A Deep Residual Shrinkage Network (DRSN) a klasszikus Deep Residual Network (ResNet) egy továbbfejlesztett változata. Lényegében a ResNet, a figyelem mechanizmus (attention mechanism) és a lágy küszöbölés (soft thresholding) integrációja.
A Deep Residual Shrinkage Network működési elve bizonyos mértékig a következőképpen fogható fel: a figyelem mechanizmus segítségével észleli a nem fontos jellemzőket, majd a lágy küszöbölés révén nullára állítja őket; ezzel szemben a fontos jellemzőket észleli és megtartja. Ez a folyamat megerősíti a mély neurális hálózat azon képességét, hogy hasznos információt nyerjen ki a zajos jelekből.
1. Kutatási motiváció
Először is, a minták osztályozása során elkerülhetetlen, hogy a mintákban valamilyen zaj legyen jelen, mint például Gauss-zaj, rózsaszín zaj, Laplace-zaj stb. Tágabb értelemben véve a minták gyakran tartalmaznak olyan információkat is, amelyek irrelevánsak az aktuális osztályozási feladat szempontjából; ezeket szintén zajként értelmezhetjük. Ezek a zajok negatívan befolyásolhatják az osztályozás eredményességét. (Megjegyzés: a lágy küszöbölés számos jelfeldolgozási és zajszűrési algoritmus kulcsfontosságú lépése.)
Például, ha az út szélén beszélgetünk, a beszédhangba óhatatlanul belevegyülhetnek a járművek dudaszavai vagy a kerekek zaja. Ha ezeken a jeleken beszédfelismerést végzünk, az eredményt elkerülhetetlenül rontják ezek a háttérzajok. A mélytanulás (Deep Learning) szemszögéből nézve a dudaszónak és a kerekek zajának megfelelő jellemzőket (feature-öket) törölni kellene a mély neurális hálózaton belül, hogy ne rontsák a beszédfelismerés hatékonyságát.
Másodszor, még egyazon adatkészleten belül is gyakran eltérő a zaj mértéke az egyes mintákban. (Ez rokonítható a figyelem mechanizmussal: például egy képadatbázisban a céltárgy elhelyezkedése képenként változhat, és a figyelem mechanizmus képes minden egyes képen a céltárgy konkrét helyére fókuszálni.)
Vegyünk például egy kutya-macska osztályozót. A „kutya” címkével ellátott 5 kép közül az elsőn lehet egy kutya és egy egér, a másodikon egy kutya és egy liba, a harmadikon egy kutya és egy csirke, a negyediken egy kutya és egy szamár, az ötödiken pedig egy kutya és egy kacsa. A kutya-macska osztályozó tanításakor elkerülhetetlenül zavart okoznak az olyan irreleváns objektumok, mint az egér, a liba, a csirke, a szamár és a kacsa, ami az osztályozási pontosság csökkenéséhez vezet. Ha képesek lennénk észlelni ezeket az irreleváns objektumokat, és törölni a hozzájuk tartozó jellemzőket, akkor javíthatnánk az osztályozó pontosságát.
2. Lágy küszöbölés (Soft Thresholding)
A lágy küszöbölés számos jelzajszűrő algoritmus központi lépése. Lényege, hogy azokat a jellemzőket, amelyek abszolút értéke kisebb egy bizonyos küszöbértéknél, törli, míg a küszöbértéknél nagyobb abszolút értékű jellemzőket a nulla irányába „összehúzza” (shrinkage). Ez a következő képlettel valósítható meg:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]A lágy küszöbölés kimenetének deriváltja a bemenet függvényében:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]A fentiekből látható, hogy a lágy küszöbölés deriváltja vagy 1, vagy 0. Ez a tulajdonság megegyezik a ReLU aktivációs függvényével. Ezért a lágy küszöbölés alkalmazása csökkentheti annak kockázatát, hogy a mélytanuló algoritmusok a gradiens eltűnésének (gradient vanishing) vagy a gradiens robbanásának (gradient exploding) problémájával szembesüljenek.
