Deep Residual Shrinkage Network-ը (DRSN) Deep Residual Network-ի (ResNet) բարելավված տարբերակն է։ Ըստ էության, այն իրենից ներկայացնում է ResNet-ի, attention mechanism-ի (ուշադրության մեխանիզմ) և soft thresholding-ի (փափուկ շեմային մշակում) ինտեգրումը։
Որոշակի իմաստով, Deep Residual Shrinkage Network-ի աշխատանքի սկզբունքը կարելի է հասկանալ այսպես․ attention mechanism-ի միջոցով այն նկատում է ոչ կարևոր հատկանիշները (features) և soft thresholding ֆունկցիայի միջոցով դրանք զրոյացնում է։ Կամ հակառակը՝ նկատում է կարևոր հատկանիշները և պահպանում դրանք։ Այս գործընթացը ուժեղացնում է խորը նեյրոնային ցանցի կարողությունը՝ աղմուկ պարունակող ազդանշաններից օգտակար ինֆորմացիա դուրս բերելու համար։
1. Հետազոտության մոտիվացիան
Նախ, նմուշների (samples) դասակարգման ժամանակ անխուսափելի է որոշակի աղմուկի առկայությունը, ինչպիսիք են Gaussian noise-ը, pink noise-ը, Laplacian noise-ը և այլն։ Ավելի լայն իմաստով, նմուշները հաճախ պարունակում են տվյալ խնդրի հետ կապ չունեցող ինֆորմացիա, որը նույնպես կարելի է ընկալել որպես աղմուկ։ Այս աղմուկը կարող է բացասաբար ազդել դասակարգման արդյունքների վրա։ (Նշենք, որ Soft thresholding-ը ազդանշանների աղմուկազերծման (signal denoising) շատ ալգորիթմների առանցքային քայլն է)։
