Το Deep Residual Shrinkage Network αποτελεί μια βελτιωμένη εκδοχή του Deep Residual Network. Στην ουσία, είναι ένας συνδυασμός (integration) των Deep Residual Networks, των μηχανισμών προσοχής (attention mechanisms) και των συναρτήσεων soft thresholding.
Σε έναν βαθμό, η αρχή λειτουργίας του Deep Residual Shrinkage Network μπορεί να γίνει αντιληπτή ως εξής: χρησιμοποιεί τον μηχανισμό προσοχής για να εντοπίσει τα ασήμαντα χαρακτηριστικά και, μέσω της συνάρτησης soft thresholding, τα μηδενίζει. Αντίστροφα, εντοπίζει τα σημαντικά χαρακτηριστικά και τα διατηρεί. Αυτή η διαδικασία ενισχύει την ικανότητα του βαθιού νευρωνικού δικτύου (deep neural network) να εξάγει χρήσιμα χαρακτηριστικά από σήματα που περιέχουν θόρυβο.
1. Κίνητρο Έρευνας
Πρώτον, κατά την ταξινόμηση δειγμάτων, είναι αναπόφευκτο να υπάρχει θόρυβος, όπως Γκαουσιανός θόρυβος (Gaussian noise), ροζ θόρυβος (pink noise) και θόρυβος Laplace. Με μια ευρύτερη έννοια, τα δείγματα συχνά περιέχουν πληροφορίες που δεν σχετίζονται με την τρέχουσα εργασία ταξινόμησης, οι οποίες μπορούν επίσης να θεωρηθούν ως θόρυβος. Αυτός ο θόρυβος μπορεί να επηρεάσει αρνητικά την απόδοση της ταξινόμησης. (Η τεχνική του soft thresholding αποτελεί βασικό βήμα σε πολλούς αλγορίθμους μείωσης θορύβου σημάτων).
Για παράδειγμα, κατά τη διάρκεια μιας συζήτησης στην άκρη του δρόμου, ο ήχος της ομιλίας μπορεί να αναμιχθεί με ήχους από κόρνες αυτοκινήτων, ρόδες κ.λπ. Όταν πραγματοποιείται αναγνώριση ομιλίας σε αυτά τα σήματα, το αποτέλεσμα θα επηρεαστεί αναπόφευκτα από αυτούς τους ήχους. Από την πλευρά του Deep Learning, τα χαρακτηριστικά που αντιστοιχούν στις κόρνες και τις ρόδες θα πρέπει να εξαλειφθούν μέσα στο νευρωνικό δίκτυο, ώστε να αποφευχθεί η αρνητική επίδραση στην αναγνώριση ομιλίας.
Δεύτερον, ακόμη και μέσα στο ίδιο σύνολο δεδομένων (dataset), η ποσότητα του θορύβου διαφέρει συχνά από δείγμα σε δείγμα. (Αυτό έχει κοινά στοιχεία με τον μηχανισμό προσοχής. Για παράδειγμα, σε ένα dataset εικόνων, η θέση του αντικειμένου-στόχου μπορεί να διαφέρει μεταξύ των εικόνων και ο μηχανισμός προσοχής μπορεί να εστιάσει στη συγκεκριμένη θέση του στόχου σε κάθε εικόνα).
Για παράδειγμα, κατά την εκπαίδευση ενός ταξινομητή “γάτας-σκύλου”, ας υποθέσουμε ότι έχουμε 5 εικόνες με την ετικέτα “σκύλος”. Η 1η εικόνα μπορεί να περιέχει έναν σκύλο και ένα ποντίκι, η 2η έναν σκύλο και μια χήνα, η 3η έναν σκύλο και μια κότα, η 4η έναν σκύλο και ένα γαϊδούρι, και η 5η έναν σκύλο και μια πάπια. Όταν εκπαιδεύουμε τον ταξινομητή, αναπόφευκτα θα υπάρξουν παρεμβολές από άσχετα αντικείμενα (ποντίκια, χήνες, κότες κ.λπ.), προκαλώντας μείωση στην ακρίβεια ταξινόμησης. Εάν μπορούσαμε να εντοπίσουμε αυτά τα άσχετα αντικείμενα και να διαγράψουμε τα αντίστοιχα χαρακτηριστικά τους, θα ήταν δυνατό να αυξήσουμε την ακρίβεια του ταξινομητή.
