Deep Residual Shrinkage Network (DRSN) — это усовершенствованная версия глубоких остаточных сетей (ResNet). По сути, данная архитектура представляет собой интеграцию ResNet, механизмов внимания (attention mechanisms) и алгоритмов мягкой пороговой обработки (soft thresholding).
Ключевой принцип работы DRSN можно сформулировать так: используя механизм внимания, сеть выявляет малозначимые признаки и «обнуляет» их посредством функции мягкого порога, сохраняя при этом информативные компоненты сигнала. Такой подход существенно повышает способность глубокой нейронной сети извлекать полезные признаки из сильно зашумленных данных.
1. Мотивация исследования
Во-первых, при классификации реальных сигналов данные неизбежно содержат помехи, такие как гауссов шум, розовый шум, лапласовский шум и другие. В широком смысле, любая информация в образце, не относящаяся к решаемой задаче классификации, может рассматриваться как шум. Эти артефакты способны негативно сказаться на точности модели. (Стоит отметить, что мягкая пороговая обработка исторически является ключевым этапом во многих классических алгоритмах шумоподавления, например, на основе вейвлет-преобразования).
Рассмотрим наглядный пример: во время разговора на обочине дороги к речи примешиваются звуки автомобильных клаксонов, шум колес и т.д. Эти посторонние звуки неизбежно затрудняют задачу распознавания речи. С точки зрения глубокого обучения (Deep Learning), признаки, соответствующие этим шумам (клаксонам, колесам), должны быть подавлены внутри нейронной сети, чтобы нивелировать их влияние на итоговый результат.
Во-вторых, даже в пределах одного датасета уровень шума может существенно варьироваться от образца к образцу. (Это наблюдение коррелирует с идеологией механизмов внимания. Если рассмотреть набор изображений, то целевой объект может находиться в разных частях кадра; механизм внимания позволяет сети сфокусироваться именно на локации объекта для каждого конкретного изображения).
Например, при обучении классификатора «кошки против собак» рассмотрим выборку из 5 изображений с меткой «собака». На первом снимке могут быть собака и мышь, на втором — собака и гусь, на третьем — собака и курица, на четвертом — собака и осел, а на пятом — собака и утка. Обучая классификатор, мы сталкиваемся с проблемой: посторонние объекты (мыши, гуси и др.) создают помехи, снижая точность модели. Если бы существовал способ автоматически детектировать эти «шумовые» объекты и удалять соответствующие им признаки, это позволило бы значительно улучшить качество классификации.
2. Мягкая пороговая обработка (Soft Thresholding)
Мягкая пороговая обработка — это фундаментальный этап многих методов обработки сигналов. Суть метода заключается в следующем: признаки, абсолютное значение которых ниже определенного порога, обнуляются, а признаки, превышающие порог, «стягиваются» к нулю на величину этого порога. Математически это описывается следующей формулой:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Производная функции мягкого порога по входной переменной принимает следующий вид:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Как видно из формул, градиент мягкого порога равен либо 1, либо 0. Это свойство идентично поведению популярной функции активации ReLU. Следовательно, использование мягкого порога позволяет минимизировать риски затухания градиента (vanishing gradient) и взрыва градиента (exploding gradient), характерные для алгоритмов глубокого обучения.
При настройке функции мягкого порога необходимо соблюдать два условия: во-первых, порог должен быть положительным числом; во-вторых, он не должен превышать максимальное абсолютное значение входного сигнала, иначе выходной сигнал станет тождественно равен нулю.
Кроме того, желательно выполнение третьего условия: каждый образец должен иметь свой собственный независимый порог, адаптирующийся под уровень шума конкретного сигнала.
Это требование обусловлено неоднородностью зашумления данных. Образец А может содержать мало шума, а образец Б — много. Соответственно, для А требуется более низкий порог, а для Б — более высокий. Хотя в глубоких нейронных сетях признаки и пороги теряют явный физический смысл, базовая логика сохраняется: порог должен быть индивидуальным и зависеть от содержания шума в конкретном входном векторе.