Օրինակ, ճանապարհի եզրին զրուցելիս ձայնի մեջ կարող են խառնվել մեքենաների ազդանշանները, անիվների ձայնը և այլն։ Եթե փորձենք կատարել խոսքի ճանաչում (speech recognition) այս ազդանշանների վրա, արդյունքներն անխուսափելիորեն կտուժեն այդ կողմնակի ձայներից։ Deep learning-ի տեսանկյունից, այդ ազդանշաններին ու անիվների ձայներին համապատասխանող հատկանիշները պետք է հեռացվեն նեյրոնային ցանցի ներսում, որպեսզի չազդեն խոսքի ճանաչման վրա։
Երկրորդ, նույնիսկ նույն dataset-ում (տվյալների բազայում), տարբեր նմուշների աղմուկի քանակը հաճախ տարբեր է։ (Սա նմանություն ունի attention mechanism-ի հետ։ Օրինակ՝ պատկերների dataset-ում թիրախային օբյեկտի դիրքը կարող է տարբեր լինել, և attention mechanism-ը կարող է կենտրոնանալ յուրաքանչյուր նկարի կոնկրետ հատվածի վրա)։
Օրինակ, երբ ուսուցանում ենք «շուն և կատու» դասակարգիչ (classifier), ենթադրենք ունենք «շուն» պիտակով 5 նկար։ 1-ին նկարում կարող են լինել շուն և մուկ, 2-րդում՝ շուն և սագ, 3-րդում՝ շուն և հավ, 4-րդում՝ շուն և ավանակ, իսկ 5-րդում՝ շուն և բադ։ Ուսուցանման ընթացքում մենք անխուսափելիորեն կբախվենք խանգարող օբյեկտների՝ մկան, սագի, հավի, ավանակի և բադի ազդեցությանը, ինչը կնվազեցնի ճշգրտությունը։ Եթե մենք կարողանանք նկատել այդ կողմնակի օբյեկտները և հեռացնել դրանց համապատասխանող հատկանիշները, հնարավոր կլինի բարձրացնել դասակարգման ճշգրտությունը։
2. Soft Thresholding (Փափուկ շեմային մշակում)
