Deep Residual Shrinkage Network (DRSN) е подобрена версия на Deep Residual Network (ResNet). По същество, тя представлява интеграция между ResNet, механизми за внимание (attention mechanisms) и функции за меко прагуване (soft thresholding).
В известна степен, принципът на действие на Deep Residual Shrinkage Network може да се разбере по следния начин: чрез механизмите за внимание се идентифицират незначителните характеристики (features), които след това се нулират чрез функцията за меко прагуване; или казано обратното – забелязват се важните характеристики и се запазват. Този процес засилва способността на дълбоката невронна мрежа да извлича полезна информация от зашумени сигнали.
1. Мотивация за изследването
Първо, при класификацията на образци, наличието на шум – като Гаусов шум, розов шум и Лапласов шум – е неизбежно. В по-широк смисъл, образците често съдържат информация, която е ирелевантна за текущата задача за класификация, което също може да се тълкува като шум. Този шум може да окаже негативно влияние върху ефективността на класификацията. (Мекото прагуване е ключова стъпка в много алгоритми за изчистване на сигнали).
Да вземем за пример разговор на улицата: аудио сигналът от разговора може да бъде смесен със звуци от клаксони, автомобилни гуми и други. Когато се извършва автоматично разпознаване на реч (speech recognition) върху тези сигнали, резултатите неизбежно ще бъдат повлияни от фоновите звуци. От гледна точка на дълбокото обучение (Deep Learning), характеристиките, съответстващи на клаксоните и шума от гумите, трябва да бъдат премахнати вътре в дълбоката невронна мрежа, за да се предотврати влиянието им върху разпознаването на речта.
Второ, дори в един и същи набор от данни (dataset), количеството шум често варира при отделните образци. (Това има допирни точки с механизмите за внимание; ако вземем за пример набор от изображения, позицията на целевия обект може да е различна във всяка снимка, и attention механизмът може да се фокусира върху конкретната локация на обекта).
Например, при обучение на класификатор за „куче/котка“, нека разгледаме 5 изображения с етикет „куче“. Първото изображение може да съдържа куче и мишка, второто – куче и гъска, третото – куче и кокошка, четвъртото – куче и магаре, а петото – куче и патица. По време на обучението, класификаторът неизбежно ще бъде подложен на смущения от ирелевантни обекти като мишки, гъски, кокошки, магарета и патици, което води до спад в точността. Ако успеем да „забележим“ тези ирелевантни обекти и да премахнем съответстващите им характеристики, е напълно възможно да повишим точността на класификатора.
2. Меко прагуване (Soft Thresholding)
Мекото прагуване е основна стъпка в много алгоритми за премахване на шум от сигнали. То премахва характеристиките, чиято абсолютна стойност е по-малка от определен праг, и „свива“ (shrinks) към нулата тези, чиято абсолютна стойност е по-голяма от този праг. Това може да се реализира чрез следната формула:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Производната на изхода спрямо входа при мекото прагуване е:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Както се вижда по-горе, производната на мекото прагуване е или 1, или 0. Това свойство е идентично с това на активационната функция ReLU. Следователно, мекото прагуване също помага да се намали рискът алгоритмите за дълбоко обучение да се сблъскат с проблема на „изчезващите“ (vanishing) или „експлодиращите“ (exploding) градиенти.
При функцията за меко прагуване, задаването на прага трябва да отговаря на две условия: Първо, прагът трябва да е положително число; Второ, прагът не може да надвишава максималната стойност на входния сигнал, в противен случай изходът ще бъде изцяло нула.
Също така, е силно препоръчително прагът да отговаря и на трето условие: всеки образец трябва да има свой собствен, независим праг, съобразен със собственото му съдържание на шум.
Това се налага, защото количеството шум често е различно при различните образци. Например, често се случва в един dataset образец А да съдържа по-малко шум, а образец Б – повече. В такъв случай, ако прилагаме меко прагуване, образец А трябва да използва по-малък праг, докато образец Б трябва да използва по-голям праг. В дълбоките невронни мрежи, въпреки че тези характеристики и прагове губят своите ясни физически дефиниции, основната логика остава същата. С други думи, всеки образец се нуждае от адаптивен праг, определен от конкретното му ниво на шум.
3. Механизъм за внимание (Attention Mechanism)
Механизмите за внимание са сравнително лесни за разбиране в сферата на компютърното зрение (Computer Vision). Зрителната система на животните може бързо да сканира цялата зона, за да открие целевия обект, и след това да концентрира вниманието си върху него, за да извлече повече детайли, като същевременно потиска ирелевантната информация. За повече детайли, моля, консултирайте се с литературата относно attention механизмите.
