Deep Residual Shrinkage Network (DRSN) er en forbedret variant av Deep Residual Networks (ResNet). I bunn og grunn er det en integrasjon av ResNet, oppmerksomhetsmekanismer (attention mechanisms) og funksjoner for soft thresholding.
I stor grad kan virkemåten til DRSN forstås slik: Den bruker en oppmerksomhetsmekanisme til å oppdage uviktige egenskaper (features) og bruker deretter soft thresholding for å sette disse til null. Omvendt vil den legge merke til viktige egenskaper og beholde dem. Dette styrker det dype nevrale nettverkets evne til å trekke ut nyttig informasjon fra signaler som inneholder støy.
1. Forskningsmotivasjon
For det første: Når vi skal klassifisere prøver, er det uunngåelig at de inneholder noe støy – som hvit støy (Gaussian noise), rosa støy eller Laplace-støy. Mer generelt inneholder prøver ofte informasjon som er irrelevant for den aktuelle oppgaven, og dette kan også tolkes som støy. Slik støy kan påvirke klassifiseringsresultatet negativt. (Soft thresholding er et nøkkeltrinn i mange algoritmer for støyfjerning i signaler.)
Ta for eksempel en samtale ved en trafikkert vei. Lydsignalet vil ofte blandes med bilhorn og hjulstøy. Når man utfører talegjenkjenning på disse signalene, vil resultatet uunngåelig påvirkes av bakgrunnslydene. Fra et dyplæringsperspektiv (deep learning perspective) bør egenskapene som representerer bilhorn og hjulstøy fjernes internt i det nevrale nettverket, slik at de ikke påvirker talegjenkjenningen.
For det andre: Selv i samme datasett vil støynivået ofte variere fra eksempel til eksempel. (Dette har likhetstrekk med oppmerksomhetsmekanismer. I et bildedatasett, for eksempel, kan posisjonen til målobjektet variere fra bilde til bilde, og mekanismen kan fokusere på akkurat der objektet befinner seg i hvert enkelt tilfelle.)
Tenk deg for eksempel at vi trener en klassifikator for å skille mellom hunder og katter. I fem bilder merket som “hund”, kan det første bildet inneholde en hund og en mus, det andre en hund og en gås, det tredje en hund og en kylling, det fjerde en hund og et esel, og det femte en hund og en and. Under treningen vil modellen uunngåelig forstyrres av de irrelevante objektene (mus, gås, kylling, osv.), noe som fører til redusert nøyaktighet. Hvis vi kan identifisere disse irrelevante objektene og fjerne egenskapene som tilhører dem, kan vi forbedre nøyaktigheten til hunde- og katteklassifikatoren.
2. Soft Thresholding
Soft thresholding (myk terskling) er et kjernetrinn i mange algoritmer for støyfjerning. Det fjerner egenskaper der absoluttverdien er lavere enn en viss terskelverdi, og krymper (shrinks) egenskaper som er større enn terskelen mot null. Dette kan implementeres ved hjelp av følgende formel:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Den deriverte av utgangen fra soft thresholding med hensyn på inngangen er:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Som vist over, er den deriverte av soft thresholding enten 1 eller 0. Denne egenskapen er identisk med aktiveringsfunksjonen ReLU. Derfor kan soft thresholding også redusere risikoen for at dyplæringsalgoritmer møter problemer med forsvinnende eller eksploderende gradienter (gradient vanishing / exploding).
Når man setter terskelverdien i en soft thresholding-funksjon, må to betingelser oppfylles: For det første må terskelen være et positivt tall. For det andre kan terskelen ikke være større enn signalets maksimalverdi, ellers vil hele utgangen bli null.
Samtidig bør terskelen helst oppfylle en tredje betingelse: Hvert eksempel (sample) bør ha sin egen, uavhengige terskelverdi basert på hvor mye støy det inneholder.
