Deep Residual Shrinkage Network (DRSN) je poboljšana varijanta Deep Residual Networka (ResNet). U suštini, radi se o integraciji ResNeta, mehanizama pažnje (attention mechanisms) i funkcija mekog pragovanja (soft thresholding).
U određenoj mjeri, princip rada Deep Residual Shrinkage Networka može se razumjeti na sljedeći način: koristi mehanizme pažnje kako bi uočio nevažne značajke (features), koje se zatim pomoću funkcije mekog pragovanja postavljaju na nulu; s druge strane, uočava važne značajke i zadržava ih. Time se jača sposobnost duboke neuronske mreže za izdvajanje korisnih značajki iz signala koji sadrže šum.
1. Motivacija istraživanja
Prvo, prilikom klasifikacije uzoraka, pojava šuma u uzorcima je neizbježna, poput Gaussovog šuma, ružičastog šuma, Laplaceovog šuma itd. U širem smislu, uzorci često sadrže informacije koje nisu relevantne za trenutni zadatak klasifikacije, a te se informacije također mogu shvatiti kao šum. Takav šum može negativno utjecati na rezultate klasifikacije. (Meko pragovanje je ključni korak u mnogim algoritmima za uklanjanje šuma, tj. signal denoising).
Na primjer, tijekom razgovora uz cestu, zvuk govora može se miješati sa zvukovima automobilskih truba, kotača i slično. Kada se na takvim zvučnim signalima provodi prepoznavanje govora, zvukovi truba i kotača neizbježno će utjecati na točnost prepoznavanja. Iz perspektive dubokog učenja (deep learning), značajke koje odgovaraju tim zvukovima (trube, kotači) trebale bi se ukloniti unutar duboke neuronske mreže kako ne bi narušavale rezultat prepoznavanja govora.
Drugo, čak i unutar istog skupa podataka, količina šuma često varira od uzorka do uzorka. (Ovo ima sličnosti s mehanizmima pažnje; ako uzmemo skup slika kao primjer, položaj ciljanog objekta može biti različit na svakoj slici; mehanizam pažnje može se fokusirati na točnu lokaciju ciljanog objekta na svakoj pojedinoj slici).
Na primjer, kada treniramo klasifikator za pse i mačke, uzmimo 5 slika s oznakom “pas”. Prva slika može sadržavati psa i miša, druga psa i gusku, treća psa i kokoš, četvrta psa i magarca, a peta psa i patku. Prilikom treniranja klasifikatora, neizbježno će doći do interferencije nepovezanih objekata (miš, guska, kokoš, magarac, patka), što dovodi do pada točnosti klasifikacije. Ako bismo mogli uočiti te irelevantne objekte i ukloniti značajke koje im pripadaju, mogli bismo povećati točnost klasifikatora.
2. Meko pragovanje (Soft Thresholding)
Meko pragovanje je ključni korak u mnogim algoritmima za uklanjanje šuma. Ono uklanja značajke čija je apsolutna vrijednost manja od određenog praga, dok značajke čija je apsolutna vrijednost veća od tog praga “sažima” (shrink) prema nuli. Može se implementirati pomoću sljedeće formule:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Derivacija izlaza mekog pragovanja u odnosu na ulaz je:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Kao što je vidljivo, derivacija mekog pragovanja je ili 1 ili 0. Ovo svojstvo je identično svojstvu ReLU aktivacijske funkcije. Stoga, meko pragovanje također može smanjiti rizik od problema nestajanja gradijenta (gradient vanishing) i eksplozije gradijenta (gradient exploding) u algoritmima dubokog učenja.
U funkciji mekog pragovanja, postavljanje praga mora zadovoljiti dva uvjeta: Prvo, prag mora biti pozitivan broj; Drugo, prag ne smije biti veći od maksimalne vrijednosti ulaznog signala, inače će svi izlazi biti nula.
