Deep Residual Shrinkage Network (DRSN) წარმოადგენს Deep Residual Network-ის გაუმჯობესებულ ვერსიას. სინამდვილეში, ის არის Deep Residual Network-ის, ყურადღების მექანიზმისა (Attention Mechanism) და Soft Thresholding-ის (რბილი ზღურბლოვანი ფუნქციის) ინტეგრაცია.
გარკვეულწილად, Deep Residual Shrinkage Network-ის მუშაობის პრინციპი შეგვიძლია ასე გავიგოთ: ყურადღების მექანიზმის საშუალებით ის ამჩნევს უმნიშვნელო მახასიათებლებს (features) და Soft Thresholding-ის ფუნქციის გამოყენებით მათ ანულებს (ნულს უტოლებს); ან პირიქით, ამჩნევს მნიშვნელოვან მახასიათებლებს და ინარჩუნებს მათ. ეს პროცესი აძლიერებს ღრმა ნეირონული ქსელის უნარს, გამოყოს სასარგებლო ინფორმაცია ხმაურიანი სიგნალებიდან.
1. კვლევის მოტივაცია
პირველ რიგში, ნიმუშების (samples) კლასიფიკაციისას, მათში ხმაურის არსებობა გარდაუვალია — მაგალითად, გაუსის ხმაური, ვარდისფერი ხმაური, ლაპლასის ხმაური და ა.შ. უფრო ფართო გაგებით, ნიმუშები ხშირად შეიცავს ისეთ ინფორმაციას, რომელიც არ არის რელევანტური მიმდინარე კლასიფიკაციის ამოცანისთვის და ესეც შეიძლება ჩაითვალოს ხმაურად. ამ ხმაურმა შესაძლოა უარყოფითი გავლენა მოახდინოს კლასიფიკაციის შედეგებზე. (Soft Thresholding-ი მრავალი სიგნალის დამუშავების და ხმაურის ჩახშობის ალგორითმის საკვანძო ეტაპია).
მაგალითად, ქუჩაში საუბრისას, ხმას შეიძლება შეერიოს მანქანის საყვირის ან ბორბლების ხმა. როდესაც ასეთ სიგნალებზე ხმის ამოცნობას (speech recognition) ვატარებთ, შედეგებზე გარდაუვლად აისახება ფონური ხმაური. Deep Learning-ის კუთხით, საყვირისა და ბორბლების შესაბამისი მახასიათებლები ღრმა ნეირონულ ქსელში უნდა წაიშალოს, რათა მათ ხელი არ შეუშალონ ხმის ამოცნობის პროცესს.
მეორე რიგში, ერთსა და იმავე მონაცემთა ბაზაშიც კი, ხმაურის რაოდენობა ხშირად განსხვავდება თითოეული ნიმუშისთვის. (ამას ბევრი საერთო აქვს ყურადღების მექანიზმთან; მაგალითად, სურათების მონაცემთა ბაზაში მიზნობრივი ობიექტის მდებარეობა სხვადასხვა სურათზე განსხვავებულია; ყურადღების მექანიზმს შეუძლია ფოკუსირება მოახდინოს კონკრეტულად იმ ადგილზე, სადაც ობიექტი მდებარეობს).
მაგალითად, ძაღლისა და კატის კლასიფიკატორის გაწვრთნისას, ავიღოთ 5 სურათი, რომელზეც გამოსახულია “ძაღლი”. პირველ სურათზე შეიძლება იყოს ძაღლი და თაგვი, მეორეზე — ძაღლი და ბატი, მესამეზე — ძაღლი და ქათამი, მეოთხეზე — ძაღლი და ვირი, ხოლო მეხუთეზე — ძაღლი და იხვი. როდესაც ჩვენ ვწვრთნით კლასიფიკატორს, გარდაუვალია ისეთი არარელევანტური ობიექტების ზეგავლენა, როგორიცაა თაგვი, ბატი, ქათამი, ვირი და იხვი, რაც ამცირებს კლასიფიკაციის სიზუსტეს. თუ ჩვენ შევძლებთ შევამჩნიოთ ეს არარელევანტური ობიექტები და წავშალოთ მათი შესაბამისი მახასიათებლები, კლასიფიკატორის სიზუსტე გაიზრდება.