Squeeze-and-Excitation Network (SENet) е сравнително нов метод в дълбокото обучение, използващ такъв механизъм. При различните образци, приносът на различните канали на характеристиките (feature channels) към задачата за класификация често е различен. SENet използва малка под-мрежа (sub-network), за да получи набор от тегла (weights), и след това умножава тези тегла по характеристиките на съответните канали, за да регулира тяхната големина. Този процес може да се разглежда като прилагане на различни нива на „внимание“ към различните канали.
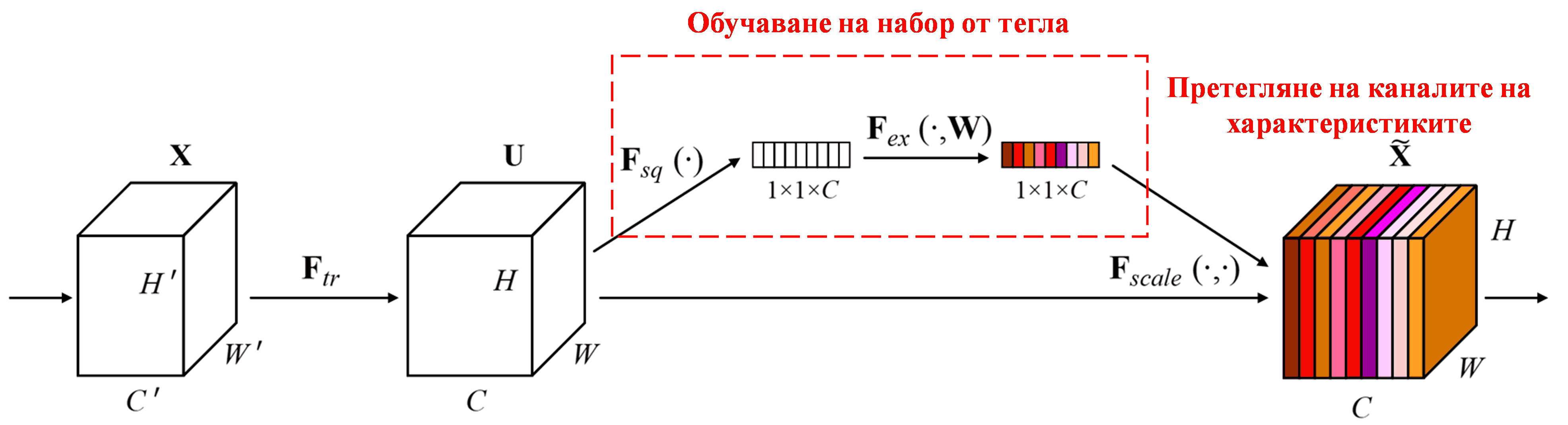
При този подход, всеки образец притежава свой собствен, независим набор от тегла. С други думи, теглата за които и да е два произволни образеца са различни. В SENet, конкретният път за получаване на теглата е: „Global Pooling → Fully Connected Layer → ReLU функция → Fully Connected Layer → Sigmoid функция“.