Dette er fordi støynivået ofte varierer mellom ulike prøver. Det er for eksempel vanlig i samme datasett at eksempel A inneholder lite støy, mens eksempel B inneholder mye støy. Hvis man da bruker soft thresholding i en støyfjerningsalgoritme, bør eksempel A ha en lavere terskelverdi, mens eksempel B bør ha en høyere terskelverdi. Selv om disse egenskapene og tersklene mister sin eksplisitte fysiske definisjon dypt inne i et nevralt nettverk, gjelder den samme grunnleggende logikken. Det vil si at hvert eksempel bør ha sin egen terskel tilpasset sitt eget støynivå.
3. Oppmerksomhetsmekanisme
Oppmerksomhetsmekanismer (attention mechanisms) er relativt enkle å forstå innen datasyn (computer vision). Dyrs visuelle system kan raskt skanne et helt område for å oppdage målobjekter, og deretter fokusere oppmerksomheten på objektet for å trekke ut flere detaljer, samtidig som irrelevant informasjon undertrykkes. For detaljer henvises det til faglitteratur om oppmerksomhetsmekanismer.
Squeeze-and-Excitation Network (SENet) er en relativt ny dyplæringsmetode som benytter oppmerksomhetsmekanismer. På tvers av ulike eksempler vil bidraget fra ulike trekk-kanaler (feature channels) til klassifiseringsoppgaven ofte variere. SENet bruker et lite under-nettverk for å beregne et sett med vekter, og multipliserer deretter disse vektene med egenskapene i de respektive kanalene for å justere størrelsen på dem. Denne prosessen kan sees på som å gi ulik grad av oppmerksomhet til de ulike kanalene.
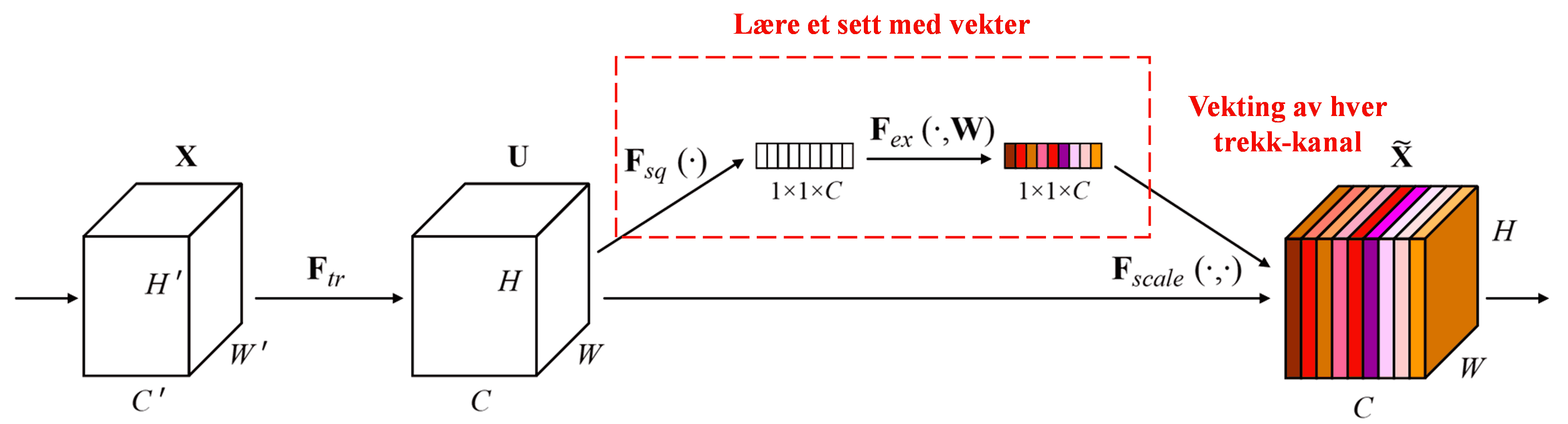
På denne måten vil hvert enkelt eksempel ha sitt eget uavhengige sett med vekter. Med andre ord er vektene for to vilkårlige eksempler forskjellige. I SENet er ruten for å oppnå disse vektene: “Global Pooling → Fullt koblet lag (Fully Connected Layer) → ReLU-funksjon → Fullt koblet lag → Sigmoid-funksjon”.
