Deep Residual Shrinkage Network (DRSN) er en forbedret variant af Deep Residual Network (ResNet). I bund og grund er det en integration af ResNet, attention mechanisms og soft thresholding-funktioner.
I en vis udstrækning kan DRSN’s virkemåde forstås således: Den bruger attention mechanisms til at identificere uvæsentlige features og anvender soft thresholding-funktioner til at sætte dem til nul. Omvendt identificeres og bevares vigtige features. Denne proces styrker det dybe neurale netværks evne til at udtrække brugbare features fra signaler, der indeholder støj.
1. Forskningsmotivation
For det første er støj uundgåelig, når man klassificerer samples – f.eks. Gaussisk støj, pink støj og Laplace-støj. Mere bredt betragtet indeholder samples ofte information, der er irrelevant for den aktuelle klassifikationsopgave, hvilket også kan tolkes som støj. Denne støj kan påvirke klassifikationsresultatet negativt. (Soft thresholding er et nøgletrin i mange algoritmer til signalstøjsreduktion).
For eksempel: Hvis man taler sammen ved en trafikeret vej, kan lyden af bilhorn og hjulstøj blande sig i samtalen. Når man udfører talegenkendelse på disse signaler, vil resultatet uundgåeligt blive påvirket af baggrundslydene. Set fra et Deep Learning-perspektiv bør de features, der svarer til bilhorn og hjulstøj, fjernes inde i det neurale netværk for at undgå, at de påvirker talegenkendelsen.
For det andet varierer mængden af støj ofte fra sample til sample, selv inden for samme datasæt. (Dette har lighedspunkter med attention mechanisms. Hvis vi tager et billeddatasæt som eksempel, kan placeringen af målobjektet variere fra billede til billede, og attention mechanisms kan fokusere på den specifikke placering i hvert enkelt billede).
Når man f.eks. træner en hunde/katte-klassifikator, kan man have 5 billeder med labelen “hund”. Det første billede indeholder måske både en hund og en mus, det andet en hund og en gås, det tredje en hund og en kylling, det fjerde en hund og et æsel, og det femte en hund og en and. Under træningen vil klassifikatoren uundgåeligt blive forstyrret af de irrelevante objekter (mus, gæs, kyllinger, æsler og ænder), hvilket fører til lavere præcision. Hvis vi kan identificere disse irrelevante objekter og fjerne deres tilhørende features, er det muligt at øge præcisionen af hunde/katte-klassifikatoren.
2. Soft Thresholding
Soft thresholding er et centralt trin i mange algoritmer til signalstøjsreduktion. Metoden fjerner features, hvis absolutte værdi er lavere end en bestemt tærskelværdi (threshold), og “krymper” features, hvis absolutte værdi er højere end denne tærskelværdi, mod nul. Det kan implementeres ved hjælp af følgende formel:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Den afledede af soft thresholding-outputtet i forhold til inputtet er:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Som det ses ovenfor, er den afledede af soft thresholding enten 1 eller 0. Denne egenskab er identisk med ReLU-aktiveringsfunktionen. Derfor kan soft thresholding også reducere risikoen for, at Deep Learning-algoritmer rammes af gradient vanishing og gradient exploding.
I soft thresholding-funktionen skal indstillingen af tærskelværdien (threshold) opfylde to betingelser: For det første skal tærskelværdien være et positivt tal. For det andet må tærskelværdien ikke overstige den maksimale værdi af inputsignalet, da outputtet ellers vil blive rent nul.
Samtidig er det bedst, hvis tærskelværdien opfylder en tredje betingelse: Hvert sample bør have sin egen uafhængige tærskelværdi baseret på dets eget støjniveau.
Dette skyldes, at indholdet af støj ofte varierer mellem samples. Det er f.eks. almindeligt i samme datasæt, at Sample A indeholder mindre støj, mens Sample B indeholder mere støj. Hvis man udfører soft thresholding i en støjreduktionsalgoritme, bør Sample A derfor bruge en mindre tærskelværdi, mens Sample B bør bruge en større. Selvom disse features og tærskelværdier mister deres eksplicitte fysiske betydning i dybe neurale netværk, gælder den grundlæggende logik stadig. Med andre ord: Hvert sample bør have sin egen uafhængige tærskelværdi bestemt af dets specifikke støjindhold.
3. Attention Mechanism
Attention mechanisms er relativt lette at forstå inden for Computer Vision. Dyrs visuelle system kan hurtigt scanne et helt område, finde målobjektet og derefter fokusere opmærksomheden på det for at udtrække flere detaljer, samtidig med at irrelevant information undertrykkes. For detaljer henvises til litteratur om attention mechanisms.
