Deep Residual Shrinkage Network (DRSN) är en förbättrad variant av Deep Residual Networks (ResNet). I grunden är det en integration av ResNet, attention-mekanismer och soft thresholding-funktioner.
Till viss del kan arbetsprincipen för Deep Residual Shrinkage Network förstås så här: den använder attention-mekanismer för att identifiera oviktiga features och eliminerar dem via soft thresholding (sätter dem till noll); omvänt identifierar den viktiga features och behåller dem. Denna process stärker det djupa neurala nätverkets förmåga att extrahera användbara features från signaler som innehåller brus.
1. Forskningsmotiv
För det första: när man klassificerar dataexempel är närvaron av brus – såsom gaussiskt brus, rosa brus och laplacianskt brus – oundviklig. Mer generellt innehåller data ofta information som är irrelevant för den aktuella klassificeringsuppgiften, vilket också kan tolkas som brus. Detta brus kan påverka klassificeringsresultatet negativt. (Soft thresholding är ett nyckelsteg i många algoritmer för signal-denoising, dvs. brusreducering.)
Ta ett exempel: vid ett samtal vid en vägkant kan ljudet blandas med biltutor och ljudet av hjul. Vid taligenkänning på dessa signaler kommer resultatet oundvikligen att påverkas av dessa bakgrundsljud. Från ett Deep Learning-perspektiv bör de features som motsvarar tutor och hjulljud raderas inuti det djupa neurala nätverket för att förhindra att de påverkar resultatet av taligenkänningen.
För det andra: även inom samma dataset varierar ofta mängden brus från exempel till exempel. (Detta har likheter med attention-mekanismer; om vi tar ett bilddataset som exempel, kan målobjektets position variera mellan olika bilder, och attention-mekanismer kan fokusera på just den specifika platsen för målobjektet i varje bild.)
Om vi till exempel tränar en klassificerare för katter och hundar, tänk dig fem bilder märkta som “hund”. Den första bilden kanske innehåller en hund och en mus, den andra en hund och en gås, den tredje en hund och en kyckling, den fjärde en hund och en åsna, och den femte en hund och en anka. Under träningen kommer klassificeraren oundvikligen att störas av irrelevanta objekt som möss, gäss, kycklingar, åsnor och ankor, vilket leder till sämre precision. Om vi kan identifiera dessa irrelevanta objekt – mössen, gässen, etc. – och radera deras motsvarande features, är det möjligt att öka precisionen för katt- och hundklassificeraren.
2. Soft Thresholding
Soft thresholding är ett centralt steg i många algoritmer för brusreducering. Det raderar features vars absolutvärde understiger ett visst tröskelvärde, och “krymper” (shrinks) features vars absolutvärde överstiger detta tröskelvärde i riktning mot noll. Det kan implementeras med följande formel:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Derivatan av soft thresholding-outputen med avseende på inputen är:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Som visas ovan är derivatan av soft thresholding antingen 1 eller 0. Denna egenskap är identisk med aktiveringsfunktionen ReLU. Därför kan soft thresholding också minska risken för att Deep Learning-algoritmer drabbas av gradient vanishing (försvinnande gradienter) och gradient exploding (exploderande gradienter).
För soft thresholding-funktionen måste inställningen av tröskelvärdet uppfylla två villkor: för det första måste tröskelvärdet vara ett positivt tal; för det andra får tröskelvärdet inte överstiga insignalens maximala värde, annars blir outputen helt och hållet noll.
Dessutom är det önskvärt att tröskelvärdet uppfyller ett tredje villkor: varje dataexempel bör ha sitt eget oberoende tröskelvärde baserat på dess eget brusinnehåll.
Detta beror på att brusinnehållet ofta varierar mellan olika exempel. Det är till exempel vanligt inom samma dataset att “Exempel A” innehåller mindre brus medan “Exempel B” innehåller mer brus. I detta fall, när man utför soft thresholding i en algoritm för brusreducering, bör Exempel A använda ett mindre tröskelvärde, medan Exempel B bör använda ett större tröskelvärde. I djupa neurala nätverk, även om dessa features och tröskelvärden förlorar sin strikta fysikaliska definition, kvarstår den grundläggande logiken. Med andra ord: varje exempel bör ha sitt eget oberoende tröskelvärde som bestäms av dess specifika brusinnehåll.
3. Attention-mekanism
Attention-mekanismer är relativt lätta att förstå inom området Computer Vision (datorseende). Djurs visuella system kan urskilja mål genom att snabbt skanna av hela området, för att sedan fokusera sin uppmärksamhet (attention) på målobjektet. Detta gör att de kan extrahera fler detaljer samtidigt som de undertrycker irrelevant information. För detaljer, vänligen se litteratur angående attention-mekanismer.
