Dziļie reziduālie sarukuma tīkli (Deep Residual Shrinkage Networks jeb DRSN) ir uzlabota dziļo reziduālo tīklu (Deep Residual Networks / ResNet) versija. Pēc būtības tā ir dziļo reziduālo tīklu, uzmanības mehānismu (attention mechanisms) un mīkstās sliekšņošanas (soft thresholding) funkciju integrācija.
Zināmā mērā DRSN darbības principu var saprast šādi: izmantojot uzmanības mehānismu, tiek pamanītas mazsvarīgas pazīmes (features), un ar mīkstās sliekšņošanas funkciju tās tiek nullētas (iestatītas uz nulli); savukārt svarīgās pazīmes tiek pamanītas un saglabātas. Tādējādi tiek stiprināta dziļā neironu tīkla spēja iegūt noderīgas pazīmes no signāliem, kas satur troksni.
1. Pētījuma motivācija
Pirmkārt, klasificējot paraugus, tajos neizbēgami ir novērojams troksnis, piemēram, Gausa troksnis, rozā troksnis, Laplasa troksnis u.c. Plašākā nozīmē paraugos bieži ir ietverta informācija, kas nav saistīta ar konkrēto klasifikācijas uzdevumu – arī šo informāciju var uzskatīt par troksni. Šis troksnis var negatīvi ietekmēt klasifikācijas rezultātus. (Jāatzīmē, ka mīkstā sliekšņošana ir galvenais solis daudzos klasiskajos signālu trokšņa mazināšanas algoritmos).
Sadzīvisks piemērs: sarunājoties ceļa malā, runas skaņai var piejaukties automašīnu skaņas signāli, riteņu troksnis utt. Veicot balss atpazīšanu šādiem signāliem, rezultātu neizbēgami ietekmēs fona trokšņi. No dziļās mācīšanās (Deep Learning) viedokļa pazīmes (features), kas atbilst šiem skaņas signāliem un riteņu trokšņiem, būtu jādzēš dziļā neironu tīkla iekšienē, lai tās neietekmētu balss atpazīšanas efektivitāti.
Otrkārt, pat viena datu kopas (dataset) ietvaros trokšņa daudzums dažādos paraugos bieži atšķiras. (Tam ir līdzība ar uzmanības mehānismiem; piemēram, attēlu datu kopā mērķa objekta atrašanās vieta katrā attēlā var būt atšķirīga, un uzmanības mehānisms spēj fokusēties uz konkrēto mērķa objekta atrašanās vietu katrā atsevišķā attēlā).
Piemēram, apmācot kaķu un suņu klasifikatoru, aplūkosim 5 attēlus ar marķējumu “suns”. 1. attēlā var būt redzams suns un pele, 2. attēlā – suns un zoss, 3. attēlā – suns un vista, 4. attēlā – suns un ēzelis, bet 5. attēlā – suns un pīle. Apmācot klasifikatoru, mēs neizbēgami saskaramies ar traucējumiem no nesaistītiem objektiem (pelēm, zosīm, vistām u.c.), kas samazina klasifikācijas precizitāti. Ja mēs spētu pamanīt šos nesaistītos objektus un dzēst tiem atbilstošās pazīmes, būtu iespējams uzlabot kaķu un suņu klasifikatora precizitāti.
2. Mīkstā sliekšņošana (Soft Thresholding)
Mīkstā sliekšņošana ir galvenais solis daudzos signālu trokšņa mazināšanas algoritmos. Tā dzēš pazīmes, kuru absolūtā vērtība ir mazāka par noteiktu slieksni, bet pazīmes, kuru absolūtā vērtība ir lielāka par šo slieksni, “sarauj” (shrink) nulles virzienā. To var realizēt ar šādu formulu:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Mīkstās sliekšņošanas izvades atvasinājums attiecībā pret ievadi ir:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Kā redzams no augstāk minētā, mīkstās sliekšņošanas atvasinājums ir vai nu 1, vai 0. Šī īpašība ir identiska ReLU aktivizācijas funkcijai. Tāpēc mīkstā sliekšņošana spēj arī samazināt risku, ka dziļās mācīšanās algoritmi saskarsies ar gradienta izzušanu (gradient vanishing) vai gradienta eksploziju (gradient exploding).
