Deep Residual Shrinkage Networks (DRSN) jsou vylepšenou variantou architektury Deep Residual Network (ResNet). V podstatě jde o integraci ResNetu, mechanismů pozornosti (attention mechanisms) a funkce měkkého prahování (soft thresholding).
Princip fungování sítí DRSN lze do jisté míry chápat takto: pomocí mechanismu pozornosti identifikují nedůležité příznaky (features), které jsou následně vynulovány pomocí funkce měkkého prahování. Naopak důležité příznaky jsou identifikovány a zachovány. Tím se zvyšuje schopnost hluboké neuronové sítě extrahovat užitečné informace i ze signálů, které obsahují silný šum.
1. Motivace výzkumu
Zaprvé, při klasifikaci vzorků se nevyhnutelně setkáváme s určitým množstvím šumu, jako je gaussovský šum, růžový šum nebo Laplaceův šum. Šířeji řečeno, vzorky často obsahují informace, které nesouvisí s aktuální klasifikační úlohou – i ty lze chápat jako šum. Tento šum může mít negativní dopad na výsledky klasifikace. (Měkké prahování je klíčovým krokem v mnoha algoritmech pro odšumění signálu.)
Uveďme příklad: při rozhovoru na kraji rušné silnice se do hlasu mluvčího mísí zvuky klaksonů, kol automobilů a podobně. Pokud bychom tyto zvukové signály zpracovávali pomocí rozpoznávání řeči, výsledky by byly těmito zvuky nevyhnutelně ovlivněny. Z pohledu hlubokého učení (Deep Learning) by měly být příznaky (features) odpovídající klaksonům a kolům uvnitř neuronové sítě odstraněny, aby neovlivňovaly přesnost rozpoznání řeči.
Zadruhé, i v rámci jedné datové sady se množství šumu u jednotlivých vzorků často liší. (To má mnoho společného s mechanismem pozornosti; vezmeme-li jako příklad sadu obrázků, poloha cílového objektu se může na každém snímku lišit a mechanismus pozornosti se dokáže zaměřit na konkrétní umístění objektu v každém jednotlivém obrázku.)
Představme si trénování klasifikátoru pro rozlišení koček a psů. Máme 5 obrázků s označením „pes“. Na 1. obrázku může být pes a myš, na 2. pes a husa, na 3. pes a slepice, na 4. pes a osel a na 5. obrázku pes a kachna. Při trénování klasifikátoru budeme nevyhnutelně rušeni irelevantními objekty (myš, husa, slepice, osel, kachna), což způsobí pokles přesnosti. Pokud bychom dokázali tyto irelevantní objekty detekovat a odstranit příznaky, které jim odpovídají, mohli bychom přesnost klasifikátoru koček a psů výrazně zvýšit.
2. Měkké prahování (Soft Thresholding)
Měkké prahování je klíčovým krokem mnoha algoritmů pro odšumění signálu. Odstraňuje příznaky, jejichž absolutní hodnota je menší než určitý práh (threshold), a příznaky s absolutní hodnotou vyšší než tento práh „smršťuje“ směrem k nule. Lze jej realizovat pomocí následujícího vzorce:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Derivace výstupu měkkého prahování podle vstupu je:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Jak je vidět výše, derivace měkkého prahování je buď 1, nebo 0. Tato vlastnost je shodná s populární aktivační funkcí ReLU. Díky tomu dokáže měkké prahování také snížit riziko, že algoritmy hlubokého učení narazí na problémy mizejícího gradientu (gradient vanishing) nebo explodujícího gradientu (gradient exploding).
V rámci funkce měkkého prahování musí nastavení prahu splňovat dvě podmínky: Zaprvé, práh musí být kladné číslo. Zadruhé, práh nesmí být větší než maximální hodnota vstupního signálu, jinak by byl výstup nulový.
