Deep Residual Shrinkage Network (DRSN) to ulepszona wersja sieci rezydualnych (ResNet). W istocie jest to integracja głębokich sieci rezydualnych, mechanizmów atencji oraz funkcji miękkiego progowania (soft thresholding).
W pewnym stopniu zasadę działania sieci DRSN można zrozumieć następująco: wykorzystuje ona mechanizm atencji do identyfikacji nieistotnych cech, a następnie zeruje je za pomocą funkcji miękkiego progowania; i odwrotnie – zauważa istotne cechy i je zachowuje. Proces ten wzmacnia zdolność głębokiej sieci neuronowej do ekstrakcji użytecznych cech z sygnałów zawierających szum.
1. Motywacja badawcza
Po pierwsze, podczas klasyfikacji próbek nieuniknione jest występowanie szumu, takiego jak szum gaussowski, różowy czy laplasowski. W szerszym ujęciu, próbki często zawierają informacje niezwiązane z bieżącym zadaniem klasyfikacji, co również można interpretować jako szum. Szum ten może negatywnie wpływać na efektywność klasyfikacji. (Miękkie progowanie jest kluczowym krokiem w wielu algorytmach odszumiania sygnałów).
Na przykład podczas rozmowy przy ruchliwej ulicy, głosom rozmówców mogą towarzyszyć dźwięki klaksonów czy toczących się kół. Podczas rozpoznawania mowy na podstawie takich sygnałów, wyniki będą nieuchronnie zakłócone przez te dźwięki tła. Z perspektywy uczenia głębokiego (deep learning), cechy odpowiadające klaksonom i kołom powinny zostać usunięte wewnątrz głębokiej sieci neuronowej, aby nie wpływały negatywnie na rozpoznawanie mowy.
Po drugie, nawet w tym samym zbiorze danych, poziom zaszumienia poszczególnych próbek jest często różny. (Ma to wiele wspólnego z mechanizmami atencji; biorąc za przykład zbiór obrazów, lokalizacja obiektu docelowego może być inna na każdym zdjęciu, a mechanizm atencji potrafi skupić się na konkretnym położeniu obiektu na każdym obrazie z osobna).
Załóżmy, że trenujemy klasyfikator psów i kotów. Mamy 5 obrazów oznaczonych etykietą „pies”. Pierwszy obraz może zawierać psa i mysz, drugi psa i gęś, trzeci psa i kurczaka, czwarty psa i osła, a piąty psa i kaczkę. Podczas trenowania klasyfikatora nieuchronnie napotkamy zakłócenia ze strony nieistotnych obiektów, takich jak myszy, gęsi, kurczaki, osły czy kaczki, co spowoduje spadek dokładności klasyfikacji. Jeśli bylibyśmy w stanie zauważyć te nieistotne obiekty i usunąć odpowiadające im cechy, możliwe stałoby się zwiększenie dokładności naszego klasyfikatora.
2. Miękkie progowanie (Soft Thresholding)
Miękkie progowanie to kluczowy krok w wielu algorytmach odszumiania sygnałów. Polega ono na usunięciu cech, których wartość bezwzględna jest mniejsza od określonego progu, oraz na „obkurczeniu” (przesunięciu w stronę zera) cech o wartościach większych od tego progu. Można to zrealizować za pomocą następującego wzoru:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Pochodna wyjścia funkcji miękkiego progowania względem wejścia wynosi:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Jak widać powyżej, pochodna miękkiego progowania wynosi albo 1, albo 0. Ta właściwość jest identyczna jak w przypadku funkcji aktywacji ReLU. Dzięki temu miękkie progowanie pozwala również zmniejszyć ryzyko wystąpienia problemów z zanikaniem lub eksplodowaniem gradientu w algorytmach uczenia głębokiego.
W funkcji miękkiego progowania ustawienie progu musi spełniać dwa warunki: po pierwsze, próg musi być liczbą dodatnią; po drugie, próg nie może przekraczać maksymalnej wartości sygnału wejściowego, w przeciwnym razie na wyjściu otrzymamy same zera.
