Deep Residual Shrinkage Network (DRSN, або Глыбокая рэшткавая сетка са сцісканнем) — гэта палепшаная версія Deep Residual Network (ResNet). Па сутнасці, гэта інтэграцыя ResNet, механізмаў увагі (attention mechanisms) і функцый мяккага парога (soft thresholding).
У пэўнай ступені прынцып працы Deep Residual Shrinkage Network можна зразумець наступным чынам: з дапамогай механізма ўвагі выяўляюцца нязначныя прыкметы, якія затым абнуляюцца праз функцыю мяккага парога; і наадварот, важныя прыкметы захоўваюцца. Гэта паляпшае здольнасць глыбокай нейроннай сеткі выдзяляць карысныя прыкметы з сігналаў, якія змяшчаюць шум.
1. Матывацыя даследавання
Па-першае, пры класіфікацыі ўзораў (сэмплаў) наяўнасць шуму — напрыклад, гаусавага, ружовага або лапласавага — з’яўляецца непазбежнай. Больш шырока кажучы, узоры часта змяшчаюць інфармацыю, якая не мае дачынення да бягучай задачы класіфікацыі, і яе таксама можна разглядаць як шум. Гэты шум можа негатыўна ўплываць на вынікі класіфікацыі. (Варта адзначыць, што soft thresholding з’яўляецца ключавым этапам у многіх алгарытмах шумападаўлення).
Напрыклад, падчас размовы на вуліцы голас можа змешвацца з гукамі аўтамабільных сігналаў і шоргатам шын. Калі выконваць распазнаванне маўлення на такіх сігналах, вынік непазбежна пацерпіць ад гэтых фонавых гукаў. З пункту гледжання глыбокага навучання (Deep Learning), прыкметы (features), якія адпавядаюць сігналам машын і колаў, павінны быць выдалены ўнутры глыбокай нейроннай сеткі, каб пазбегнуць іх уплыву на распазнаванне маўлення.
Па-другое, нават у адным і тым жа наборы даных колькасць шуму ў розных узорах часта адрозніваецца. (Гэта пераклікаецца з механізмамі ўвагі; калі ўзяць набор малюнкаў, то мэтавы аб’ект можа знаходзіцца ў розных месцах на розных малюнках, і механізм увагі дазваляе сфакусавацца менавіта на гэтых месцах).
Напрыклад, пры навучанні класіфікатара «кот/сабака» возьмем 5 малюнкаў з пазнакай «сабака». Першы малюнак можа змяшчаць сабаку і мыш, другі — сабаку і гусака, трэці — сабаку і курыцу, чацвёрты — сабаку і асла, а пяты — сабаку і качку. Падчас навучання мы непазбежна сутыкнемся з перашкодамі ад старонніх аб’ектаў (мышэй, гусей, курэй, аслоў і качак), што прывядзе да зніжэння дакладнасці класіфікацыі. Калі мы зможам выявіць гэтыя староннія аб’екты і выдаліць адпаведныя ім прыкметы, гэта дапаможа павысіць дакладнасць класіфікатара катоў і сабак.
2. Soft Thresholding (Мяккая парогавая апрацоўка)
Soft thresholding — гэта ключавы этап многіх алгарытмаў шумападаўлення сігналаў. Ён выдаляе прыкметы, абсалютнае значэнне якіх меншае за пэўны парог (threshold), і «сціскае» ў кірунку нуля тыя прыкметы, абсалютнае значэнне якіх перавышае гэты парог. Гэта можна рэалізаваць з дапамогай наступнай формулы:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Вытворная выхаду soft thresholding па ўваходзе роўная:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Як бачна вышэй, вытворная функцыі мяккага парога роўная альбо 1, альбо 0. Гэтая ўласцівасць ідэнтычная функцыі актывацыі ReLU. Таму soft thresholding таксама здольны знізіць рызыку таго, што алгарытм глыбокага навучання сутыкнецца з праблемамі знікнення градыента (gradient vanishing) або выбуху градыента (gradient exploding).
