Deep Residual Shrinkage Network (DRSN) on paranneltu versio Deep Residual Networkista (ResNet). Pohjimmiltaan se on yhdistelmä ResNetiä, huomiomekanismeja (attention mechanisms) ja pehmeää kynnistystä (soft thresholding).
Tietyssä määrin Deep Residual Shrinkage Networkin toimintaperiaate voidaan ymmärtää seuraavasti: se hyödyntää huomiomekanismia tunnistaakseen epäolennaiset piirteet ja nollaa ne pehmeän kynnistyksen avulla; vastaavasti se tunnistaa tärkeät piirteet ja säilyttää ne. Tämä prosessi parantaa syvän neuroverkon kykyä erottaa hyödyllisiä piirteitä kohinaisesta signaalista.
1. Tutkimuksen tausta
Ensinnäkin, kun näytteitä luokitellaan, niissä on väistämättä jonkin verran kohinaa, kuten Gaussista kohinaa, vaaleanpunaista kohinaa tai Laplace-kohinaa. Laajemmin tarkasteltuna näytteet sisältävät usein tietoa, joka on epäolennaista nykyisen luokittelutehtävän kannalta, ja tätäkin voidaan pitää kohinana. Tämä kohina voi heikentää luokittelun tuloksia. (Soft thresholding eli pehmeä kynnistys on keskeinen vaihe monissa signaalin kohinanvaimennusalgoritmeissa.)
Esimerkiksi tienvarressa käydyssä keskustelussa puheäänen sekaan saattaa sekoittua autojen torvien ja renkaiden ääniä. Kun tällaiselle signaalille tehdään puheentunnistusta, taustaäänet heikentävät väistämättä tunnistustarkkuutta. Syväoppimisen (deep learning) näkökulmasta torvien ja renkaiden ääniä vastaavat piirteet tulisi poistaa syvän neuroverkon sisällä, jotta ne eivät vaikuttaisi puheentunnistuksen lopputulokseen.
Toiseksi, kohinan määrä vaihtelee usein näytteestä toiseen jopa saman aineiston (dataset) sisällä. (Tämä muistuttaa huomiomekanismin toimintaa; esimerkiksi kuva-aineistossa kohdeobjektin sijainti voi vaihdella kuvasta toiseen, ja huomiomekanismi voi kohdistaa huomion juuri oikeaan kohtaan kussakin kuvassa.)
Otetaan esimerkiksi kissa-koira-luokittelijan kouluttaminen. Jos meillä on viisi kuvaa, joiden etiketti on “koira”, ensimmäisessä kuvassa voi olla koira ja hiiri, toisessa koira ja hanhi, kolmannessa koira ja kana, neljännessä koira ja aasi, ja viidennessä koira ja ankka. Luokittelijaa koulutettaessa nämä epäolennaiset kohteet – hiiret, hanhet, kanat, aasit ja ankat – aiheuttavat häiriötä, mikä laskee luokittelutarkkuutta. Jos pystymme huomaamaan nämä epäolennaiset kohteet ja poistamaan niitä vastaavat piirteet, voimme parantaa kissa-koira-luokittelijan tarkkuutta.
2. Soft Thresholding (Pehmeä kynnistys)
Soft thresholding on monien signaalin kohinanvaimennusalgoritmien ydin. Se poistaa piirteet, joiden itseisarvo on pienempi kuin tietty kynnysarvo, ja “kutistaa” nollaa kohti ne piirteet, joiden itseisarvo on suurempi kuin tämä kynnysarvo. Tämä voidaan toteuttaa seuraavalla kaavalla:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Soft thresholding -funktion derivaatta tulon suhteen on:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Kuten yllä olevasta käy ilmi, soft thresholding -funktion derivaatta on joko 1 tai 0. Tämä ominaisuus on identtinen ReLU-aktivointifunktion kanssa. Siksi soft thresholding voi myös vähentää riskiä, että syväoppimisalgoritmi kärsisi gradientin katoamisesta (gradient vanishing) tai räjähtämisestä (gradient exploding).
