Deep Residual Shrinkage Network on sügavate jääkvõrkude (Deep Residual Networks ehk ResNet) edasiarendus. Sisuliselt on see ResNeti, tähelepanumehhanismide ja pehme lävendamise (soft thresholding) funktsioonide integratsioon.
Teatud määral võib Deep Residual Shrinkage Networki tööpõhimõtet mõista järgmiselt: tähelepanumehhanismi abil tuvastatakse ebaolulised tunnused, mis nullitakse pehme lävendamise funktsiooni kaudu; või vastupidi, märgatakse olulisi tunnuseid ja säilitatakse need. See tugevdab sügavate närvivõrkude võimet eraldada mürarikastest signaalidest kasulikke tunnuseid.
1. Uurimistöö motivatsioon
Esiteks, proovide (samples) klassifitseerimisel sisaldavad need paratamatult teatud määral müra, nagu Gaussi müra, roosa müra, Laplace’i müra jne. Laiemas plaanis sisaldavad proovid sageli teavet, mis ei ole praeguse klassifitseerimisülesandega seotud, ning ka seda võib tõlgendada mürana. See müra võib klassifitseerimise tulemust kahjustada. (Pehme lävendamine on paljude signaalimüra vähendamise algoritmide põhisamm.)
Näiteks tänaval vesteldes võib kõne sisse seguneda autode signaalitamist, rattamüra jne. Nende helisignaalide tuvastamisel (kõnetuvastus) mõjutavad tulemust paratamatult taustahelid. Sügavõppe (Deep Learning) seisukohalt tuleks signaalitamisele ja rattamürale vastavad tunnused sügava närvivõrgu sees kustutada, et vältida nende mõju kõnetuvastuse tulemustele.
Teiseks, isegi samas andmekogumis on eri proovide müratase sageli erinev. (Sellel on sarnasusi tähelepanumehhanismiga; näiteks piltide puhul võib sihtobjekt asuda igal pildil eri kohas ja tähelepanumehhanism suudab keskenduda just sellele asukohale.)
Näiteks kassi ja koera klassifikaatori treenimisel: viie “koera” sildiga pildi puhul võib esimene pilt sisaldada koera ja hiirt, teine koera ja hane, kolmas koera ja kana, neljas koera ja eeslit ning viies koera ja parti. Klassifikaatori treenimisel segavad meid paratamatult asjakohatud objektid (hiir, hani, kana, eesel, part), mis vähendab täpsust. Kui suudame neid ebaolulisi objekte märgata ja neile vastavad tunnused eemaldada, on võimalik kassi-koera klassifikaatori täpsust parandada.
2. Pehme lävendamine (Soft Thresholding)
Pehme lävendamine on paljude signaalimüra vähendamise algoritmide põhisamm. See eemaldab tunnused, mille absoluutväärtus on väiksem kui teatud lävend (threshold), ja ahendab sellest lävendist suurema absoluutväärtusega tunnuseid nulli suunas. Seda saab väljendada järgmise valemiga:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Pehme lävendamise väljundi tuletis sisendi suhtes on:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Ülaltoodust nähtub, et pehme lävendamise tuletis on kas 1 või 0. See omadus on identne ReLU aktiveerimisfunktsiooniga. Seetõttu aitab pehme lävendamine vähendada riski, et sügavõppe algoritmides tekiksid gradientide hääbumise (gradient vanishing) või plahvatamise (gradient exploding) probleemid.
Pehme lävendamise funktsioonis peab lävendi seadistus vastama kahele tingimusele: esiteks peab lävend olema positiivne arv; teiseks ei tohi lävend olla suurem kui sisendsignaali maksimumväärtus, vastasel juhul on väljundiks ainult nullid.
Samuti on soovitav, et lävend vastaks kolmandale tingimusele: igal proovil peaks olema oma sõltumatu lävend, mis põhineb proovi enda mürasisaldusel.