Mīkstās sliekšņošanas funkcijā sliekšņa iestatīšanai jāatbilst diviem nosacījumiem: pirmkārt, slieksnim jābūt pozitīvam skaitlim; otrkārt, slieksnis nedrīkst būt lielāks par ievades signāla maksimālo vērtību, pretējā gadījumā visa izvade būs nulle.
Vienlaikus ir vēlams, lai slieksnis atbilstu arī trešajam nosacījumam: katram paraugam jābūt savam neatkarīgam slieksnim, kas balstīts uz tā trokšņa saturu.
Tas ir tāpēc, ka trokšņa daudzums dažādos paraugos bieži atšķiras. Piemēram, vienā datu kopā paraugam A var būt mazāk trokšņa, bet paraugam B – vairāk. Veicot mīksto sliekšņošanu trokšņa mazināšanas algoritmā, paraugam A būtu jāpiemēro mazāks slieksnis, bet paraugam B – lielāks. Lai gan dziļajos neironu tīklos šīs pazīmes un sliekšņi zaudē savu tiešo fizikālo nozīmi, pamatprincips paliek spēkā. Citiem vārdiem sakot, katram paraugam ir nepieciešams savs unikāls slieksnis, kas atbilst tā trokšņa līmenim.
3. Uzmanības mehānisms (Attention Mechanism)
Datorredzes (Computer Vision) jomā uzmanības mehānismus ir samērā viegli saprast. Dzīvnieku redzes sistēma spēj ātri noskenēt visu redzes lauku, atklāt mērķa objektu un pēc tam koncentrēt uzmanību tieši uz to, lai iegūtu vairāk detaļu, vienlaikus ignorējot nebūtisko informāciju. Sīkāku informāciju skatiet literatūrā par uzmanības mehānismiem.
Squeeze-and-Excitation Network (SENet) ir relatīvi jauna dziļās mācīšanās metode, kas izmanto uzmanības mehānismus. Dažādos paraugos dažādu pazīmju kanālu (feature channels) ieguldījums klasifikācijas uzdevumā bieži ir atšķirīgs. SENet izmanto nelielu apakštīklu (sub-network), lai iegūtu svaru kopu, un pēc tam reizina šos svarus ar attiecīgo kanālu pazīmēm, tādējādi pielāgojot katra kanāla pazīmju lielumu. Šo procesu var uzskatīt par dažāda līmeņa uzmanības pievēršanu dažādiem pazīmju kanāliem.
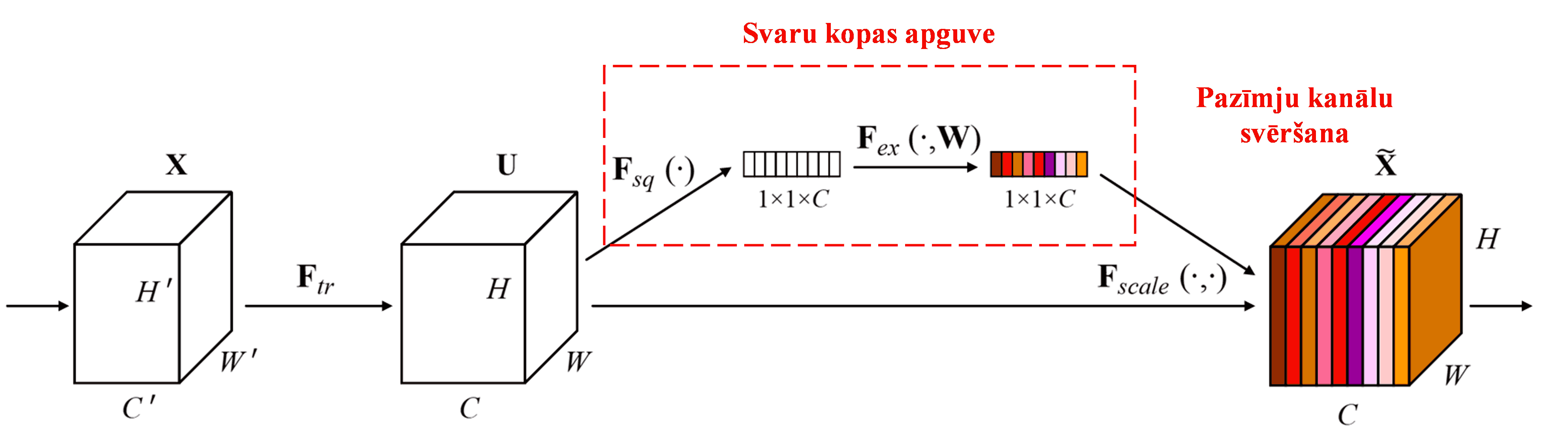
Šādā pieejā katram paraugam ir sava neatkarīga svaru kopa. Citiem vārdiem sakot, jebkuriem diviem paraugiem svari būs atšķirīgi. SENet modelī svaru iegūšanas ceļš ir: “Global Pooling → Fully Connected Layer → ReLU funkcija → Fully Connected Layer → Sigmoid funkcija”.