2. Soft Thresholding (რბილი ზღურბლოვანი ფუნქცია)
Soft Thresholding-ი არის სიგნალის ხმაურისგან გაწმენდის (denoising) მრავალი ალგორითმის მთავარი ნაბიჯი. ის შლის მახასიათებლებს, რომელთა აბსოლუტური მნიშვნელობა გარკვეულ ზღვარზე (threshold) ნაკლებია, ხოლო იმ მახასიათებლებს, რომლებიც ზღვარზე მეტია, “კუმშავს” (shrink) ნულის მიმართულებით. მისი იმპლემენტაცია შესაძლებელია შემდეგი ფორმულით:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Soft Thresholding-ის გამოსავლის (output) წარმოებული შემავალი სიგნალის (input) მიმართ არის:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]როგორც ზემოთ ჩანს, Soft Thresholding-ის წარმოებული ან 1-ია, ან 0. ეს თვისება იდენტურია ReLU აქტივაციის ფუნქციისა. შესაბამისად, Soft Thresholding-ს ასევე შეუძლია შეამციროს Deep Learning ალგორითმებში გრადიენტის გაქრობის (gradient vanishing) ან აფეთქების (gradient exploding) რისკი.
Soft Thresholding-ის ფუნქციაში ზღვრის (threshold) დაყენებამ უნდა დააკმაყოფილოს ორი პირობა: პირველი, ზღვარი უნდა იყოს დადებითი რიცხვი; მეორე, ზღვარი არ უნდა აღემატებოდეს შემავალი სიგნალის მაქსიმალურ მნიშვნელობას, წინააღმდეგ შემთხვევაში გამოსავალი მთლიანად ნული იქნება.
ამასთანავე, სასურველია ზღვარი აკმაყოფილებდეს მესამე პირობასაც: თითოეულ ნიმუშს, საკუთარი ხმაურის დონის მიხედვით, უნდა ჰქონდეს ინდივიდუალური ზღვარი.
ეს იმიტომ ხდება, რომ ხმაურის შემცველობა ხშირად განსხვავდება სხვადასხვა ნიმუშში. მაგალითად, ხშირია შემთხვევა, როდესაც ერთსა და იმავე მონაცემთა ბაზაში ნიმუში A შეიცავს ნაკლებ ხმაურს, ხოლო ნიმუში B — მეტს. ასეთ შემთხვევაში, ხმაურის დახშობისას, ნიმუშ A-სთვის უნდა გამოვიყენოთ უფრო მცირე ზღვარი, ხოლო ნიმუშ B-სთვის — უფრო დიდი. მიუხედავად იმისა, რომ ღრმა ნეირონულ ქსელებში ამ მახასიათებლებსა და ზღვრებს მკაფიო ფიზიკური მნიშვნელობა ეკარგებათ, ძირითადი ლოგიკა იგივე რჩება. ანუ, თითოეულ ნიმუშს უნდა ჰქონდეს საკუთარი, დამოუკიდებელი ზღვარი, რომელიც მის ხმაურის შემცველობაზეა დაფუძნებული.
3. ყურადღების მექანიზმი (Attention Mechanism)
ყურადღების მექანიზმების გაგება ყველაზე მარტივია კომპიუტერული ხედვის (Computer Vision) სფეროში. ცხოველების ვიზუალურ სისტემას შეუძლია სწრაფად დაასკანეროს მთლიანი არეალი, აღმოაჩინოს მიზნობრივი ობიექტი და შემდეგ ყურადღება გაამახვილოს მასზე, რათა მეტი დეტალი გამოყოს და პარალელურად ჩაახშოს არარელევანტური ინფორმაცია. დეტალებისთვის გთხოვთ იხილოთ შესაბამისი ლიტერატურა Attention მექანიზმების შესახებ.
