Les Xarxes de Contracció Residual Profunda (en anglès, Deep Residual Shrinkage Networks o DRSN) són una variant millorada de les Xarxes Residuals Profundes (ResNets). Essencialment, són una integració de les ResNets, mecanismes d’atenció i funcions de llindarització suau (soft thresholding).
En certa mesura, el principi de funcionament de les DRSN es pot entendre de la següent manera: utilitza mecanismes d’atenció per identificar les característiques no importants i empra funcions de llindarització suau per posar-les a zero; per contra, identifica les característiques importants i les conserva. Aquest procés millora la capacitat de la xarxa neuronal profunda per extreure característiques útils de senyals que contenen soroll.
1. Motivació de la recerca
En primer lloc, quan classifiquem mostres, la presència de soroll —com ara soroll gaussià, soroll rosa o soroll laplacià— és inevitable. En un sentit més ampli, les mostres sovint contenen informació irrellevant per a la tasca de classificació actual, la qual també es pot interpretar com a soroll. Aquest soroll pot afectar negativament el rendiment de la classificació. (La llindarització suau és un pas clau en molts algoritmes d’eliminació de soroll de senyals).
Per exemple, durant una conversa a la vora de la carretera, l’àudio es pot barrejar amb el so de clàxons i rodes de cotxes. Quan es realitza el reconeixement de la parla sobre aquests senyals, els resultats es veuran inevitablement afectats per aquests sons de fons. Des de la perspectiva de l’aprenentatge profund (Deep Learning), les característiques corresponents als clàxons i les rodes s’haurien d’eliminar dins de la xarxa neuronal per evitar que afectin el reconeixement de la veu.
En segon lloc, fins i tot dins del mateix conjunt de dades, la quantitat de soroll sovint varia d’una mostra a l’altra. (Això comparteix similituds amb els mecanismes d’atenció; prenent com a exemple un conjunt d’imatges, la ubicació de l’objecte objectiu pot diferir entre imatges, i els mecanismes d’atenció poden centrar-se en la ubicació específica de l’objectiu en cada imatge).
Per exemple, quan entrenem un classificador de gats i gossos, considerem 5 imatges etiquetades com a “gos”. La primera imatge pot contenir un gos i un ratolí, la segona un gos i una oca, la tercera un gos i un pollastre, la quarta un gos i un ruc, i la cinquena un gos i un ànec. Durant l’entrenament, el classificador es veurà inevitablement sotmès a la interferència d’objectes irrellevants com ratolins, oques, pollastres, rucs i ànecs, la qual cosa resultarà en una disminució de la precisió de la classificació. Si som capaços de notar aquests objectes irrellevants —els ratolins, oques, pollastres, rucs i ànecs— i eliminar les seves característiques corresponents, és possible millorar la precisió del classificador de gats i gossos.
2. Llindarització suau (Soft Thresholding)
La llindarització suau és un pas central en molts algoritmes d’eliminació de soroll. Elimina les característiques amb valors absoluts inferiors a un cert llindar i contrau cap a zero aquelles amb valors absoluts superiors a aquest llindar. Es pot implementar utilitzant la fórmula següent:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]La derivada de la sortida de la llindarització suau respecte a l’entrada és:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Com es mostra a dalt, la derivada de la llindarització suau és 1 o 0. Aquesta propietat és idèntica a la de la funció d’activació ReLU. Per tant, la llindarització suau també pot reduir el risc que els algoritmes d’aprenentatge profund pateixin problemes de desaparició o explosió del gradient (gradient vanishing/exploding).
En la funció de llindarització suau, la configuració del llindar ha de complir dues condicions: primera, el llindar ha de ser un nombre positiu; segona, el llindar no pot superar el valor màxim del senyal d’entrada, altrament la sortida seria totalment zero.
A més, és preferible que el llindar compleixi una tercera condició: cada mostra hauria de tenir el seu propi llindar independent basat en el seu contingut de soroll.