Soft thresholding -funktiossa kynnysarvon asettamisen on täytettävä kaksi ehtoa: ensinnäkin kynnysarvon on oltava positiivinen luku; toiseksi kynnysarvo ei saa olla suurempi kuin tulosignaalin maksimiarvo, muuten ulostulo on kokonaan nollaa.
Lisäksi on toivottavaa, että kynnysarvo täyttää kolmannen ehdon: jokaisella näytteellä tulisi olla oma itsenäinen kynnysarvonsa, joka perustuu näytteen sisältämään kohinaan.
Tämä johtuu siitä, että kohinan määrä vaihtelee usein näytteiden välillä. On tavallista, että samassa aineistossa näyte A sisältää vähemmän kohinaa ja näyte B enemmän. Tällöin kohinanvaimennusalgoritmin tulisi käyttää näytteelle A pienempää kynnysarvoa ja näytteelle B suurempaa kynnysarvoa. Vaikka nämä piirteet ja kynnysarvot menettävätkin tarkan fysikaalisen merkityksensä syvissä neuroverkoissa, peruslogiikka on sama. Toisin sanoen jokaisella näytteellä tulisi olla oma kynnysarvonsa, joka määräytyy sen sisältämän kohinan perusteella.
3. Huomiomekanismi (Attention Mechanism)
Huomiomekanismit ovat helposti ymmärrettävissä tietokonenäön (computer vision) kontekstissa. Eläinten näköjärjestelmä pystyy skannaamaan nopeasti koko alueen ja löytämään kohdeobjektin, minkä jälkeen huomio keskitetään tähän kohteeseen yksityiskohtien havaitsemiseksi, samalla kun epäolennainen tieto sivuutetaan. Lisätietoja löytyy huomiomekanismeja käsittelevästä kirjallisuudesta.
Squeeze-and-Excitation Network (SENet) on suhteellisen uusi syväoppimismenetelmä, joka hyödyntää huomiomekanismeja. Eri näytteissä eri piirrekanavien (feature channels) merkitys luokittelutehtävässä vaihtelee. SENet käyttää pientä aliverkkoa (sub-network) oppiakseen joukon painokertoimia. Nämä painokertoimet kerrotaan kunkin kanavan piirteillä, jolloin eri kanavien piirteiden suuruutta voidaan säätää. Tätä prosessia voidaan pitää erisuuruisen huomion kohdistamisena eri piirrekanaviin.
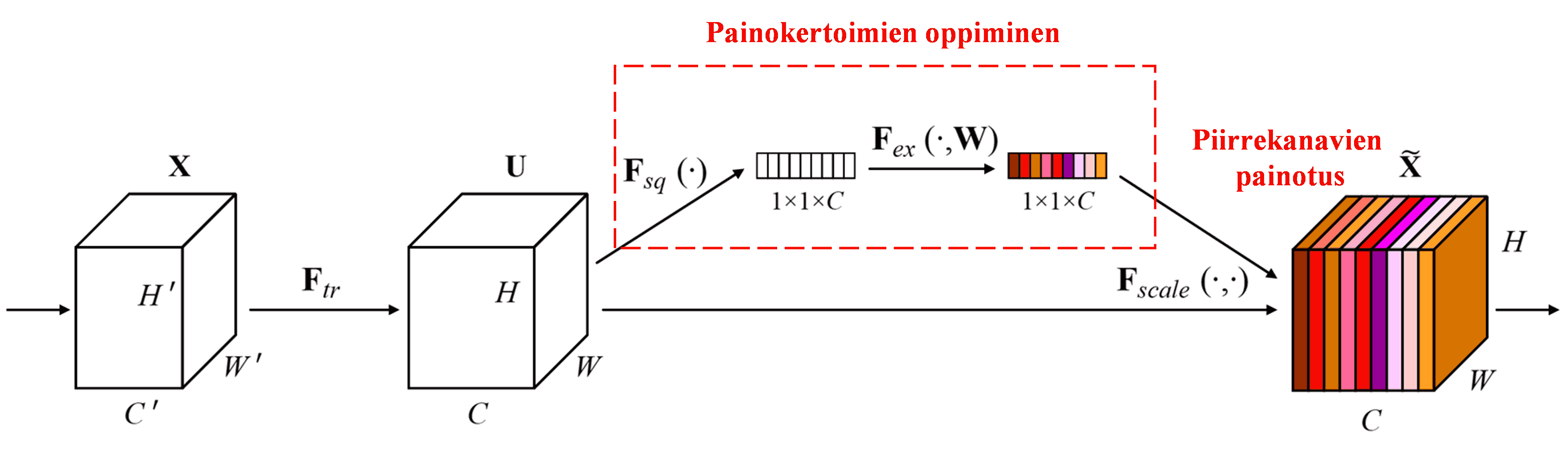
Tässä lähestymistavassa jokaisella näytteellä on oma itsenäinen joukko painokertoimia. Toisin sanoen, kahden satunnaisen näytteen painokertoimet ovat erilaiset. SENetissä painokertoimien laskentareitti on: “Globaali poolaus (Global Pooling) → Täysin kytketty kerros (Fully Connected Layer) → ReLU-funktio → Täysin kytketty kerros → Sigmoid-funktio”.