Squeeze-and-Excitation Network (SENet) är en relativt ny Deep Learning-metod som använder attention-mekanismer. Bidraget från olika feature-kanaler till klassificeringsuppgiften varierar ofta mellan olika exempel. SENet använder ett litet sub-nätverk för att få fram en uppsättning vikter, och multiplicerar sedan dessa vikter med features från respektive kanal för att justera storleken på features i varje kanal. Denna process kan ses som att man applicerar olika nivåer av attention på olika feature-kanaler.
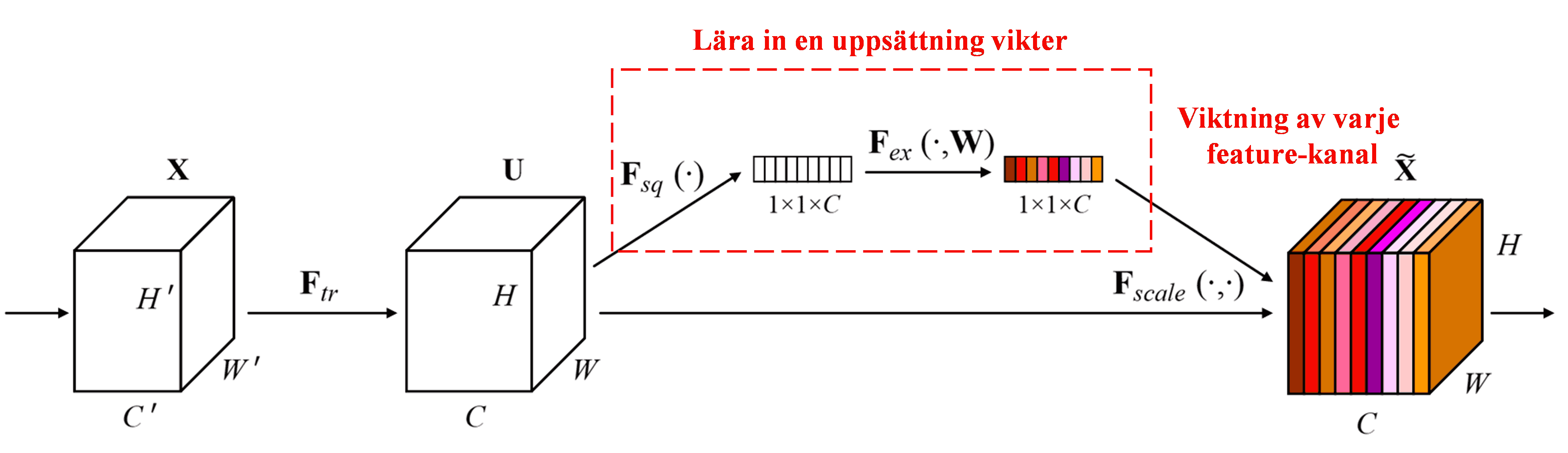
I denna metod har varje dataexempel sin egen oberoende uppsättning vikter. Med andra ord är vikterna för två godtyckliga exempel olika. I SENet är den specifika vägen för att erhålla vikter: “Global Pooling → Fully Connected-lager → ReLU-funktion → Fully Connected-lager → Sigmoid-funktion”.