2. Soft Thresholding
Το soft thresholding είναι ένα βασικό βήμα σε πολλούς αλγορίθμους μείωσης θορύβου σημάτων. Διαγράφει χαρακτηριστικά των οποίων η απόλυτη τιμή είναι μικρότερη από ένα συγκεκριμένο κατώφλι (threshold) και “συρρικνώνει” (shrinks) προς το μηδέν τα χαρακτηριστικά που είναι μεγαλύτερα από αυτό το κατώφλι. Μπορεί να υλοποιηθεί μέσω του ακόλουθου τύπου:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Η παράγωγος της εξόδου του soft thresholding ως προς την είσοδο είναι:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Όπως φαίνεται παραπάνω, η παράγωγος του soft thresholding είναι είτε 1 είτε 0. Αυτή η ιδιότητα είναι ίδια με αυτή της συνάρτησης ενεργοποίησης ReLU. Επομένως, το soft thresholding μπορεί επίσης να μειώσει τον κίνδυνο εμφάνισης προβλημάτων όπως το gradient vanishing και gradient exploding στους αλγορίθμους Deep Learning.
Στη συνάρτηση soft thresholding, ο καθορισμός του κατωφλίου (threshold) πρέπει να πληροί δύο προϋποθέσεις: Πρώτον, το κατώφλι πρέπει να είναι θετικός αριθμός. Δεύτερον, το κατώφλι δεν πρέπει να είναι μεγαλύτερο από τη μέγιστη τιμή του σήματος εισόδου, διαφορετικά η έξοδος θα είναι εξ ολοκλήρου μηδενική.
Ταυτόχρονα, είναι προτιμότερο το κατώφλι να πληροί και μια τρίτη προϋπόθεση: κάθε δείγμα θα πρέπει να έχει το δικό του ανεξάρτητο κατώφλι, ανάλογα με την ποσότητα θορύβου που περιέχει.
Αυτό συμβαίνει επειδή το περιεχόμενο θορύβου είναι συχνά διαφορετικό. Για παράδειγμα, στο ίδιο dataset, το Δείγμα Α μπορεί να έχει λιγότερο θόρυβο, ενώ το Δείγμα Β περισσότερο. Έτσι, κατά την εφαρμογή του soft thresholding, το Δείγμα Α θα πρέπει να χρησιμοποιεί μικρότερο κατώφλι, ενώ το Δείγμα Β μεγαλύτερο. Στα βαθιά νευρωνικά δίκτυα, αν και αυτά τα χαρακτηριστικά και τα κατώφλια χάνουν τη σαφή φυσική τους σημασία, η βασική λογική παραμένει η ίδια. Δηλαδή, κάθε δείγμα πρέπει να έχει το δικό του κατώφλι προσαρμοσμένο στον θόρυβό του.
3. Μηχανισμός Προσοχής (Attention Mechanism)
Οι μηχανισμοί προσοχής είναι σχετικά εύκολα κατανοητοί στον τομέα της Υπολογιστικής Όρασης (Computer Vision). Το οπτικό σύστημα των ζώων μπορεί να σαρώσει γρήγορα ολόκληρη την περιοχή, να εντοπίσει το αντικείμενο-στόχο και στη συνέχεια να εστιάσει την προσοχή του σε αυτό για να εξάγει περισσότερες λεπτομέρειες, καταστέλλοντας ταυτόχρονα τις άσχετες πληροφορίες. Για λεπτομέρειες, παρακαλούμε ανατρέξτε στη βιβλιογραφία σχετικά με το Attention Mechanism.