See on vajalik, kuna proovide mürasisaldus on sageli erinev. Näiteks andmekogumis võib proov A sisaldada vähem müra ja proov B rohkem müra. Sel juhul peaks müravähenduse algoritmis rakendama proovile A väiksemat lävendit ja proovile B suuremat lävendit. Kuigi sügavates närvivõrkudes kaotavad need tunnused ja lävendid oma otsese füüsikalise tähenduse, jääb põhimõte samaks. Ehk siis: igal proovil peaks olema sõltumatu lävend, mis on määratud selle konkreetse müra põhjal.
3. Tähelepanumehhanism (Attention Mechanism)
Tähelepanumehhanism on arvutinägemise valdkonnas üsna kergesti mõistetav. Loomade nägemissüsteem suudab kiiresti skaneerida kogu ala, avastada sihtobjekti ja seejärel koondada tähelepanu sellele, et eraldada rohkem detaile, surudes samal ajal alla ebaolulist teavet. Täpsema info saamiseks vaadake tähelepanumehhanisme käsitlevat kirjandust.
Squeeze-and-Excitation Network (SENet) on suhteliselt uus sügavõppe meetod, mis kasutab tähelepanumehhanisme. Erinevates proovides on eri tunnustekanalite (feature channels) panus klassifitseerimisülesandesse sageli erinev. SENet kasutab väikest alamvõrku (sub-network), et leida hulk kaalusid, ja korrutab need kaalud vastavate kanalite tunnustega, et reguleerida iga kanali tunnuste suurust. Seda protsessi võib vaadelda kui erineva suurusega tähelepanu pööramist erinevatele tunnustekanalitele.
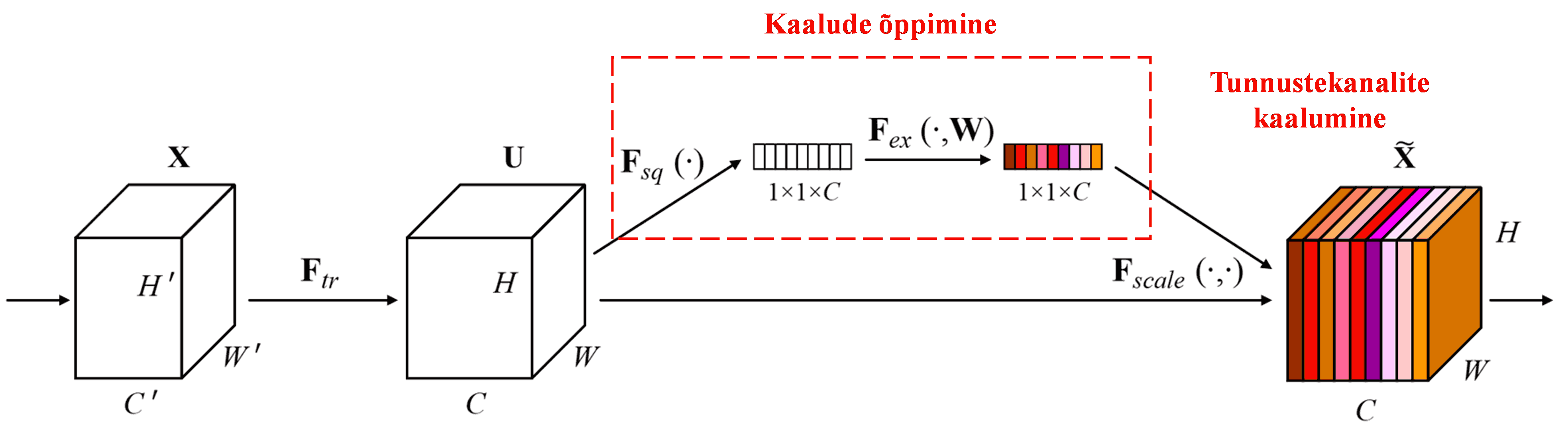
Sellisel viisil on igal proovil oma sõltumatu kaalude komplekt. Teisisõnu, kahe suvalise proovi kaalud on erinevad. SENetis on kaalude saamise konkreetne teekond järgmine: “Global Pooling → Fully Connected kiht → ReLU funktsioon → Fully Connected kiht → Sigmoid funktsioon”.