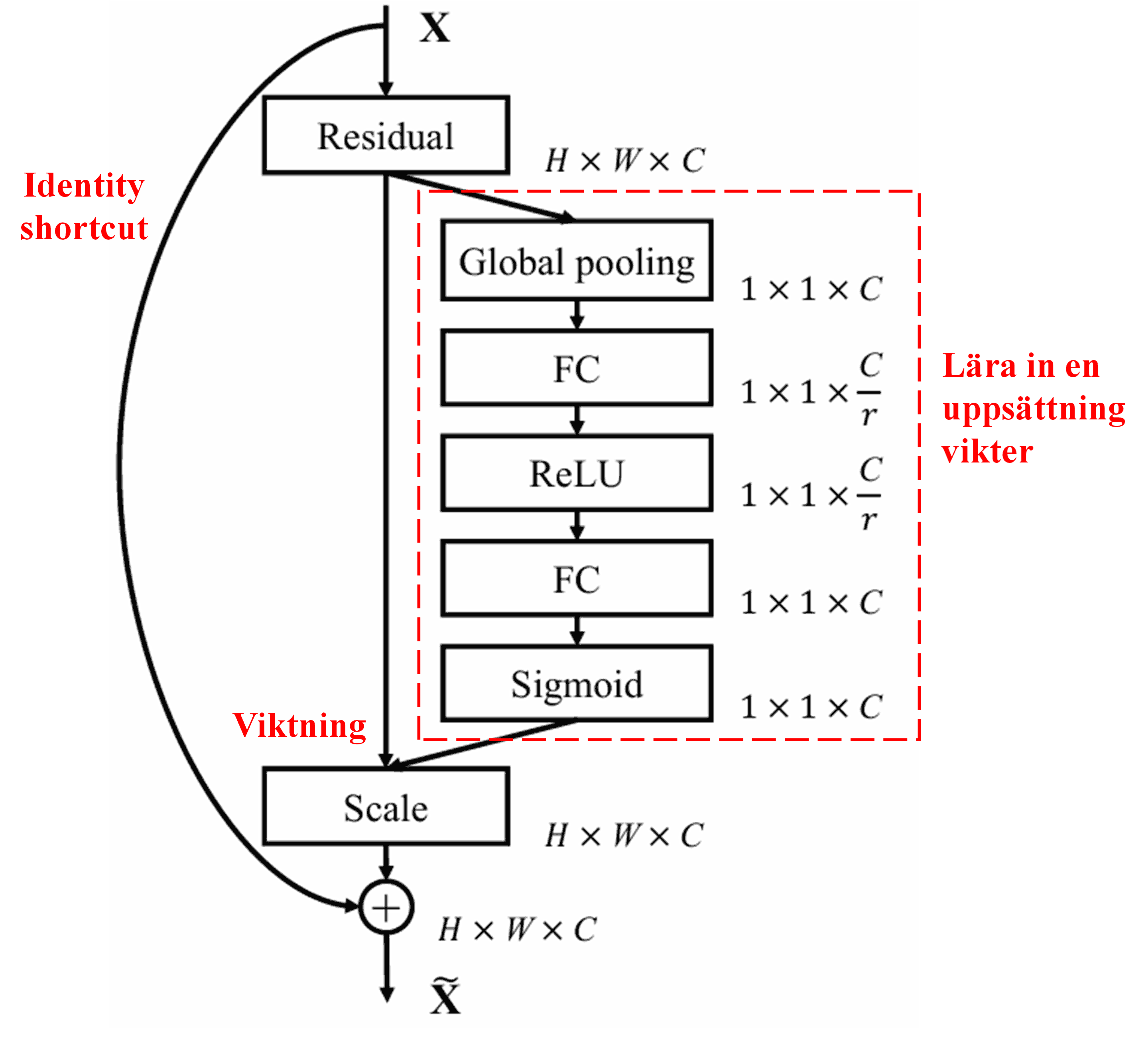
4. Soft Thresholding under en Djup Attention-mekanism
Deep Residual Shrinkage Network lånar strukturen från det ovannämnda SENet-subnätverket för att implementera soft thresholding under en djup attention-mekanism. Genom sub-nätverket (markerat inom den röda rutan i diagrammet) kan en uppsättning tröskelvärden läras in för att applicera soft thresholding på varje feature-kanal.
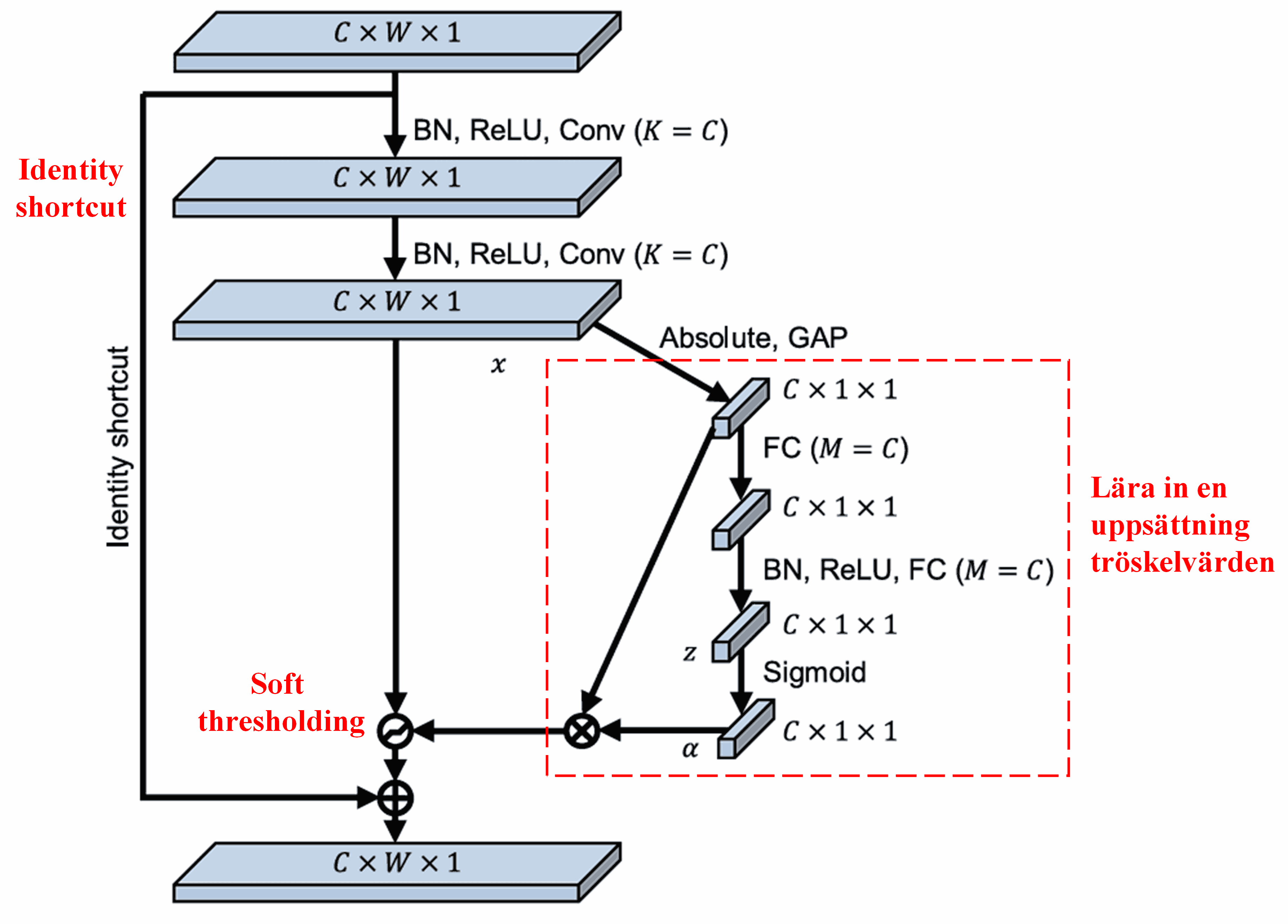
I detta sub-nätverk beräknas först absolutvärdet av alla features i input-feature-kartan. Därefter, genom Global Average Pooling och medelvärdesbildning, erhålls en feature som betecknas A. I den andra vägen matas feature-kartan (efter Global Average Pooling) in i ett litet Fully Connected-nätverk. Detta nätverk använder en Sigmoid-funktion som sitt sista lager för att normalisera outputen till mellan 0 och 1, vilket ger en koefficient som betecknas α. Det slutliga tröskelvärdet kan uttryckas som α × A. Tröskelvärdet är alltså produkten av ett tal mellan 0 och 1 och genomsnittet av absolutvärdena i feature-kartan. Denna metod garanterar att tröskelvärdet inte bara är positivt, utan inte heller för stort.
Dessutom resulterar olika dataexempel i olika tröskelvärden. Följaktligen kan detta till viss del tolkas som en specialiserad attention-mekanism: den identifierar features som är irrelevanta för den nuvarande uppgiften, omvandlar dem till värden nära noll via två faltningslager (convolutional layers), och sätter dem till noll via soft thresholding; alternativt identifierar den features som är relevanta för uppgiften, omvandlar dem till värden långt från noll via två faltningslager, och bevarar dem.