Zároveň je vhodné, aby práh splňoval ještě třetí podmínku: každý vzorek by měl mít svůj vlastní nezávislý práh v závislosti na tom, kolik šumu obsahuje.
Důvodem je, že obsah šumu se u různých vzorků často liší. Například se běžně stává, že ve stejné datové sadě obsahuje vzorek A méně šumu, zatímco vzorek B obsahuje šumu více. Pokud tedy provádíme měkké prahování v rámci odšumovacího algoritmu, měl by se pro vzorek A použít nižší práh a pro vzorek B vyšší práh. Přestože v hlubokých neuronových sítích ztrácejí tyto příznaky a prahy svůj explicitní fyzikální význam, základní logika zůstává stejná. Jinými slovy, každý vzorek by měl mít svůj vlastní práh přizpůsobený vlastní úrovni šumu.
3. Mechanismus pozornosti (Attention Mechanism)
V oblasti počítačového vidění (Computer Vision) je mechanismus pozornosti poměrně snadno pochopitelný. Zrakový systém zvířat dokáže rychle skenovat celou oblast, objevit cílový objekt a následně na něj zaměřit pozornost, aby získal více detailů a zároveň potlačil irelevantní informace. Konkrétní detaily naleznete v odborné literatuře o mechanismech pozornosti.
Squeeze-and-Excitation Network (SENet) je relativně nová metoda hlubokého učení využívající mechanismus pozornosti. U různých vzorků je přínos různých kanálů příznaků (feature channels) pro klasifikační úlohu často odlišný. SENet využívá malou podsíť (sub-network) k získání sady vah, kterými následně násobí příznaky v jednotlivých kanálech, čímž upravuje jejich velikost. Tento proces lze chápat jako aplikaci různé míry pozornosti na jednotlivé kanály příznaků.
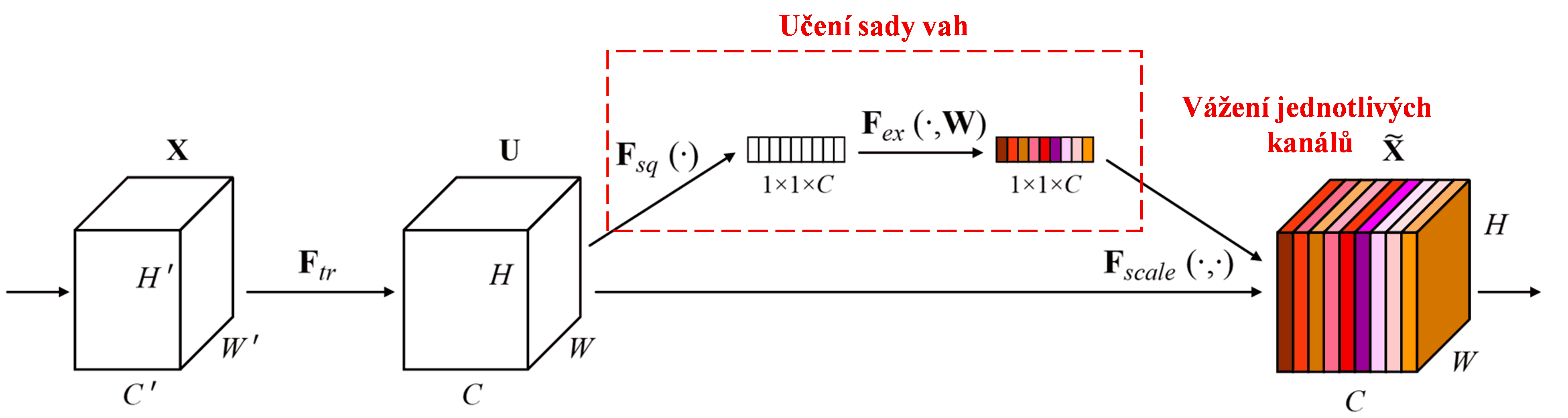
Tímto způsobem má každý vzorek svou vlastní nezávislou sadu vah. Jinými slovy, váhy pro libovolné dva vzorky jsou odlišné. V architektuře SENet je cesta k získání vah následující: „Globální pooling → Plně propojená vrstva (Fully Connected Layer) → ReLU → Plně propojená vrstva → Sigmoid“.