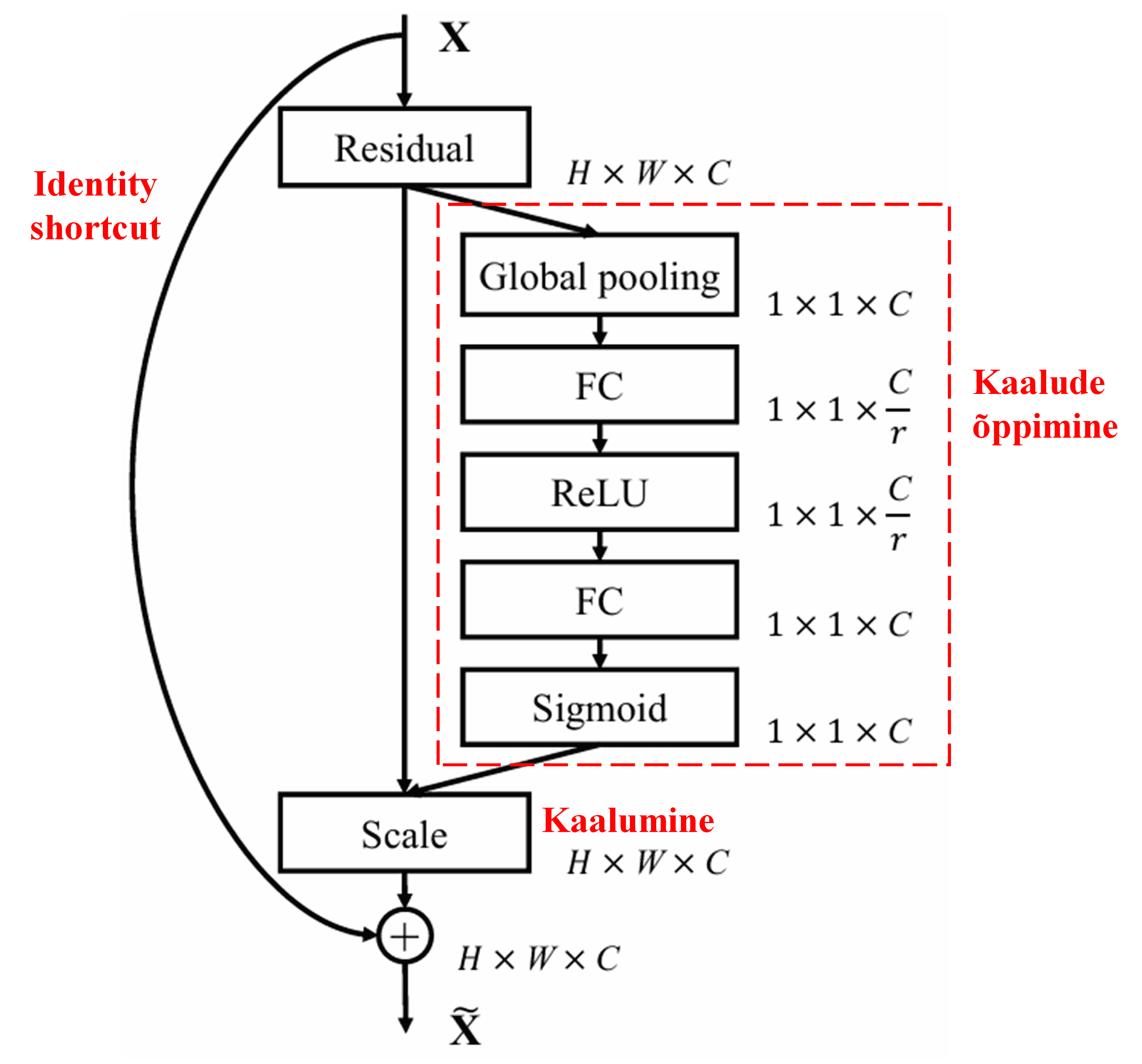
4. Pehme lävendamine sügava tähelepanumehhanismiga
Deep Residual Shrinkage Network on inspireeritud eelnimetatud SENeti alamvõrgu struktuurist, et realiseerida pehmet lävendamist sügava tähelepanumehhanismi abil. Punase kastiga märgitud alamvõrgu kaudu on võimalik õppida hulk lävendeid, et rakendada pehmet lävendamist igale tunnustekanalile.