У функцыі мяккага парога наладка парога (threshold) павінна адпавядаць дзвюм умовам: па-першае, парог павінен быць дадатным лікам; па-другое, ён не павінен перавышаць максімальнае значэнне ўваходнага сігналу, інакш усе выхадныя значэнні будуць роўныя нулю.
Акрамя таго, пажадана выкананне трэцяй умовы: кожны ўзор павінен мець свой уласны незалежны парог у залежнасці ад уласнага ўзроўню шуму.
Гэта тлумачыцца тым, што змест шуму часта адрозніваецца ў розных узорах. Напрыклад, у адным наборы даных узор A можа ўтрымліваць мала шуму, а узор B — шмат. У такім выпадку пры выкананні soft thresholding у алгарытме шумападаўлення для ўзора A варта выкарыстоўваць меншы парог, а для ўзора B — большы. У глыбокіх нейронных сетках, хоць гэтыя прыкметы і парогі губляюць свой відавочны фізічны сэнс, базавая логіка застаецца ранейшай. Іншымі словамі, кожны ўзор павінен мець свой незалежны парог, які вызначаецца яго асабістым узроўнем шуму.
3. Механізм увагі (Attention Mechanism)
Механізмы ўвагі даволі лёгка зразумець у галіне камп’ютарнага зроку (Computer Vision). Глядзельная сістэма жывёл можа хутка сканаваць усю вобласць, выяўляць мэтавы аб’ект і канцэнтраваць увагу менавіта на ім, каб выдзяляць больш дэталяў і адначасова падыўляць нерэлевантную інфармацыю. Падрабязней пра гэта глядзіце ў артыкулах пра механізмы ўвагі.
Squeeze-and-Excitation Network (SENet) — гэта адносна новы метад глыбокага навучання, які выкарыстоўвае механізмы ўвагі. У розных узорах уклад розных каналаў прыкмет (feature channels) у задачу класіфікацыі часта адрозніваецца. SENet выкарыстоўвае невялікую падсетку (sub-network) для атрымання набору вагаў, а затым памнажае гэтыя вагі на прыкметы адпаведных каналаў, каб скарэктаваць велічыню прыкмет кожнага канала. Гэты працэс можна разглядаць як прымяненне рознага ўзроўню ўвагі да розных каналаў прыкмет.
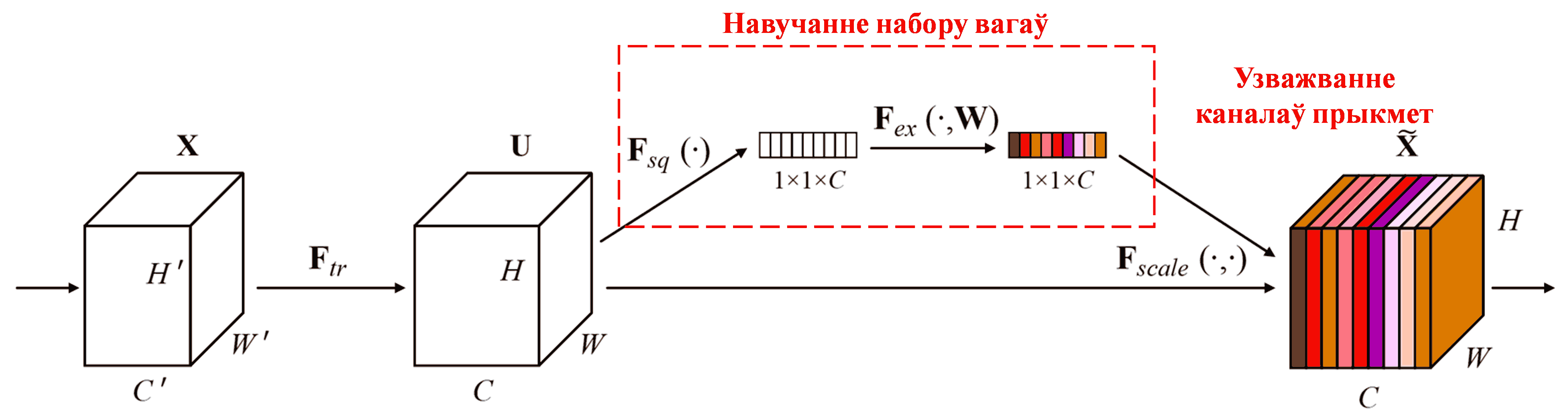
Пры такім падыходзе кожны ўзор будзе мець свой уласны незалежны набор вагаў. Іншымі словамі, для любых двух узораў іх вагі будуць рознымі. У SENet шлях атрымання вагаў выглядае так: «Global Pooling → Fully Connected Layer → ReLU → Fully Connected Layer → Sigmoid».