Soft thresholding-ը ազդանշանների աղմուկազերծման շատ ալգորիթմների հիմնական քայլն է։ Այն հեռացնում է այն հատկանիշները, որոնց բացարձակ արժեքը փոքր է որոշակի շեմից (threshold), իսկ մեծ արժեք ունեցող հատկանիշները «սեղմում» (shrink) է դեպի զրո։ Այն կարելի է իրականացնել հետևյալ բանաձևով՝
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Soft thresholding-ի ելքի ածանցյալը մուտքի նկատմամբ հավասար է՝
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Ինչպես տեսնում ենք, soft thresholding-ի ածանցյալը կամ 1 է, կամ 0։ Այս հատկությունը նույնական է ReLU ակտիվացման ֆունկցիայի հետ։ Հետևաբար, soft thresholding-ը նույնպես նվազեցնում է deep learning ալգորիթմներում gradient vanishing-ի (գրադիենտի անհետացման) և gradient exploding-ի (գրադիենտի պայթյունի) ռիսկը։
Soft thresholding ֆունկցիայի մեջ շեմի (threshold) կարգավորումը պետք է բավարարի երկու պայմանի․ առաջին՝ շեմը պետք է լինի դրական թիվ, և երկրորդ՝ շեմը չպետք է գերազանցի մուտքային ազդանշանի մաքսիմալ արժեքը, հակառակ դեպքում ելքը ամբողջությամբ կլինի զրո։
Միևնույն ժամանակ, ցանկալի է, որ շեմը բավարարի նաև երրորդ պայմանին․ յուրաքանչյուր նմուշ պետք է ունենա իր անհատական շեմը՝ կախված սեփական աղմուկի պարունակությունից։