Això es deu al fet que el contingut de soroll sovint varia entre mostres. Per exemple, és habitual dins del mateix conjunt de dades que la Mostra A contingui menys soroll mentre que la Mostra B en contingui més. En aquest cas, quan es realitza la llindarització suau en un algoritme de reducció de soroll, la Mostra A hauria d’utilitzar un llindar més petit, mentre que la Mostra B hauria d’utilitzar un llindar més gran. Tot i que aquestes característiques i llindars perden les seves definicions físiques explícites en les xarxes neuronals profundes, la lògica subjacent bàsica continua sent la mateixa. En altres paraules, cada mostra hauria de tenir el seu propi llindar independent determinat pel seu contingut específic de soroll.
3. Mecanisme d’atenció
Els mecanismes d’atenció són relativament fàcils d’entendre en el camp de la visió per computador. Els sistemes visuals dels animals poden distingir objectius escanejant ràpidament tota l’àrea, centrant posteriorment l’atenció en l’objecte objectiu per extreure’n més detalls mentre suprimeixen la informació irrellevant. Per a més detalls, consulteu la literatura sobre mecanismes d’atenció.
La Squeeze-and-Excitation Network (SENet) representa un mètode d’aprenentatge profund relativament nou que utilitza mecanismes d’atenció. En diferents mostres, la contribució dels diferents canals de característiques a la tasca de classificació sovint varia. La SENet empra una petita subxarxa per obtenir un conjunt de pesos i, a continuació, multiplica aquests pesos per les característiques dels canals respectius per ajustar la magnitud de les característiques en cada canal. Aquest procés es pot considerar com l’aplicació de diferents nivells d’atenció a diferents canals de característiques.
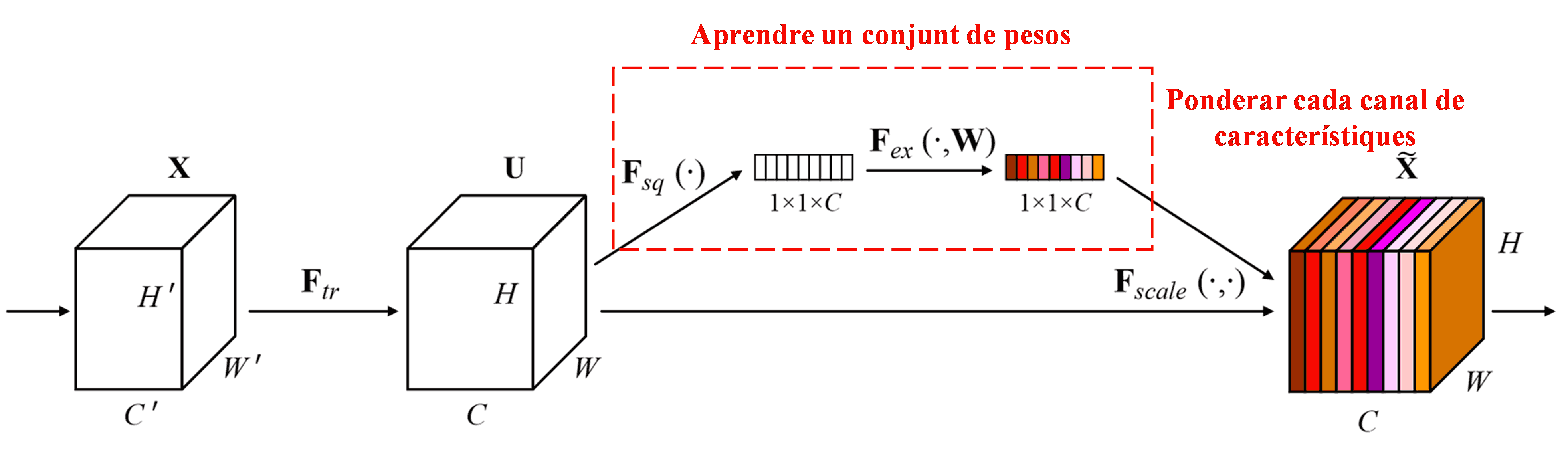
En aquest enfocament, cada mostra posseeix el seu propi conjunt independent de pesos. En altres paraules, els pesos per a dues mostres arbitràries qualsevol són diferents. En la SENet, el camí específic per obtenir pesos és “Global Pooling → Capa totalment connectada (FC) → Funció ReLU → Capa totalment connectada (FC) → Funció Sigmoide”.