Istovremeno, najbolje je da prag zadovoljava i treći uvjet: svaki uzorak trebao bi imati vlastiti, neovisni prag, ovisno o količini šuma koju sadrži.
To je zato što se količina šuma često razlikuje među uzorcima. Na primjer, česta je situacija da unutar istog skupa podataka uzorak A sadrži manje šuma, dok uzorak B sadrži više šuma. U tom slučaju, ako provodimo meko pragovanje unutar algoritma za uklanjanje šuma, za uzorak A trebao bi se koristiti manji prag, a za uzorak B veći prag. Iako u dubokim neuronskim mrežama ove značajke i pragovi gube svoje eksplicitno fizikalno značenje, osnovna logika ostaje ista. Drugim riječima, svaki uzorak trebao bi imati svoj nezavisni prag temeljen na vlastitoj razini šuma.
3. Mehanizam pažnje (Attention Mechanism)
Mehanizam pažnje je relativno lako razumljiv u području računalnog vida (computer vision). Vizualni sustav životinja može brzo skenirati cijelo područje kako bi otkrio ciljani objekt, a zatim fokusirati pažnju na taj objekt radi izdvajanja više detalja, istovremeno potiskujući nebitne informacije. Za detalje, molimo pogledajte literaturu o mehanizmima pažnje.
Squeeze-and-Excitation Network (SENet) je novija metoda dubokog učenja koja koristi mehanizam pažnje. Doprinos različitih kanala značajki (feature channels) klasifikacijskom zadatku često se razlikuje od uzorka do uzorka. SENet koristi malu pod-mrežu (sub-network) kako bi dobio skup težina, a zatim te težine množi sa značajkama odgovarajućih kanala kako bi prilagodio veličinu značajki u svakom kanalu. Ovaj proces može se smatrati primjenom različite razine pažnje na različite kanale značajki.
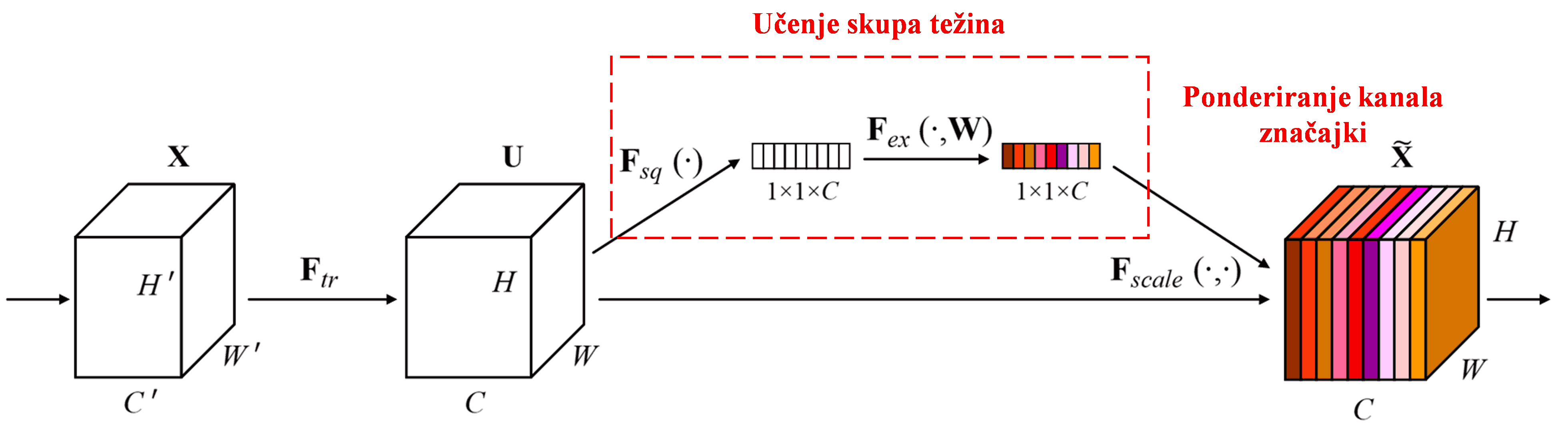
Na ovaj način, svaki uzorak ima svoj neovisni skup težina. Drugim riječima, težine za bilo koja dva uzorka su različite. U SENet-u, specifična putanja za dobivanje težina je: “Globalno usrednjavanje (Global Pooling) → Potpuno povezani sloj (FC) → ReLU funkcija → Potpuno povezani sloj (FC) → Sigmoid funkcija”.
