Deep Residual Shrinkage Network হলো Deep Residual Network-এর একটি উন্নত সংস্করণ। এটি মূলত Deep Residual Network, Attention Mechanism এবং Soft Thresholding Function-এর একটি ইন্টিগ্রেশন বা সংমিশ্রণ।
সহজভাবে বলতে গেলে, Deep Residual Shrinkage Network-এর কাজের ধরন বা Working Principle এমন: এটি Attention Mechanism ব্যবহার করে অপ্রয়োজনীয় Feature-গুলোকে নোটিস (notice) করে এবং Soft Thresholding Function-এর মাধ্যমে সেগুলোকে জিরো (zero) করে দেয়। আবার উল্টোভাবে বললে, এটি গুরুত্বপূর্ণ Feature-গুলোকে চিহ্নিত করে সেগুলোকে ধরে রাখে। এর ফলে Noisy Signal থেকে কাজের Feature বা দরকারি তথ্য বের করে আনার ক্ষেত্রে Deep Neural Network-এর ক্ষমতা অনেক বেড়ে যায়।
1. Research Motivation (গবেষণার উদ্দেশ্য)
প্রথমত, যেকোনো স্যাম্পল (Sample) ক্লাসিফাই (Classify) করার সময় তাতে কিছু নয়েজ (Noise) থাকাটা স্বাভাবিক, যেমন Gaussian Noise, Pink Noise, Laplacian Noise ইত্যাদি। আরও বড় পরিসরে বলতে গেলে, স্যাম্পলের মধ্যে এমন অনেক তথ্য থাকতে পারে যা আমাদের বর্তমান টাস্কের (Task) সাথে সম্পর্কিত নয়—এগুলোকেও Noise হিসেবে ধরা যেতে পারে। এই Noise-গুলো ক্লাসিফিকেশনের ফলাফলের ওপর খারাপ প্রভাব ফেলতে পারে। (Soft Thresholding হলো অনেক Signal Denoising Algorithm-এর একটি মূল ধাপ।)