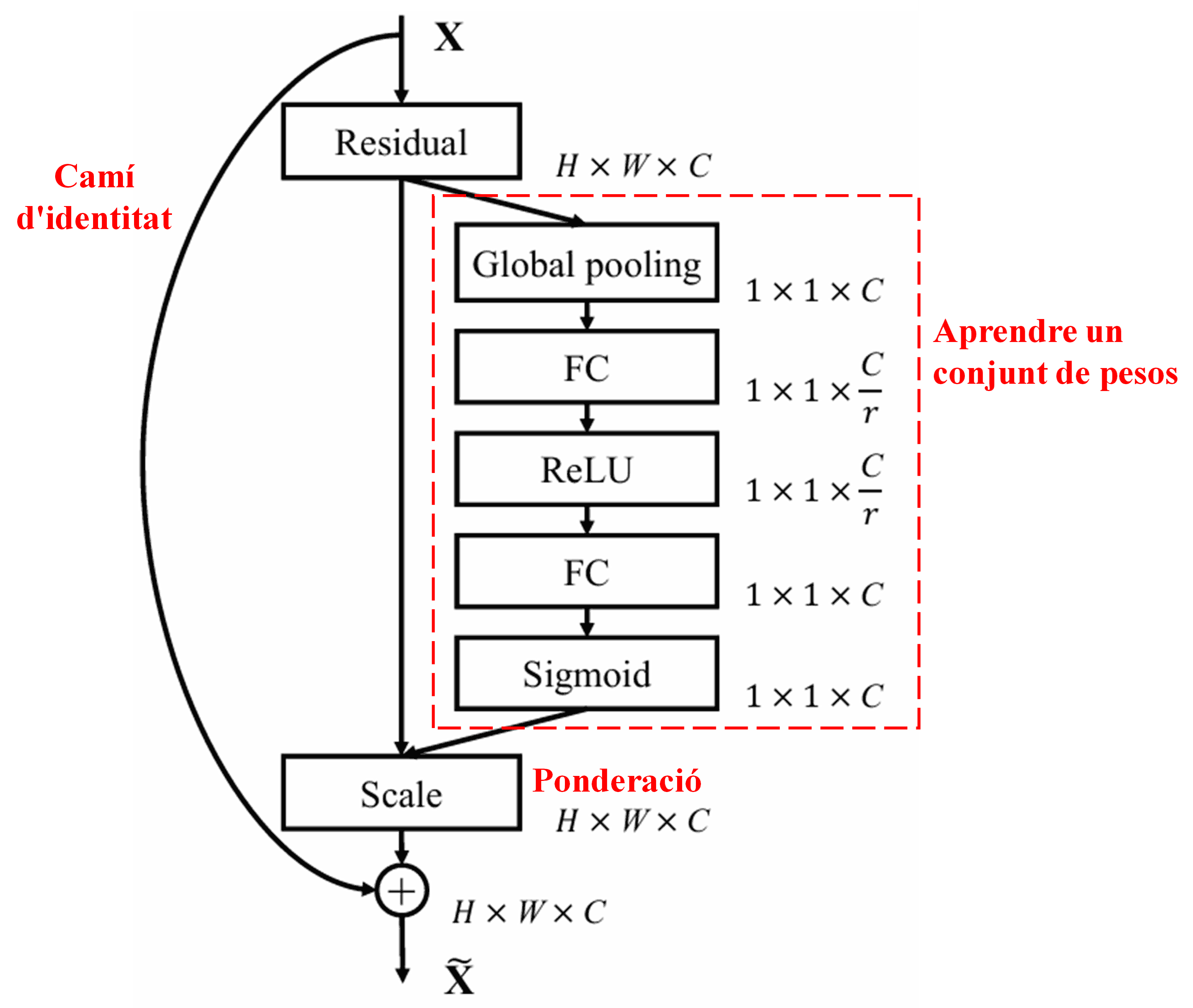
4. Llindarització suau sota un Mecanisme d’Atenció Profunda
La Xarxa de Contracció Residual Profunda (DRSN) s’inspira en l’estructura de la subxarxa SENet esmentada anteriorment per implementar la llindarització suau sota un mecanisme d’atenció profunda. A través de la subxarxa (indicada dins del requadre vermell en els diagrames), es pot aprendre un conjunt de llindars per aplicar la llindarització suau a cada canal de característiques.