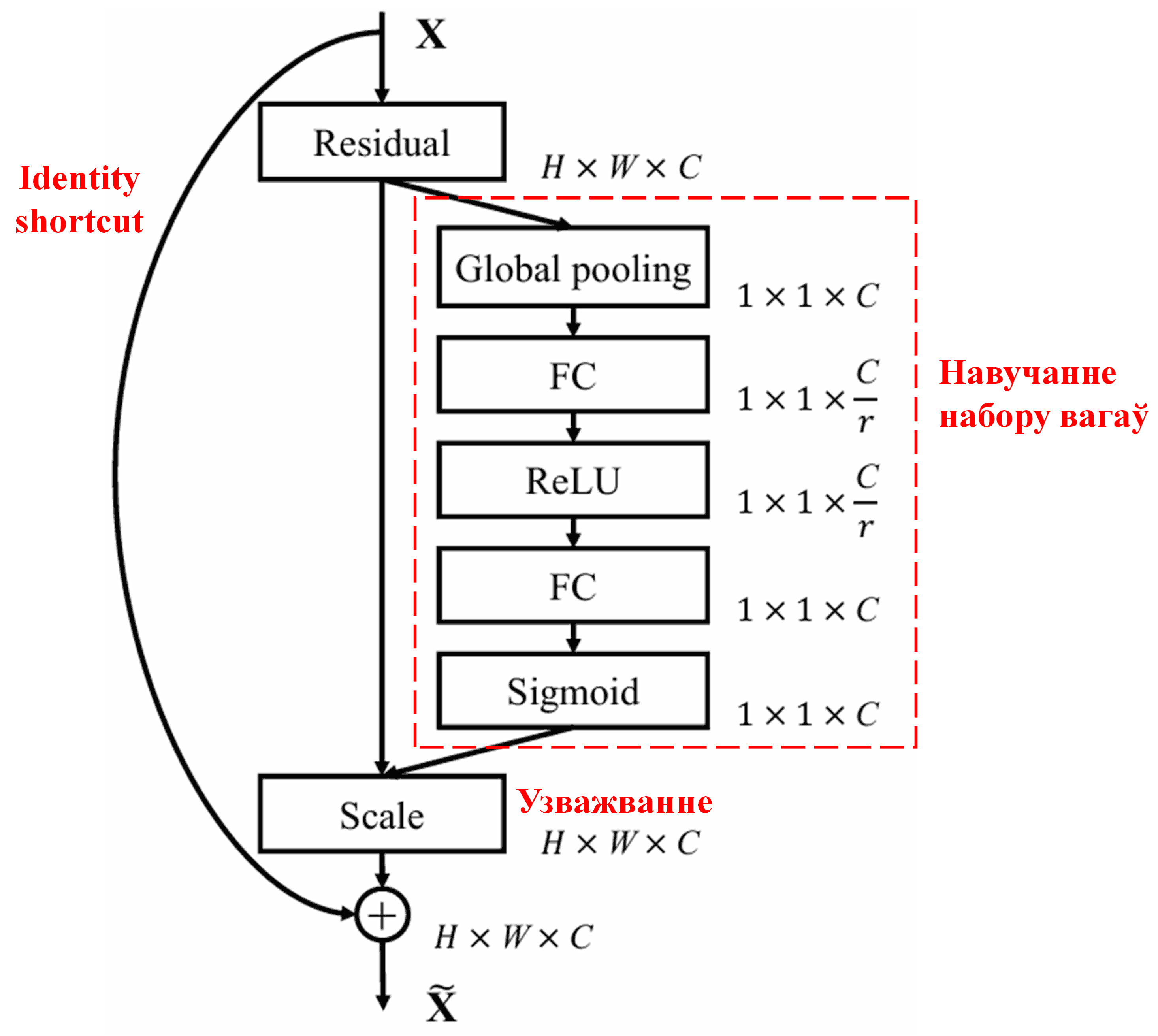
4. Soft Thresholding з глыбокім механізмам увагі
Deep Residual Shrinkage Network запазычвае структуру падсеткі вышэйзгаданай SENet для рэалізацыі soft thresholding у кантэксце глыбокага механізма ўвагі. Праз падсетку (пазначаную чырвонай рамкай) можна навучыцца атрымліваць набор парогаў для прымянення soft thresholding да кожнага канала прыкмет.