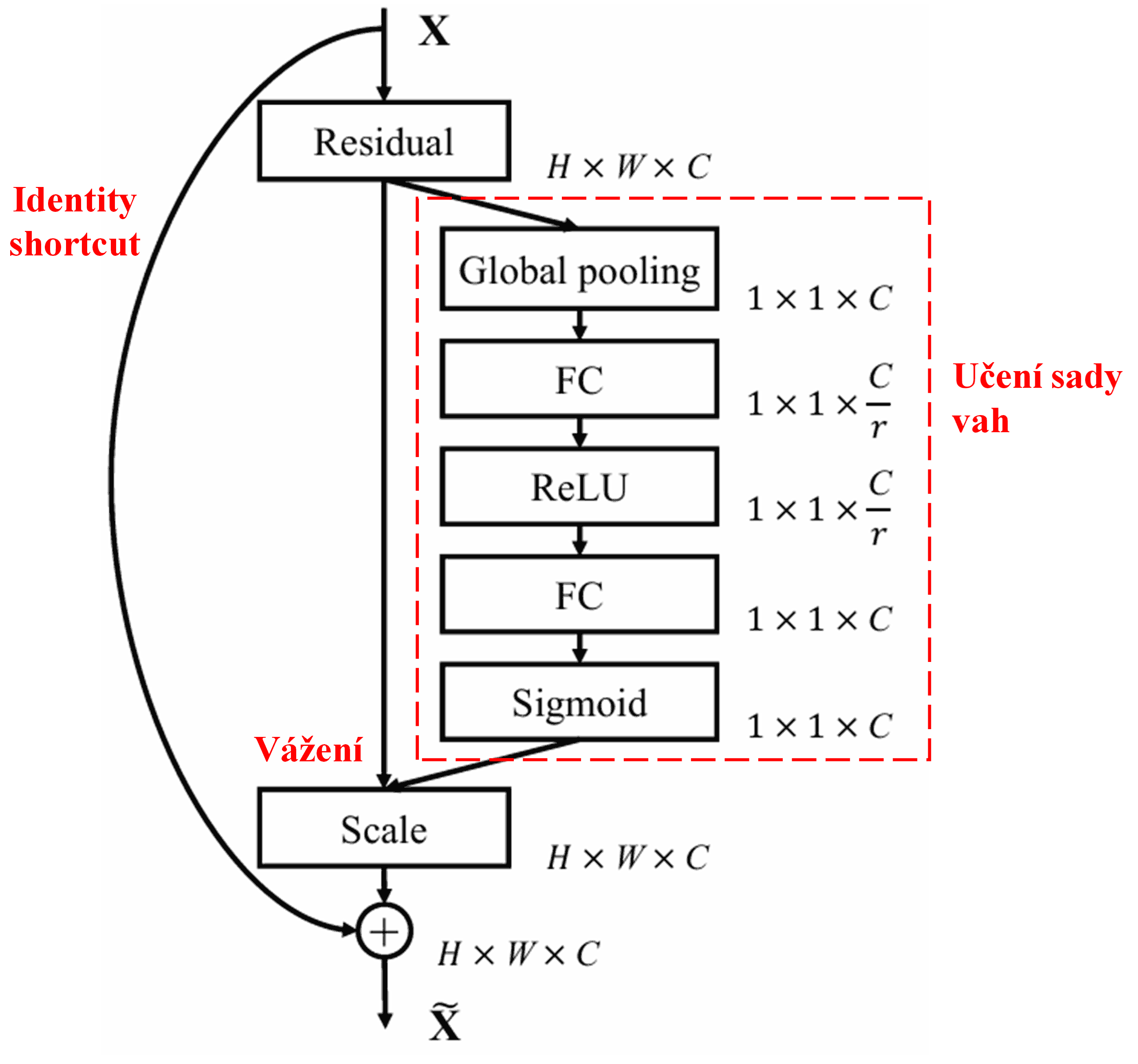
4. Měkké prahování s hlubokým mechanismem pozornosti
Sítě DRSN se inspirují výše uvedenou strukturou podsítě SENetu, aby realizovaly měkké prahování řízené hlubokým mechanismem pozornosti. Prostřednictvím speciální podsítě (v původním diagramu často značené červeně) se síť naučí sadu prahů, kterými provede měkké prahování pro každý kanál příznaků.