উদাহরণস্বরূপ, রাস্তার পাশে কথা বলার সময় কথার আওয়াজের সাথে গাড়ির হর্ন বা চাকার শব্দ মিশে যেতে পারে। এই সিগন্যালগুলো দিয়ে যখন Speech Recognition করা হয়, তখন হর্ন বা চাকার শব্দের কারণে রেজাল্ট খারাপ হতে পারে। Deep Learning-এর ভাষায় বললে, এই হর্ন বা চাকার শব্দের সাথে সম্পর্কিত Feature-গুলোকে Deep Neural Network-এর ভেতর থেকেই মুছে ফেলা উচিত, যাতে Speech Recognition-এর ফলাফলে কোনো সমস্যা না হয়।
দ্বিতীয়ত, একই ডেটাসেটের (Dataset) ভেতরেও বিভিন্ন স্যাম্পলে নয়েজের পরিমাণ আলাদা হতে পারে। (এর সাথে Attention Mechanism-এর মিল রয়েছে; যেমন একটি ইমেজের (Image) কালেকশনে একেকটি ছবিতে টার্গেট অবজেক্ট একেক জায়গায় থাকতে পারে; Attention Mechanism প্রতিটি ছবির জন্য আলাদাভাবে টার্গেট অবজেক্টের জায়গাটি খুঁজে বের করতে পারে।)
যেমন, একটি ক্যাট-ডগ (Cat-Dog) ক্লাসিফায়ার ট্রেইন করার সময়, “Dog” লেবেলের ৫টি ছবি নেওয়া হলো। ১ম ছবিতে কুকুরের সাথে ইঁদুর, ২য় ছবিতে কুকুরের সাথে রাজহাঁস, ৩য় ছবিতে মুরগি, ৪র্থ ছবিতে গাধা এবং ৫ম ছবিতে হাঁস থাকতে পারে। আমরা যখন ক্যাট-ডগ ক্লাসিফায়ার ট্রেইন করি, তখন এই ইঁদুর, রাজহাঁস, মুরগি, গাধা বা হাঁসের মতো অপ্রয়োজনীয় অবজেক্টগুলো ডিস্টার্ব করতে পারে এবং ক্লাসিফিকেশনের Accuracy কমিয়ে দিতে পারে। আমরা যদি এই অপ্রয়োজনীয় অবজেক্টগুলোকে নোটিস (notice) করতে পারি এবং এদের সাথে সম্পর্কিত Feature-গুলোকে মুছে ফেলতে পারি, তাহলে ক্যাট-ডগ ক্লাসিফায়ারের Accuracy বাড়ানো সম্ভব।