A lágy küszöbölési függvényben a küszöbérték beállításának két feltételnek kell megfelelnie: Először is, a küszöbértéknek pozitívnak kell lennie. Másodszor, a küszöbérték nem lehet nagyobb a bemeneti jel maximális értékénél, különben a kimenet csupa nulla lesz.
Ugyanakkor célszerű, ha a küszöbérték megfelel egy harmadik feltételnek is: minden mintának a saját zajszintjéhez igazodó, független küszöbértékkel kell rendelkeznie.
Ez azért fontos, mert a minták zajtartalma gyakran eltérő. Például egy adatkészletben gyakran előfordul, hogy az „A” minta kevesebb zajt tartalmaz, míg a „B” minta többet. Ilyenkor a zajszűrő algoritmusban végzett lágy küszöbölés során az „A” mintához kisebb, míg a „B” mintához nagyobb küszöbértéket kellene alkalmazni. Bár a mély neurális hálózatokban ezek a jellemzők és küszöbértékek elveszítik közvetlen fizikai jelentésüket, az alapvető logika ugyanaz marad. Vagyis minden mintához a saját zajtartalmától függő, egyedi küszöbértékre van szükség.
3. Figyelem mechanizmus (Attention Mechanism)
A figyelem mechanizmus a számítógépes látás (Computer Vision) területén viszonylag könnyen érthető. Az állatok látórendszere képes gyorsan átvizsgálni a teljes területet, felfedezni a céltárgyat, majd a figyelmet a céltárgyra összpontosítani, hogy több részletet nyerjen ki, miközben elnyomja az irreleváns információkat. A részletekért kérjük, olvasson utána a figyelem mechanizmussal foglalkozó szakirodalomban.
A Squeeze-and-Excitation Network (SENet) egy viszonylag új mélytanulási módszer, amely a figyelem mechanizmuson alapul. Különböző minták esetén a különböző jellemzőcsatornák (feature channels) hozzájárulása az osztályozási feladathoz gyakran eltérő. A SENet egy kisméretű alhálózat segítségével előállít egy súlykészletet, majd ezekkel a súlyokkal megszorozza az egyes csatornák jellemzőit, így szabályozva azok méretét. Ez a folyamat úgy értelmezhető, mintha különböző mértékű figyelmet fordítanánk az egyes jellemzőcsatornákra.
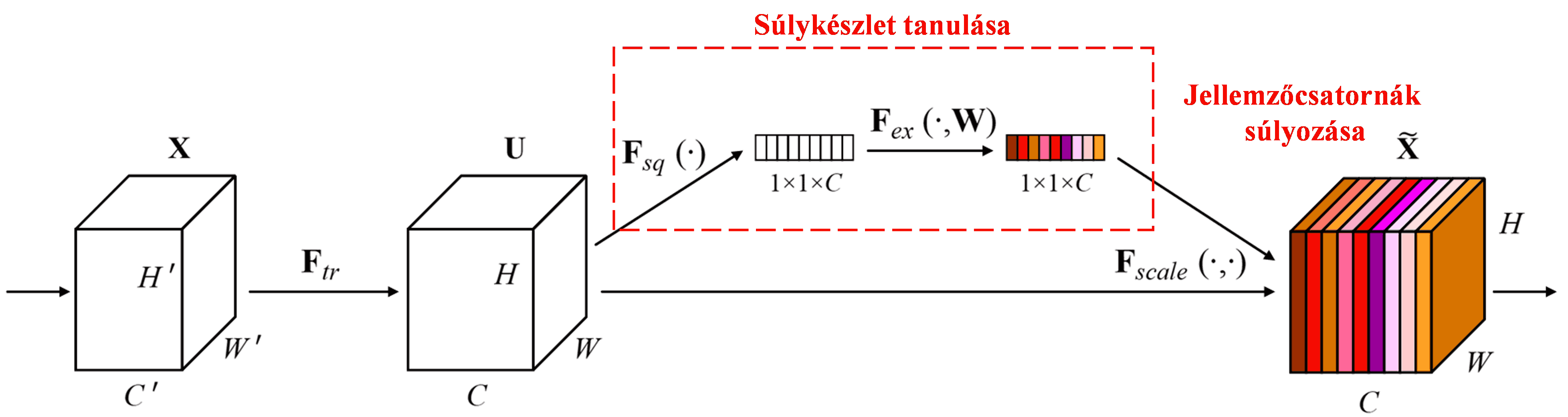
Ezzel a módszerrel minden egyes minta saját, független súlykészlettel rendelkezik. Más szóval, bármely két minta súlyai eltérőek. A SENet-ben a súlyok előállításának konkrét útvonala: „Globális pooling → Teljesen összekapcsolt (FC) réteg → ReLU függvény → Teljesen összekapcsolt (FC) réteg → Sigmoid függvény”.