Jednocześnie najlepiej, aby próg spełniał trzeci warunek: każda próbka powinna mieć swój własny, niezależny próg, dostosowany do zawartości szumu.
Wynika to z faktu, że zawartość szumu często różni się w zależności od próbki. W ramach jednego zbioru danych często zdarza się sytuacja, gdzie próbka A zawiera mało szumu, a próbka B zawiera go dużo. W takim przypadku, podczas wykonywania miękkiego progowania w algorytmie odszumiania, dla próbki A należałoby zastosować mniejszy próg, a dla próbki B – większy. W głębokich sieciach neuronowych, chociaż te cechy i progi tracą swoje bezpośrednie fizyczne definicje, podstawowa logika pozostaje ta sama. Innymi słowy, każda próbka powinna mieć swój własny, niezależny próg, wynikający z jej specyficznej zawartości szumu.
3. Mechanizm atencji
Mechanizmy atencji są stosunkowo łatwe do zrozumienia na przykładzie dziedziny widzenia komputerowego (computer vision). System wzrokowy zwierząt potrafi szybko przeskanować cały obszar, wykryć obiekt docelowy, a następnie skupić na nim uwagę (atencję), aby wyodrębnić więcej szczegółów, jednocześnie tłumiąc nieistotne informacje. Szczegółowe informacje można znaleźć w literaturze dotyczącej mechanizmów atencji.
Squeeze-and-Excitation Network (SENet) to stosunkowo nowa metoda w głębokim uczeniu wykorzystująca mechanizm atencji. W różnych próbkach wkład poszczególnych kanałów cech (feature channels) w zadanie klasyfikacji jest często różny. SENet wykorzystuje niewielką podsieć do uzyskania zestawu wag, a następnie mnoży te wagi przez cechy odpowiednich kanałów, aby dostosować wielkość cech w każdym kanale. Proces ten można postrzegać jako przykładanie uwagi o różnym natężeniu do poszczególnych kanałów cech.
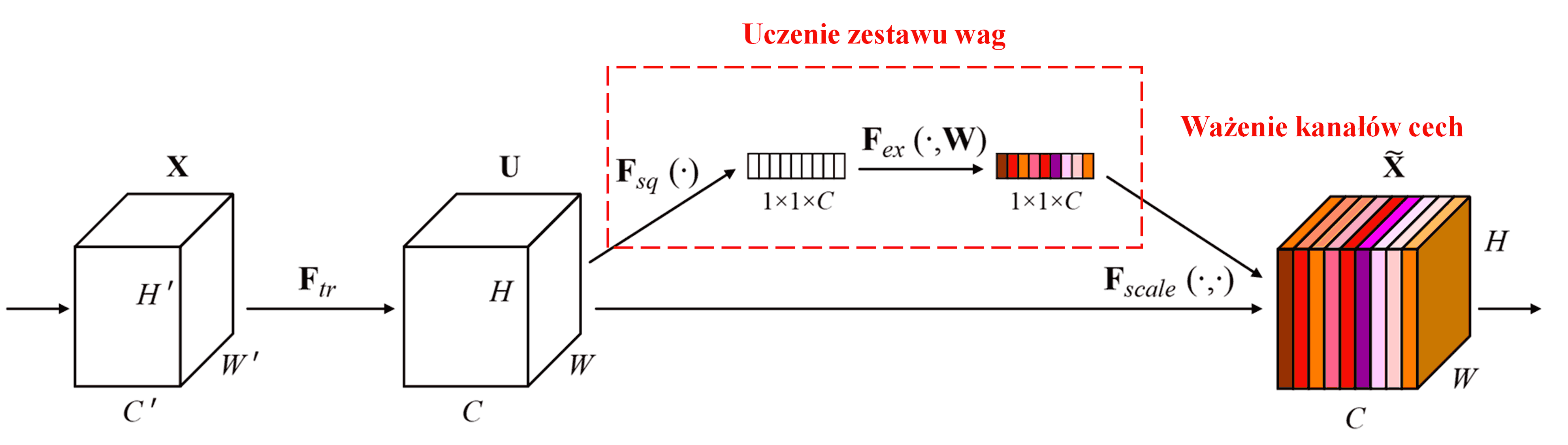
W tym podejściu każda próbka otrzymuje swój własny, niezależny zestaw wag. Innymi słowy, wagi dla dowolnych dwóch próbek są różne. W sieci SENet konkretna ścieżka uzyskiwania wag to: „Global Pooling (globalne uśrednianie) → Warstwa w pełni połączona → Funkcja ReLU → Warstwa w pełni połączona → Funkcja Sigmoid”.