Պատճառն այն է, որ շատ նմուշներում աղմուկի քանակը տարբեր է։ Օրինակ, հաճախ նույն dataset-ում Նմուշ A-ն պարունակում է քիչ աղմուկ, իսկ Նմուշ B-ն՝ շատ։ Այս դեպքում, աղմուկազերծման ժամանակ Նմուշ A-ի համար պետք է կիրառել փոքր շեմ, իսկ Նմուշ B-ի համար՝ մեծ։ Թեև խորը նեյրոնային ցանցերում այս հատկանիշներն ու շեմերը կորցնում են իրենց հստակ ֆիզիկական իմաստը, հիմնական տրամաբանությունը մնում է նույնը։ Այսինքն՝ յուրաքանչյուր նմուշ պետք է ունենա իր անհատական շեմը՝ հիմնված իր աղմուկի մակարդակի վրա։
3. Attention Mechanism (Ուշադրության մեխանիզմ)
Attention mechanism-ը համակարգչային տեսողության (computer vision) ոլորտում բավականին հեշտ է հասկանալ։ Կենդանիների տեսողական համակարգը կարող է արագ սկանավորել ամբողջ տարածքը, հայտնաբերել թիրախային օբյեկտը և ուշադրությունը կենտրոնացնել դրա վրա՝ ավելի շատ մանրամասներ տեսնելու համար, միաժամանակ ճնշելով անկարևոր ինֆորմացիան։ Մանրամասների համար կարող եք ծանոթանալ attention mechanism-ի վերաբերյալ գրականությանը։
Squeeze-and-Excitation Network (SENet)-ը attention mechanism-ի վրա հիմնված համեմատաբար նոր deep learning մեթոդ է։ Տարբեր նմուշներում տարբեր հատկանիշների ալիքները (feature channels) հաճախ տարբեր ներդրում (contribution) են ունենում դասակարգման խնդրում։ SENet-ը օգտագործում է փոքր ենթացանց (sub-network), որպեսզի ստանա կշիռների (weights) մի խումբ, և հետո այդ կշիռները բազմապատկում է համապատասխան ալիքների հատկանիշների հետ՝ դրանց մեծությունը կարգավորելու համար։ Այս գործընթացը կարելի է դիտարկել որպես տարբեր չափի ուշադրության կիրառում տարբեր հատկանիշների ալիքների վրա։