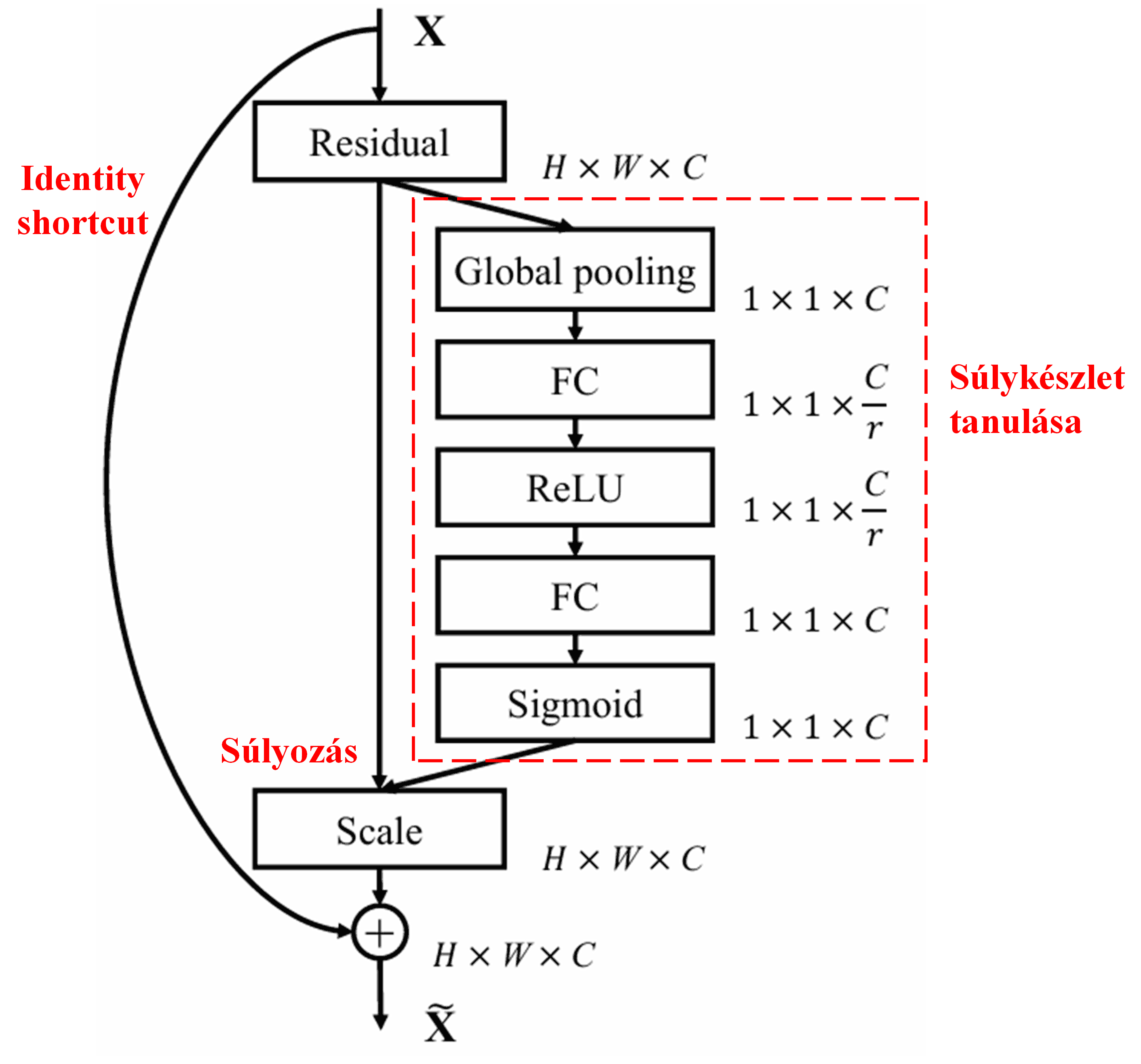
4. Lágy küszöbölés mély figyelem mechanizmussal
A Deep Residual Shrinkage Network a fent említett SENet alhálózati struktúrájából merít ihletet, hogy megvalósítsa a lágy küszöbölést egy mély figyelem mechanizmus keretében. A piros kerettel jelölt alhálózaton keresztül a rendszer megtanul egy küszöbérték-készletet, amellyel végrehajtja a lágy küszöbölést az egyes jellemzőcsatornákon.