Squeeze-and-Excitation Network (SENet) არის შედარებით ახალი Deep Learning მეთოდი, რომელიც იყენებს ყურადღების მექანიზმს. სხვადასხვა ნიმუშებში, სხვადასხვა მახასიათებლის არხების (feature channels) წვლილი კლასიფიკაციის ამოცანაში ხშირად განსხვავებულია. SENet იყენებს პატარა ქვექსელს (sub-network), რათა მიიღოს წონების (weights) ნაკრები და შემდეგ გაამრავლოს ეს წონები შესაბამისი არხების მახასიათებლებზე, მათი სიდიდის დასარეგულირებლად. ეს პროცესი შეიძლება ჩაითვალოს სხვადასხვა დონის ყურადღების მიქცევად სხვადასხვა არხებზე.
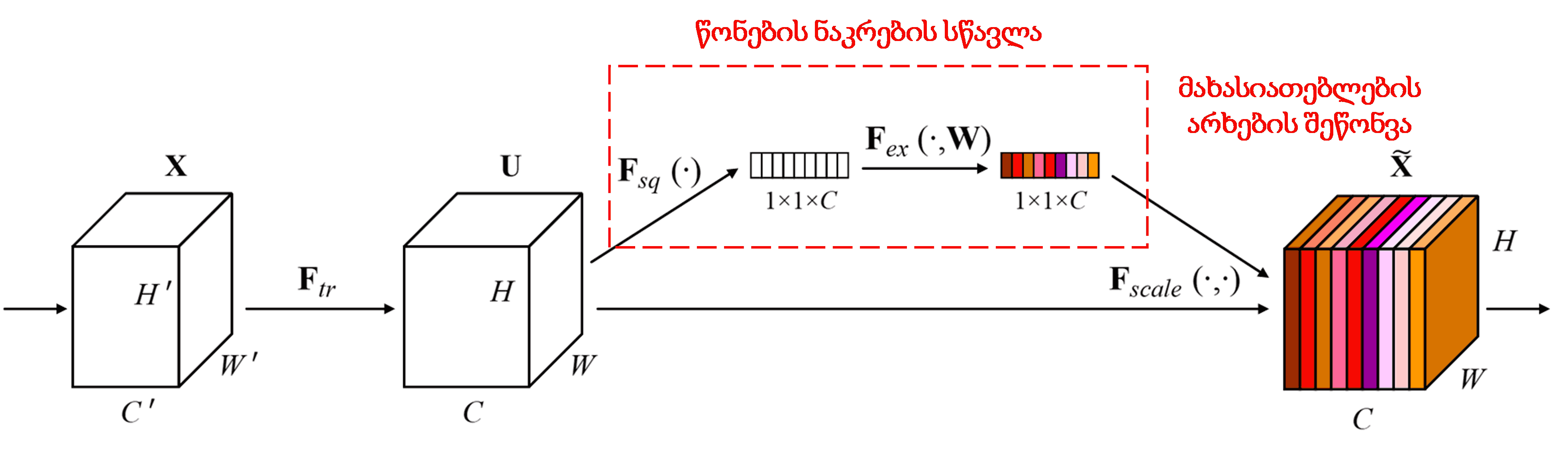
ამ მეთოდით, თითოეულ ნიმუშს აქვს წონების საკუთარი, დამოუკიდებელი ნაკრები. SENet-ში წონების მიღების გზა არის: “Global Pooling → Fully Connected Layer → ReLU → Fully Connected Layer → Sigmoid”.