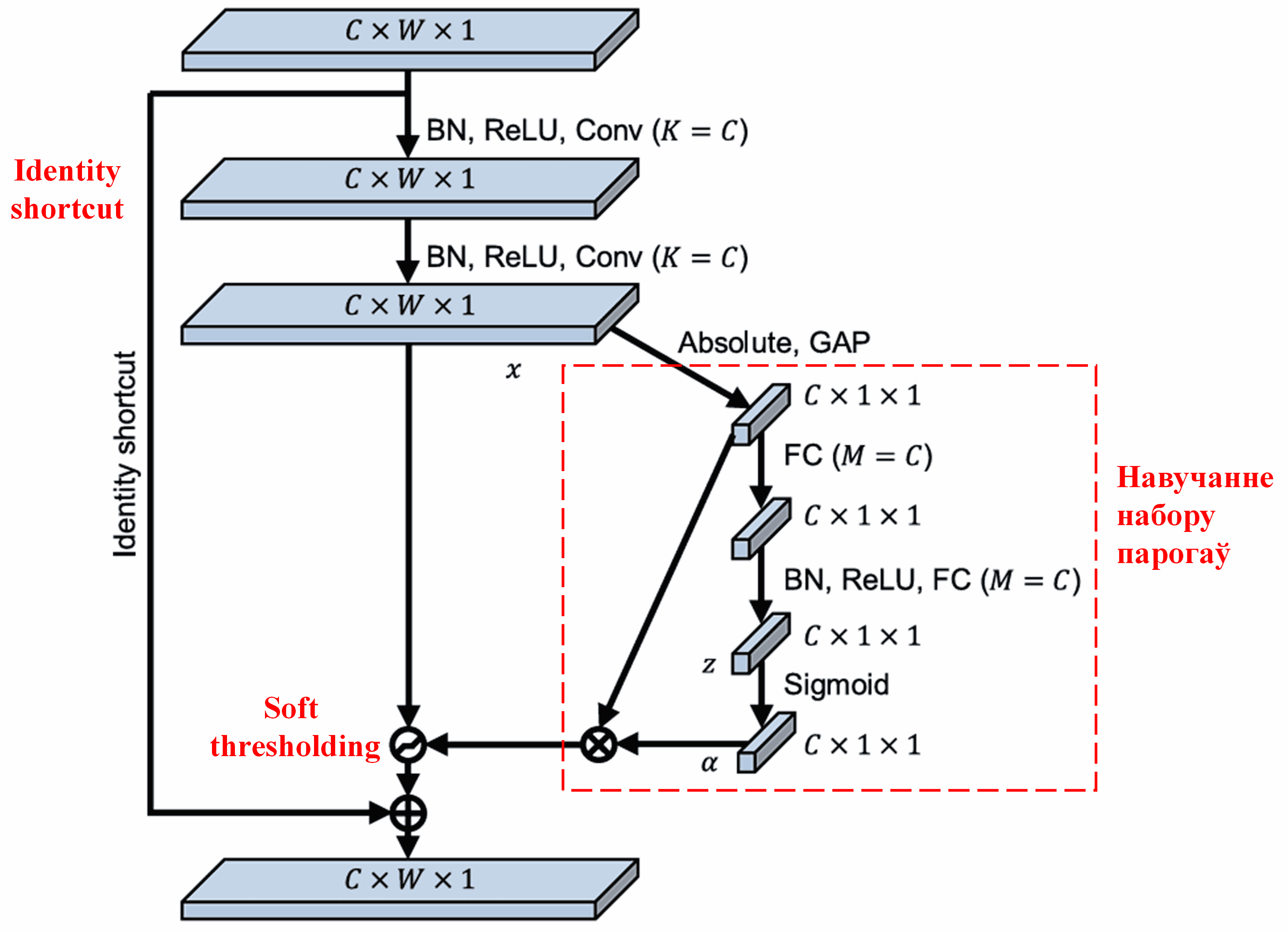
У гэтай падсетцы спачатку вылічваюцца абсалютныя значэнні ўсіх прыкмет уваходнай карты прыкмет (feature map). Затым праз глабальны пулінг (Global Average Pooling) і ўсярэдненне атрымліваецца адна прыкмета, пазначаная як A. На іншым шляху карта прыкмет пасля глабальнага пулінга падаецца ў невялікую паўназвязную сетку (fully connected network). Гэтая паўназвязная сетка выкарыстоўвае функцыю Sigmoid у якасці апошняга слоя для нармалізацыі выхаду ў дыяпазон ад 0 да 1, атрымліваючы каэфіцыент, пазначаны як α. Выніковы парог можна запісаць як α × A. Такім чынам, парог уяўляе сабой лік ад 0 да 1, памножаны на сярэдняе абсалютнае значэнне карты прыкмет. Гэты метад гарантуе, што парог не толькі будзе дадатным, але і не занадта вялікім.
Больш за тое, розныя ўзоры атрымліваюць розныя парогі. Такім чынам, у пэўнай ступені гэта можна лічыць адмысловым механізмам увагі: заўважыць прыкметы, не звязаныя з бягучай задачай, трансфармаваць іх у