Squeeze-and-Excitation Network (SENet) er en nyere Deep Learning-metode, der benytter attention mechanisms. På tværs af forskellige samples varierer bidraget fra forskellige feature channels ofte i forhold til klassifikationsopgaven. SENet bruger et lille under-netværk (sub-network) til at beregne et sæt vægte. Disse vægte ganges derefter med de respektive channels’ features for at justere størrelsen af features i hver channel. Denne proces kan ses som at påføre forskellige niveauer af opmærksomhed (attention) på de forskellige feature channels.
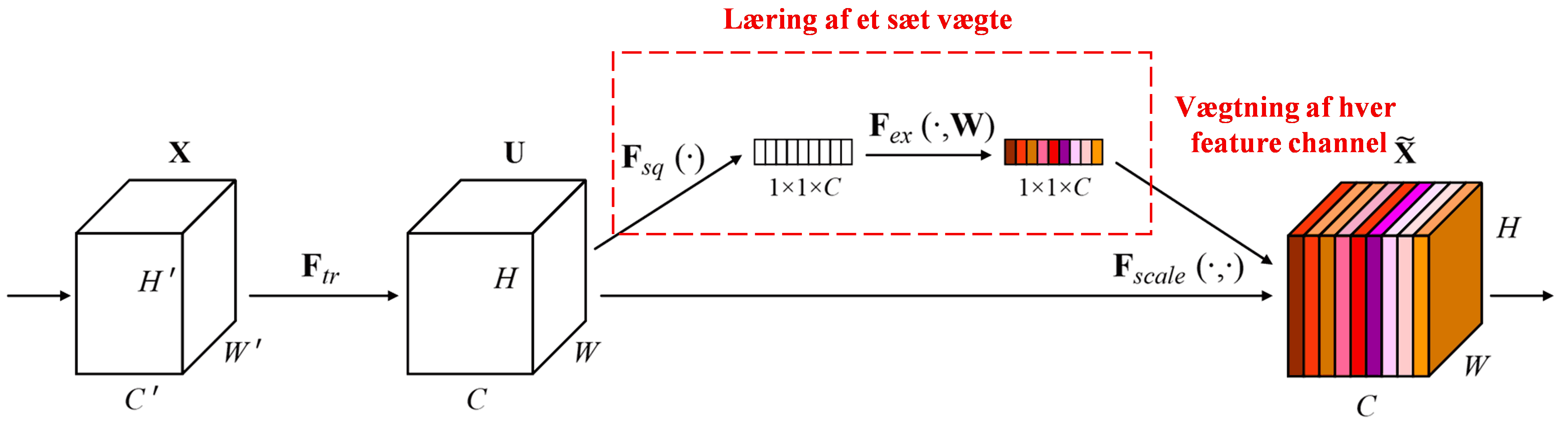
På denne måde får hvert sample sit eget uafhængige sæt vægte. Med andre ord er vægtene for to vilkårlige samples forskellige. I SENet er den specifikke sti til at opnå vægte: “Global Pooling → Fully Connected layer → ReLU-funktion → Fully Connected layer → Sigmoid-funktion”.