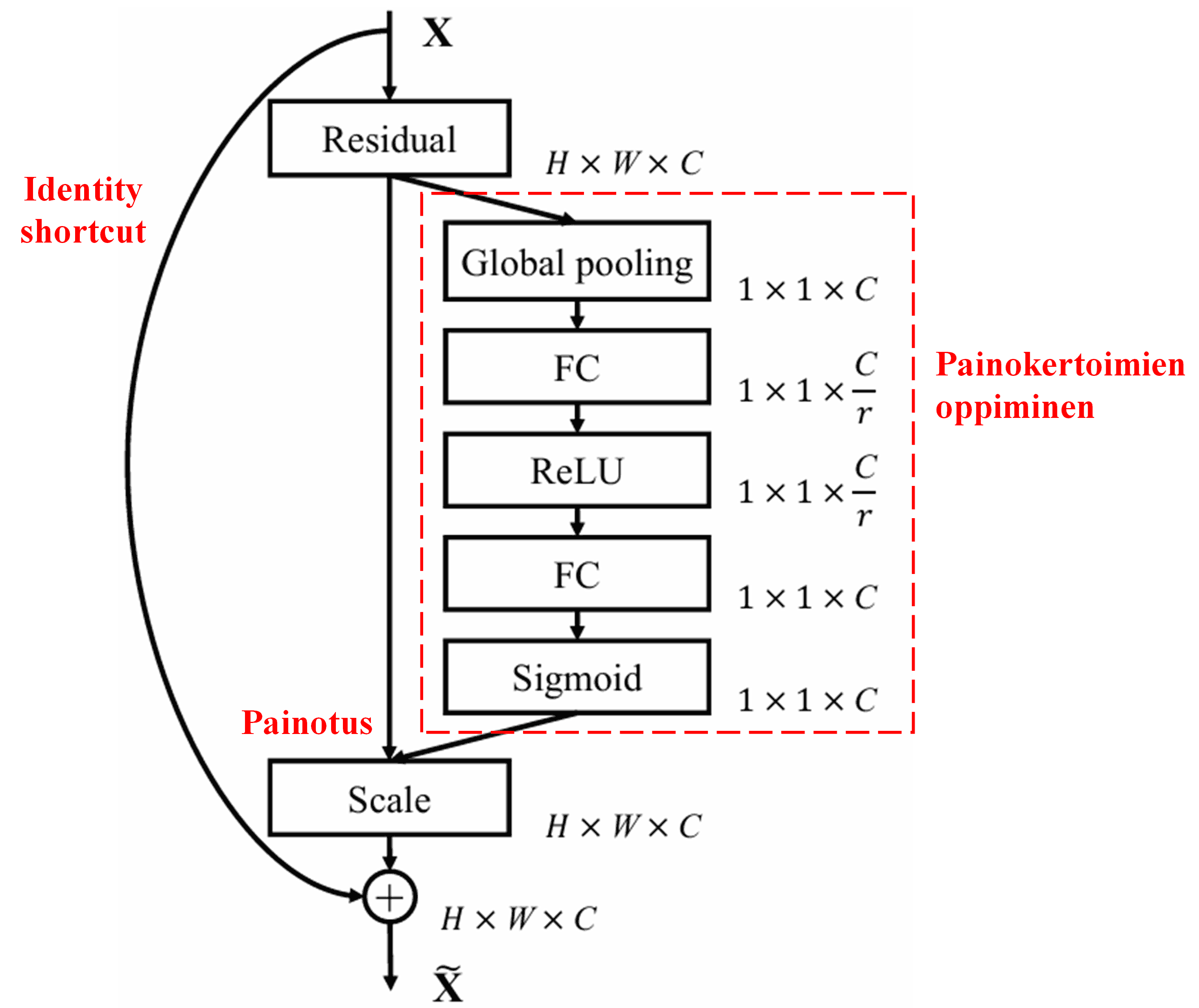
4. Soft Thresholding syvällä huomiomekanismilla
Deep Residual Shrinkage Network hyödyntää edellä mainittua SENet-aliverkon rakennetta toteuttaakseen soft thresholding -operaation syvän huomiomekanismin avulla. Punaisella laatikolla merkityn aliverkon avulla voidaan oppia kynnysarvot, joilla soft thresholding suoritetaan kullekin piirrekanavalle.