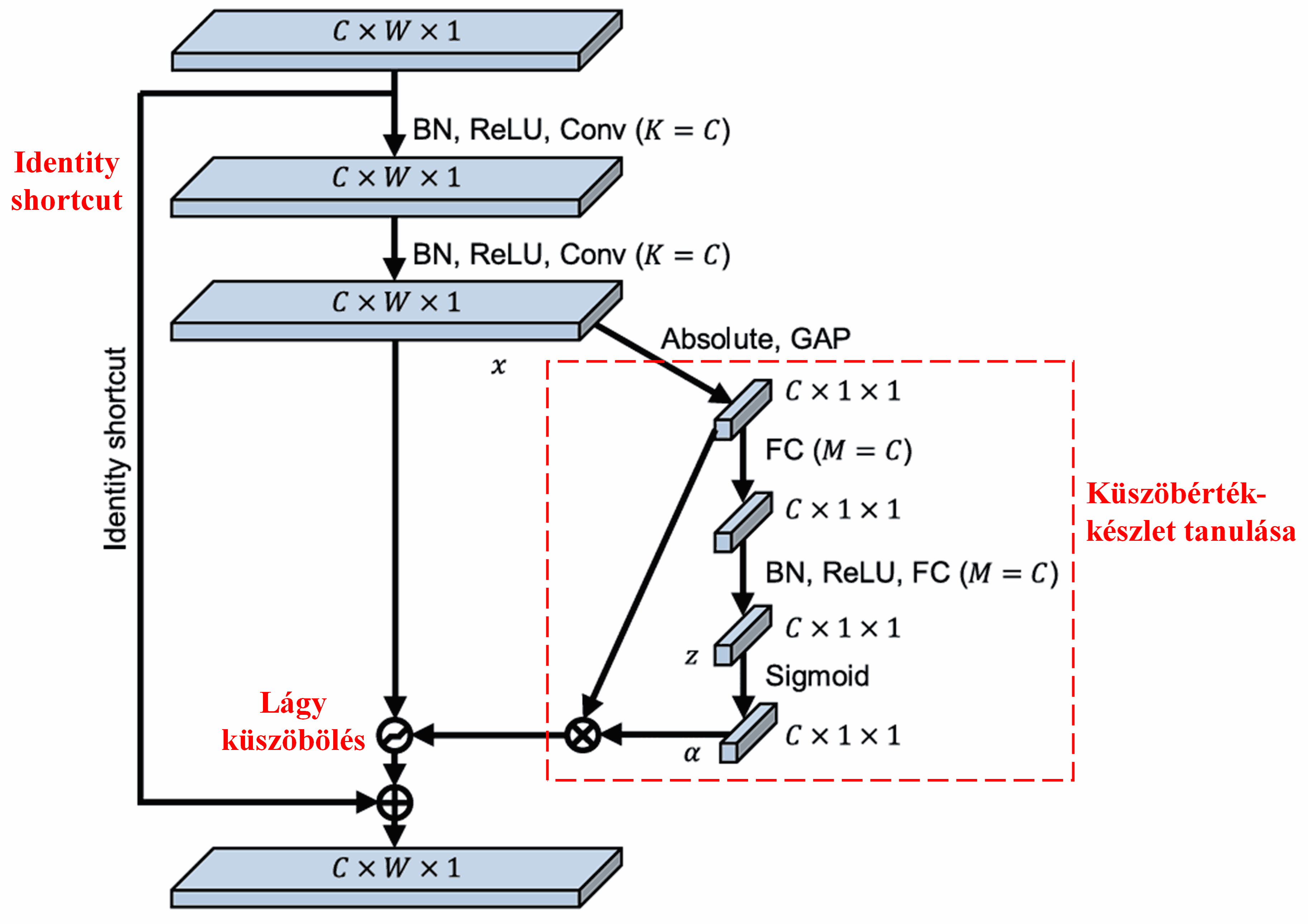
Ebben az alhálózatban először a bemeneti jellemzőtérkép (feature map) összes elemének vesszük az abszolút értékét. Ezután a globális átlagoló pooling (Global Average Pooling, GAP) és átlagolás révén kapunk egy jellemzőt, amelyet jelöljünk A-val. Egy másik útvonalon a globális átlagoló pooling után kapott jellemzőtérképet egy kisméretű, teljesen összekapcsolt hálózatba vezetjük. Ennek a hálózatnak az utolsó rétege egy Sigmoid függvény, amely a kimenetet 0 és 1 közé normalizálja; az így kapott együtthatót jelöljük α-val. A végső küszöbérték az α×A képlettel fejezhető ki. Tehát a küszöbérték egy 0 és 1 közötti szám szorozva a jellemzőtérkép abszolút értékeinek átlagával. Ez a módszer biztosítja, hogy a küszöbérték nemcsak pozitív, de nem is túl nagy.
Ráadásul a különböző minták különböző küszöbértékeket kapnak. Ezért ez bizonyos mértékig egy speciális figyelem mechanizmusként értelmezhető: észleli az aktuális feladat szempontjából irreleváns jellemzőket, két