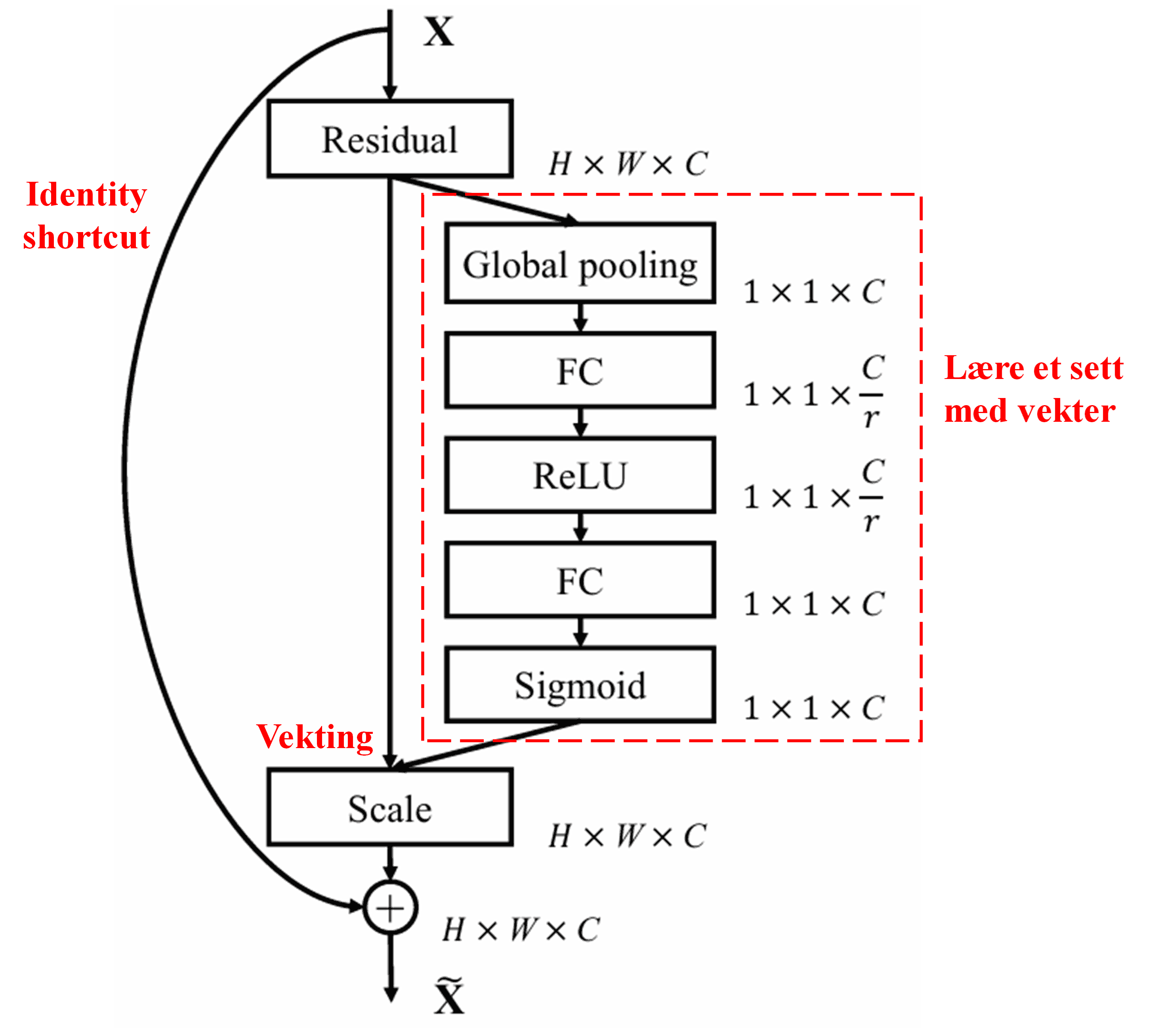
4. Soft Thresholding med dyp oppmerksomhetsmekanisme
Deep Residual Shrinkage Network henter inspirasjon fra strukturen i SENet nevnt over for å implementere soft thresholding styrt av en dyp oppmerksomhetsmekanisme. Gjennom et under-nettverk (markert med rød boks i arkitekturen) kan modellen lære et sett med terskelverdier for å utføre soft thresholding på hver enkelt trekk-kanal.