3. Механизм внимания (Attention Mechanism)
Принцип работы механизмов внимания проще всего проиллюстрировать на примере зрительной системы. Животные способны быстро сканировать поле зрения, обнаруживать целевой объект и фокусировать на нем внимание для извлечения деталей, одновременно подавляя нерелевантную информацию. (Более подробную информацию можно найти в обзорной литературе по Attention Mechanisms).
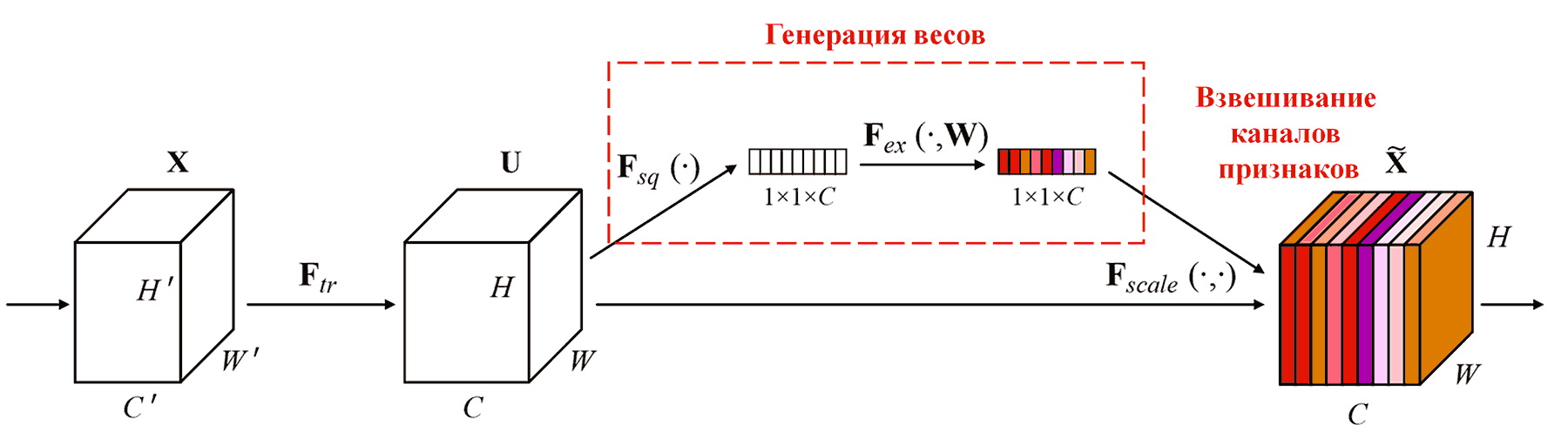
Squeeze-and-Excitation Network (SENet) — одна из современных архитектур, эффективно использующая этот принцип. В нейронных сетях вклад различных каналов признаков (feature channels) в задачу классификации часто неодинаков. SENet использует небольшую подсеть для генерации набора весов, которые затем перемножаются с признаками соответствующих каналов. Это позволяет регулировать значимость признаков в каждом канале. Данный процесс можно рассматривать как наложение «внимания» разной силы на разные каналы признаков.