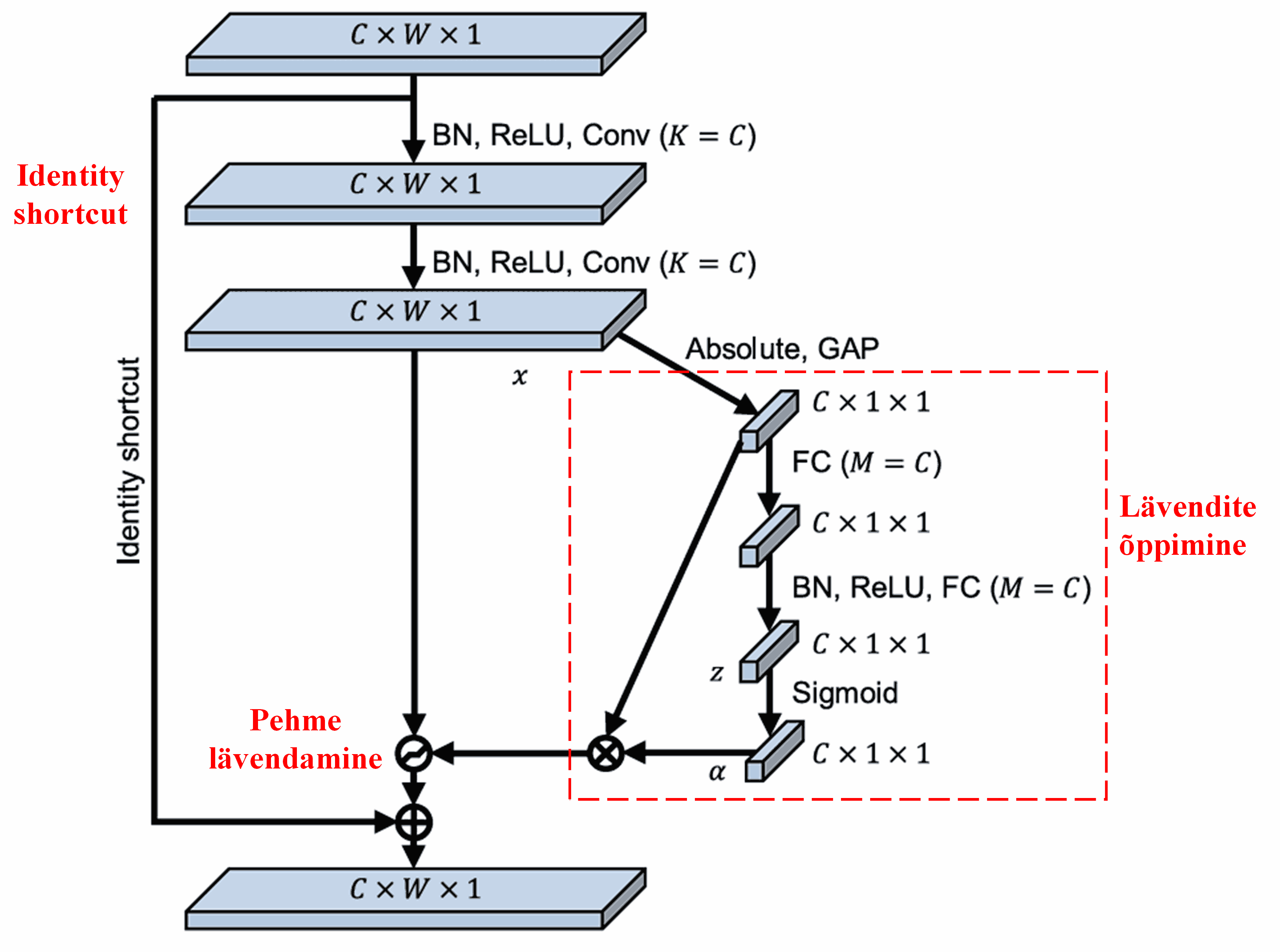
Selles alamvõrgus arvutatakse esmalt kõigi sisendtunnuste absoluutväärtused. Seejärel saadakse Global Average Pooling ja keskmistamise teel tunnus, mida tähistame tähega A. Teises harus sisestatakse Global Average Pooling läbinud tunnustekaart (feature map) väikesesse Fully Connected võrku. Selle võrgu viimaseks kihiks on Sigmoid funktsioon, mis normaliseerib väljundi vahemikku 0 kuni 1, andes koefitsiendi, mida tähistame tähisega α. Lõplikku lävendit saab väljendada kui α × A. Seega on lävend korrutis arvust vahemikus 0–1 ja tunnustekaardi absoluutväärtuste keskmisest. See meetod tagab, et lävend on positiivne ega ole liiga suur.
Lisaks on erinevatel proovidel erinevad lävendid. Seetõttu võib seda teatud määral mõista kui spetsiaalset tähelepanumehhanismi: märgatakse praeguse ülesande jaoks ebaolulisi tunnuseid, muudetakse