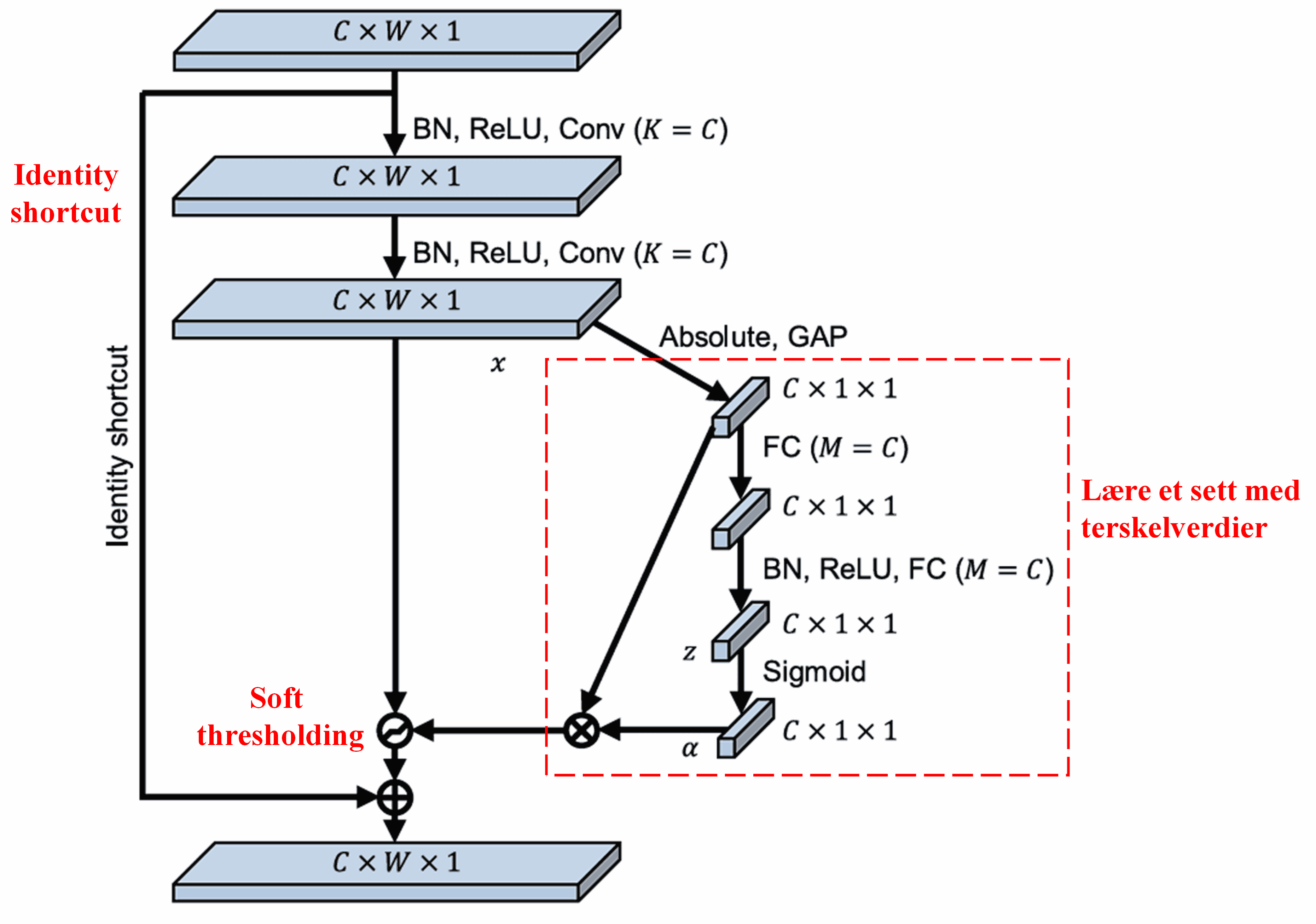
I dette under-nettverket beregnes først absoluttverdien av alle egenskaper i input-kartet. Deretter, gjennom global gjennomsnittspooling og midling, får man en egenskap som vi kaller A. I den andre ruten sendes det poolede egenskapskartet inn i et lite, fullt koblet nettverk. Dette nettverket bruker en Sigmoid-funksjon som siste lag for å normalisere utgangen til mellom 0 og 1, noe som gir en koeffisient vi kaller α. Den endelige terskelverdien kan uttrykkes som α × A. Derfor er terskelen produktet av et tall mellom 0 og 1 og gjennomsnittet av absoluttverdiene i egenskapskartet. Denne metoden sikrer at terskelen ikke bare er positiv, men heller ikke blir for stor.
Videre får ulike eksempler ulike terskelverdier. Derfor kan dette i stor grad forstås som en spesialisert oppmerksomhetsmekanisme: Den legger merke til egenskaper som er irrelevante for den nåværende oppgaven, bruker to konvolusjonslag til å transformere