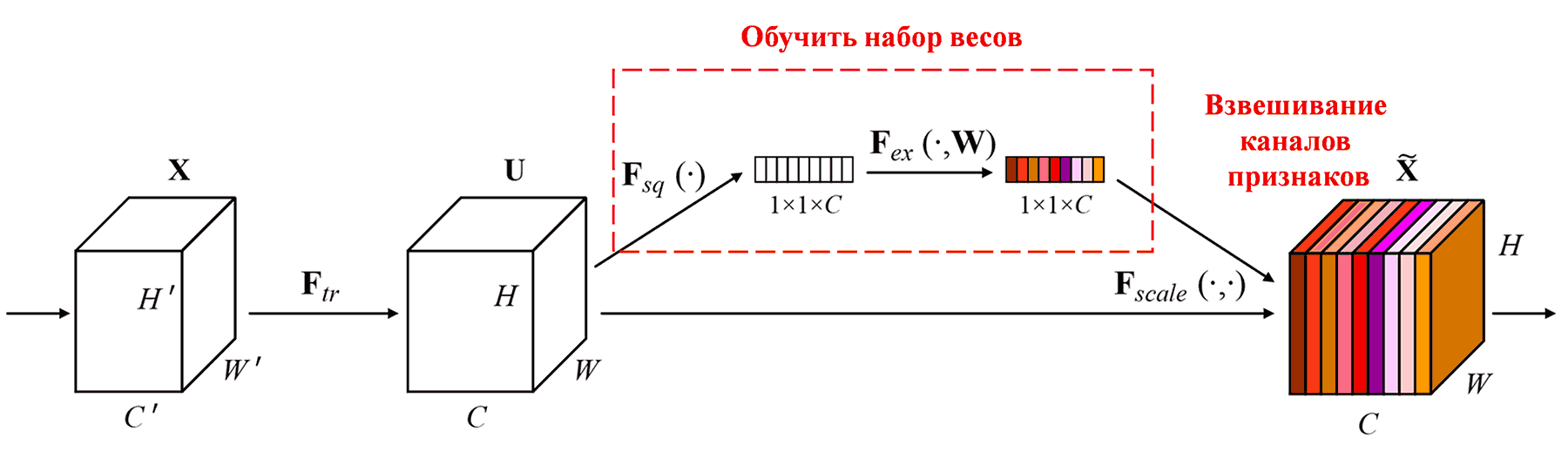
При таком подходе каждый образец получает свой независимый набор весов. Другими словами, для любых двух произвольных образцов веса будут различаться. В SENet путь генерации весов выглядит следующим образом: «Глобальный пулинг (Global Pooling) → Полносвязный слой → Функция ReLU → Полносвязный слой → Функция Sigmoid».
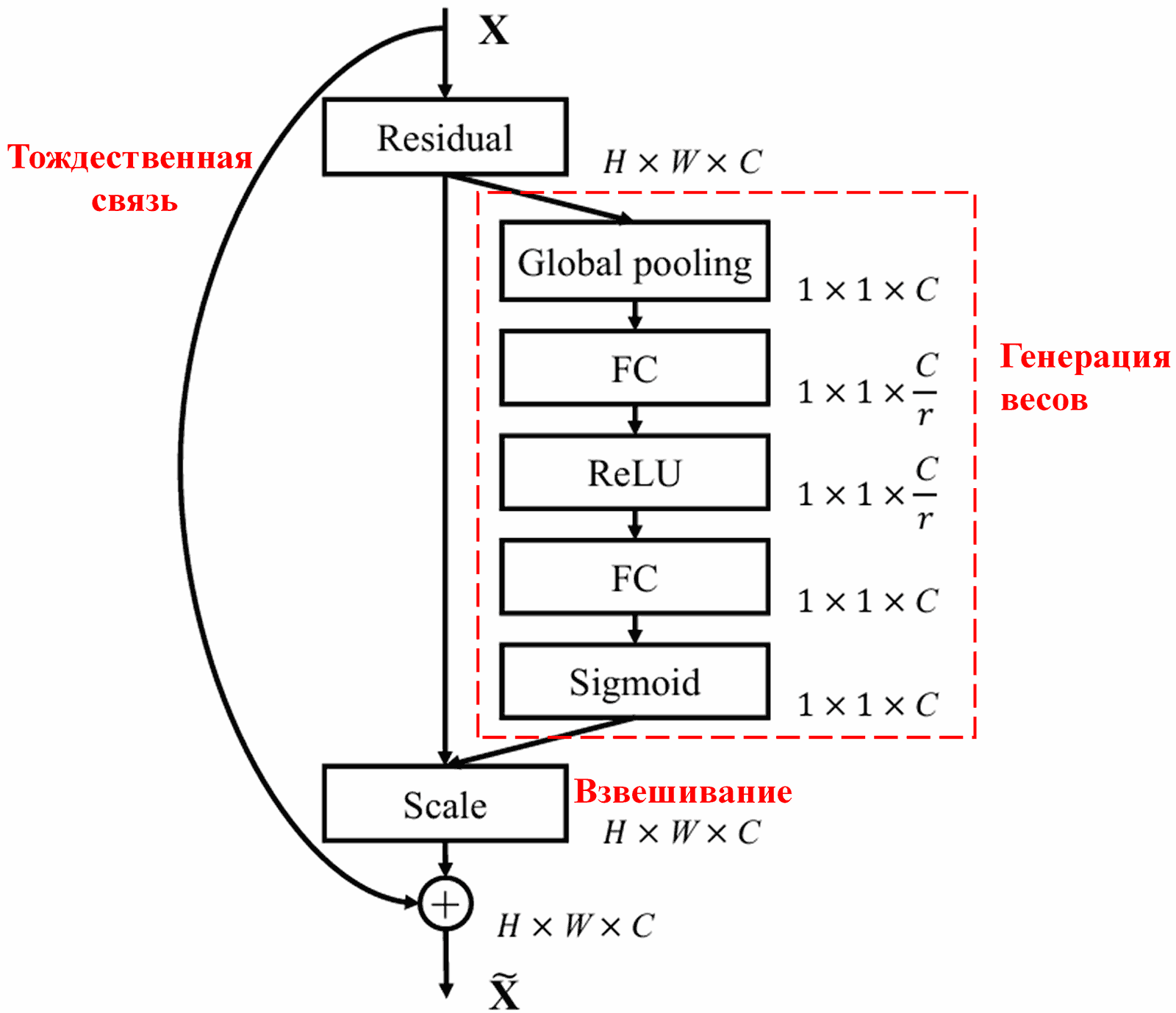
4. Мягкая пороговая обработка на основе глубокого механизма внимания
Архитектура Deep Residual Shrinkage Network заимствует структуру подсети у SENet для реализации мягкой пороговой обработки, управляемой механизмом внимания. С помощью подсети (выделена красной рамкой на схеме алгоритма) сеть обучается генерировать набор порогов для применения мягкого порога к каждому каналу признаков.
Алгоритм функционирует следующим образом: сначала вычисляются абсолютные значения всех признаков во входной карте признаков (feature map). Затем, после глобального усредняющего пулинга (Global Average Pooling), получается усредненный признак, обозначим его как A. Далее этот признак подается в небольшую полносвязную сеть. Последним слоем этой полносвязной сети является функция Sigmoid, которая нормализует выходное значение в диапазоне от 0 до 1, давая коэффициент, обозначим его как α. Итоговый порог вычисляется как произведение α × A. Такой метод гарантирует, что порог не только будет положительным, но и не окажется слишком большим.
Более того, для разных образцов генерируются разные пороги. В определенной степени это можно интерпретировать как специальный механизм внимания: сеть выявляет признаки, не относящиеся к текущей задаче, преобразует их в значения, близкие к нулю (через сверточные слои), и окончательно обнуляет их с помощью функции мягкого порога. И наоборот: признаки, важные для задачи, преобразуются в значения, далекие от нуля, и сохраняются.
Наконец, объединив определенное количество таких базовых модулей со сверточными слоями, пакетной нормализацией (Batch Normalization), функциями активации, глобальным усредняющим пулингом и выходным полносвязным слоем, мы получаем полную архитектуру Deep Residual Shrinkage Network.
