acuratețea clasificării imaginilor.
În recunoașterea vocală, în special în medii relativ zgomotoase, cum ar fi conversațiile pe marginea drumului sau în interiorul unui atelier de fabrică, Deep Residual Shrinkage Network poate îmbunătăți acuratețea recunoașterii vocale sau, cel puțin, oferă o metodologie capabilă să îmbunătățească această acuratețe.
Bibliografie
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Impact Academic
Această lucrare a primit peste 1400 de citări pe Google Scholar.
Conform estimărilor, Deep Residual Shrinkage Networks (DRSN) au fost utilizate în peste 1000 de publicații. Aceste lucrări au aplicat direct sau au îmbunătățit rețeaua într-o gamă largă de domenii, inclusiv inginerie mecanică, energie electrică, computer vision, medicină, procesarea vorbirii, analiză de text, radar și teledetecție.