disse til verdier nær null, og bruker så soft thresholding for å sette dem helt til null. Omvendt vil den legge merke til relevante egenskaper, transformere dem til verdier langt fra null, og bevare dem.
Til slutt, ved å stable et visst antall slike grunnmoduler sammen med konvolusjonslag, batch-normalisering (Batch Normalization), aktiveringsfunksjoner, global gjennomsnittspooling og fullt koblede utgangslag, får man et komplett Deep Residual Shrinkage Network.
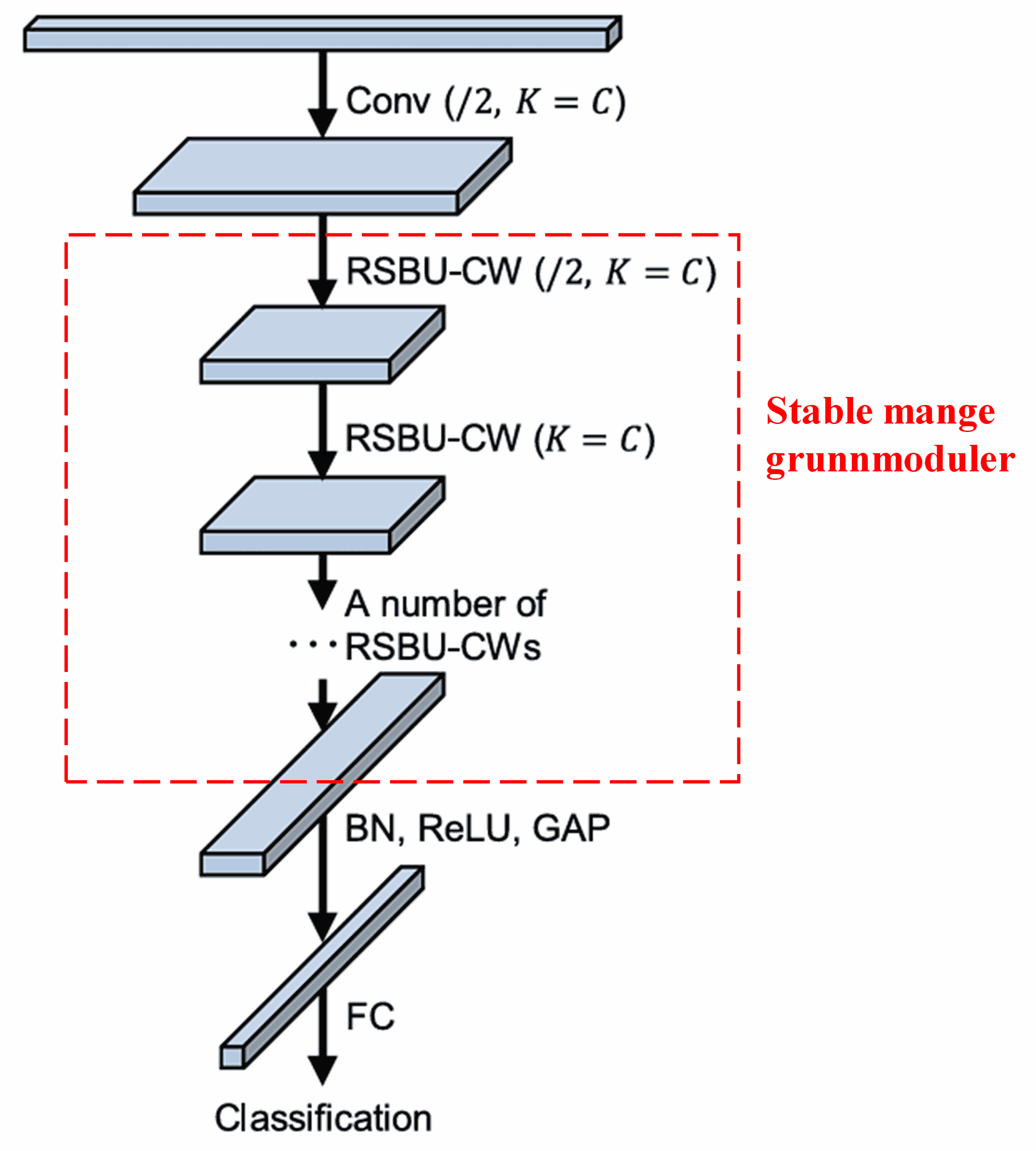
5. Generaliseringsevne
Deep Residual Shrinkage Network er i realiteten en generell metode for å lære egenskaper (feature learning). Dette skyldes at i mange oppgaver inneholder dataprøvene mer eller mindre støy, samt irrelevant informasjon. Denne støyen og den irrelevante informasjonen kan påvirke læringsresultatet negativt. For eksempel:
Innen bildeklassifisering: Hvis et bilde samtidig inneholder mange andre objekter, kan disse objektene forstås som “støy”. Deep Residual Shrinkage Network kan potensielt bruke oppmerksomhetsmekanismen til å legge merke til denne “støyen”, og deretter bruke soft thresholding til å sette egenskapene som tilsvarer “støyen” til null, noe som kan øke nøyaktigheten i bildeklassifiseringen.
Innen talegjenkjenning: I omgivelser med mye støy, som ved en vei eller inne i en fabrikkhall, kan Deep Residual Shrinkage Network kanskje forbedre nøyaktigheten, eller i det minste tilby en tilnærming som kan bidra til bedre talegjenkjenning.
Referanser
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Akademisk innflytelse
Denne artikkelen har over 1400 siteringer på Google Scholar.
Ifølge konservative estimater har Deep Residual Shrinkage Networks (DRSN) blitt brukt i over 1000 publikasjoner. Disse arbeidene har enten anvendt nettverket direkte eller forbedret det for bruk innen en rekke felt, inkludert mekanikk, elkraft, datasyn, helse, talebehandling, tekstanalyse, radar og fjernmåling.