Το Squeeze-and-Excitation Network (SENet) είναι μια σχετικά νέα μέθοδος Deep Learning που χρησιμοποιεί μηχανισμούς προσοχής. Σε διαφορετικά δείγματα, η συνεισφορά των διαφορετικών καναλιών χαρακτηριστικών (feature channels) στην εργασία ταξινόμησης είναι συχνά διαφορετική. Το SENet χρησιμοποιεί ένα μικρό υπο-δίκτυο (sub-network) για να λάβει ένα σύνολο βαρών (weights) και στη συνέχεια πολλαπλασιάζει αυτά τα βάρη με τα χαρακτηριστικά των αντίστοιχων καναλιών, ώστε να προσαρμόσει το μέγεθος των χαρακτηριστικών σε κάθε κανάλι. Αυτή η διαδικασία μπορεί να θεωρηθεί ως εφαρμογή διαφορετικών επιπέδων προσοχής σε διαφορετικά κανάλια χαρακτηριστικών.
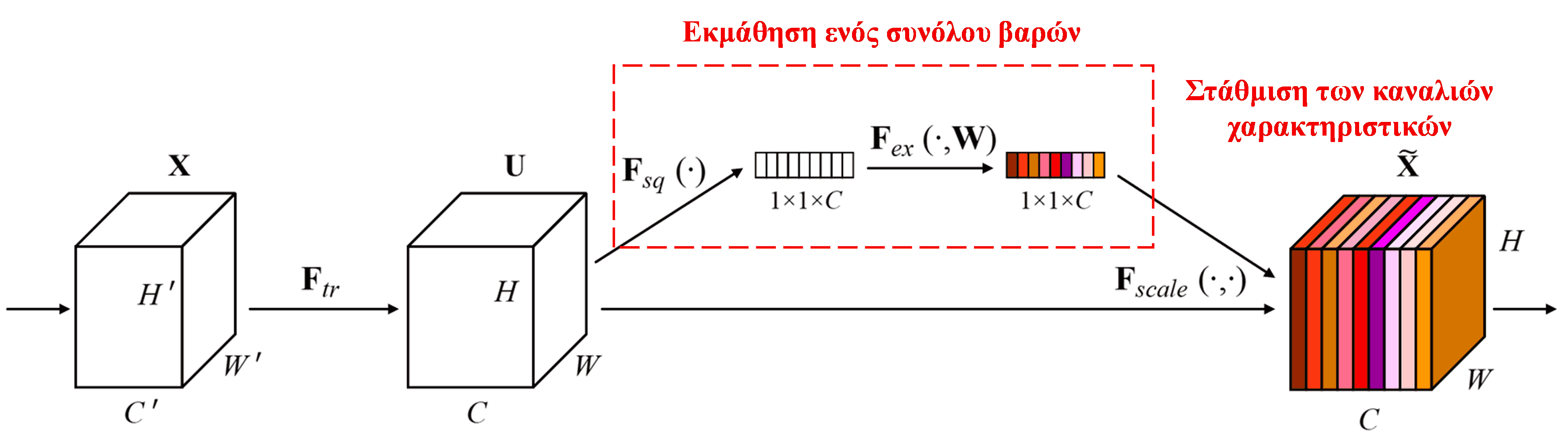
Με αυτόν τον τρόπο, κάθε δείγμα έχει το δικό του ανεξάρτητο σύνολο βαρών. Με άλλα λόγια, τα βάρη για οποιαδήποτε δύο δείγματα είναι διαφορετικά. Στο SENet, η συγκεκριμένη διαδρομή για την απόκτηση των βαρών είναι “Global Pooling → Fully Connected Layer → ReLU → Fully Connected Layer → Sigmoid”.