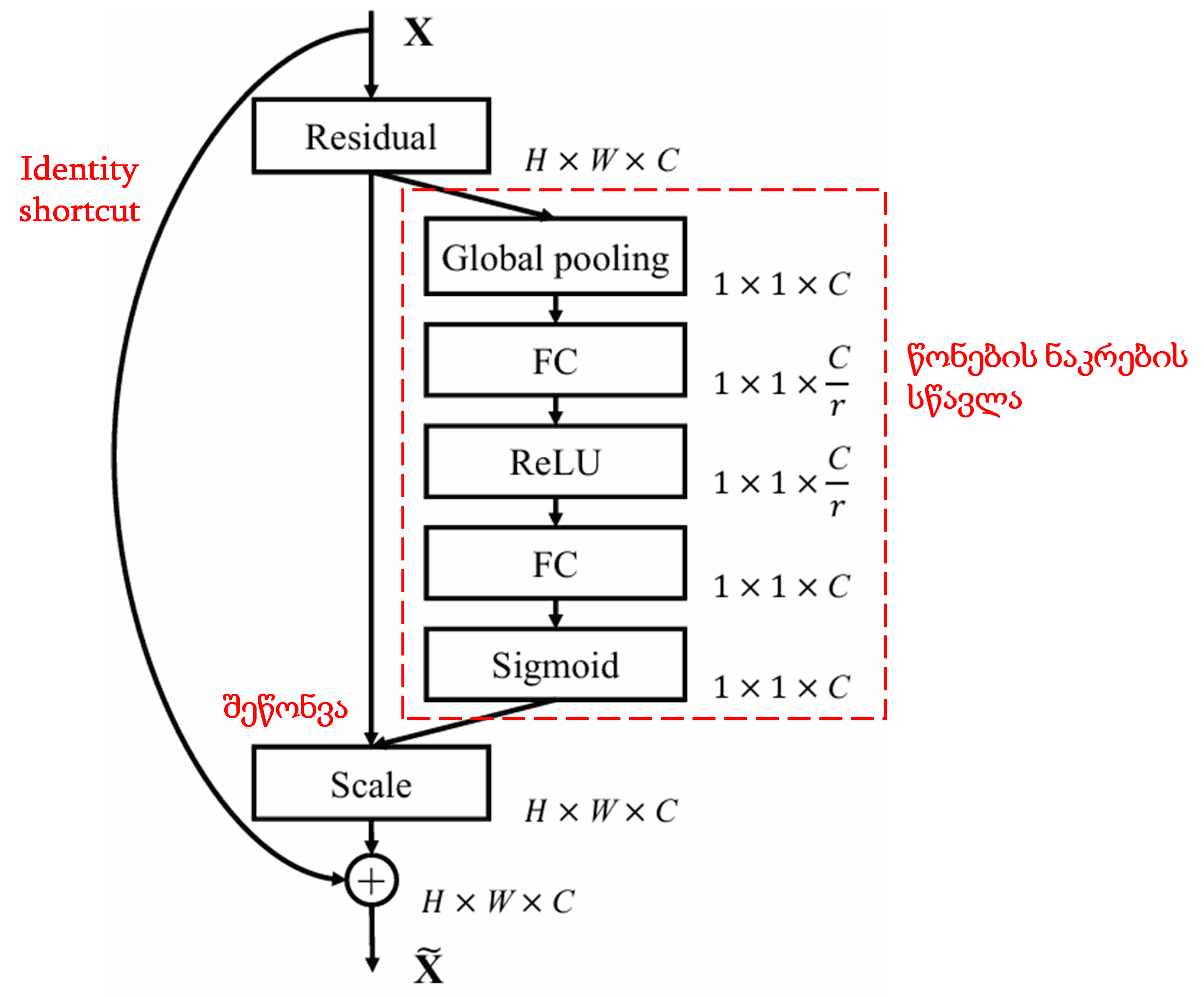
4. Soft Thresholding ღრმა ყურადღების მექანიზმით
Deep Residual Shrinkage Network იყენებს ზემოხსენებულ SENet-ის ქვექსელის სტრუქტურას, რათა მოახდინოს Soft Thresholding-ის იმპლემენტაცია ღრმა ყურადღების მექანიზმის ქვეშ. წითელ ჩარჩოში მოცემული ქვექსელის მეშვეობით შესაძლებელია ვისწავლოთ ზღვრების (thresholds) ნაკრები და მოვახდინოთ თითოეული მახასიათებლის არხის Soft Thresholding-ი.