2. Soft Thresholding
Soft Thresholding হলো অনেক Signal Denoising Algorithm-এর একটি প্রধান ধাপ। এতে কোনো Feature-এর Absolute Value যদি একটি নির্দিষ্ট Threshold-এর চেয়ে কম হয়, তবে সেটিকে মুছে ফেলা হয়; আর যদি বেশি হয়, তবে সেটিকে জিরোর দিকে ‘Shrink’ বা সংকুচিত করা হয়। এটি নিচের ফর্মুলার মাধ্যমে ইমপ্লিমেন্ট করা যায়:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]ইনপুটের সাপেক্ষে Soft Thresholding-এর আউটপুটের ডেরিভেটিভ (Derivative) হলো:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]ওপরের সমীকরণ থেকে দেখা যায়, Soft Thresholding-এর ডেরিভেটিভ হয় ১ হবে, না হয় ০ হবে। এই বৈশিষ্ট্যটি ReLU Activation Function-এর মতোই। তাই, Soft Thresholding ব্যবহার করলে Deep Learning Algorithm-এ Gradient Vanishing এবং Gradient Exploding-এর ঝুঁকি কমে যায়।
Soft Thresholding ফাংশনে Threshold সেট করার সময় দুটি শর্ত মানতে হয়: প্রথমত, Threshold হতে হবে পজিটিভ (positive); দ্বিতীয়ত, Threshold-টি ইনপুট সিগন্যালের ম্যাক্সিমাম ভ্যালুর (Maximum Value) চেয়ে বড় হতে পারবে না, নইলে আউটপুট সব জিরো হয়ে যাবে।
একই সাথে, Threshold-টি তৃতীয় আরেকটি শর্ত মানলে সবচেয়ে ভালো হয়: প্রতিটি স্যাম্পলের নিজস্ব নয়েজ লেভেল অনুযায়ী তার নিজস্ব আলাদা Threshold থাকা উচিত।