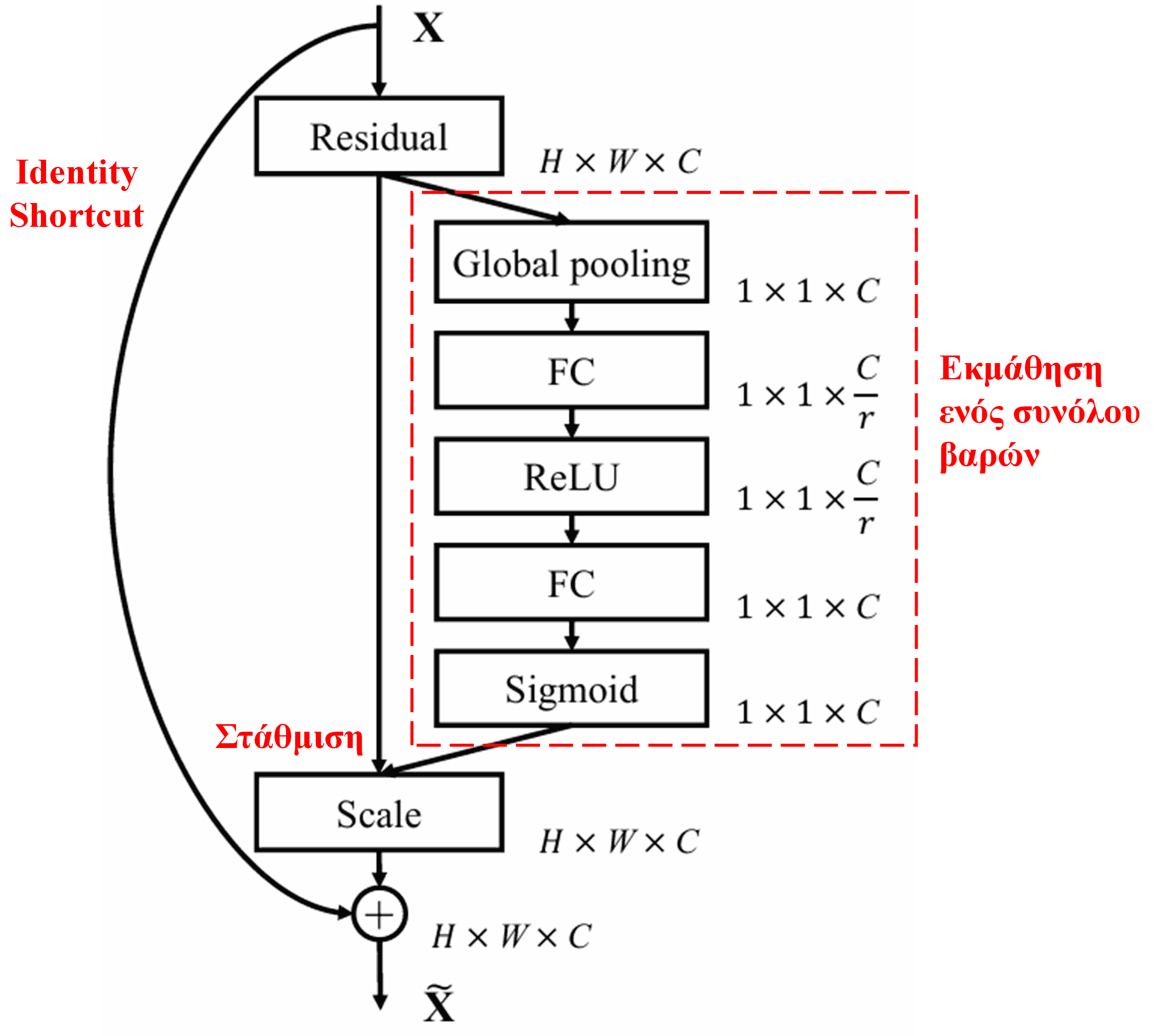
4. Soft Thresholding υπό το πρίσμα του Deep Attention Mechanism
Το Deep Residual Shrinkage Network δανείζεται τη δομή του υπο-δικτύου του SENet που αναφέρθηκε παραπάνω, για να εφαρμόσει το soft thresholding υπό έναν βαθύ μηχανισμό προσοχής. Μέσω του υπο-δικτύου μέσα στο κόκκινο πλαίσιο (στο διάγραμμα της αρχιτεκτονικής), μπορεί να μαθευτεί ένα σύνολο κατωφλίων για την εφαρμογή soft thresholding σε κάθε κανάλι χαρακτηριστικών.