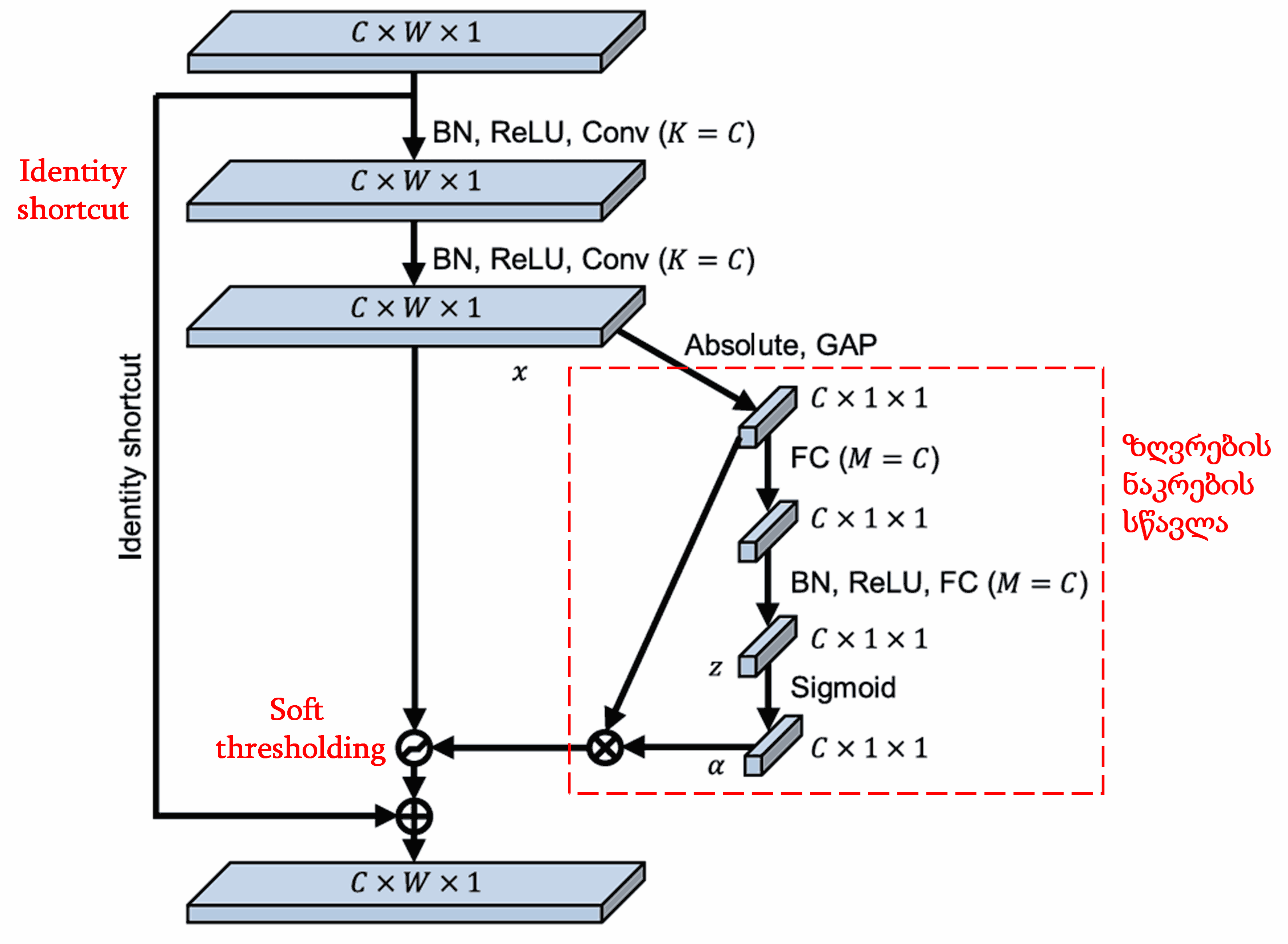
ამ ქვექსელში, პირველ რიგში გამოითვლება შემავალი Feature Map-ის ყველა მახასიათებლის აბსოლუტური მნიშვნელობა. შემდეგ, გლობალური გასაშუალოების (Global Average Pooling) შედეგად ვიღებთ მახასიათებელს, აღნიშნულს როგორც A. მეორე გზაზე, გლობალური გასაშუალოების შემდეგ მიღებული Feature Map შედის პატარა Fully Connected ქსელში. ამ ქსელის ბოლო შრე არის Sigmoid ფუნქცია, რომელსაც გამოსავალი გადაჰყავს 0-სა და 1-ს შორის დიაპაზონში და ვიღებთ კოეფიციენტს, აღნიშნულს როგორც α. საბოლოო ზღვარი გამოისახება როგორც α×A. შესაბამისად, ზღვარი არის 0-სა და 1-ს შორის მოთავსებული რიცხვის ნამრავლი Feature Map-ის აბსოლუტური მნიშვნელობების საშუალოზე. ეს მეთოდი უზრუნველყოფს, რომ ზღვარი იყოს დადებითი და არც ისე დიდი.