konvolúciós rétegen keresztül nullához közeli értékké alakítja őket, majd a lágy küszöböléssel nullára állítja ezeket; illetve észleli a releváns jellemzőket, két konvolúciós rétegen keresztül a nullától távoli értékké alakítja, és megőrzi őket.
Végezetül, bizonyos számú alapmodul, valamint konvolúciós rétegek, Batch Normalization, aktivációs függvények, globális átlagoló pooling és teljesen összekapcsolt kimeneti rétegek egymásra építésével megkapjuk a teljes Deep Residual Shrinkage Network-öt.
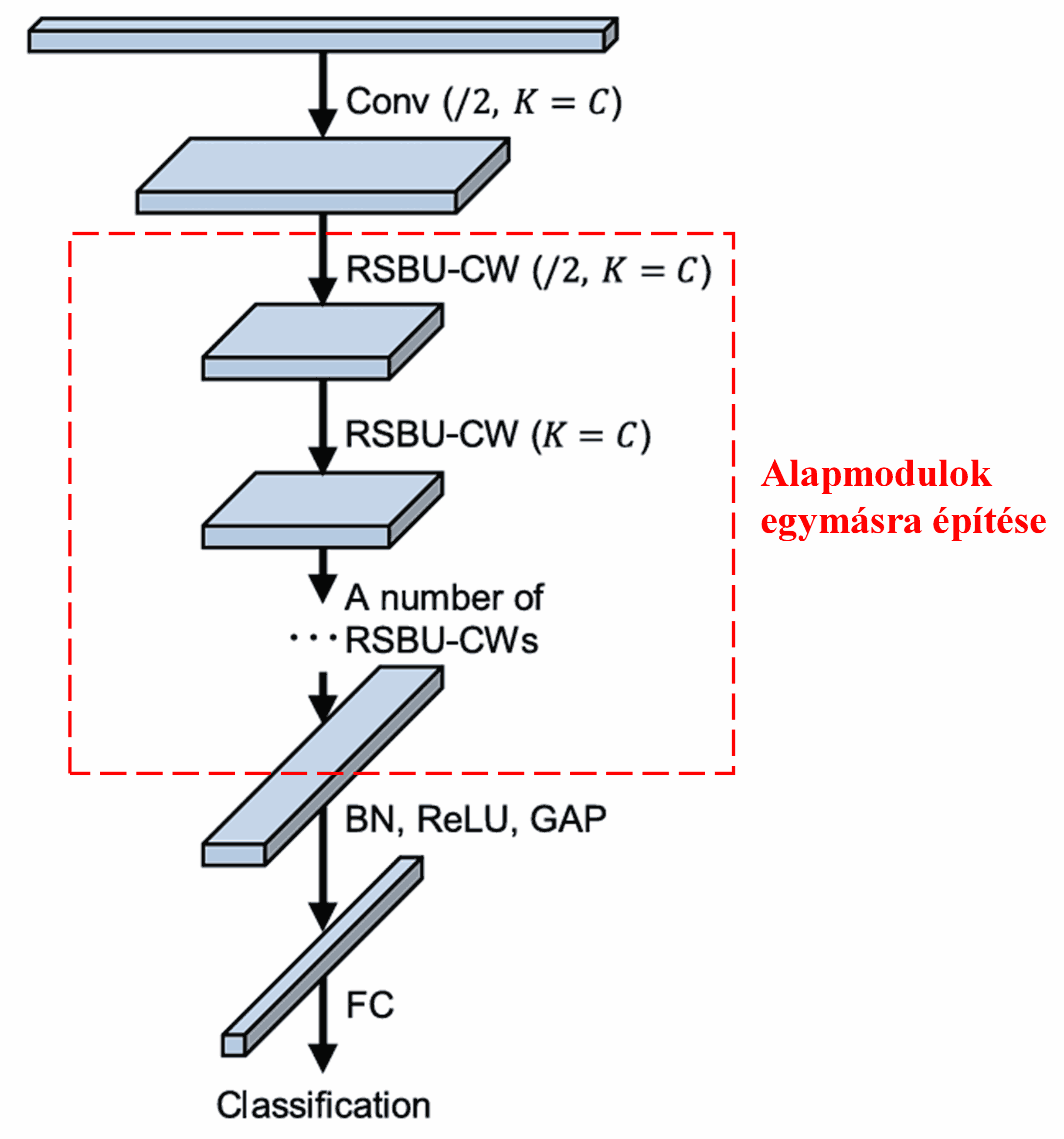
5. Általánosíthatóság (Univerzalitás)
A Deep Residual Shrinkage Network valójában egy általános célú jellemzőtanulási (feature learning) módszer. Ez azért van így, mert számos jellemzőtanulási feladatban a minták több-kevesebb zajt, valamint irreleváns információt tartalmaznak. Ezek a zajok és irreleváns információk befolyásolhatják a tanulás hatékonyságát. Például:
Képosztályozásnál, ha a képen sok egyéb tárgy is szerepel, ezek „zajként” értelmezhetők. A Deep Residual Shrinkage Network a figyelem mechanizmus segítségével észlelheti ezt a „zajt”, majd a lágy küszöbölés révén nullára állíthatja a hozzá tartozó jellemzőket, ami javíthatja a képosztályozás pontosságát.
Beszédfelismerésnél, ha a környezet zajos – például egy út mellett vagy egy gyárcsarnokban történő beszélgetés során –, a Deep Residual Shrinkage Network javíthatja a felismerés pontosságát, vagy legalábbis egy olyan megközelítést kínál, amely képes lehet erre.
Hivatkozások
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Tudományos hatás
A tanulmányra a Google Scholar adatai szerint már több mint 1400 alkalommal hivatkoztak.
A nem teljes körű statisztikák alapján a Deep Residual Shrinkage Network (DRSN) módszert több mint 1000 publikációban alkalmazták közvetlenül, vagy annak továbbfejlesztett változatát használták fel számos területen, beleértve a gépészetet, a villamosenergia-ipart, a gépi látást, az orvostudományt, a beszédfeldolgozást, a szövegelemzést, a radar- és távérzékelési technológiákat.