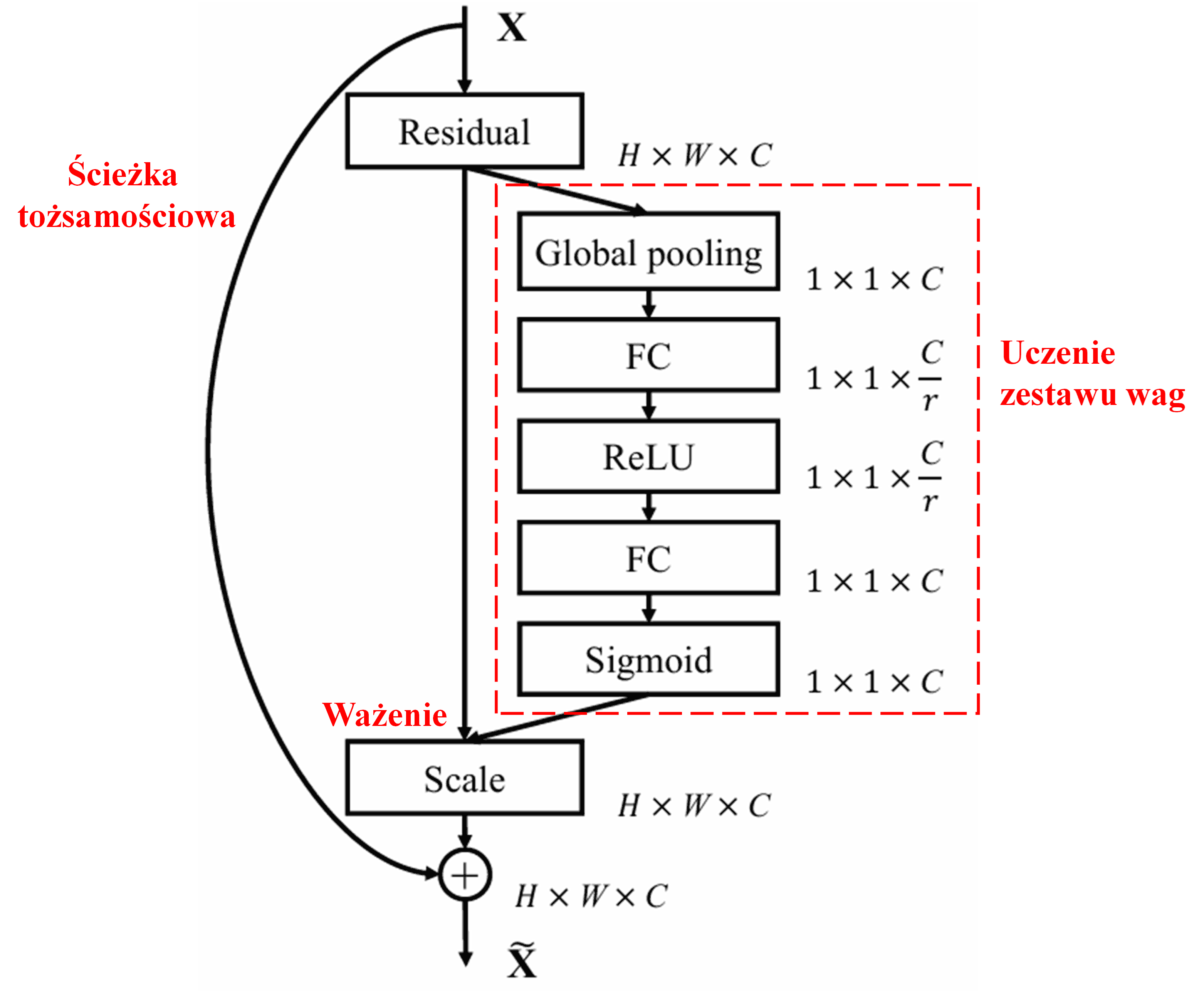
4. Miękkie progowanie w ramach głębokiego mechanizmu atencji
Sieć Deep Residual Shrinkage Network (DRSN) czerpie inspirację z opisanej powyżej struktury podsieci SENet, aby zrealizować miękkie progowanie w ramach głębokiego mechanizmu atencji. Za pomocą podsieci (zaznaczonej w czerwonej ramce) można wyuczyć zestaw progów, które posłużą do wykonania miękkiego progowania na każdym kanale cech.