need kahe konvolutsioonikihi abil nullilähedasteks ja nullitakse pehme lävendamise abil; või vastupidi, märgatakse asjakohaseid tunnuseid, muudetakse need nullist kaugemale ja säilitatakse.
Lõpuks, ladudes üksteise otsa teatud hulga põhimooduleid ning lisades konvolutsioonikihid, Batch Normalization (BN), aktiveerimisfunktsioonid, Global Average Pooling ja Fully Connected väljundkihi, saadaksegi terviklik Deep Residual Shrinkage Network.
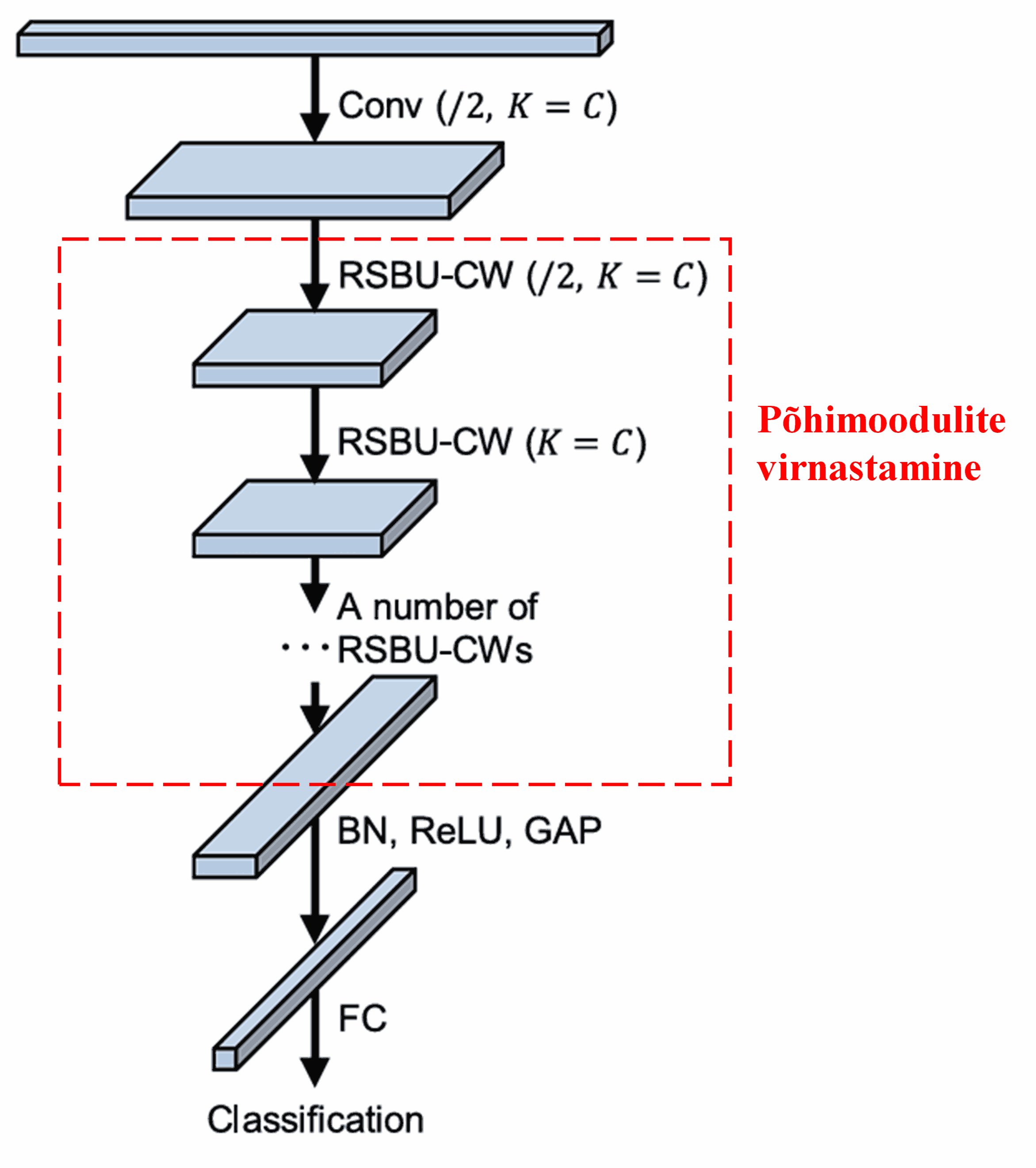
5. Üldistusvõime
Deep Residual Shrinkage Network on tegelikult universaalne tunnuste õppimise (feature learning) meetod. Seda seetõttu, et paljudes tunnuste õppimise ülesannetes sisaldavad andmed vähemal või rohkemal määral müra ja ebaolulist teavet. See müra võib mõjutada õppimise tulemusi. Näiteks:
Piltide klassifitseerimisel: kui pilt sisaldab korraga palju muid objekte, võib neid objekte mõista kui “müra”. Deep Residual Shrinkage Network suudab tähelepanumehhanismi abil seda “müra” märgata ja seejärel pehme lävendamise abil vastavad tunnused nullida, parandades seeläbi klassifitseerimise täpsust.
Kõnetuvastuses: mürarikkas keskkonnas (nt tänaval või tehases vesteldes) võib Deep Residual Shrinkage Network parandada tuvastustäpsust või vähemalt pakkuda lahenduse, kuidas täpsust suurendada.
Kirjandus
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Mõju teadusmaailmas
See artikkel on Google Scholaris kogunud üle 1400 viite.
Mitteametliku statistika kohaselt on Deep Residual Shrinkage Networki kasutatud (kas otse või täiustatud kujul) rohkem kui 1000 teaduspublikatsioonis paljudes valdkondades, sealhulgas masinaehituses, energeetikas, arvutinägemises, meditsiinis, kõnetöötluses, tekstianalüüsis, radarites ja kaugseires.