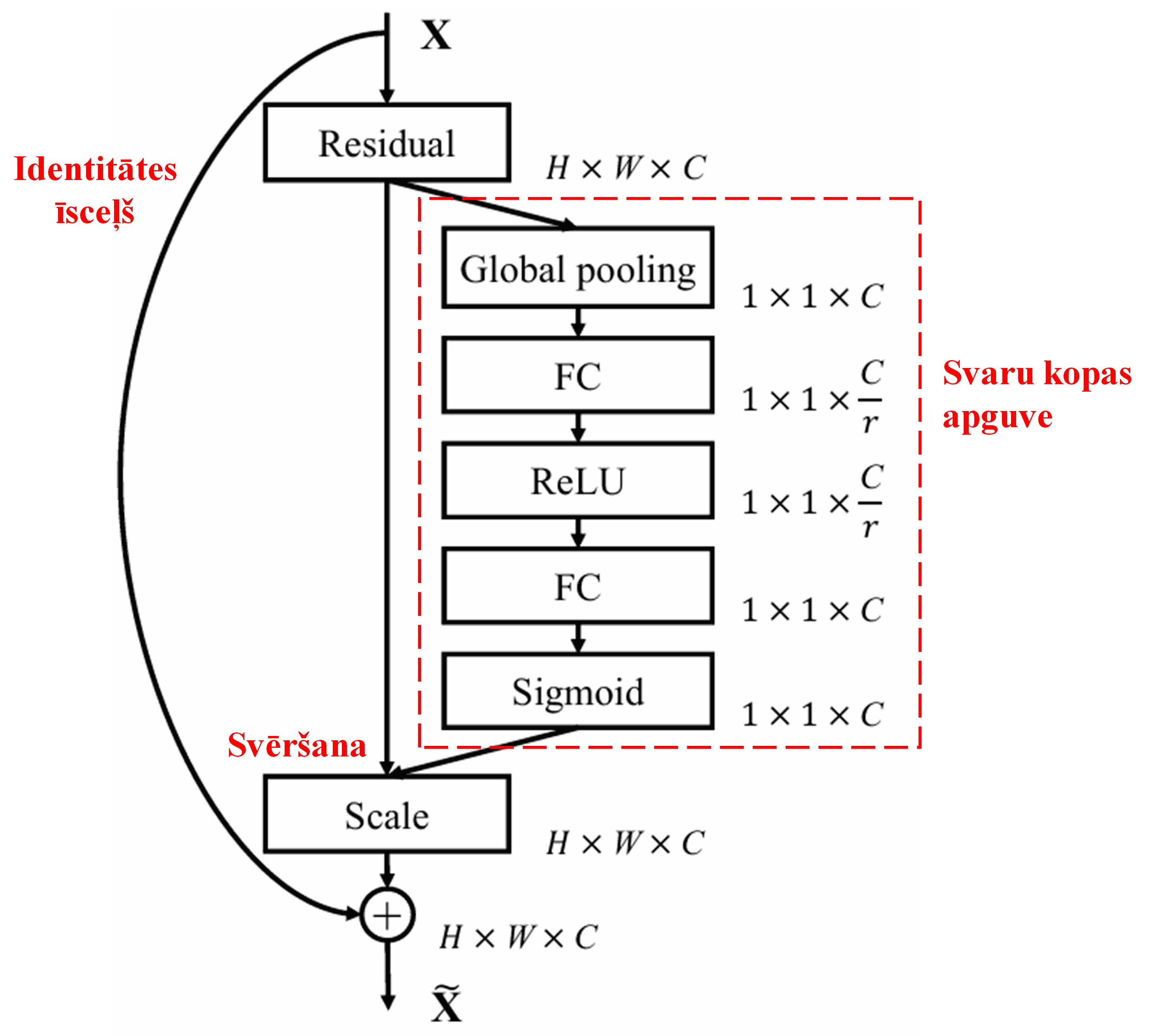
4. Mīkstā sliekšņošana ar dziļo uzmanības mehānismu
Dziļie reziduālie sarukuma tīkli (DRSN) aizgūst minēto SENet apakštīkla struktūru, lai realizētu mīksto sliekšņošanu dziļā uzmanības mehānisma ietvaros. Izmantojot apakštīklu (kas parasti attēlots sarkanā rāmī arhitektūras diagrammās), ir iespējams iemācīties sliekšņu kopu, lai veiktu mīksto sliekšņošanu katram pazīmju kanālam.