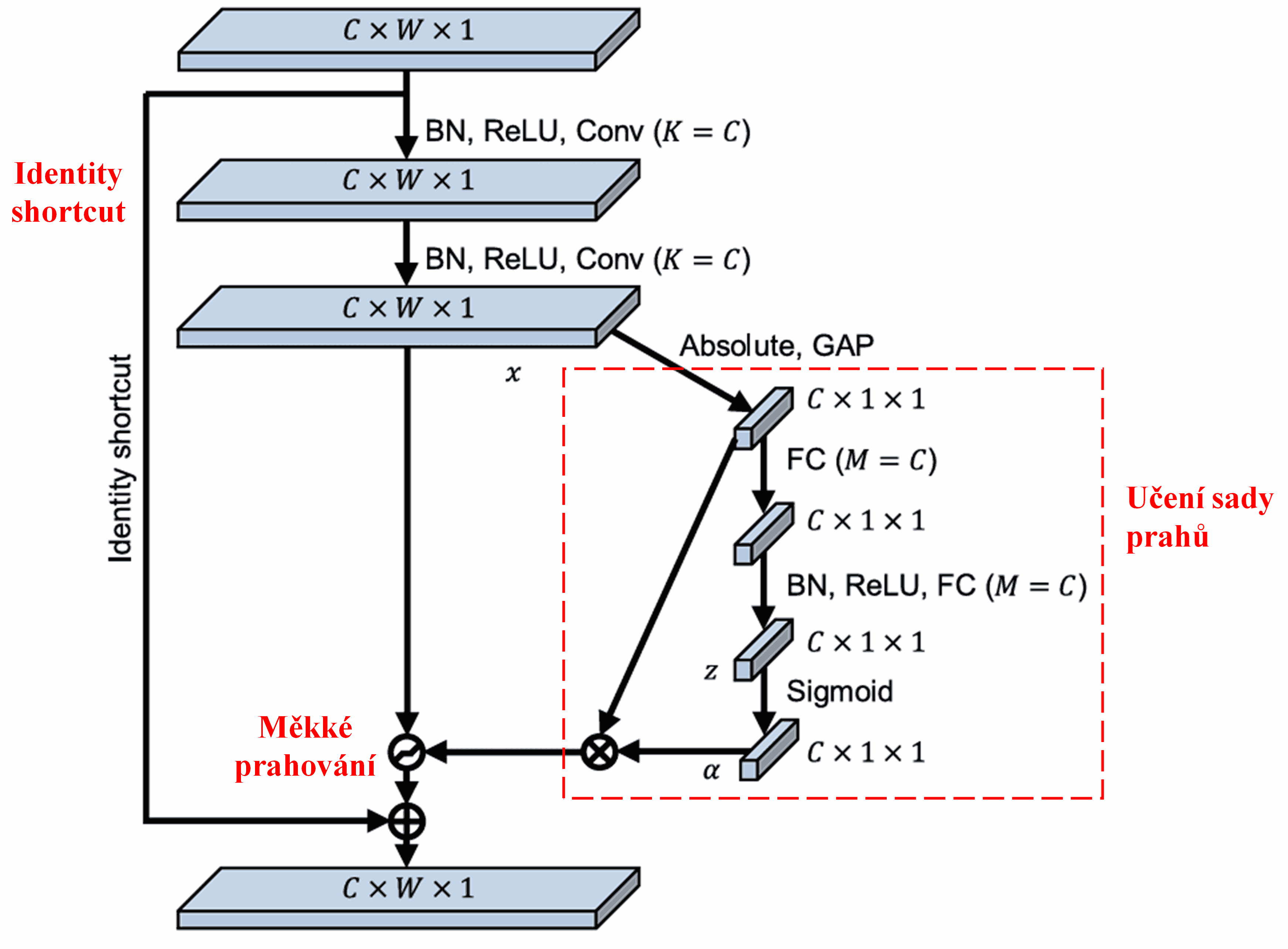
V této podsíti se nejprve vypočítají absolutní hodnoty všech příznaků ve vstupní mapě příznaků (feature map). Poté se provede globální průměrovací pooling (Global Average Pooling) a zprůměrování, čímž získáme jeden příznak, který označíme jako A. V druhé větvi je mapa příznaků po globálním poolingu vložena do malé plně propojené sítě. Tato síť používá jako poslední vrstvu funkci Sigmoid, která normalizuje výstup do rozmezí 0 až 1, čímž získáme koeficient označený jako α. Konečný práh lze vyjádřit jako α × A. Práh je tedy výsledkem násobení čísla mezi 0 a 1 a průměru absolutních hodnot mapy příznaků. Tento způsob zaručuje, že práh je nejen kladný, ale také nebude příliš velký.
Navíc mají různé vzorky různé prahy. Do jisté míry to lze chápat jako speciální mechanismus pozornosti: síť si všimne příznaků, které nesouvisí s aktuální úlohou, pomocí dvou konvolučních vrstev