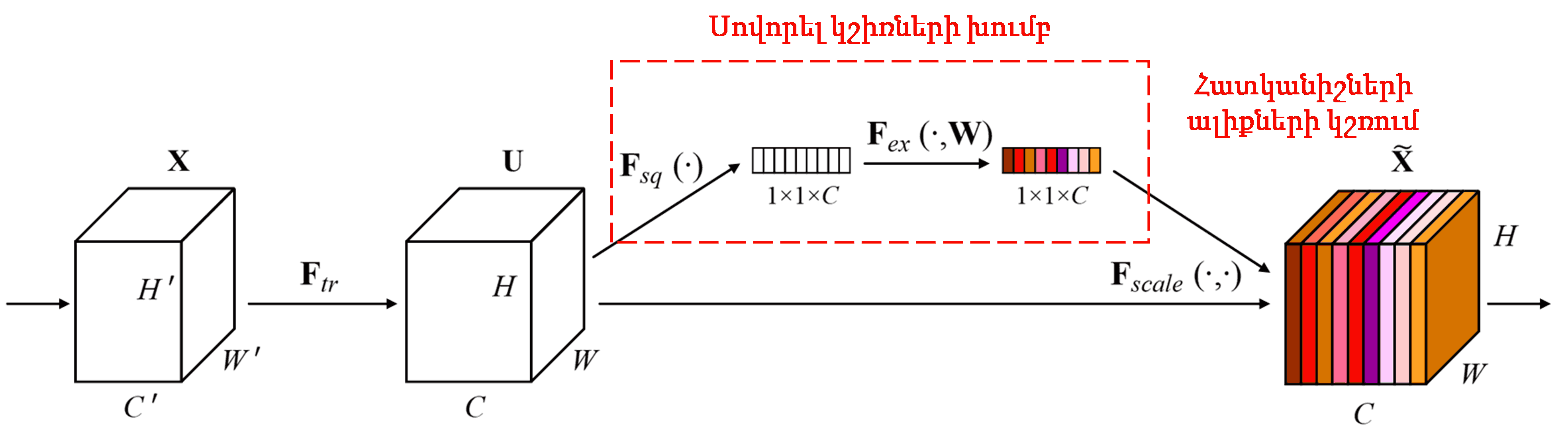
Այս եղանակով, յուրաքանչյուր նմուշ ունենում է կշիռների իր անհատական խումբը։ Այլ կերպ ասած՝ ցանկացած երկու նմուշի կշիռները տարբեր են։ SENet-ում կշիռների ստացման կոնկրետ ճանապարհն է՝ «Global Pooling → Fully Connected Layer → ReLU → Fully Connected Layer → Sigmoid»:
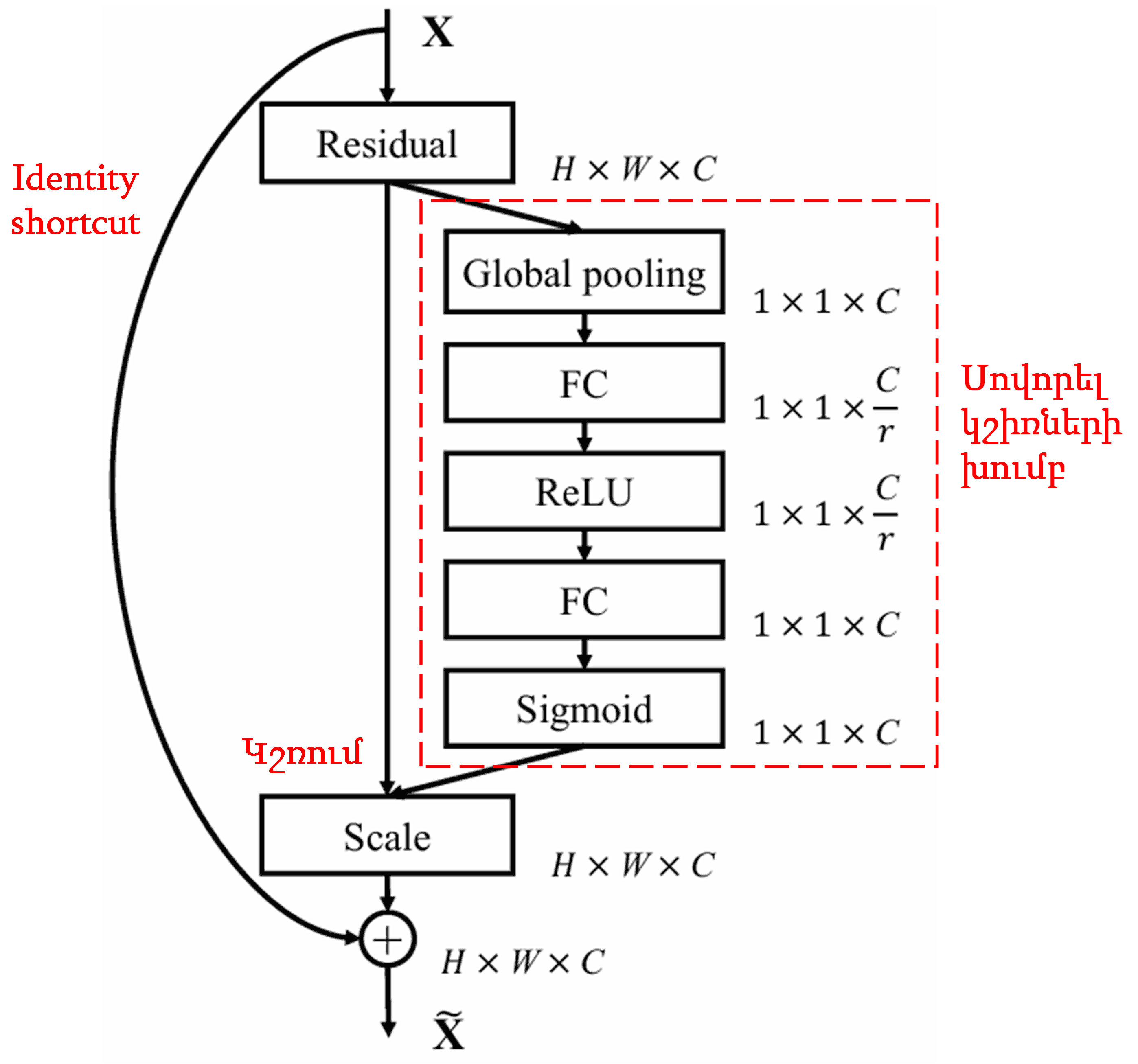
4. Soft Thresholding՝ Deep Attention Mechanism-ի կիրառմամբ
Deep Residual Shrinkage Network-ը փոխառել է վերը նշված SENet-ի ենթացանցի կառուցվածքը, որպեսզի իրականացնի soft thresholding՝ խորը ուշադրության մեխանիզմի կիրառմամբ։ Կարմիր շրջանակի մեջ գտնվող ենթացանցի միջոցով հնարավոր է սովորել (learn) շեմերի մի խումբ և կիրառել soft thresholding յուրաքանչյուր հատկանիշի ալիքի (feature channel) համար։
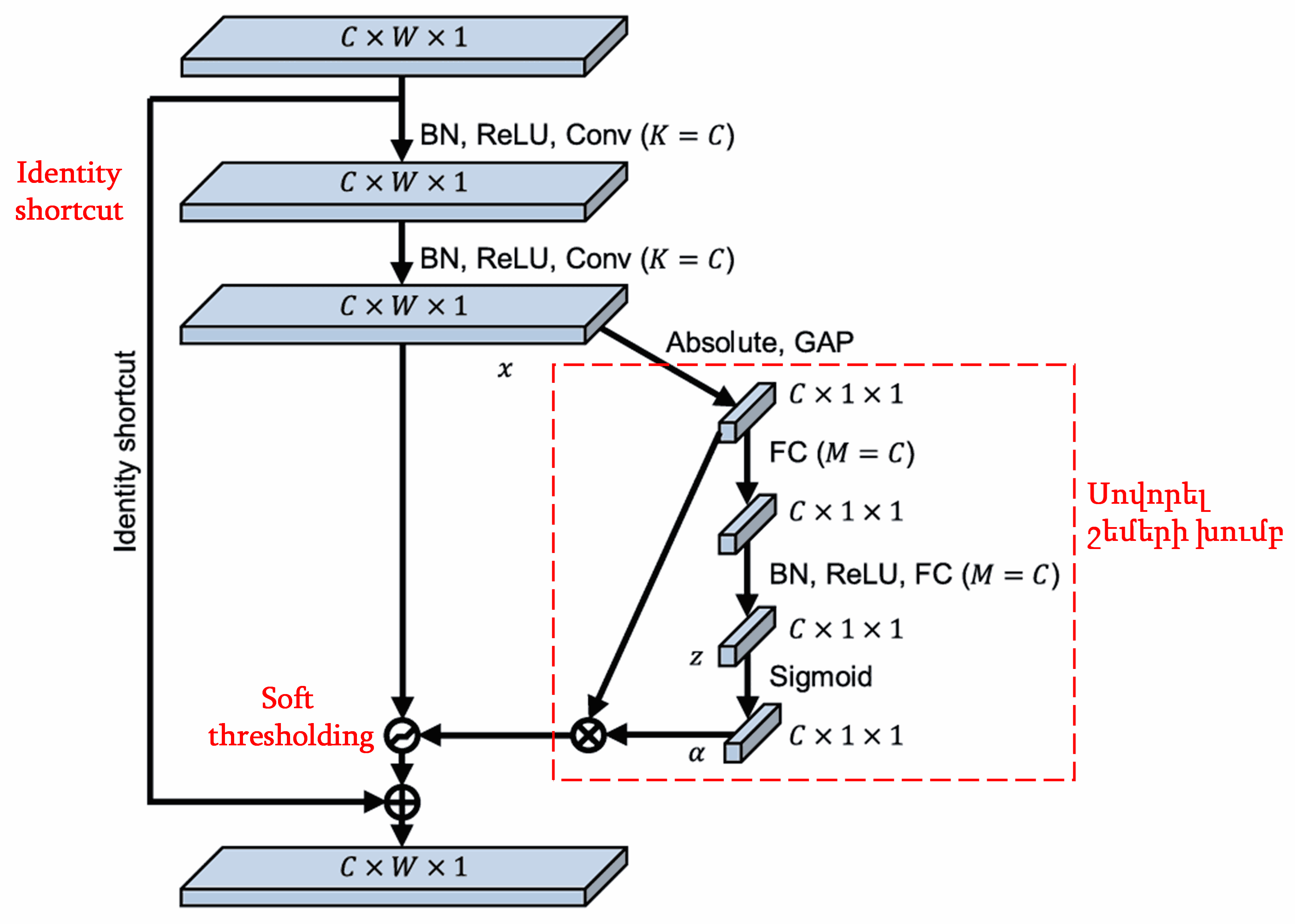
Այս ենթացանցում, նախ հաշվարկվում է մուտքային feature map-ի բոլոր հատկանիշների բացարձակ արժեքը։ Այնուհետև, global average pooling-ի և միջինացման միջոցով ստացվում է մի հատկանիշ, որը նշանակենք A։ Մյուս ճանապարհով՝ global average pooling-ից հետո feature map-ը մուտքագրվում է փոքր fully connected ցանց։ Այս fully connected ցանցը որպես վերջին շերտ օգտագործում է Sigmoid