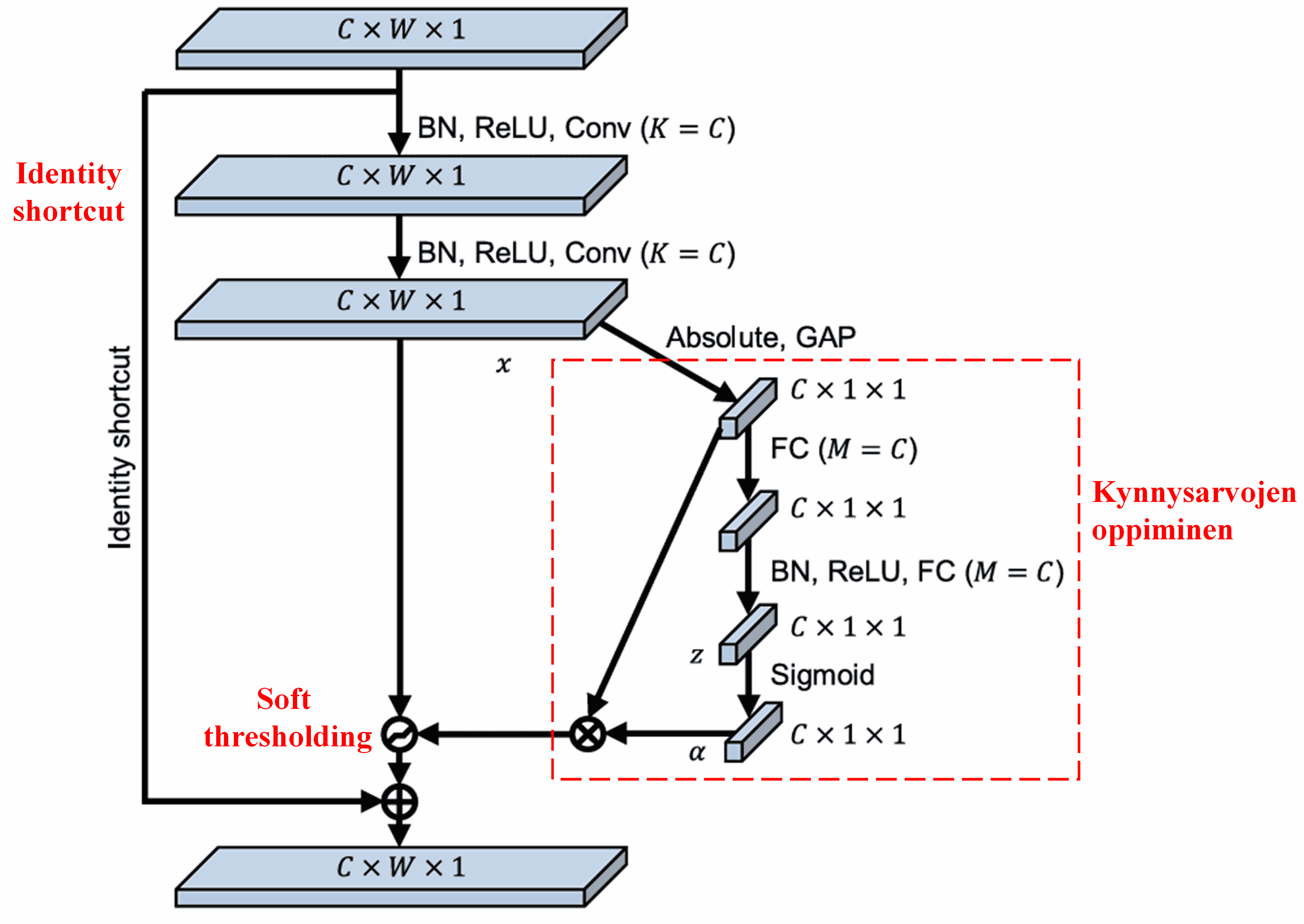
Tässä aliverkossa lasketaan ensin syötepiirrekartan (feature map) kaikkien piirteiden itseisarvot. Tämän jälkeen globaalin keskiarvopoolauksen (Global Average Pooling) avulla saadaan yksi piirre, jota merkitään kirjaimella A. Toisessa haarassa globaalin poolauksen jälkeinen piirrekartta syötetään pieneen täysin kytkettyyn verkkoon. Tämän verkon viimeisenä kerroksena on Sigmoid-funktio, joka skaalaa ulostulon välille 0–1, tuottaen kertoimen α. Lopullinen kynnysarvo voidaan esittää muodossa α × A. Kynnysarvo on siis luku väliltä 0–1 kerrottuna piirrekartan itseisarvojen keskiarvolla. Tämä menetelmä varmistaa, että kynnysarvo on positiivinen, mutta ei liian suuri.
Lisäksi eri näytteet saavat eri kynnysarvot. Tätä voidaan tietyssä määrin pitää erityisenä huomiomekanismina: se huomaa nykyisen tehtävän kannalta epäolennaiset piirteet, muuntaa ne