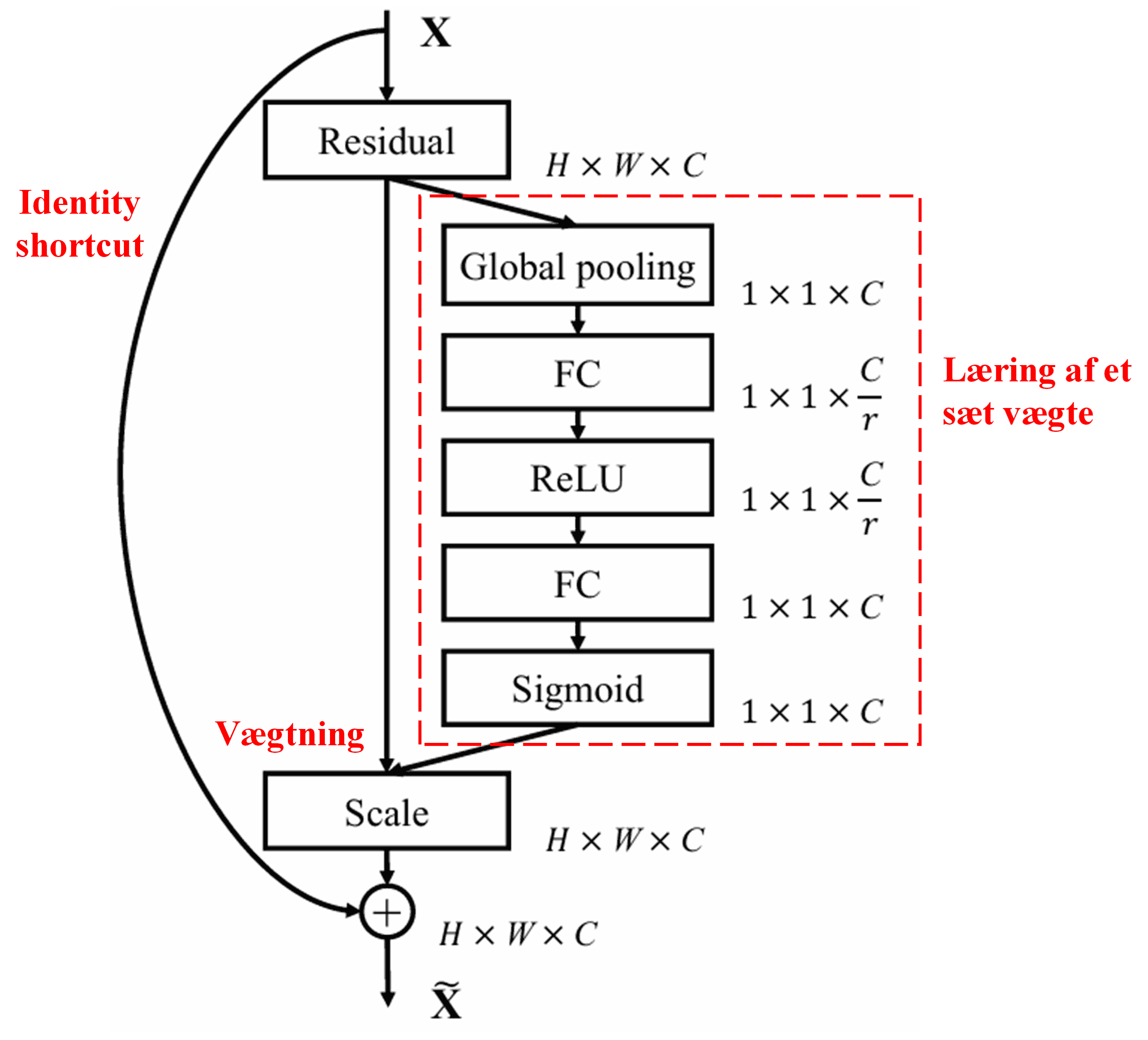
4. Soft Thresholding under Deep Attention Mechanism
Deep Residual Shrinkage Network er inspireret af den ovennævnte SENet-struktur for at implementere soft thresholding under en deep attention mechanism. Gennem under-netværket (markeret med den røde boks i diagrammer) kan der læres et sæt tærskelværdier til at udføre soft thresholding på hver enkelt feature channel.
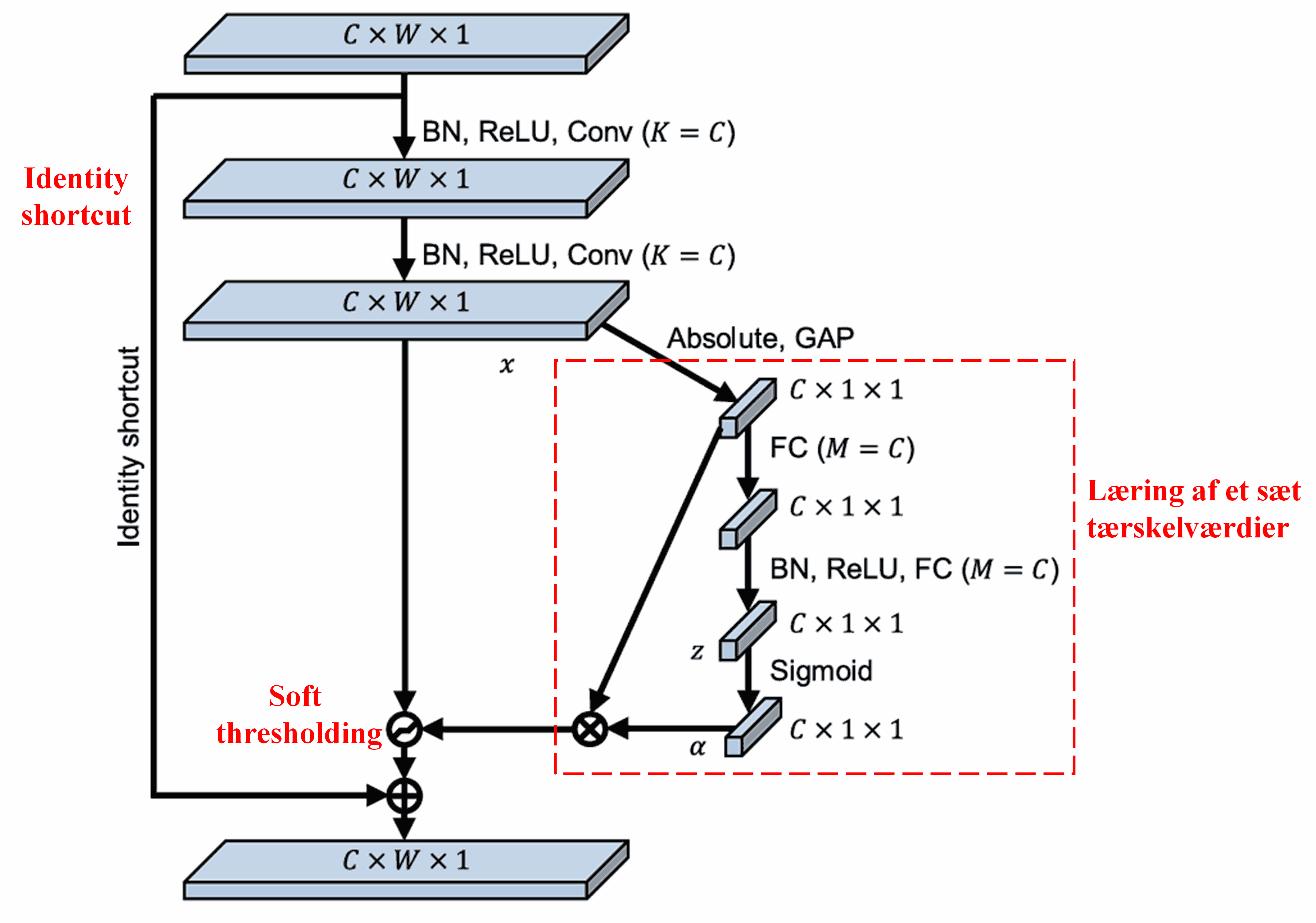
I dette sub-network beregnes først den absolutte værdi af alle features i input-feature mappet. Derefter opnås en feature, betegnet som A, gennem Global Average Pooling (gennemsnitsberegning). I den anden sti sendes feature mappet efter Global Average Pooling ind i et lille Fully Connected netværk. Dette netværk bruger en Sigmoid-funktion som sit sidste lag til at normalisere outputtet til mellem 0 og 1, hvilket giver en koefficient betegnet som α. Den endelige tærskelværdi kan udtrykkes som α × A. Tærskelværdien er altså produktet af et tal mellem 0 og 1 og gennemsnittet af de absolutte værdier af feature mappet. Denne metode sikrer, at tærskelværdien ikke kun er positiv, men heller ikke bliver for stor.
Desuden får forskellige samples forskellige tærskelværdier. I en vis forstand kan dette forstås som en specialiseret attention mechanism: Den bemærker features, der er irrelevante for den aktuelle opgave, transformerer dem til værdier tæt på nul via to convolutional layers og sætter dem til nul ved hjælp af soft thresholding. Alternativt bemærker den features, der er relevante for opgaven, transformerer dem til værdier langt fra nul og bevarer dem.
Til sidst, ved at stakke et vist antal basismoduler sammen med convolutional layers, Batch Normalization, aktiveringsfunktioner, Global Average Pooling og Fully Connected output layers, opnås det komplette Deep Residual Shrinkage Network.