значэнні, блізкія да нуля (праз два згорткавыя слаі), і абнуліць іх з дапамогай soft thresholding; або наадварот, заўважыць прыкметы, важныя для бягучай задачы, трансфармаваць іх у значэнні, далёкія ад нуля, і захаваць іх.
Нарэшце, поўная архітэктура Deep Residual Shrinkage Network ствараецца шляхам стэкінгу (наслаення) пэўнай колькасці базавых блокаў разам са слаямі згорткі (convolutional layers), нармалізацыі па батчы (batch normalization), функцыямі актывацыі, глабальным пулінгам і выхадным паўназвязным слоем.
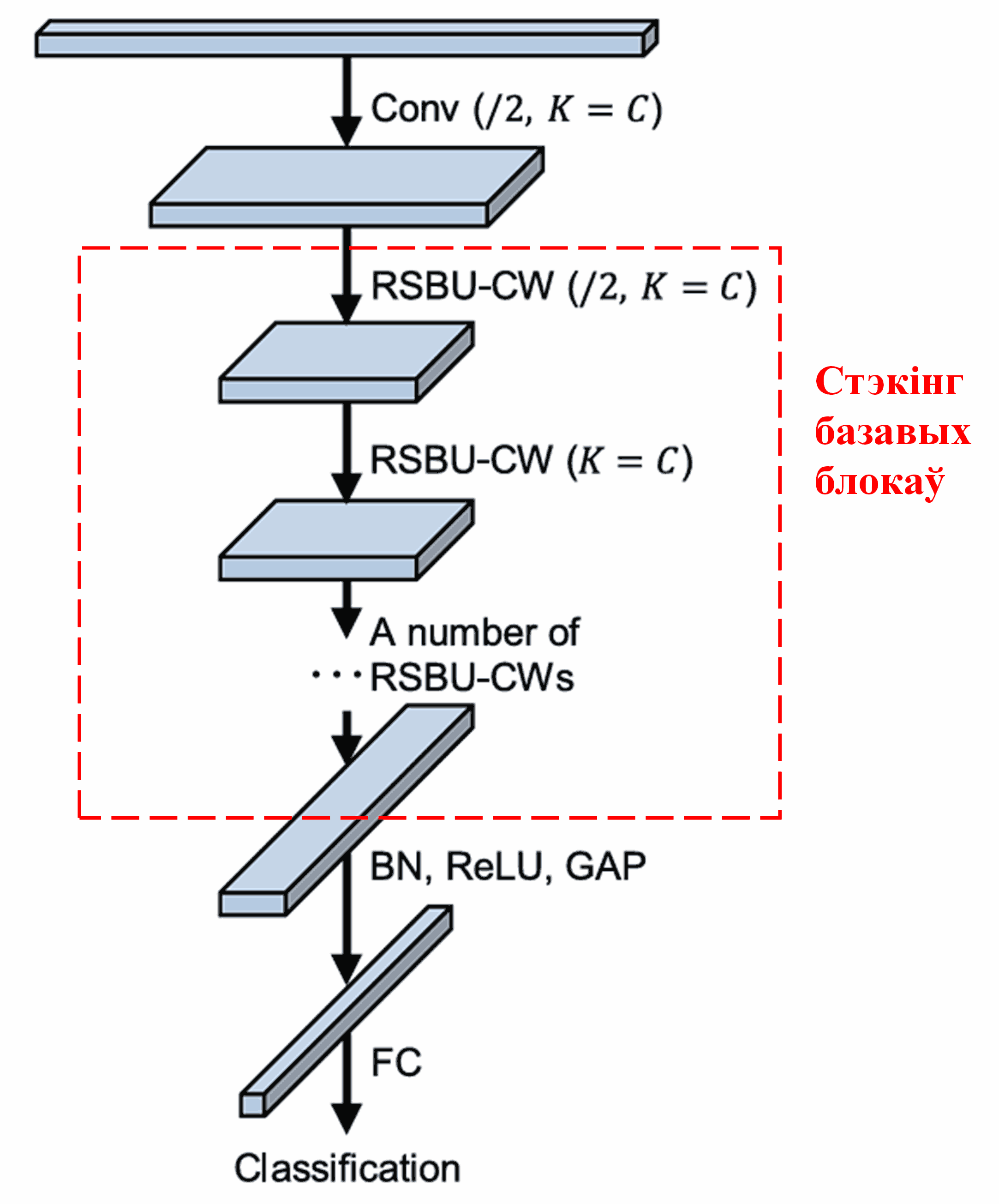
5. Універсальнасць
Deep Residual Shrinkage Network фактычна з’яўляецца універсальным метадам навучання прыкметам (feature learning). Гэта звязана з тым, што ў многіх задачах навучання ўзоры ў большай ці меншай ступені ўтрымліваюць шум і нерэлевантную інфармацыю. Гэты шум і лішняя інфармацыя могуць паўплываць на эфектыўнасць навучання. Напрыклад:
Пры класіфікацыі малюнкаў, калі малюнак адначасова змяшчае мноства іншых аб’ектаў, гэтыя аб’екты можна разумець як «шум». Deep Residual Shrinkage Network можа выкарыстоўваць механізм увагі, каб заўважыць гэты «шум», а затым прымяніць soft thresholding, каб абнуліць прыкметы, якія адпавядаюць гэтаму «шуму», што патэнцыйна павысіць дакладнасць класіфікацыі малюнкаў.
Пры распазнаванні маўлення, асабліва ў шумным асяроддзі (напрыклад, размова на вуліцы ці ў вытворчым цэху), Deep Residual Shrinkage Network можа павысіць дакладнасць распазнавання або, прынамсі, прапанаваць падыход, здольны палепшыць вынікі ў такіх умовах.
Літаратура і спасылкі
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Акадэмічны ўплыў
Гэты артыкул мае больш за 1400 цытаванняў у Google Scholar.
Паводле няпоўнай статыстыкі, Deep Residual Shrinkage Network выкарыстоўваецца (прама ці ў мадыфікаваным выглядзе) у больш чым 1000 публікацыях у такіх галінах, як машынабудаванне, энергетыка, камп’ютарны зрок, медыцына, апрацоўка маўлення і тэксту, радыёлакацыя, дыстанцыйнае зандзіраванне і многіх іншых.