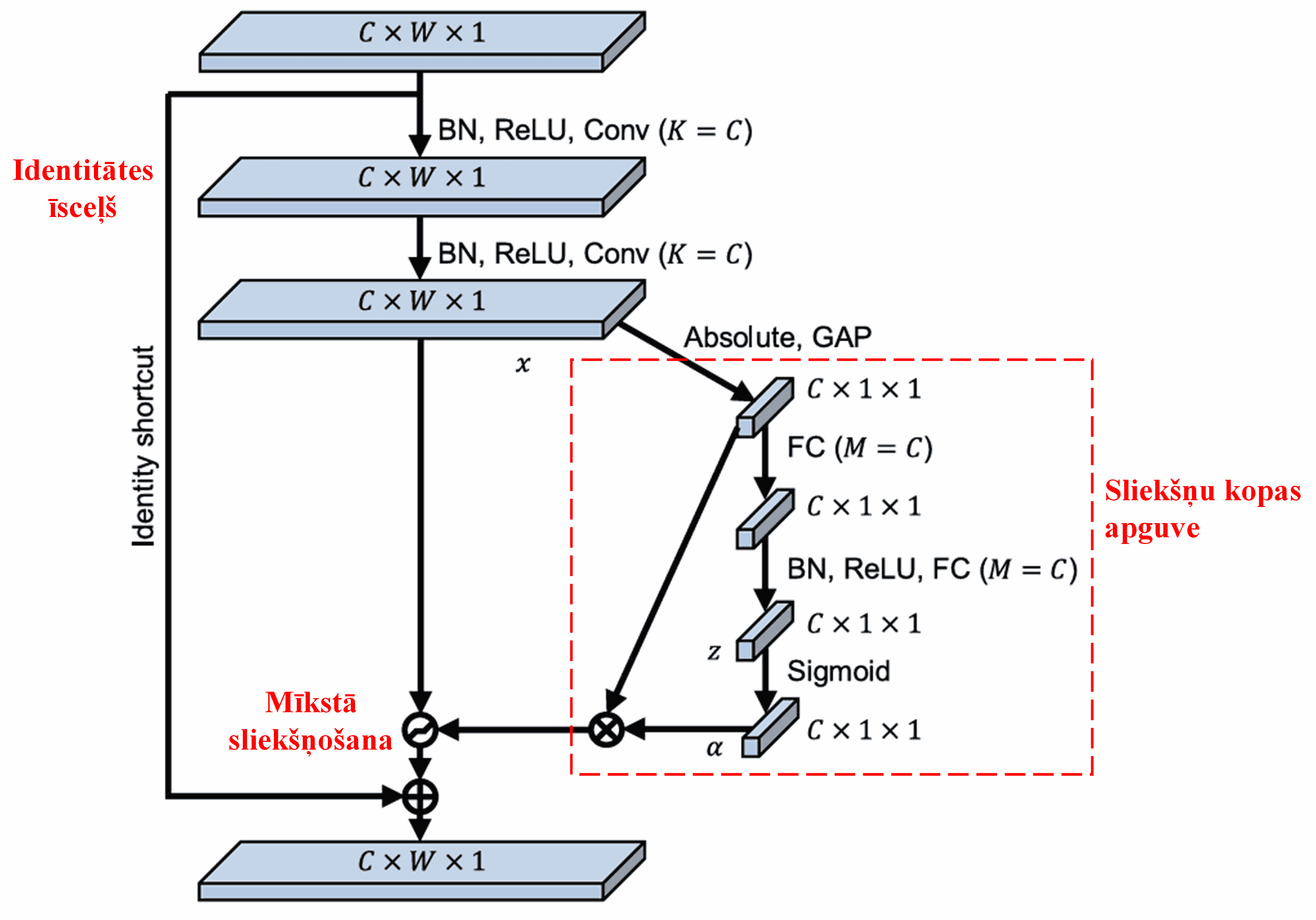
Šajā apakštīklā vispirms tiek aprēķināta visu ievades pazīmju kartes (feature map) pazīmju absolūtā vērtība. Pēc tam, izmantojot globālo vidējo apvienošanu (Global Average Pooling) un vidējošanu, tiek iegūta pazīme, ko apzīmēsim ar A. Otrā ceļā: pazīmju karte pēc Global Average Pooling tiek ievadīta nelielā pilnībā savienotā (fully connected) tīklā. Šī tīkla pēdējais slānis ir Sigmoid funkcija, kas normalizē izvadi diapazonā no 0 līdz 1, iegūstot koeficientu, ko apzīmēsim ar α. Galīgo slieksni var izteikt kā α × A. Tādējādi slieksnis ir skaitlis starp 0 un 1, kas reizināts ar pazīmju kartes absolūto vērtību vidējo rādītāju. Šī pieeja garantē, ka slieksnis ir ne tikai pozitīvs, bet arī nav pārāk liels.
Turklāt dažādiem paraugiem tiek iegūti atšķirīgi sliekšņi. Tāpēc zināmā mērā to var saprast kā īpašu uzmanības mehānismu: tas pamana ar