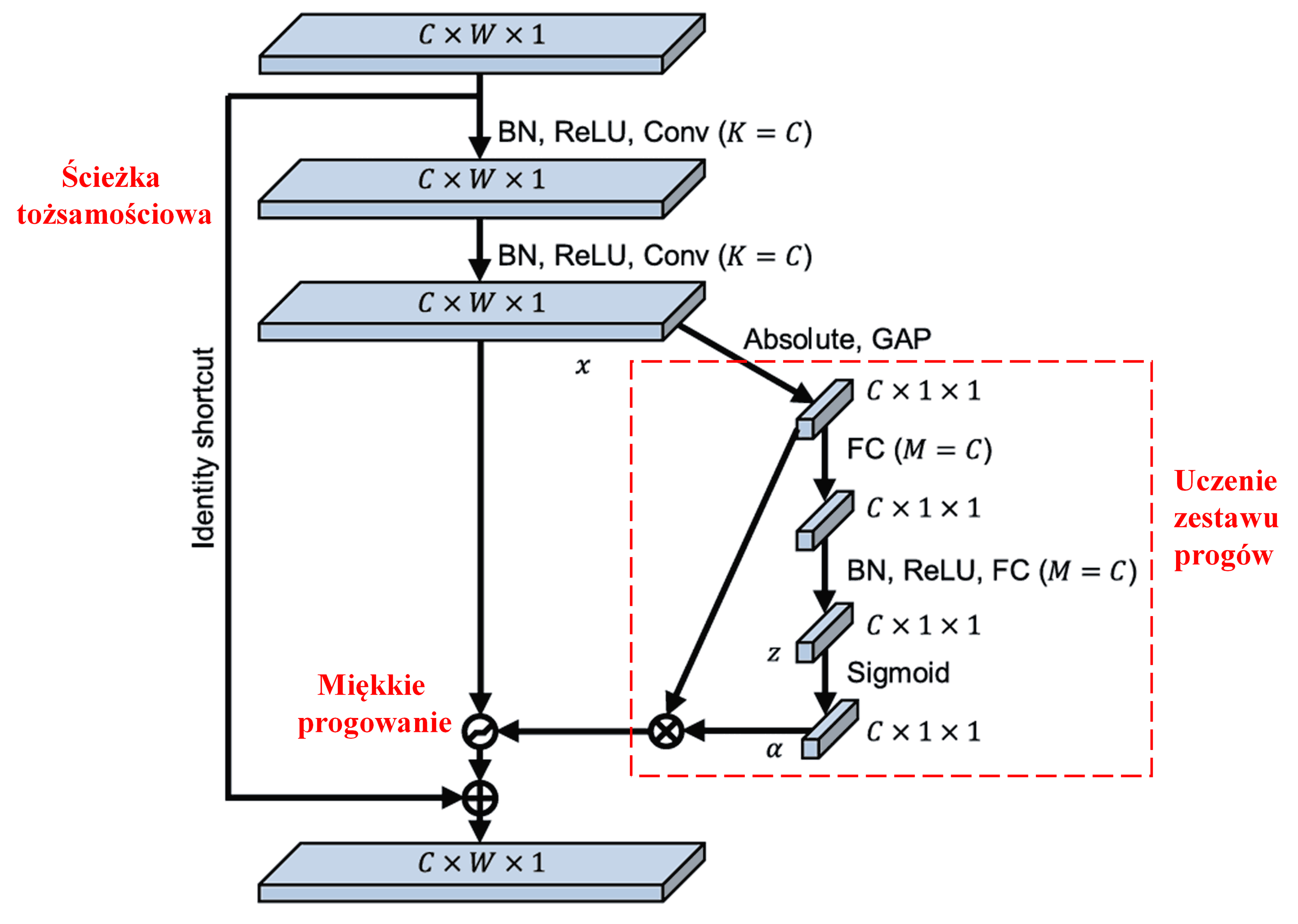
W tej podsieci najpierw obliczane są wartości bezwzględne wszystkich cech na wejściowej mapie cech. Następnie, poprzez globalne uśrednianie (Global Average Pooling), uzyskuje się cechę, którą oznaczymy jako A. W drugiej ścieżce, mapa cech po globalnym uśrednianiu trafia do małej sieci w pełni połączonej (fully connected). Ta sieć wykorzystuje funkcję Sigmoid jako ostatnią warstwę, aby znormalizować wyjście do przedziału między 0 a 1, uzyskując współczynnik oznaczony jako α. Ostateczny próg można wyrazić jako α×A. Zatem próg jest iloczynem liczby z przedziału od 0 do 1 oraz średniej wartości bezwzględnej mapy cech. Taka metoda gwarantuje, że próg jest nie tylko dodatni, ale także nie jest zbyt duży.
Ponadto, różne próbki otrzymują różne progi. W pewnym stopniu można to interpretować jako specyficzny mechanizm atencji: system zauważa cechy niezwiązane z bieżącym zadaniem, przekształca je (poprzez dwie warstwy konwolucyjne) w wartości