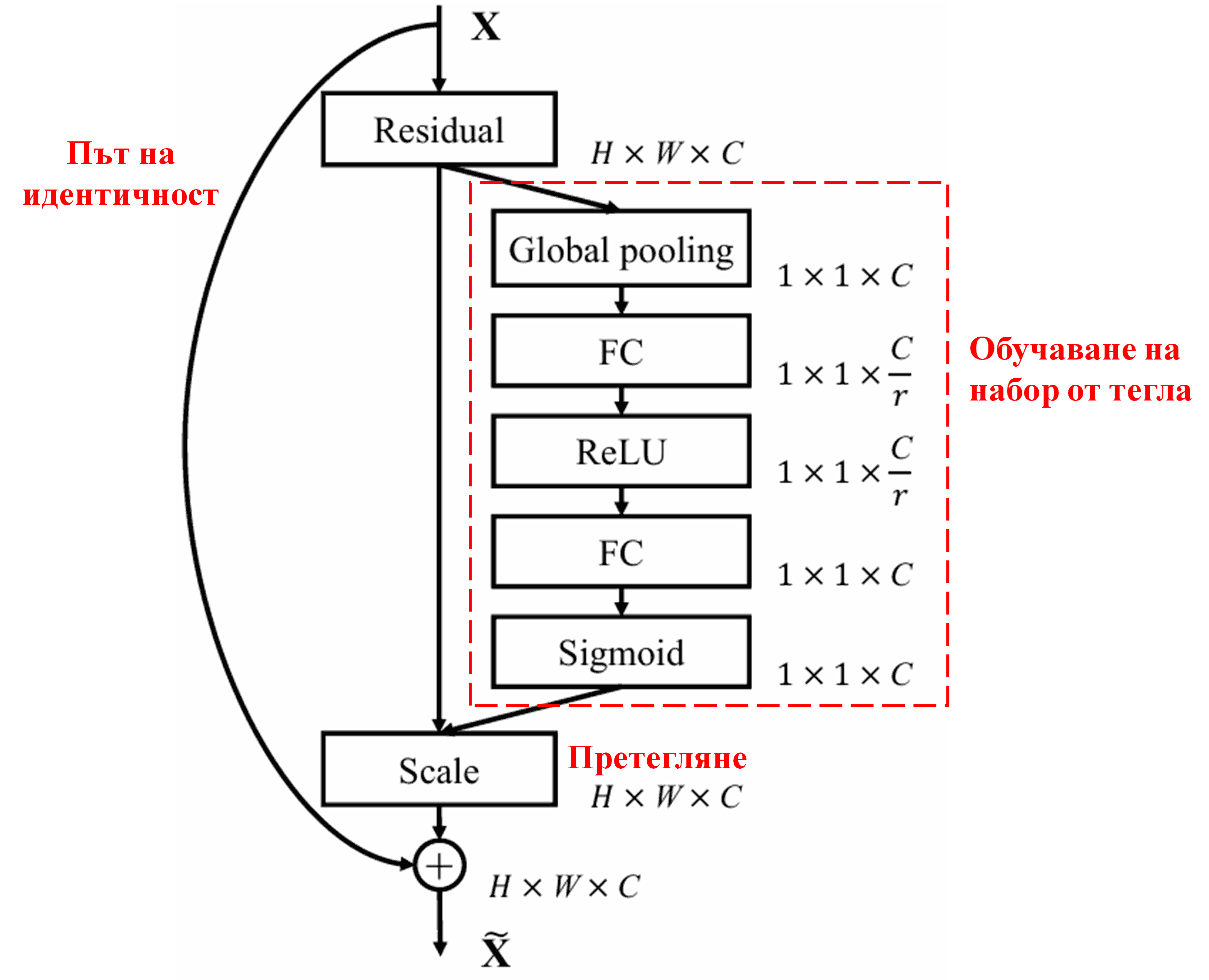
4. Меко прагуване в условията на дълбоки механизми за внимание
Deep Residual Shrinkage Network черпи вдъхновение от структурата на под-мрежата на SENet, за да реализира меко прагуване, управлявано от attention механизъм. Чрез под-мрежата (обозначена в червената кутия на архитектурните диаграми) може да се обучи набор от прагове, които да се приложат към всеки канал на характеристиките.
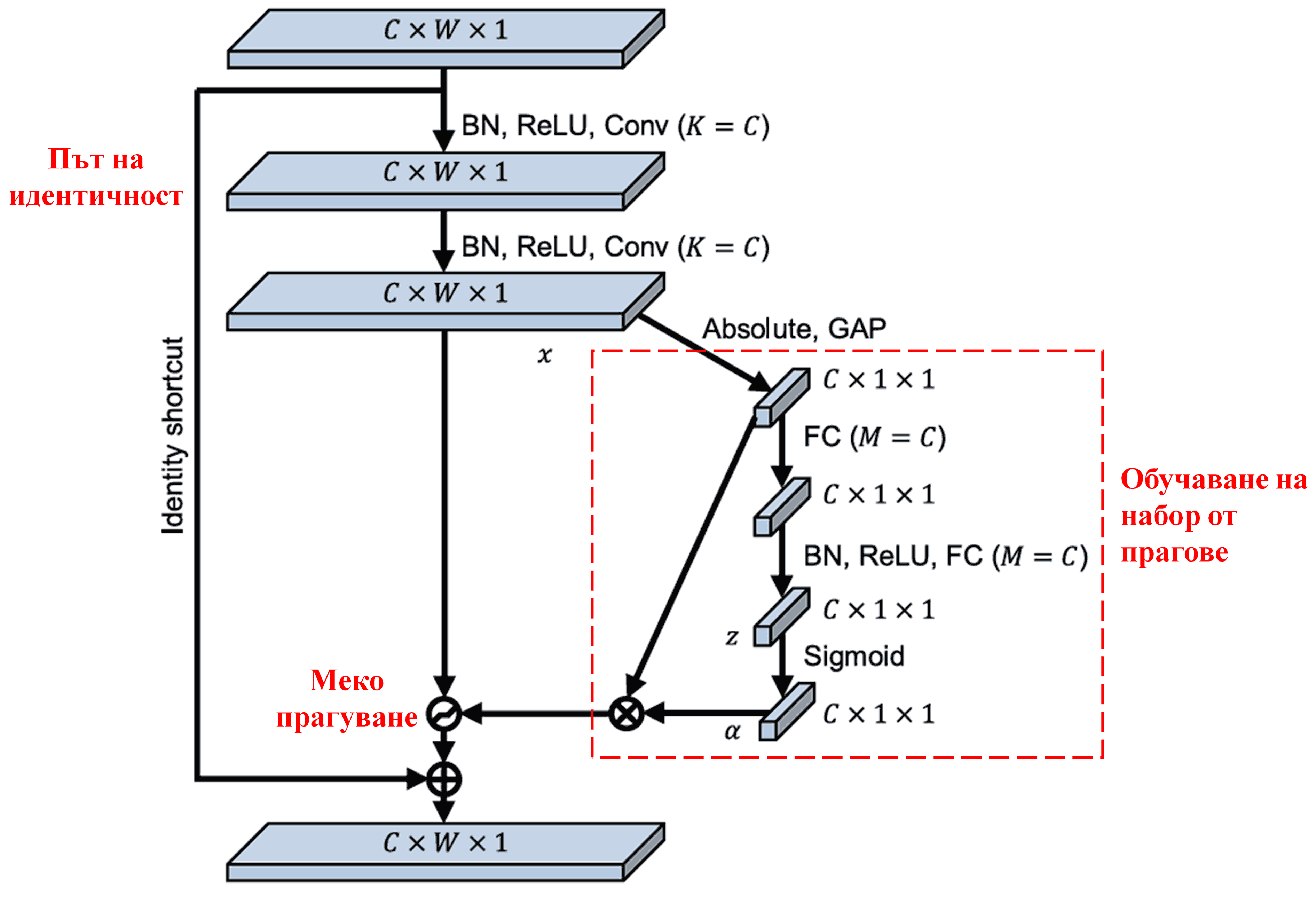
В тази под-мрежа, първо се изчисляват абсолютните стойности на всички характеристики във входната карта (feature map). След това, чрез глобално осредняващо обединяване (Global Average Pooling) и осредняване, се получава една характеристика, обозначена като A. В другия път на мрежата, feature map-ът след глобалното обединяване се подава към малка напълно свързана мрежа (FC network). Тази FC мрежа използва Sigmoid функция като последен слой, за да нормализира изхода в диапазона между 0 и 1, получавайки коефициент, обозначен като α. Крайният праг може да се изрази като α×A. Следователно, прагът представлява произведението на число между 0 и 1 и средната стойност на абсолютните стойности на картата на характеристиките. Този метод гарантира, че прагът е не само положителен, но и не е прекалено голям.
Освен това, различните образци получават различни прагове. Следователно, в известна степен, това може да се тълкува като специализиран механизъм за внимание: забелязват се характеристиките, които са ирелевантни за текущата задача, трансформират се в стойности близки до нулата чрез два конволюционни слоя (convolutional layers), и се нулират напълно чрез меко прагуване; или алтернативно – забелязват се важните за задачата характеристики и се запазват.