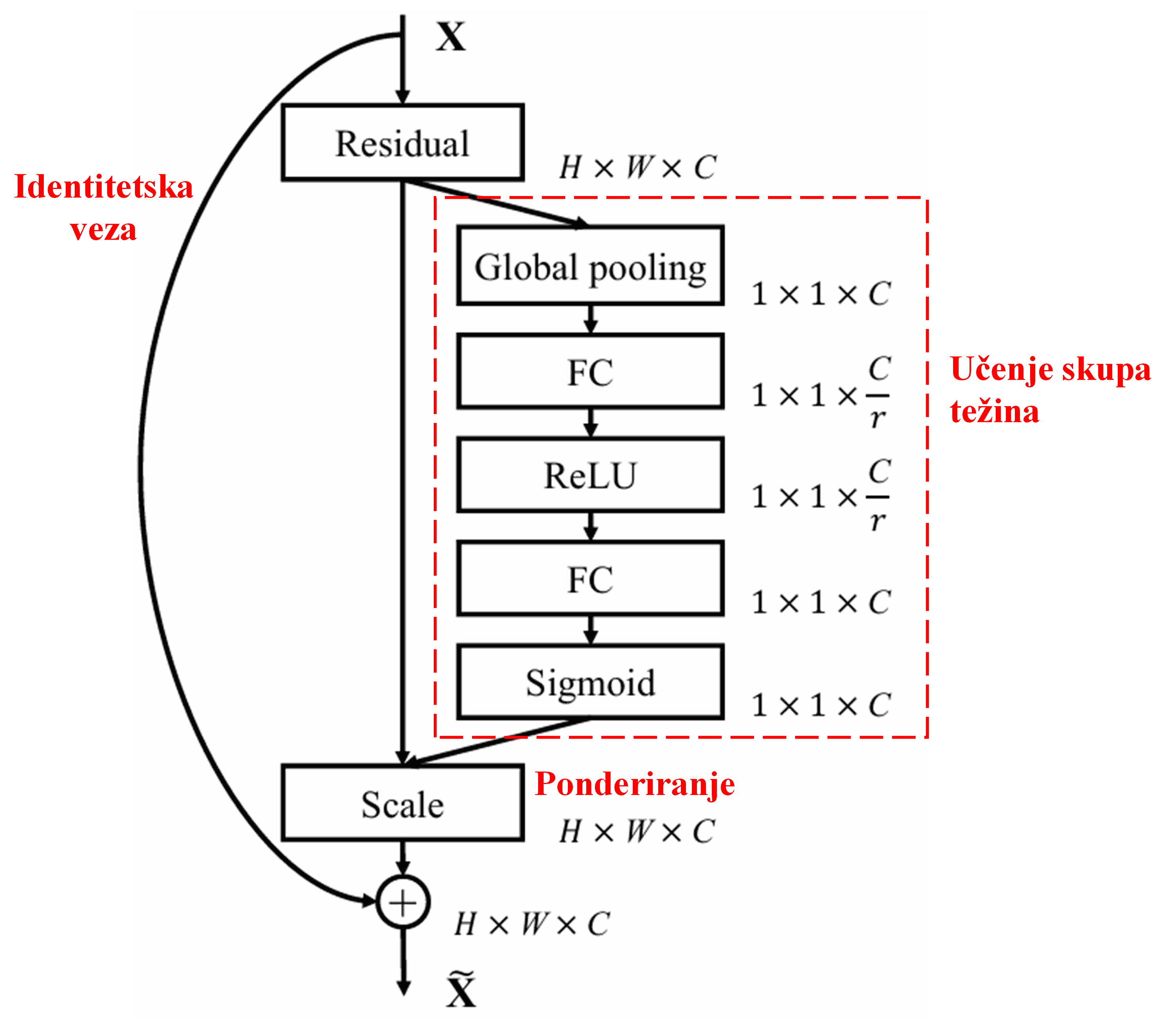
4. Meko pragovanje uz duboki mehanizam pažnje
Deep Residual Shrinkage Network preuzima strukturu spomenute pod-mreže iz SENet-a kako bi implementirao meko pragovanje unutar dubokog mehanizma pažnje. Putem te pod-mreže (prikazane unutar crvenog okvira u dijagramima arhitekture), moguće je naučiti skup pragova za primjenu mekog pragovanja na svaki kanal značajki.