bliskie zeru, a następnie całkowicie zeruje za pomocą miękkiego progowania; i odwrotnie – zauważa cechy związane z zadaniem, przekształca je w wartości dalekie od zera i zachowuje je.
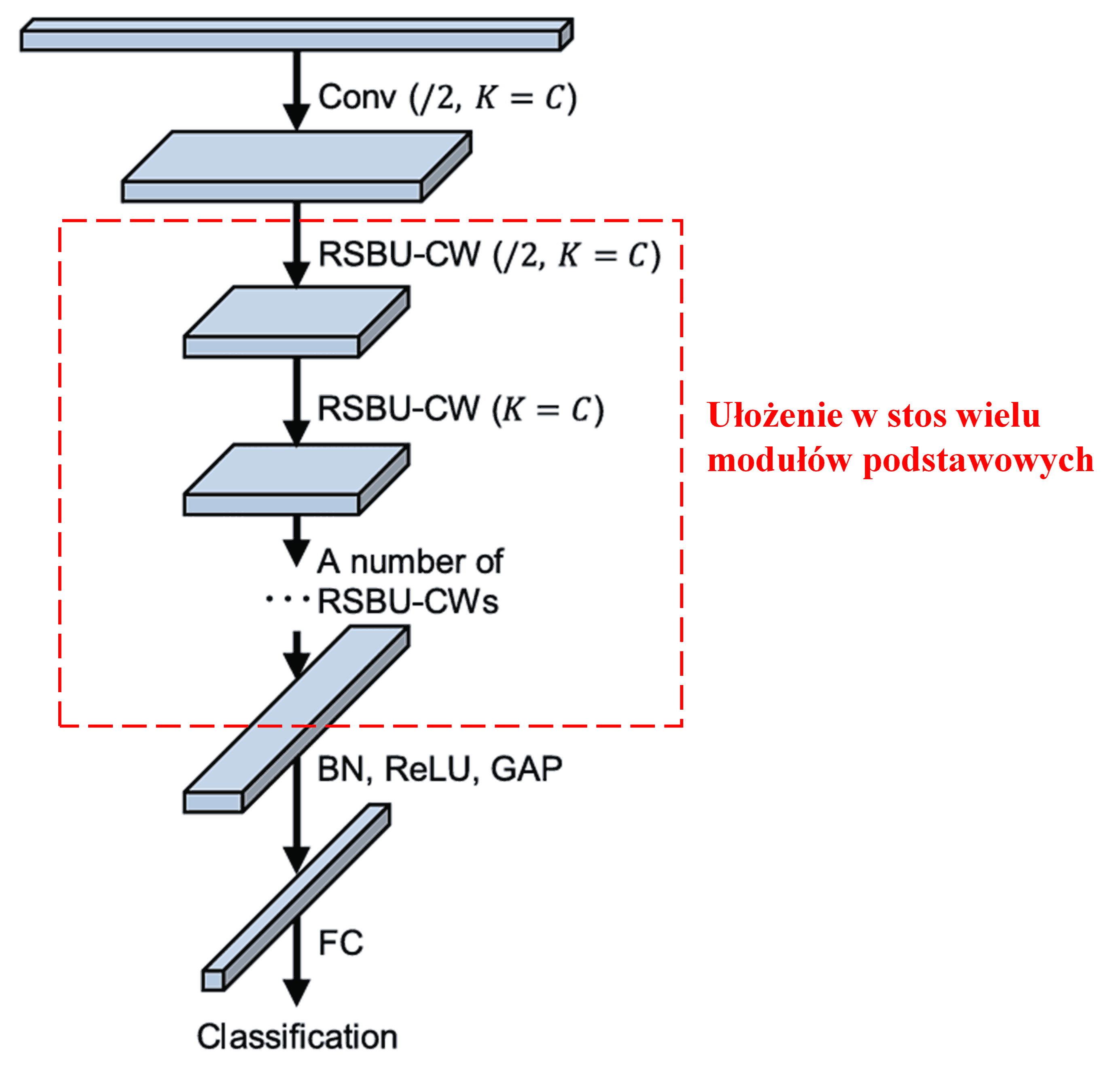
Na koniec, poprzez ułożenie w stos określonej liczby tych podstawowych modułów wraz z warstwami konwolucyjnymi, normalizacją wsadową (Batch Normalization), funkcjami aktywacji, globalnym uśrednianiem (GAP) oraz warstwami wyjściowymi, otrzymujemy kompletną sieć DRSN.
5. Uniwersalność metody
Sieć Deep Residual Shrinkage Network jest w rzeczywistości uniwersalną metodą uczenia się cech (feature learning). Dzieje się tak dlatego, że w wielu zadaniach uczenia cech próbki zawierają mniej lub więcej szumu oraz nieistotnych informacji. Szum ten i nieistotne informacje mogą wpływać na efektywność uczenia. Na przykład:
Podczas klasyfikacji obrazów, jeśli obraz zawiera jednocześnie wiele innych obiektów, obiekty te można rozumieć jako „szum”. Sieć DRSN może być w stanie wykorzystać mechanizm atencji do zauważenia tego „szumu”, a następnie użyć miękkiego progowania, aby wyzerować cechy odpowiadające temu „szumowi”, co potencjalnie zwiększy dokładność klasyfikacji obrazów.
Podczas rozpoznawania mowy, zwłaszcza w dość hałaśliwym otoczeniu, na przykład podczas rozmowy przy ulicy lub w hali fabrycznej, sieć DRSN może poprawić dokładność rozpoznawania mowy, lub przynajmniej wskazać kierunek myślenia pozwalający na zwiększenie tej dokładności.
Bibliografia
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Wpływ w środowisku akademickim
Artykuł ten uzyskał już ponad 1400 cytowań w Google Scholar.
Według niepełnych statystyk, sieci Deep Residual Shrinkage Networks (DRSN) zostały wykorzystane w ponad 1000 publikacjach, gdzie były bezpośrednio stosowane lub udoskonalane w wielu dziedzinach, takich jak inżynieria mechaniczna, energetyka, widzenie komputerowe, medycyna, przetwarzanie mowy, analiza tekstu, technika radarowa czy teledetekcja.