kahden konvoluutiokerroksen avulla lähelle nollaa oleviksi arvoiksi ja nollaa ne soft thresholding -operaatiolla; tai vastaavasti huomaa tehtävän kannalta olennaiset piirteet ja säilyttää ne.
Lopuksi, pinoamalla tietty määrä perusmoduuleja sekä konvoluutiokerroksia, Batch Normalizationia, aktivointifunktioita, globaalia keskiarvopoolausta ja täysin kytkettyjä ulostulokerroksia, saadaan muodostettua täydellinen Deep Residual Shrinkage Network.
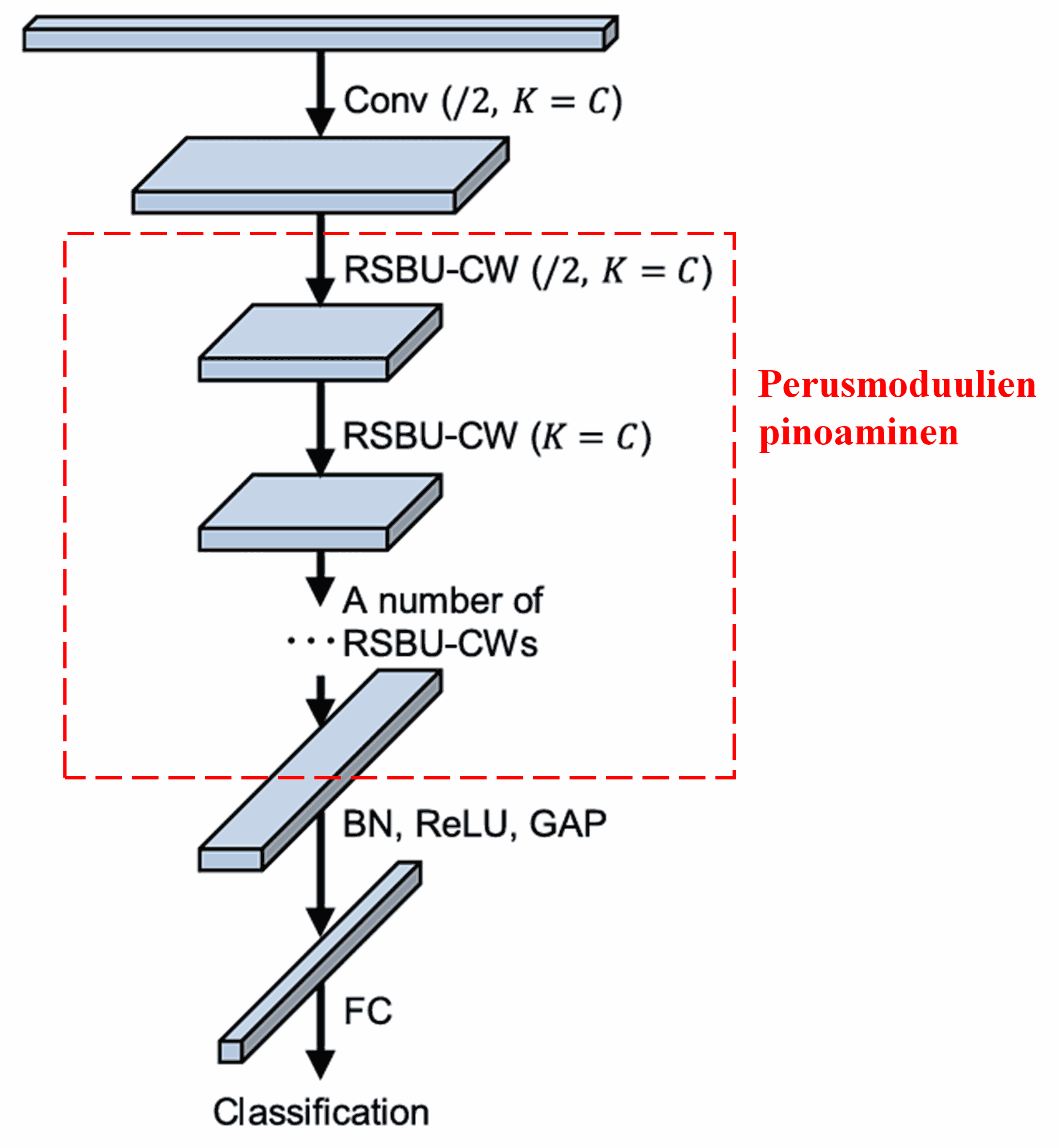
5. Yleistettävyys
Deep Residual Shrinkage Network on itse asiassa yleiskäyttöinen piirteiden oppimismenetelmä. Tämä johtuu siitä, että monissa piirteiden oppimistehtävissä näytteet sisältävät väistämättä jonkin verran kohinaa ja epäolennaista tietoa. Nämä voivat vaikuttaa heikentävästi oppimistuloksiin. Esimerkkejä:
Kuvien luokittelussa, jos kuva sisältää monia muita objekteja, näitä voidaan pitää “kohinana”. Deep Residual Shrinkage Network voi huomiomekanisminsa avulla havaita tämän “kohinan” ja nollata sitä vastaavat piirteet soft thresholding -tekniikalla, mikä voi parantaa luokittelutarkkuutta.
Puheentunnistuksessa, erityisesti meluisissa ympäristöissä kuten tienvarressa tai tehdashallissa keskusteltaessa, Deep Residual Shrinkage Network voi parantaa tunnistustarkkuutta tai ainakin tarjota menetelmän, jolla tarkkuutta on mahdollista parantaa.
Viitteet
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Akateeminen vaikuttavuus
Artikkelilla on jo yli 1400 viittausta Google Scholarissa.
Epätäydellisten tilastojen mukaan Deep Residual Shrinkage Networkia (DRSN) on sovellettu tai jatkokehitetty yli 1000 julkaisussa monilla eri aloilla, mukaan lukien koneenrakennus, sähkövoimatekniikka, tietokonenäkö, terveydenhuolto, puheenkäsittely, tekstianalyysi, tutkateknologia ja kaukokartoitus.