এর কারণ হলো, সব স্যাম্পলে নয়েজের পরিমাণ সমান থাকে না। যেমন, একই ডেটাসেটে স্যাম্পল A-তে নয়েজ কম থাকতে পারে, আবার স্যাম্পল B-তে নয়েজ বেশি থাকতে পারে। তাই Denoising Algorithm-এ Soft Thresholding করার সময় স্যাম্পল A-এর জন্য ছোট Threshold এবং স্যাম্পল B-এর জন্য বড় Threshold ব্যবহার করা উচিত। Deep Neural Network-এ যদিও এই Feature এবং Threshold-এর ফিজিক্যাল অর্থ সবসময় পরিষ্কার থাকে না, কিন্তু মূল লজিকটা একই। অর্থাৎ, প্রতিটি স্যাম্পলের নিজস্ব নয়েজ কন্টেন্ট অনুযায়ী আলাদা আলাদা Threshold থাকা উচিত।
3. Attention Mechanism
Computer Vision-এর ক্ষেত্রে Attention Mechanism বোঝা বেশ সহজ। প্রাণীদের ভিশন সিস্টেম খুব দ্রুত পুরো এলাকা স্ক্যান করে টার্গেট অবজেক্ট খুঁজে বের করতে পারে এবং অন্য অপ্রয়োজনীয় তথ্য বাদ দিয়ে শুধু টার্গেটের ওপর মনোযোগ বা ‘Attention’ দিতে পারে। বিস্তারিত জানার জন্য Attention Mechanism নিয়ে লেখা অন্যান্য আর্টিকেল দেখতে পারেন।
Squeeze-and-Excitation Network (SENet) হলো Attention Mechanism-ভিত্তিক একটি আধুনিক Deep Learning মেথড। ক্লাসিফিকেশন টাস্কে বিভিন্ন স্যাম্পলের জন্য বিভিন্ন Feature Channel-এর গুরুত্ব বা কন্ট্রিবিউশন আলাদা হয়। SENet একটি ছোট সাব-নেটওয়ার্ক (Sub-network) ব্যবহার করে এক সেট Weight তৈরি করে। এরপর এই Weight-গুলো দিয়ে প্রতিটি চ্যানেলের Feature-কে গুণ করা হয়। এই পুরো প্রক্রিয়াটিকে বিভিন্ন Feature Channel-এর ওপর বিভিন্ন মাত্রার Attention দেওয়া হিসেবে গণ্য করা যেতে পারে।