გარდა ამისა, სხვადასხვა ნიმუშს ექნება განსხვავებული ზღვარი. შესაბამისად, გარკვეულწილად, ეს შეიძლება გავიგოთ როგორც სპეციალური ყურადღების მექანიზმი: შეამჩნიოს მიმდინარე ამოცანისთვის არარელევანტური მახასიათებლები, გარდაქმნას ისინი 0-თან ახლოს მყოფ მნიშვნელობებად ორი საკონვოლუციო შრის (convolutional layer) მეშვეობით და Soft Thresholding-ის გამოყენებით გაანულოს ისინი; ან პირიქით, შეამჩნიოს რელევანტური მახასიათებლები, გარდაქმნას ისინი 0-სგან დაშორებულ მნიშვნელობებად და შეინარჩუნოს.
საბოლოოდ, გარკვეული რაოდენობის ძირითადი მოდულების, საკონვოლუციო შრეების, Batch Normalization-ის, აქტივაციის ფუნქციების, Global Average Pooling-ისა და Fully Connected გამომავალი შრის დაწყობით (stacking), მიიღება სრული Deep Residual Shrinkage Network.
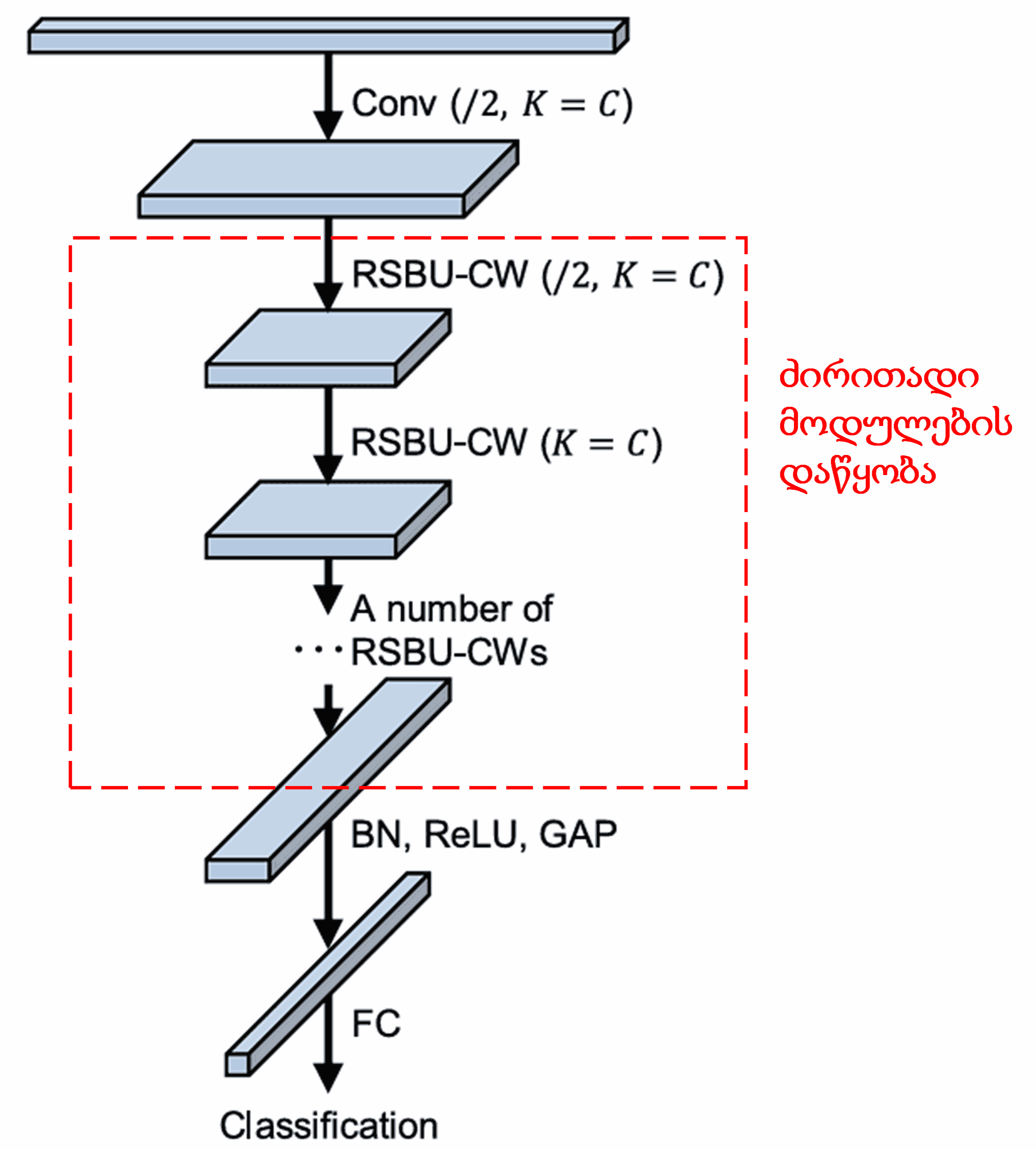
5. უნივერსალურობა
Deep Residual Shrinkage Network ფაქტობრივად მახასიათებლების სწავლის (feature learning) უნივერსალური მეთოდია. ეს იმიტომ, რომ მახასიათებლების სწავლის მრავალ ამოცანაში, ნიმუშები მეტ-ნაკლებად შეიცავენ ხმაურს და არარელევანტური ინფორმაციას. ამ ხმაურმა შეიძლება გავლენა მოახდინოს სწავლის ეფექტურობაზე. მაგალითად:
სურათების კლასიფიკაციისას, თუ სურათი შეიცავს სხვა მრავალ ობიექტს, ეს ობიექტები შეიძლება გავიგოთ როგორც “ხმაური”. Deep Residual Shrinkage Network-ს შეუძლია გამოიყენოს ყურადღების მექანიზმი ამ “ხმაურის” შესამჩნევად და შემდეგ Soft Thresholding-ის მეშვეობით გაანულოს მათი შესაბამისი მახასიათებლები, რამაც შესაძლოა გაზარდოს კლასიფიკაციის სიზუსტე.
ხმის ამოცნობისას, ხმაურიან გარემოში (მაგალითად, ქუჩაში ან ქარხანაში საუბრისას), Deep Residual Shrinkage Network-მა შესაძლოა გააუმჯობესოს ამოცნობის სიზუსტე, ან სულ მცირე, შემოგვთავაზოს მიდგომა, რომელიც ამ მიმართულებით ეფექტური იქნება.
ლიტერატურა:
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
აკადემიური გავლენა
აღნიშნული ნაშრომის ციტირების მაჩვენებელი Google Scholar-ზე 1400-ს აღემატება.
არასრული სტატისტიკის მიხედვით, Deep Residual Shrinkage Network უკვე გამოყენებულია 1000-ზე მეტ სამეცნიერო პუბლიკაციაში, როგორც პირდაპირი სახით, ისე გაუმჯობესებული ვერსიებით. ის ფართოდ გამოიყენება ისეთ სფეროებში, როგორიცაა მექანიკა, ენერგეტიკა, კომპიუტერული ხედვა (computer vision), მედიცინა, ხმის დამუშავება, ტექსტის ანალიზი, რადარული ტექნოლოგიები, დისტანციური ზონდირება და სხვა.