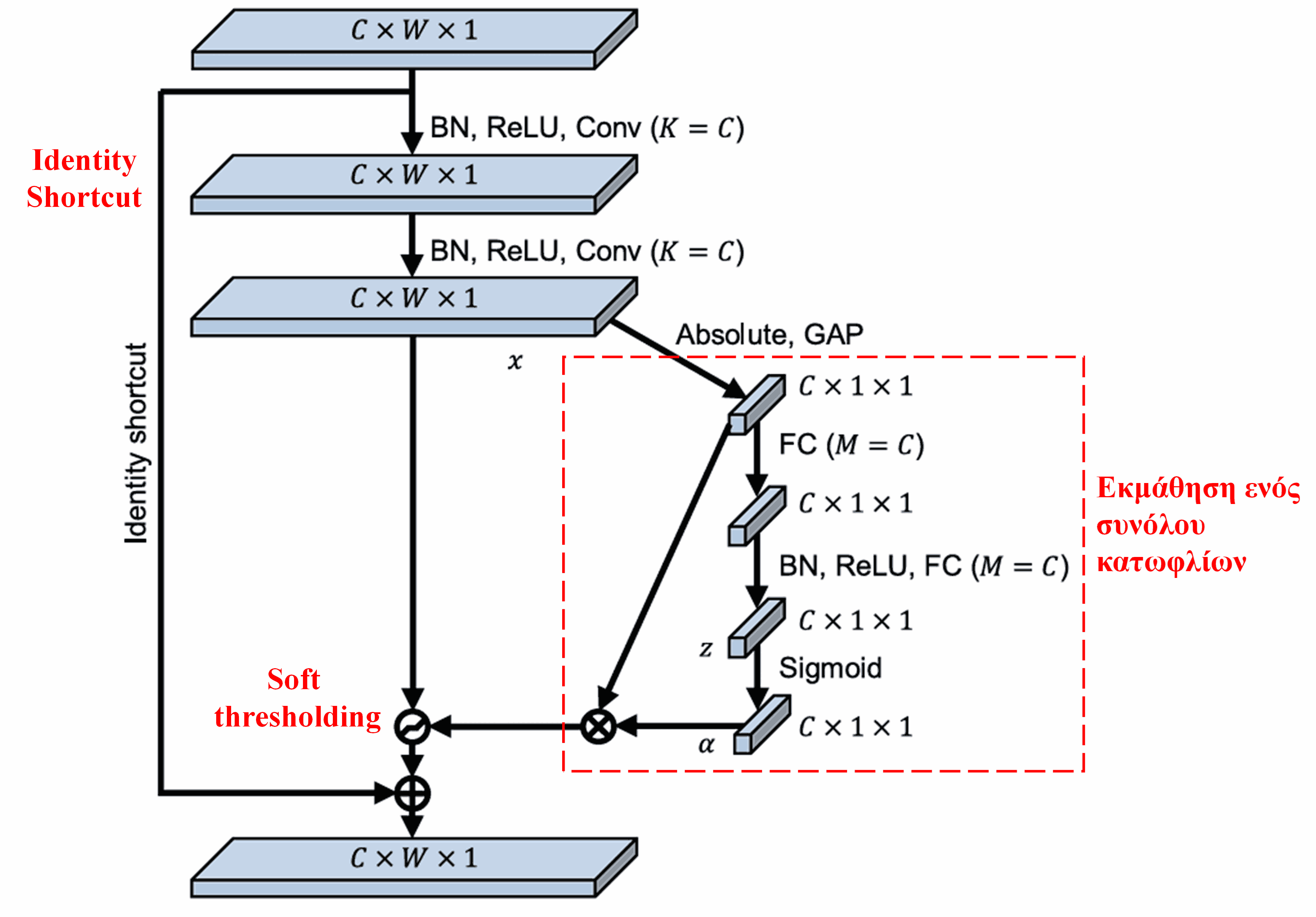
Σε αυτό το υπο-δίκτυο, αρχικά υπολογίζεται η απόλυτη τιμή όλων των χαρακτηριστικών στον χάρτη χαρακτηριστικών εισόδου (input feature map). Στη συνέχεια, μέσω του global average pooling και της μέσης τιμής, λαμβάνεται ένα χαρακτηριστικό, το οποίο συμβολίζουμε ως A. Στο άλλο μονοπάτι, ο χάρτης χαρακτηριστικών μετά το global average pooling εισάγεται σε ένα μικρό πλήρως συνδεδεμένο δίκτυο (fully connected network). Αυτό το δίκτυο χρησιμοποιεί τη συνάρτηση Sigmoid ως το τελευταίο επίπεδο για να κανονικοποιήσει την έξοδο μεταξύ 0 και 1, λαμβάνοντας έναν συντελεστή, τον οποίο συμβολίζουμε ως α. Το τελικό κατώφλι μπορεί να εκφραστεί ως α×A. Επομένως, το κατώφλι είναι το γινόμενο ενός αριθμού μεταξύ 0 και 1 και του μέσου όρου των απόλυτων τιμών του χάρτη χαρακτηριστικών. Αυτή η μέθοδος εξασφαλίζει ότι το κατώφλι δεν είναι μόνο θετικό, αλλά και όχι υπερβολικά μεγάλο.