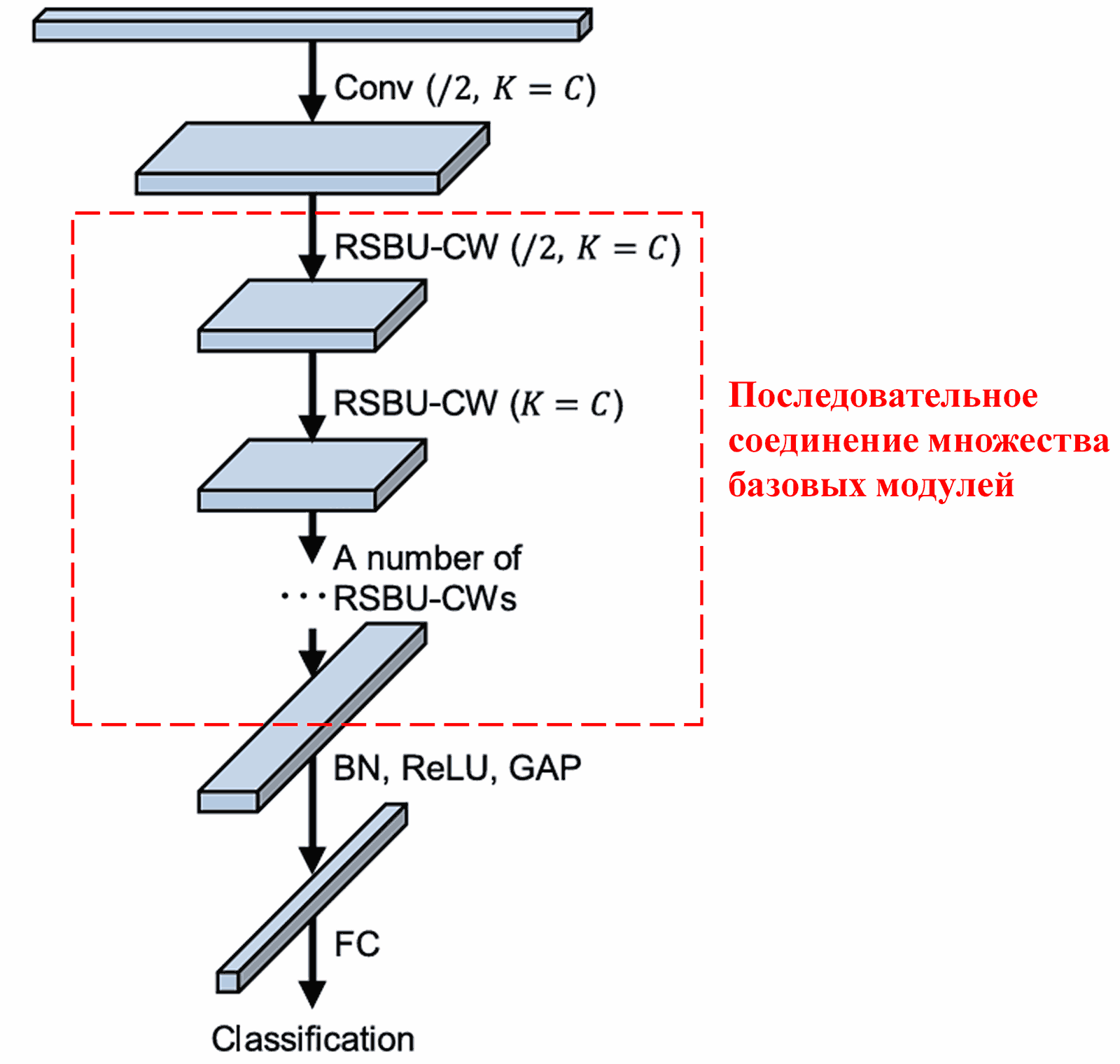
5. Универсальность метода
Deep Residual Shrinkage Network фактически является универсальным методом обучения признаков (feature learning). Это обусловлено тем, что во многих реальных задачах образцы в той или иной степени содержат шум и нерелевантную информацию, которые могут ухудшить качество обучения. Например:
В задачах классификации изображений, если фон картинки содержит множество посторонних объектов, их можно рассматривать как «шум». DRSN, используя механизм внимания, может локализовать этот «шум», а затем с помощью мягкой пороговой обработки обнулить соответствующие ему признаки, что потенциально повысит точность классификации.
В задачах распознавания речи, особенно в зашумленной обстановке (например, разговор у дороги или в заводском цеху), DRSN может повысить точность распознавания или, как минимум, предлагает перспективный подход для повышения робастности моделей.
Ссылки
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Академическое влияние
Количество цитирований данной статьи в Google Scholar (Google Академии) уже превысило 1400.
Согласно имеющимся данным, Deep Residual Shrinkage Network была применена (напрямую или в модифицированном виде) в более чем 1000 научных работах в самых разных областях, включая машиностроение, электроэнергетику, компьютерное зрение, медицину, обработку речи и текста, радиолокацию, дистанционное зондирование и другие.