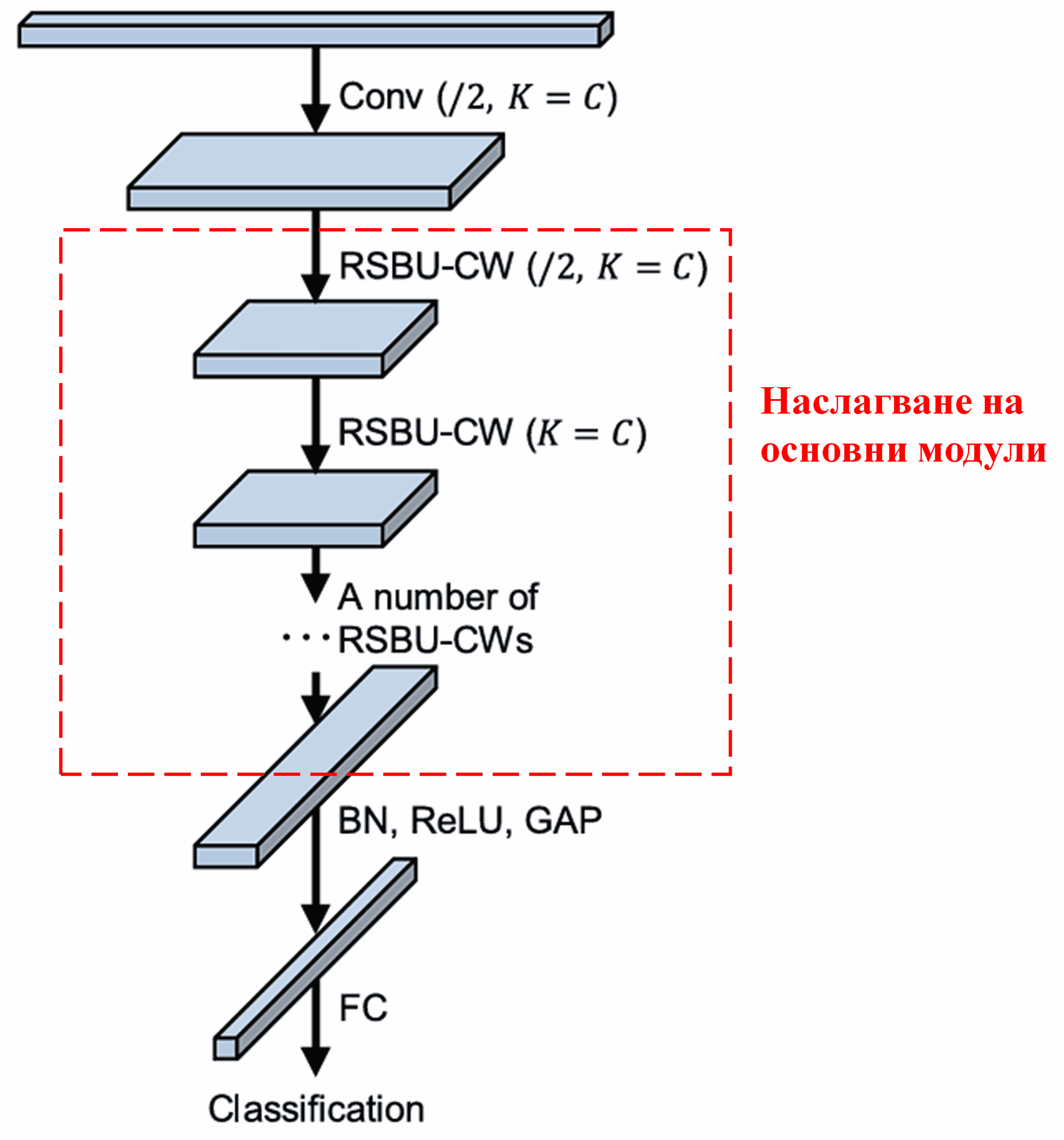
Накрая, чрез наслагване на определен брой такива базови модули заедно с конволюционни слоеве, Batch Normalization, активационни функции, Global Average Pooling и напълно свързани изходни слоеве, се изгражда пълната архитектура на Deep Residual Shrinkage Network.
5. Универсалност
Deep Residual Shrinkage Network всъщност е универсален метод за обучение на характеристики (feature learning). Това е така, защото в много задачи за машинно обучение, образците съдържат повече или по-малко шум, както и ирелевантна информация. Този шум и излишна информация могат да повлияят негативно на резултатите. Например:
При класификация на изображения, ако снимката съдържа множество други обекти, тези обекти могат да се възприемат като „шум“. DRSN може да използва механизма за внимание, за да забележи този „шум“, и след това да използва меко прагуване, за да нулира характеристиките, съответстващи на шума, като по този начин потенциално повишава точността на класификацията.
При разпознаване на реч, особено в шумна среда (като разговори край пътя или във фабрично хале), Deep Residual Shrinkage Network може да подобри точността на разпознаване или най-малкото да предложи методология, способна да постигне това подобрение.
Литература
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Академично влияние
Тази статия има над 1400 цитирания в Google Scholar.
Според непълни статистически данни, Deep Residual Shrinkage Networks (DRSN) са използвани в над 1000 публикации. Тези трудове директно прилагат или подобряват мрежата в широк спектър от области, включително машинно инженерство, електроенергетика, компютърно зрение, медицина, обработка на реч и текст, радарни технологии и дистанционно наблюдение (remote sensing).