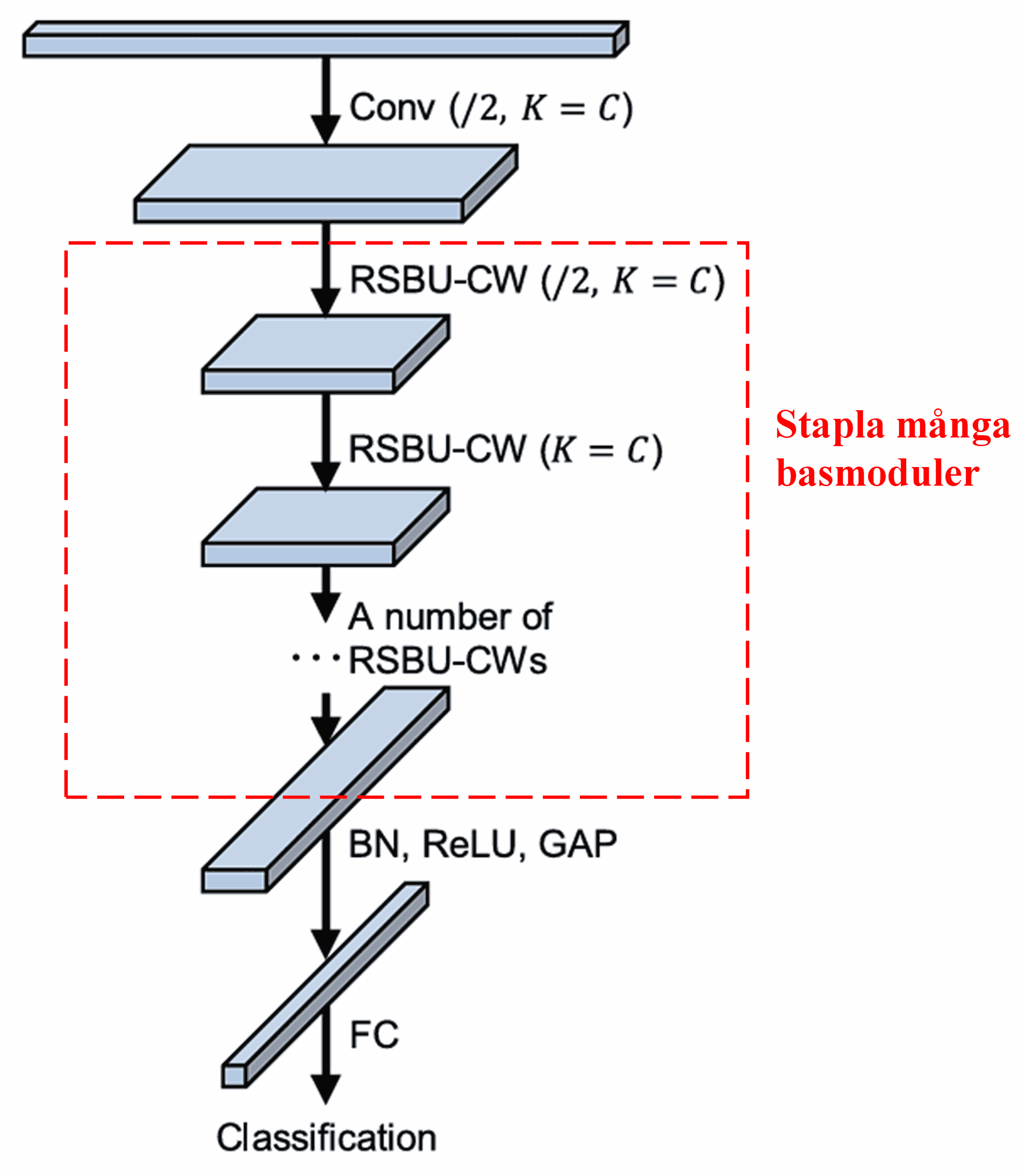
Slutligen, genom att stapla ett antal av dessa basmoduler tillsammans med faltningslager, Batch Normalization, aktiveringsfunktioner, Global Average Pooling och Fully Connected-utgångslager, konstrueras det kompletta Deep Residual Shrinkage Network.
5. Generaliseringsförmåga
Deep Residual Shrinkage Network är i själva verket en generell metod för feature-inlärning. Detta beror på att dataexempel i många inlärningsuppgifter mer eller mindre innehåller en del brus samt irrelevant information. Detta brus och denna irrelevanta information kan påverka resultatet av feature-inlärningen. Till exempel:
Vid bildklassificering: om en bild samtidigt innehåller många andra objekt, kan dessa objekt förstås som “brus”. Deep Residual Shrinkage Network kan potentiellt använda attention-mekanismen för att notera detta “brus” och sedan använda soft thresholding för att sätta de features som motsvarar detta “brus” till noll, vilket därmed kan förbättra precisionen i bildklassificeringen.
Vid taligenkänning: specifikt i relativt bullriga miljöer, såsom vid samtal vid en vägkant eller inne i en fabrikslokal, kan Deep Residual Shrinkage Network förbättra precisionen för taligenkänning, eller åtminstone erbjuda en metodik som kan förbättra precisionen.
Referenser
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Akademiskt inflytande
Denna artikel har fått över 1400 citeringar på Google Scholar.
Enligt ofullständig statistik har Deep Residual Shrinkage Networks (DRSN) använts i över 1000 publikationer. Dessa arbeten har antingen direkt tillämpat eller förbättrat nätverket inom ett brett spektrum av områden, inklusive maskinteknik, elkraft, datorseende (computer vision), sjukvård, talbehandling, textanalys, radar och fjärranalys.