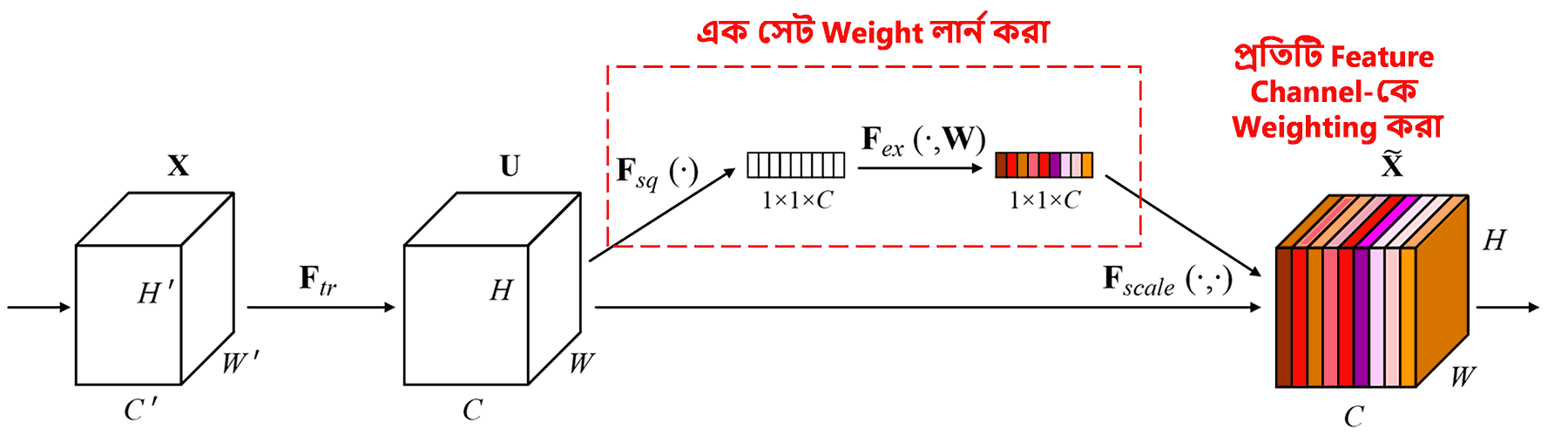
এই পদ্ধতিতে, প্রতিটি স্যাম্পলের জন্য আলাদা আলাদা Weight তৈরি হয়। অন্য কথায়, যেকোনো দুটি স্যাম্পলের Weight আলাদা হবে। SENet-এ এই Weight পাওয়ার পথটি হলো: “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”।
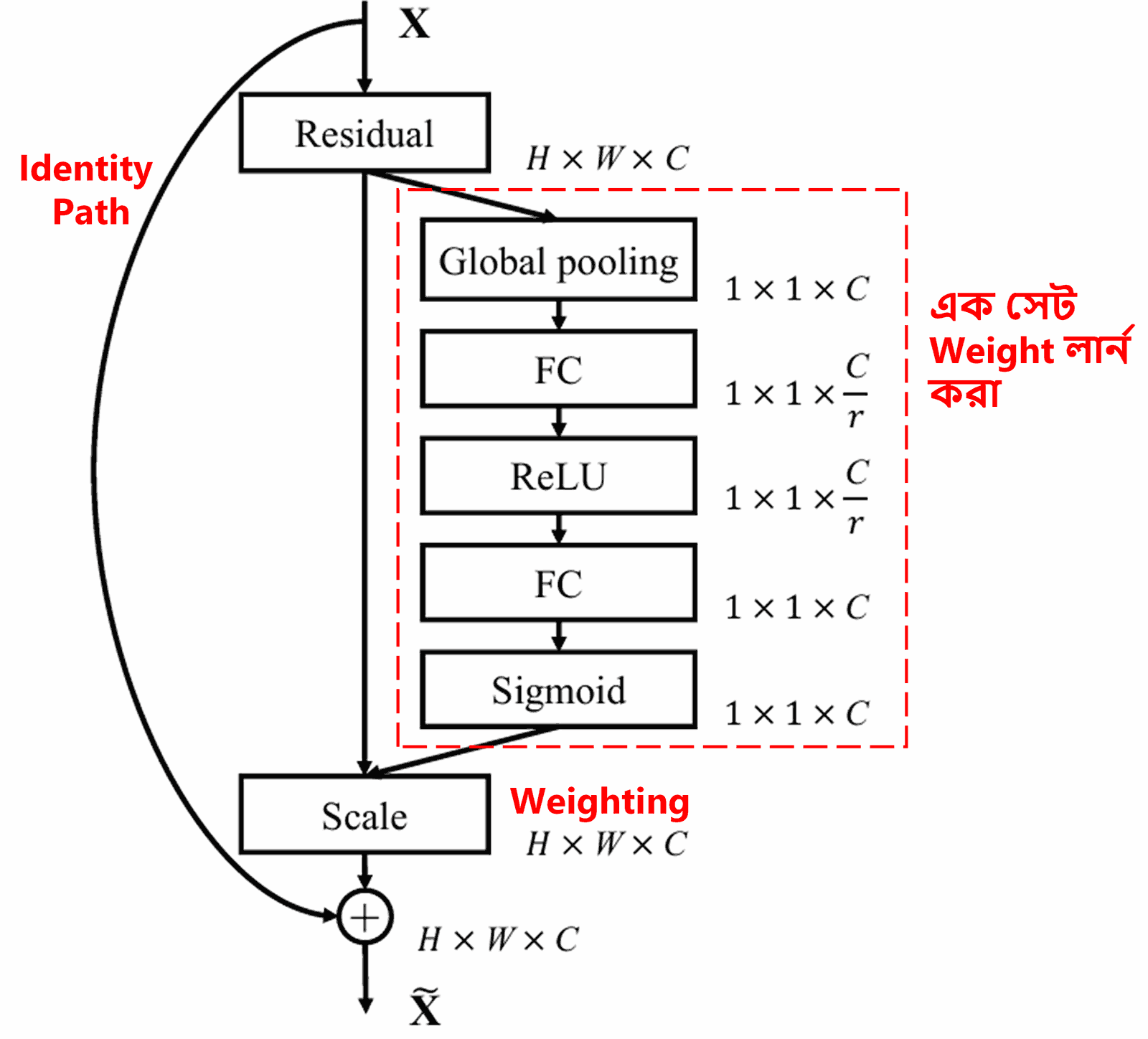
4. Deep Attention Mechanism-এর মাধ্যমে Soft Thresholding
Deep Residual Shrinkage Network মূলত ওপরের SENet-এর সাব-নেটওয়ার্ক স্ট্রাকচারটি ব্যবহার করে Deep Attention Mechanism-এর অধীনে Soft Thresholding বাস্তবায়ন করে। লাল বক্সের ভেতরের সাব-নেটওয়ার্কটির মাধ্যমে এক সেট Threshold লার্ন (learn) করা হয়, যা দিয়ে প্রতিটি Feature Channel-এ Soft Thresholding অ্যাপ্লাই করা হয়।
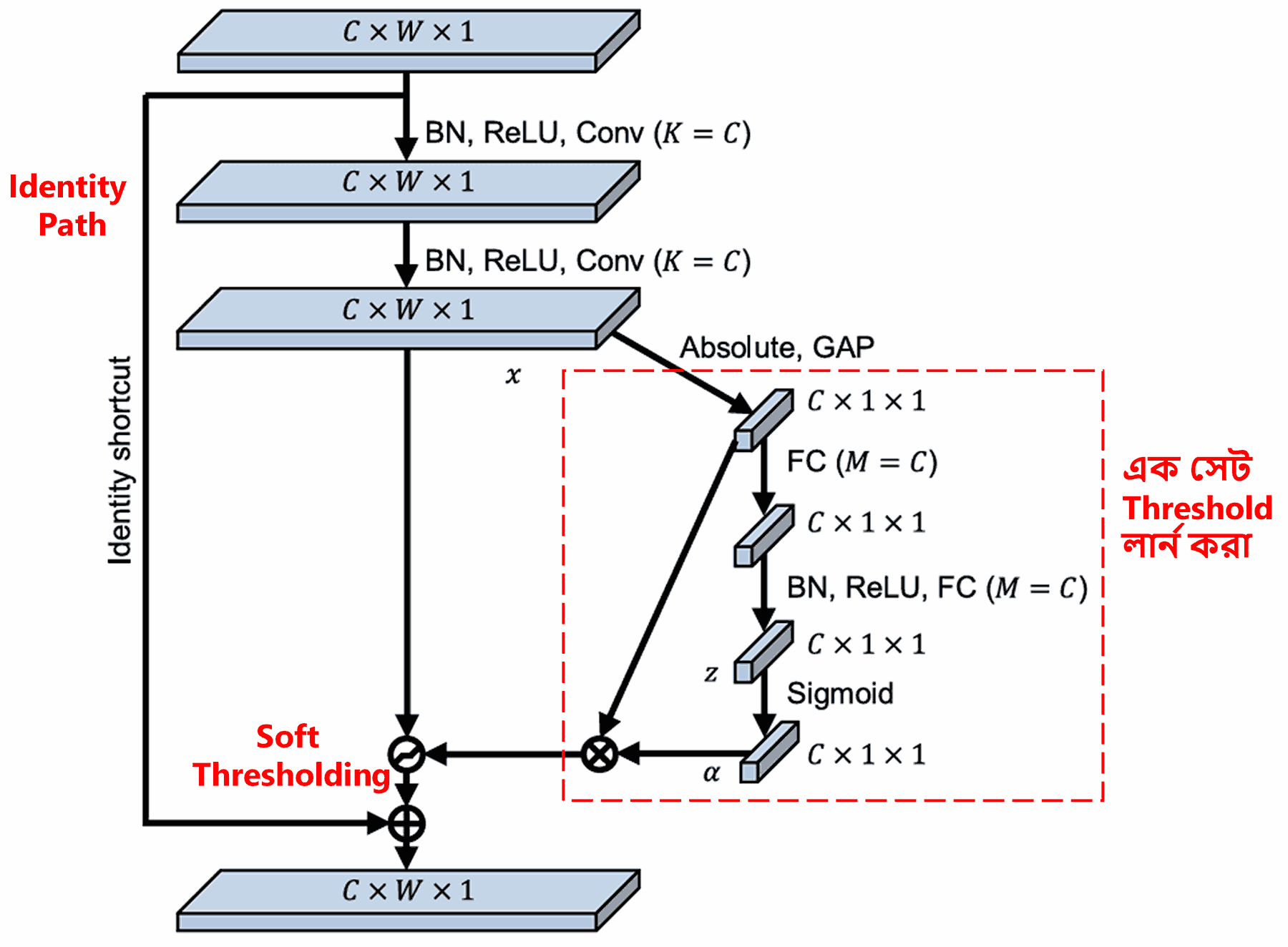
এই সাব-নেটওয়ার্কে প্রথমে ইনপুট Feature Map-এর সব Feature-এর Absolute Value বের করা হয়। এরপর Global Average Pooling এবং অ্যাভারেজ করার মাধ্যমে একটি ফিচার পাওয়া যায়, যাকে আমরা A ধরি। অন্য একটি পথে, Global Average Pooling-এর পর ফিচার ম্যাপটি একটি ছোট Fully Connected Network-এ ইনপুট দেওয়া হয়। এই নেটওয়ার্কের শেষ লেয়ারে Sigmoid Function থাকে, যা আউটপুটকে ০ এবং ১-এর মধ্যে নরমালাইজ (normalize) করে। এখান থেকে একটি কোএফিসিয়েন্ট (coefficient) পাওয়া যায়, যাকে আমরা α (alpha) ধরি। ফাইনাল Threshold-টিকে α × A হিসেবে প্রকাশ করা যায়। সহজ কথায়, Threshold হলো: ০ থেকে ১-এর মধ্যে একটি সংখ্যা × Feature Map-এর Absolute Value-এর গড়। এই পদ্ধতি নিশ্চিত করে যে Threshold-টি পজিটিভ হবে এবং খুব বেশি বড়ও হবে না।
তাছাড়াও, এর ফলে ভিন্ন ভিন্ন স্যাম্পলের জন্য ভিন্ন ভিন্ন Threshold তৈরি হয়। তাই কিছুটা সহজভাবে বললে, এটিকে একটি বিশেষ ধরণের Attention Mechanism হিসেবে ভাবা যায়: এটি বর্তমান টাস্কের সাথে সম্পর্কহীন Feature-গুলোকে নোটিস করে, দুটি Convolutional Layer-এর মাধ্যমে সেগুলোকে ০-এর কাছাকাছি নিয়ে আসে এবং Soft Thresholding-এর মাধ্যমে সেগুলোকে পুরোপুরি জিরো করে দেয়। আবার উল্টোভাবে, কাজের সাথে সম্পর্কিত Feature-গুলোকে এটি ০ থেকে দূরে সরিয়ে দেয় এবং সেগুলোকে ধরে রাখে।
সবশেষে, নির্দিষ্ট সংখ্যক বেসিক মডিউলের সাথে Convolutional Layer, Batch Normalization, Activation Function, Global Average Pooling এবং Fully Connected Output Layer ইত্যাদি স্ট্যাক (stack) করে সম্পূর্ণ Deep Residual Shrinkage Network তৈরি করা হয়।
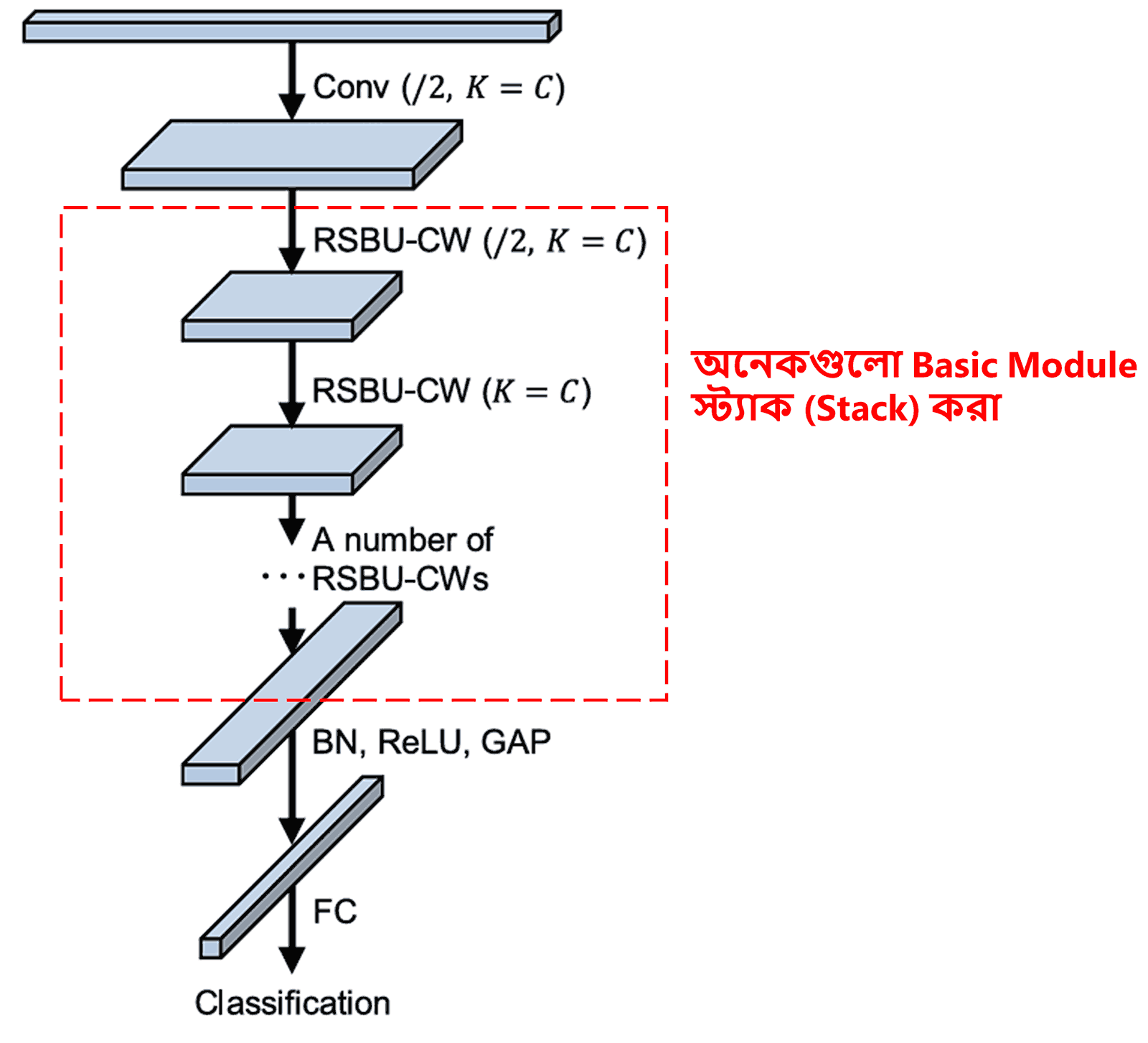
5. Generalization Capability (সার্বজনীনতা)
Deep Residual Shrinkage Network আসলে একটি জেনারেল বা সাধারণ Feature Learning Method। কারণ অনেক Feature Learning টাস্কে স্যাম্পলগুলোর মধ্যে কম-বেশি নয়েজ বা অপ্রয়োজনীয় তথ্য থাকেই। এই নয়েজ এবং অপ্রয়োজনীয় তথ্যগুলো লার্নিং-এ বাধা দিতে পারে। যেমন:
Image Classification-এর সময়, ছবিতে যদি অন্য অনেক অবজেক্ট থাকে, তবে সেগুলোকে “Noise” হিসেবে ধরা যায়। Deep Residual Shrinkage Network তার Attention Mechanism দিয়ে এই “Noise”-গুলোকে নোটিস করতে পারে এবং Soft Thresholding ব্যবহার করে সেগুলোর Feature-কে জিরো করে দিতে পারে। এতে ক্লাসিফিকেশনের Accuracy বাড়ার সম্ভাবনা থাকে।
Speech Recognition-এর সময়, যদি পরিবেশ খুব কোলাহলপূর্ণ হয় (যেমন রাস্তার পাশে বা কারখানার ভেতরে কথা বলার সময়), তবে Deep Residual Shrinkage Network হয়তো Speech Recognition-এর Accuracy বাড়াতে পারে, বা অন্তত এমন একটি পথের সন্ধান দেয় যা Accuracy বাড়াতে সাহায্য করতে পারে।
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Academic Impact (গবেষণায় প্রভাব)
এই পেপারটির Google Scholar সাইটেশন সংখ্যা ১৪০০ ছাড়িয়ে গেছে।
অসম্পূর্ণ পরিসংখ্যান অনুযায়ী, Deep Residual Shrinkage Network বা DRSN-কে ১০০০-এরও বেশি গবেষণাপত্রে সরাসরি ব্যবহার করা হয়েছে অথবা ইম্প্রুভ (improve) করে অ্যাপ্লাই করা হয়েছে। এর মধ্যে মেকানিক্যাল ইঞ্জিনিয়ারিং, ইলেকট্রিক পাওয়ার, কম্পিউটার ভিশন, মেডিকেল সায়েন্স, স্পিচ প্রসেসিং, টেক্সট অ্যানালাইসিস, রাডার এবং রিমোট সেন্সিং-এর মতো অনেকগুলো ফিল্ড অন্তর্ভুক্ত।