A Rede Residual Profunda de Contração (Deep Residual Shrinkage Network) é uma variante aprimorada da Rede Residual Profunda (Deep Residual Network). Essencialmente, trata-se de uma integração de Redes Residuais Profundas, mecanismos de atenção e funções de limiarização suave (soft thresholding).
Até certo ponto, o princípio de funcionamento da Rede Residual Profunda de Contração pode ser entendido da seguinte forma: ela utiliza mecanismos de atenção para identificar características (features) não importantes e emprega funções de limiarização suave para zerá-las; ou, dito de outra forma, identifica características importantes e as preserva. Esse processo fortalece a capacidade da rede neural profunda de extrair características úteis de sinais que contêm ruído.
1. Motivação da Pesquisa
Primeiro, ao classificar amostras, a presença de ruído — como ruído gaussiano, ruído rosa e ruído laplaciano — é inevitável. Em um sentido mais amplo, as amostras frequentemente contêm informações irrelevantes para a tarefa de classificação atual, o que também pode ser interpretado como ruído. Esse ruído pode afetar negativamente o desempenho da classificação. (A limiarização suave é uma etapa fundamental em muitos algoritmos de redução de ruído em sinais).
Por exemplo, durante uma conversa à beira da estrada, o áudio pode estar misturado com sons de buzinas e rodas de veículos. Ao realizar o reconhecimento de voz nesses sinais, os resultados serão inevitavelmente afetados por esses sons de fundo. Da perspectiva do Deep Learning, as características correspondentes às buzinas e rodas deveriam ser eliminadas dentro da rede neural profunda para evitar que afetem os resultados do reconhecimento de voz.
Segundo, mesmo dentro do mesmo conjunto de dados (dataset), a quantidade de ruído muitas vezes varia de amostra para amostra. (Isso compartilha semelhanças com mecanismos de atenção; tomando um conjunto de imagens como exemplo, a localização do objeto alvo pode diferir entre as imagens, e os mecanismos de atenção podem focar na localização específica do objeto alvo em cada imagem).
Por exemplo, ao treinar um classificador de cães e gatos, considere 5 imagens rotuladas como “cachorro”. A 1ª imagem pode conter um cachorro e um rato, a 2ª um cachorro e um ganso, a 3ª um cachorro e uma galinha, a 4ª um cachorro e um burro, e a 5ª um cachorro e um pato. Durante o treinamento, o classificador sofrerá inevitavelmente interferência de objetos irrelevantes como ratos, gansos, galinhas, burros e patos, resultando em uma queda na acurácia da classificação. Se conseguirmos notar esses objetos irrelevantes e eliminar as características correspondentes a eles, é possível aumentar a acurácia do classificador de cães e gatos.
2. Limiarização Suave (Soft Thresholding)
A limiarização suave (soft thresholding) é uma etapa central em muitos algoritmos de redução de ruído de sinais. Ela elimina características cujos valores absolutos são menores que um determinado limiar (threshold) e “contrai” em direção a zero aquelas cujos valores absolutos são maiores que esse limiar. Ela pode ser implementada através da seguinte fórmula:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]A derivada da saída da limiarização suave em relação à entrada é:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Como mostrado acima, a derivada da limiarização suave é 1 ou 0. Essa propriedade é idêntica à da função de ativação ReLU. Portanto, a limiarização suave também é capaz de reduzir o risco de algoritmos de Deep Learning enfrentarem problemas de desvanecimento de gradiente (gradient vanishing) e explosão de gradiente (gradient exploding).
Na função de limiarização suave, a definição do limiar deve satisfazer duas condições: Primeiro, o limiar deve ser um número positivo; Segundo, o limiar não pode ser maior que o valor máximo do sinal de entrada, caso contrário, a saída será totalmente zero.
Além disso, é preferível que o limiar satisfaça uma terceira condição: cada amostra deve ter seu próprio limiar independente, baseado no seu conteúdo de ruído.