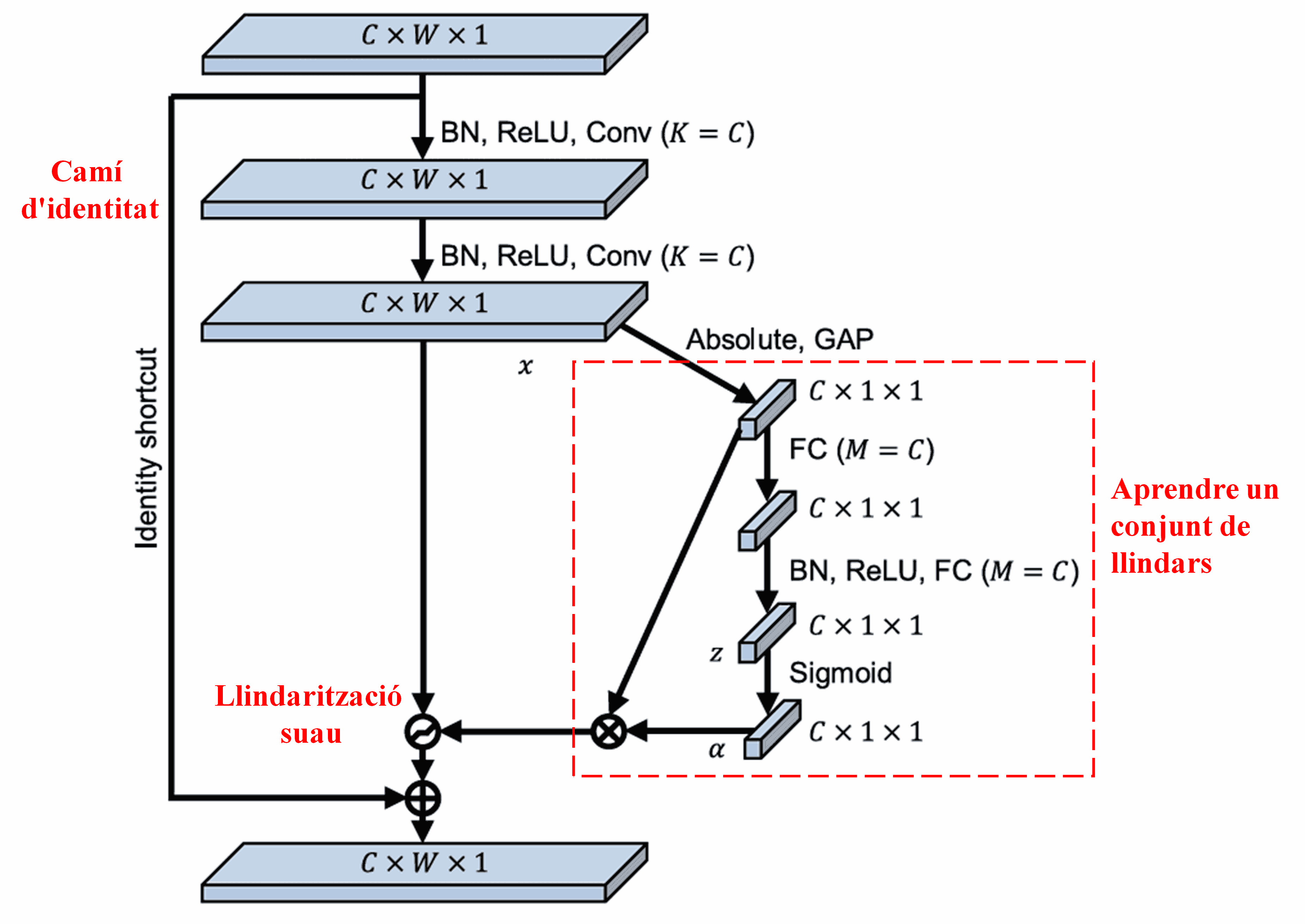
En aquesta subxarxa, primer es calculen els valors absoluts de totes les característiques del mapa de característiques d’entrada. Després, mitjançant el Global Average Pooling i el càlcul de la mitjana, s’obté una característica, denotada com a A. En l’altre camí, el mapa de característiques després del Global Average Pooling s’introdueix en una petita xarxa totalment connectada. Aquesta xarxa utilitza la funció Sigmoide com a última capa per normalitzar la sortida entre 0 i 1, obtenint un coeficient denotat com a α. El llindar final es pot expressar com a α × A. Per tant, el llindar és el producte d’un nombre entre 0 i 1 i la mitjana dels valors absoluts del mapa de característiques. Aquest mètode garanteix que el llindar no només sigui positiu, sinó que tampoc sigui excessivament gran.
A més, diferents mostres resulten en diferents llindars. En conseqüència, en certa mesura, això es pot interpretar com un mecanisme d’atenció especialitzat: identifica les característiques irrellevants per a la tasca actual, les transforma