ֆունկցիան, որպեսզի ելքը նորմալացնի 0-ի և 1-ի միջև՝ ստանալով մի գործակից, որը նշանակենք α։ Վերջնական շեմը կարելի է ներկայացնել որպես α × A։ Այսպիսով, շեմը իրենից ներկայացնում է 0-ի և 1-ի միջև ընկած թվի և feature map-ի բացարձակ արժեքների միջինի արտադրյալը։ Այս եղանակը երաշխավորում է, որ շեմը ոչ միայն դրական է, այլև չափազանց մեծ չէ։
Ավելին, տարբեր նմուշներ կունենան տարբեր շեմեր։ Հետևաբար, որոշակի իմաստով, սա կարելի է հասկանալ որպես հատուկ attention mechanism․ նկատել տվյալ խնդրի հետ կապ չունեցող հատկանիշները, երկու կոնվոլյուցիոն շերտերի (convolutional layers) միջոցով դրանք փոխակերպել 0-ին մոտ արժեքների և soft thresholding-ի միջոցով զրոյացնել դրանք։ Կամ հակառակը՝ նկատել խնդրի հետ կապ ունեցող հատկանիշները, փոխակերպել դրանք 0-ից հեռու արժեքների և պահպանել դրանք։
Վերջապես, դասավորելով որոշակի քանակությամբ հիմնական մոդուլներ, ինչպես նաև կոնվոլյուցիոն շերտեր, Batch Normalization, ակտիվացման ֆունկցիաներ, global average pooling և fully connected ելքային շերտ, ստացվում է ամբողջական Deep Residual Shrinkage Network-ը։
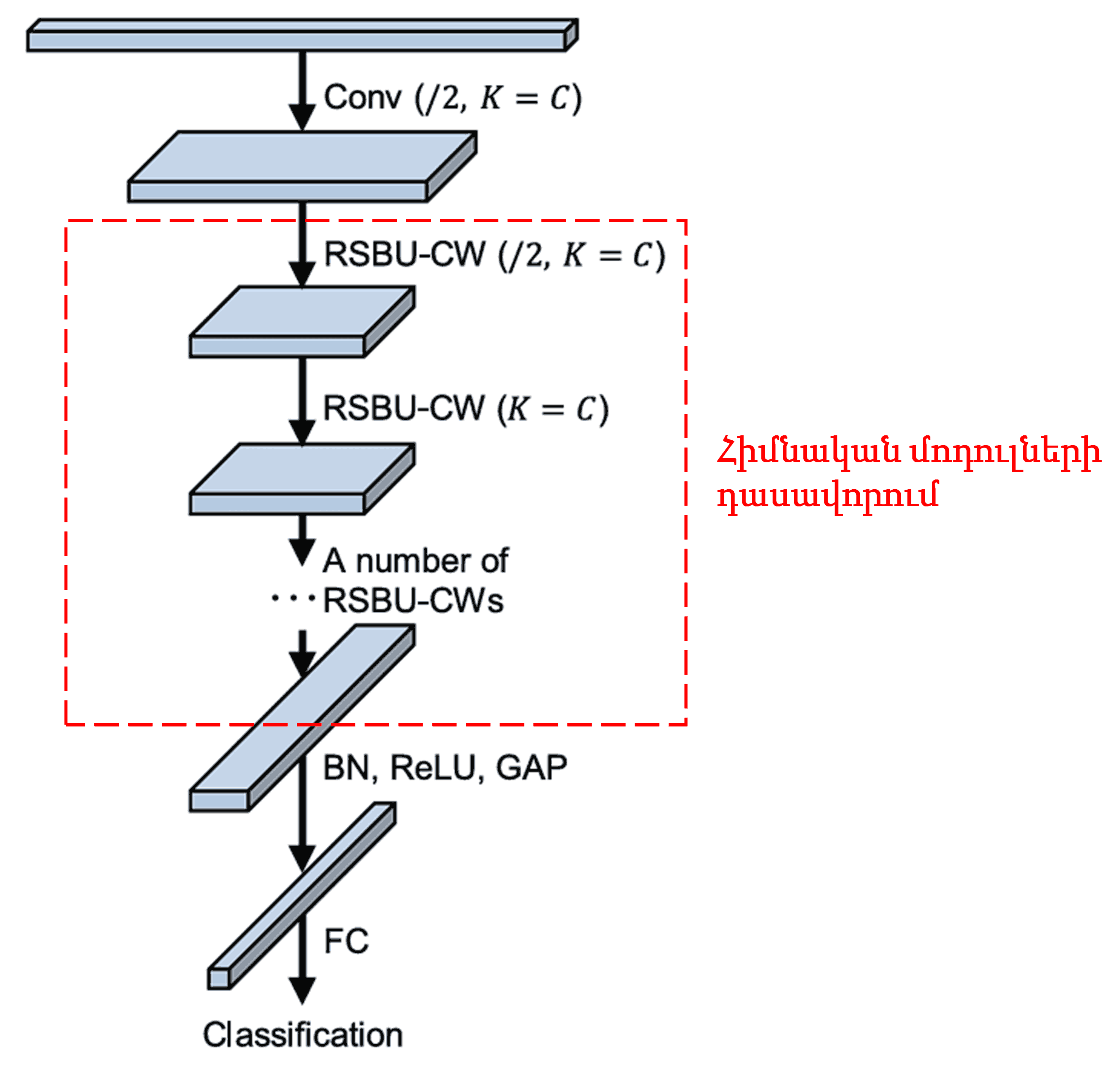
5. Ունիվերսալություն (Generalization Capability)
Deep Residual Shrinkage Network-ը փաստացի հատկանիշների ուսուցման (feature learning) ունիվերսալ մեթոդ է։ Պատճառն այն է, որ feature learning-ի շատ խնդիրներում նմուշները այս կամ այն չափով պարունակում են աղմուկ կամ ոչ ռելևանտ ինֆորմացիա։ Այս աղմուկը կարող է ազդել ուսուցման արդյունավետության վրա։ Օրինակ՝