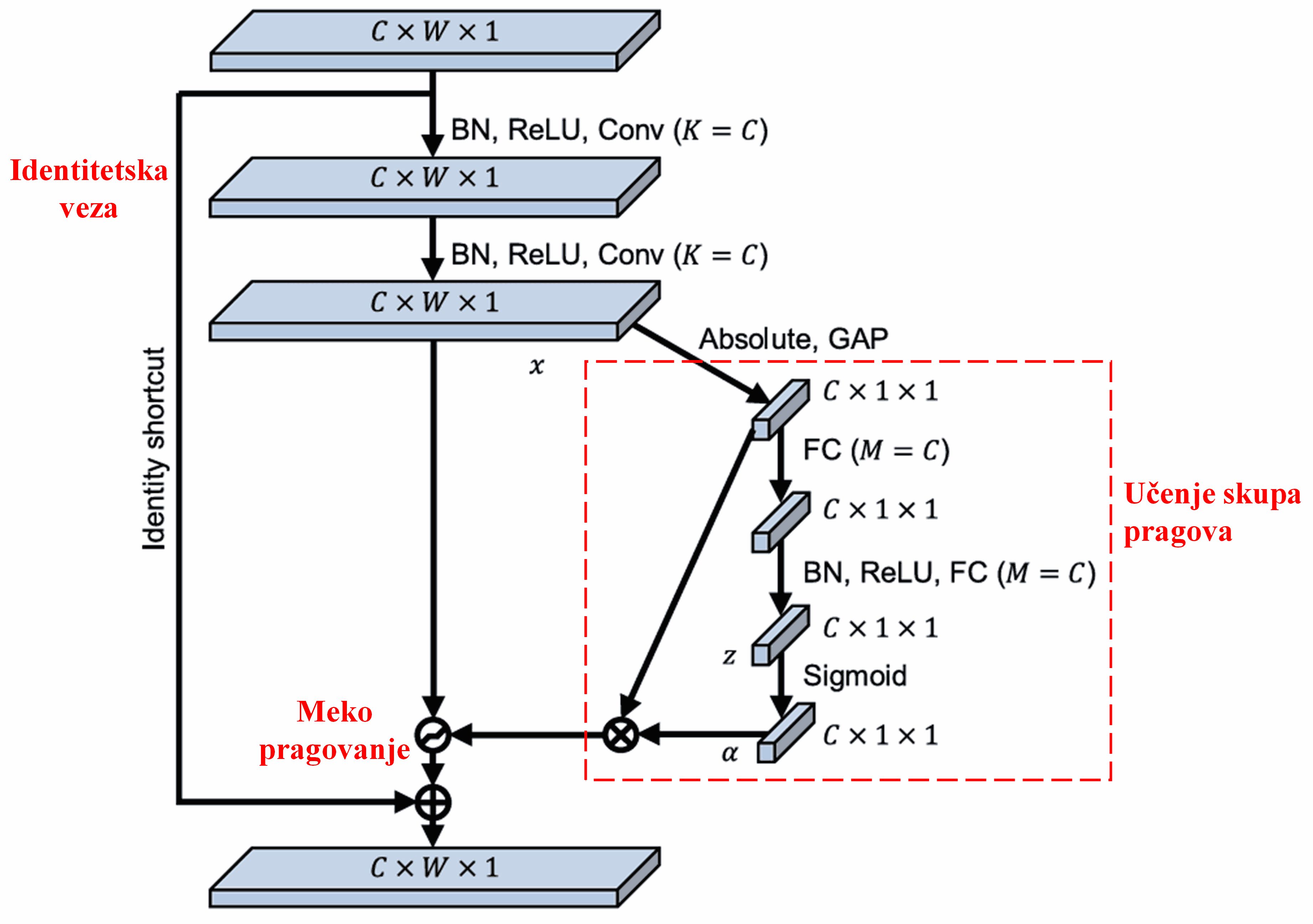
U ovoj pod-mreži, prvo se računaju apsolutne vrijednosti svih značajki na ulaznoj mapi značajki. Zatim se kroz globalno prosječno sažimanje (Global Average Pooling - GAP) i usrednjavanje dobiva jedna značajka, koju označavamo kao A. U drugom putu, mapa značajki nakon GAP-a ulazi u malu potpuno povezanu (FC) mrežu. Ova FC mreža koristi Sigmoid funkciju kao zadnji sloj kako bi normalizirala izlaz na vrijednost između 0 i 1, čime se dobiva koeficijent kojeg označavamo kao α. Konačni prag može se prikazati kao α×A. Dakle, prag je umnožak broja između 0 i 1 te prosjeka apsolutnih vrijednosti mape značajki. Ovakav način osigurava da je prag ne samo pozitivan, već i da nije prevelik.
Štoviše, različiti uzorci dobivaju različite pragove. Stoga se ovo u određenoj mjeri može shvatiti kao poseban mehanizam pažnje: uočava značajke koje nisu važne za trenutni zadatak, transformira ih (kroz dva