pašreizējo uzdevumu nesaistītas pazīmes, caur diviem konvolūcijas slāņiem pārveido tās par vērtībām tuvu nullei un ar mīksto sliekšņošanu iestata tās uz nulli; vai, gluži pretēji, pamana ar uzdevumu saistītas pazīmes un saglabā tās.
Visbeidzot, sakārtojot virknē noteiktu skaitu pamatbloku, kā arī konvolūcijas slāņus, Batch Normalization, aktivizācijas funkcijas, Global Average Pooling un pilnībā savienoto izvades slāni, tiek iegūts pilnīgs dziļais reziduālais sarukuma tīkls (DRSN).
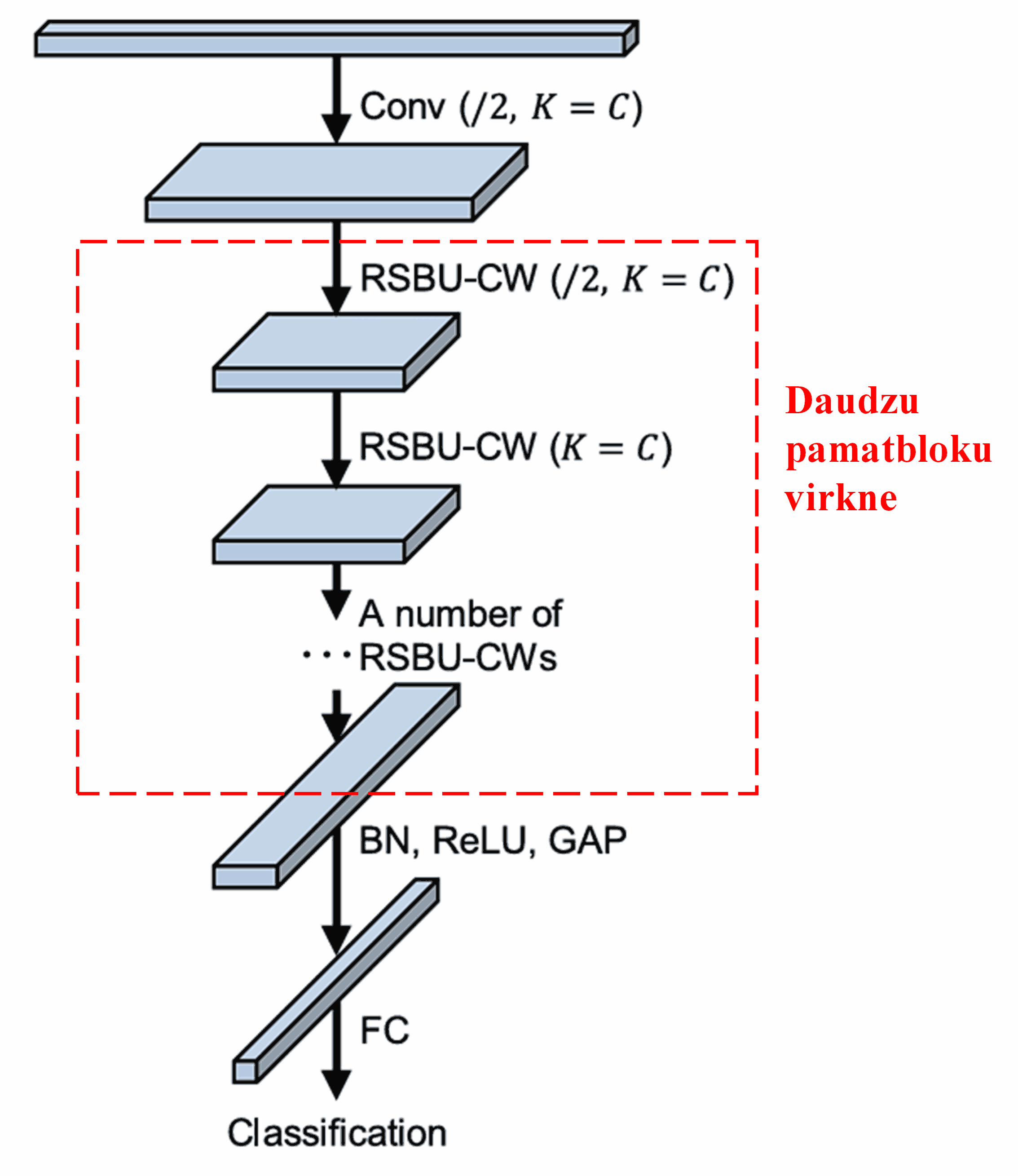
5. Universalitāte
Dziļie reziduālie sarukuma tīkli faktiski ir universāla pazīmju apguves metode. Tas ir tāpēc, ka daudzos pazīmju apguves uzdevumos paraugi vairāk vai mazāk satur troksni un nesaistītu informāciju. Šis troksnis un nesaistītā informācija var ietekmēt apguves rezultātus. Piemēram:
Attēlu klasifikācijā, ja attēls satur daudzus citus objektus, šos objektus var uztvert kā “troksni”; DRSN, iespējams, spēj izmantot uzmanības mehānismu, lai pamanītu šo “troksni”, un pēc tam ar mīksto sliekšņošanu nullēt šim “troksnim” atbilstošās pazīmes, tādējādi potenciāli uzlabojot attēlu klasifikācijas precizitāti.
Runas atpazīšanā, ja darbība notiek trokšņainā vidē, piemēram, sarunājoties ceļa malā vai rūpnīcas cehā, DRSN var uzlabot runas atpazīšanas precizitāti vai vismaz piedāvāt pieeju, kā šo precizitāti uzlabot.
Literatūra un atsauces
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Ietekme akadēmiskajā vidē
Šī raksta citējamība Google Scholar ir pārsniegusi 1400 reižu.
Saskaņā ar nepilnīgu statistiku, Dziļie reziduālie sarukuma tīkli (DRSN) ir izmantoti vai uzlaboti vairāk nekā 1000 publikācijās dažādās jomās, tostarp mehānikā, elektroenerģētikā, datorredzē, medicīnā, runas apstrādē, teksta analīzē, radaru tehnoloģijās un tālizpētē.