Պատկերների դասակարգման (image classification) ժամանակ, եթե նկարը պարունակում է շատ այլ օբյեկտներ, այդ օբյեկտները կարելի է ընկալել որպես «աղմուկ»։ DRSN-ը կարող է attention mechanism-ի օգնությամբ նկատել այդ «աղմուկը», այնուհետև soft thresholding-ի միջոցով զրոյացնել այդ «աղմուկին» համապատասխանող հատկանիշները՝ դրանով իսկ բարձրացնելով դասակարգման ճշգրտությունը։
Խոսքի ճանաչման (speech recognition) դեպքում, եթե միջավայրը աղմկոտ է (օրինակ՝ զրույց փողոցում կամ գործարանում), DRSN-ը կարող է բարելավել ճանաչման ճշգրտությունը կամ գոնե առաջարկել մոտեցում, որը կօգնի այդ հարցում։
Հղումներ (Reference)
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Ակադեմիական ազդեցությունը
Google Scholar-ում այս հոդվածի հղումների քանակը գերազանցել է 1400-ը։
Ըստ ոչ պաշտոնական վիճակագրության՝ Deep Residual Shrinkage Network-ը կիրառվել է ավելի քան 1000 գիտական հոդվածներում՝ ուղղակիորեն կամ բարելավված տարբերակներով։ Այն օգտագործվել է բազմաթիվ ոլորտներում, ներառյալ մեխանիկական ինժեներիան, էլեկտրաէներգետիկան, համակարգչային տեսողությունը, բժշկությունը, խոսքի մշակումը, տեքստի վերլուծությունը, ռադիոլոկացիան և հեռահար զոնդավորումը (remote sensing):