konvolucijska sloja) u vrijednosti bliske nuli, te ih putem mekog pragovanja postavlja na nulu; ili, s druge strane, uočava značajke važne za trenutni zadatak, transformira ih u vrijednosti udaljene od nule i zadržava ih.
Konačno, slaganjem određenog broja ovih osnovnih modula, zajedno s konvolucijskim slojevima, Batch normalizacijom (BN), aktivacijskim funkcijama, globalnim prosječnim sažimanjem (GAP) i potpuno povezanim izlaznim slojem, dobiva se potpuni Deep Residual Shrinkage Network.
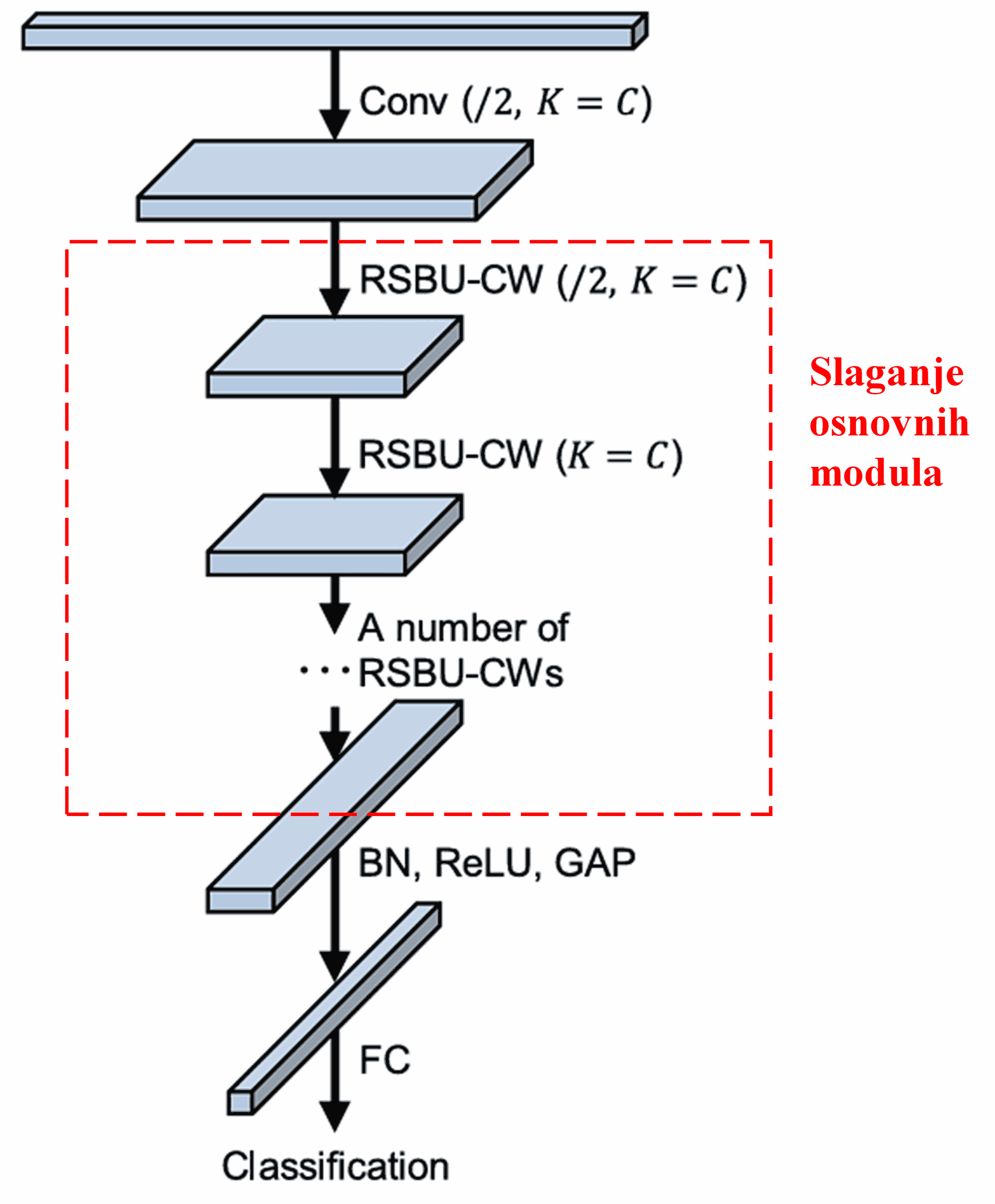
5. Univerzalnost primjene
Deep Residual Shrinkage Network je zapravo univerzalna metoda za učenje značajki. To je zato što u mnogim zadacima učenja značajki uzorci manje ili više sadrže određeni šum, kao i irelevantne informacije. Taj šum i irelevantne informacije mogu utjecati na učinkovitost učenja značajki. Na primjer:
Kod klasifikacije slika, ako slika istovremeno sadrži mnogo drugih objekata, ti se objekti mogu shvatiti kao “šum”; Deep Residual Shrinkage Network može pomoću mehanizma pažnje uočiti taj “šum”, a zatim pomoću mekog pragovanja postaviti značajke koje odgovaraju tom “šumu” na nulu, čime se može povećati točnost klasifikacije slika.
Kod prepoznavanja govora, posebno u bučnim okruženjima kao što su razgovor uz cestu ili u tvorničkoj hali, Deep Residual Shrinkage Network može poboljšati točnost prepoznavanja govora ili barem ponuditi pristup koji omogućuje poboljšanje točnosti.
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Utjecaj u akademskoj zajednici
Ovaj rad ima više od 1400 citata na Google Scholaru.
Prema nepotpunoj statistici, Deep Residual Shrinkage Network izravno je primijenjen ili poboljšan u više od 1000 radova u brojnim područjima, uključujući strojarstvo, energetiku, računalni vid, medicinu, obradu govora i teksta, radarsku tehnologiju, daljinska istraživanja i druga područja.