Επιπλέον, διαφορετικά δείγματα οδηγούν σε διαφορετικά κατώφλια. Συνεπώς, σε έναν βαθμό, αυτό μπορεί να γίνει κατανοητό ως ένας ειδικός μηχανισμός προσοχής: παρατηρεί τα χαρακτηριστικά που είναι άσχετα με την τρέχουσα εργασία, τα μετατρέπει σε τιμές κοντά στο 0 μέσω δύο συνελικτικών επιπέδων (convolutional layers) και τα μηδενίζει μέσω του soft thresholding. Ή αλλιώς, παρατηρεί τα χαρακτηριστικά που σχετίζονται με την τρέχουσα εργασία και τα διατηρεί.
Τέλος, στοιβάζοντας έναν συγκεκριμένο αριθμό βασικών δομικών μονάδων μαζί με convolutional layers, Batch Normalization, συναρτήσεις ενεργοποίησης, Global Average Pooling και πλήρως συνδεδεμένα επίπεδα εξόδου, λαμβάνουμε το πλήρες Deep Residual Shrinkage Network.
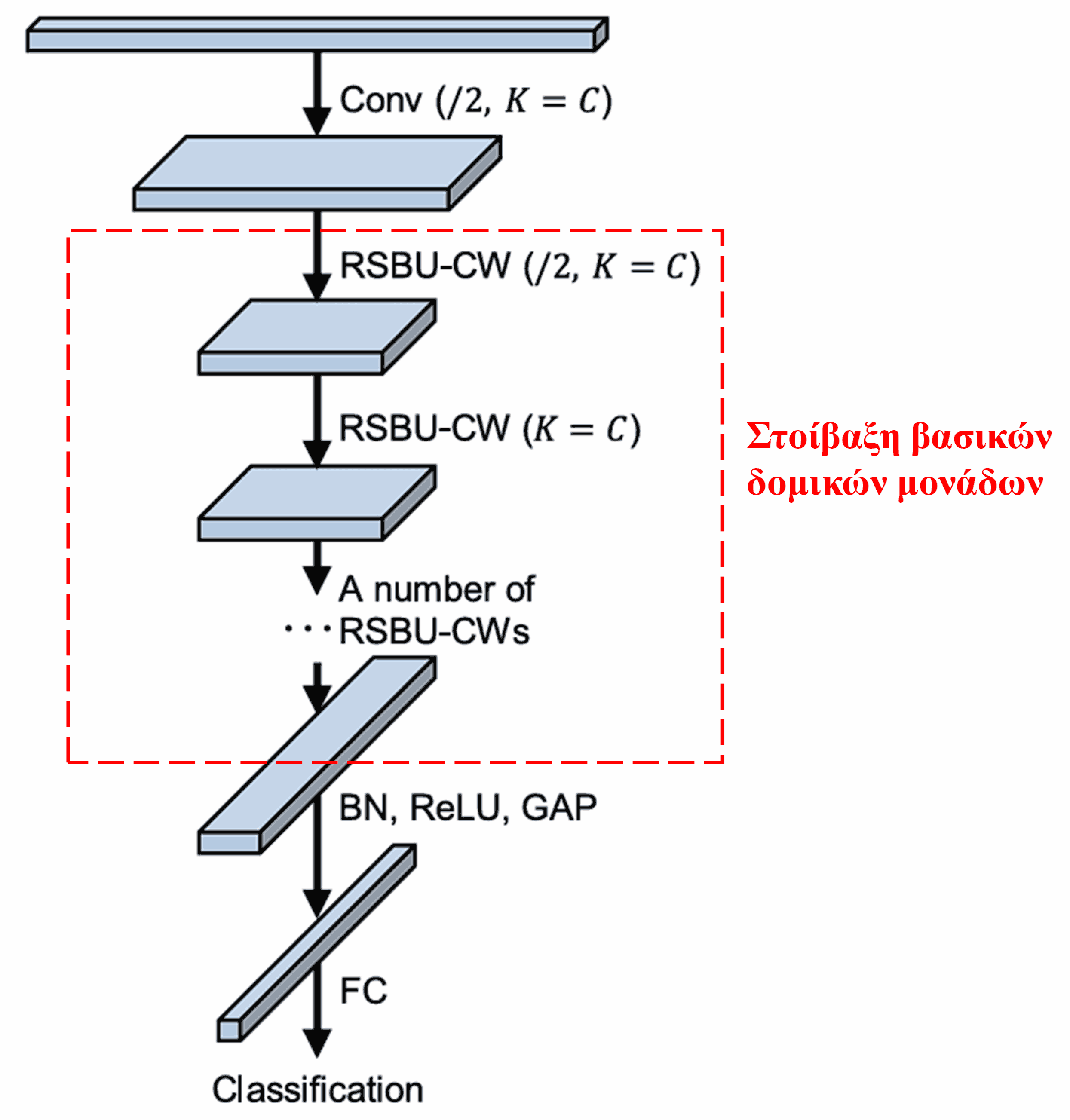
5. Γενικευσιμότητα
Το Deep Residual Shrinkage Network είναι στην πραγματικότητα μια γενική μέθοδος εκμάθησης χαρακτηριστικών (feature learning method). Αυτό συμβαίνει επειδή σε πολλές εργασίες εκμάθησης χαρακτηριστικών, τα δείγματα περιέχουν λίγο πολύ θόρυβο, καθώς και άσχετες πληροφορίες. Αυτός ο θόρυβος και οι άσχετες πληροφορίες μπορεί να επηρεάσουν την αποτελεσματικότητα της μάθησης. Για παράδειγμα:
Στην ταξινόμηση εικόνας, εάν μια εικόνα περιέχει ταυτόχρονα πολλά άλλα αντικείμενα, αυτά μπορούν να θεωρηθούν ως “θόρυβος”. Το Deep Residual Shrinkage Network ίσως μπορέσει να αξιοποιήσει τον μηχανισμό προσοχής για να παρατηρήσει αυτόν τον “θόρυβο” και στη συνέχεια, μέσω του soft thresholding, να μηδενίσει τα χαρακτηριστικά που αντιστοιχούν σε αυτόν, αυξάνοντας έτσι την ακρίβεια ταξινόμησης.
Στην αναγνώριση ομιλίας, ειδικά σε περιβάλλοντα με έντονο θόρυβο, όπως δίπλα στον δρόμο ή μέσα σε ένα εργοστάσιο, το Deep Residual Shrinkage Network ίσως μπορέσει να βελτιώσει την ακρίβεια της αναγνώρισης ή τουλάχιστον να προσφέρει μια μεθοδολογία για τη βελτίωσή της.
Βιβλιογραφία
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Ακαδημαϊκή Επιρροή
Οι αναφορές της εργασίας στο Google Scholar έχουν ξεπεράσει τις 1400.
Σύμφωνα με ελλιπή στατιστικά στοιχεία, τα Deep Residual Shrinkage Networks έχουν εφαρμοστεί άμεσα ή βελτιωθεί σε περισσότερες από 1000 δημοσιεύσεις σε πολλούς τομείς, όπως η μηχανολογία, η ηλεκτρική ενέργεια, η υπολογιστική όραση, η ιατρική, η επεξεργασία φωνής και κειμένου, τα ραντάρ και η τηλεπισκόπηση.