je transformuje na hodnoty blízké nule a následně je pomocí měkkého prahování zcela vynuluje. Nebo naopak: síť si všimne příznaků relevantních pro danou úlohu, transformuje je na hodnoty vzdálené od nuly a zachová je.
Nakonec se poskládáním určitého počtu těchto základních modulů spolu s konvolučními vrstvami, vrstvami Batch normalization (BN), aktivačními funkcemi, globálním průměrovacím poolingem a plně propojenou výstupní vrstvou získá kompletní Deep Residual Shrinkage Network.
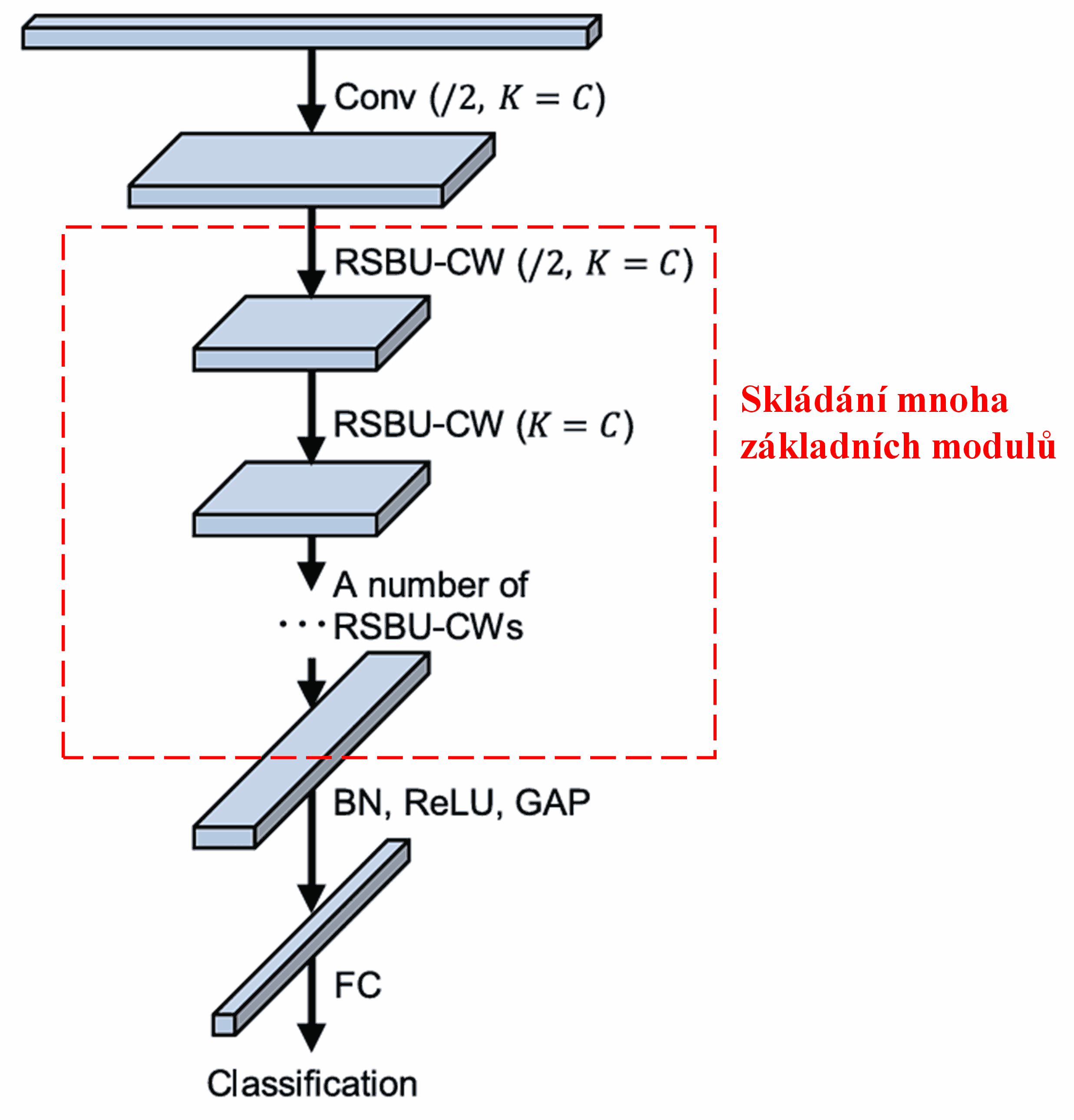
5. Univerzálnost
Deep Residual Shrinkage Network je ve skutečnosti univerzální metodou pro učení příznaků (feature learning). Důvodem je, že v mnoha úlohách učení příznaků obsahují vzorky více či méně šumu a irelevantních informací. Tento šum a nesouvisející informace mohou ovlivnit efektivitu učení. Například:
Při klasifikaci obrázků, pokud obrázek obsahuje mnoho dalších objektů, lze tyto objekty chápat jako „šum“. Sítě DRSN mohou pomocí mechanismu pozornosti tento „šum“ zaznamenat a následně pomocí měkkého prahování vynulovat příznaky, které mu odpovídají. Tím lze potenciálně zvýšit přesnost klasifikace obrazu.
Při rozpoznávání řeči, pokud se nacházíme v hlučném prostředí (například rozhovor u silnice nebo v tovární hale), mohou sítě DRSN zvýšit přesnost rozpoznávání, nebo přinejmenším nabízejí směr, jak přesnost v takových podmínkách zlepšit.
Literatura a odkazy
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Dopad ve vědecké komunitě
Tento článek má na Google Scholar již více než 1400 citací.
Podle neúplných statistik byly sítě Deep Residual Shrinkage Networks (DRSN) přímo aplikovány nebo vylepšeny ve více než 1000 publikacích v mnoha oborech, včetně strojírenství, energetiky, počítačového vidění, lékařství, zpracování řeči, textové analýzy, radarových systémů a dálkového průzkumu Země.