en valors propers a zero mitjançant dues capes convolucionals i les posa a zero utilitzant la llindarització suau; alternativament, identifica les característiques rellevants per a la tasca actual, les transforma en valors allunyats de zero mitjançant dues capes convolucionals i les conserva.
Finalment, apilant un cert nombre de mòduls bàsics juntament amb capes convolucionals, Batch Normalization (BN), funcions d’activació, Global Average Pooling i capes de sortida totalment connectades, es construeix la DRSN completa.
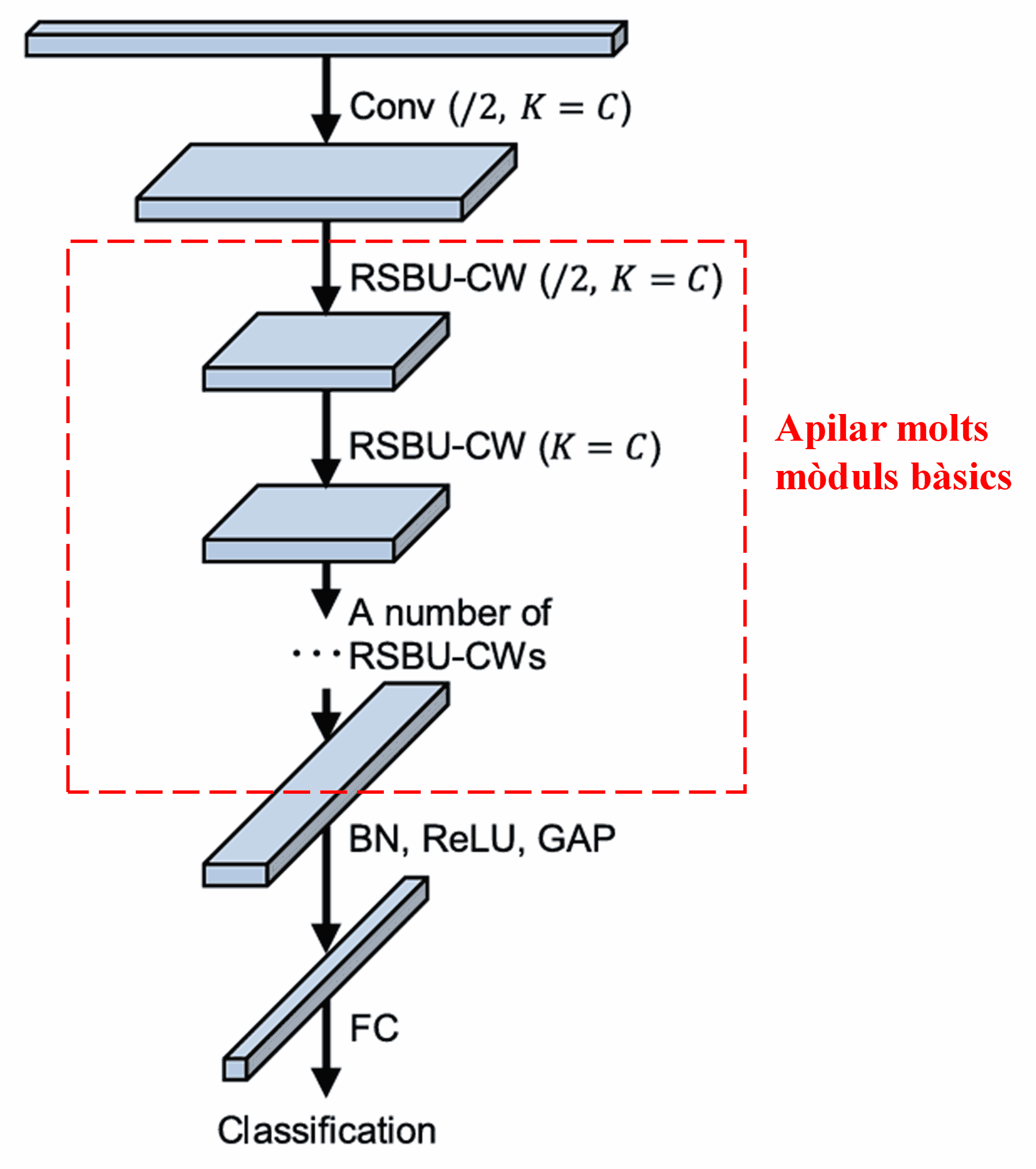
5. Aplicabilitat general
La DRSN és, de fet, un mètode general d’aprenentatge de característiques. Això és perquè, en moltes tasques d’aprenentatge, les mostres contenen més o menys soroll, així com informació irrellevant. Aquest soroll i informació irrellevant poden afectar el rendiment de l’aprenentatge de característiques. Per exemple:
En la classificació d’imatges, si una imatge conté simultàniament molts altres objectes, aquests objectes es poden entendre com a “soroll”. La DRSN pot ser capaç d’utilitzar el mecanisme d’atenció per notar aquest “soroll” i després emprar la llindarització suau per posar a zero les característiques corresponents a aquest “soroll”, millorant així potencialment la precisió de la classificació d’imatges.
En el reconeixement de la veu, específicament en entorns relativament sorollosos com ara converses a la vora de la carretera o dins d’un taller de fàbrica, la DRSN pot millorar la precisió del reconeixement de la veu o, com a mínim, oferir una metodologia capaç de millorar-ne la precisió.
Bibliografia i Referències
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Impacte acadèmic
Aquest article ha rebut més de 1400 cites a Google Scholar.
Segons estimacions conservadores, les Xarxes de Contracció Residual Profunda (DRSN) s’han utilitzat en més de 1000 publicacions. Aquests treballs han aplicat directament o han millorat la xarxa en una àmplia gamma de camps, incloent-hi l’enginyeria mecànica, l’energia elèctrica, la visió per computador, l’assistència sanitària, el processament de la veu, l’anàlisi de text, el radar i la teledetecció.