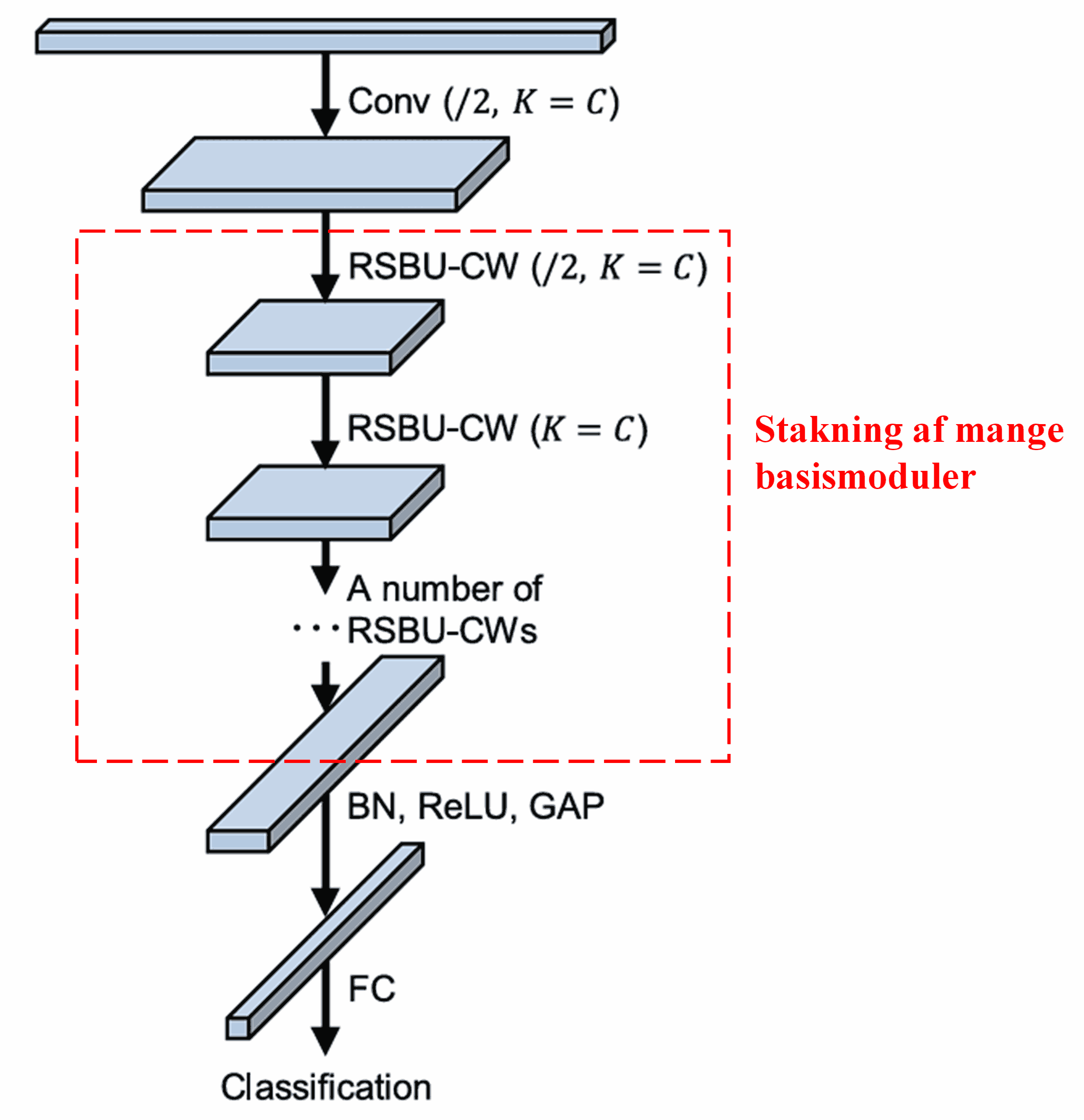
5. Anvendelighed
Deep Residual Shrinkage Network er faktisk en generel metode til feature learning. Det skyldes, at samples i mange feature learning-opgaver i større eller mindre grad indeholder støj og irrelevant information. Denne støj kan påvirke læringen negativt. For eksempel:
Ved billedklassificering: Hvis et billede samtidig indeholder mange andre objekter, kan disse objekter forstås som “støj”. Deep Residual Shrinkage Network kan muligvis bruge attention-mekanismen til at bemærke denne “støj” og derefter bruge soft thresholding til at sætte de features, der svarer til “støjen”, til nul. Dette kan potentielt øge præcisionen af billedklassificeringen.
Ved talegenkendelse: Især i miljøer med meget støj, såsom ved en vej eller i en fabrikshal, kan Deep Residual Shrinkage Network muligvis forbedre nøjagtigheden af talegenkendelsen – eller i det mindste tilbyde en metode, der kan forbedre den.
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Akademisk Indflydelse
Artiklen har modtaget over 1400 citationer på Google Scholar.
Ifølge konservative estimater er Deep Residual Shrinkage Networks (DRSN) blevet anvendt i mere end 1000 publikationer. Disse arbejder har enten anvendt netværket direkte eller forbedret det til brug inden for en lang række områder, herunder maskinteknik, el-forsyning, computer vision, sundhedssektoren, talebehandling, tekstanalyse, radar og remote sensing.