Isso ocorre porque o conteúdo de ruído frequentemente varia entre as amostras. Por exemplo, é comum em um mesmo dataset que a Amostra A contenha menos ruído, enquanto a Amostra B contém mais ruído. Nesse caso, ao realizar a limiarização suave em um algoritmo de redução de ruído, a Amostra A deveria utilizar um limiar menor, enquanto a Amostra B deveria utilizar um limiar maior. Em redes neurais profundas, embora essas características e limiares percam suas definições físicas explícitas, a lógica básica permanece a mesma. Ou seja, cada amostra deve ter seu próprio limiar independente, determinado pelo seu conteúdo específico de ruído.
3. Mecanismo de Atenção
Os mecanismos de atenção são relativamente fáceis de entender no campo da visão computacional. O sistema visual dos animais pode escanear rapidamente toda uma área para descobrir o objeto alvo e, em seguida, focar a atenção nele para extrair mais detalhes, suprimindo informações irrelevantes. Para detalhes específicos, consulte a literatura sobre mecanismos de atenção.
A Squeeze-and-Excitation Network (SENet) é um método de Deep Learning relativamente novo sob a ótica dos mecanismos de atenção. Em diferentes amostras, a contribuição de diferentes canais de características (feature channels) para a tarefa de classificação geralmente varia. A SENet emprega uma pequena sub-rede para obter um conjunto de pesos e, em seguida, multiplica esses pesos pelas características dos respectivos canais para ajustar a magnitude das características em cada canal. Esse processo pode ser visto como a aplicação de diferentes níveis de atenção aos canais de características.
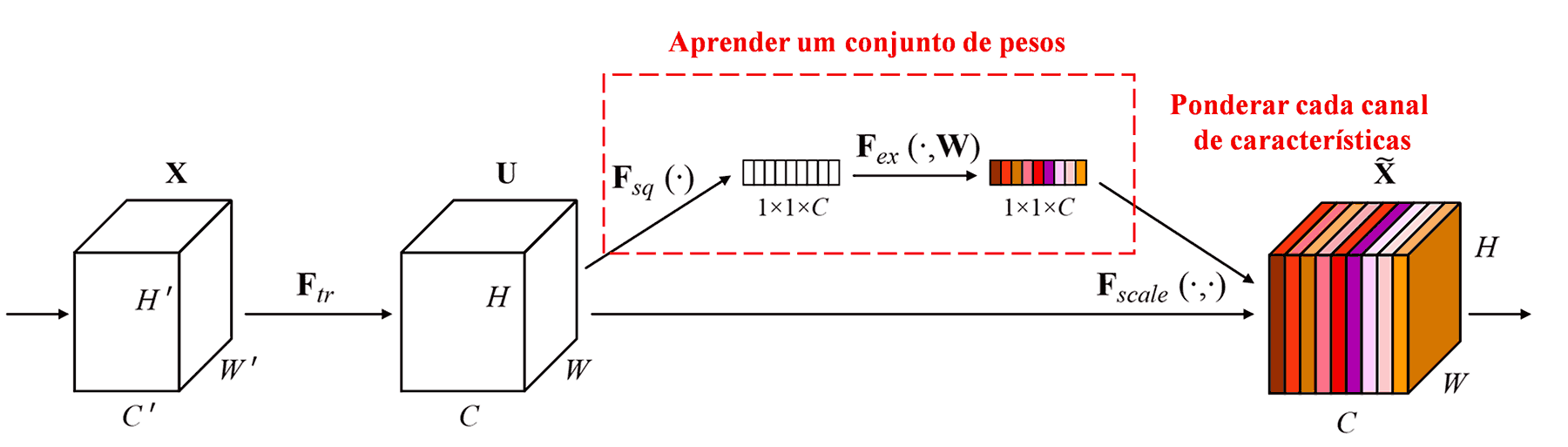
Nessa abordagem, cada amostra terá seu próprio conjunto independente de pesos. Em outras palavras, os pesos para quaisquer duas amostras arbitrárias são diferentes. Na SENet, o caminho específico para obter os pesos é “Pooling Global → Camada Totalmente Conectada → Função ReLU → Camada Totalmente Conectada → Função Sigmoid”.
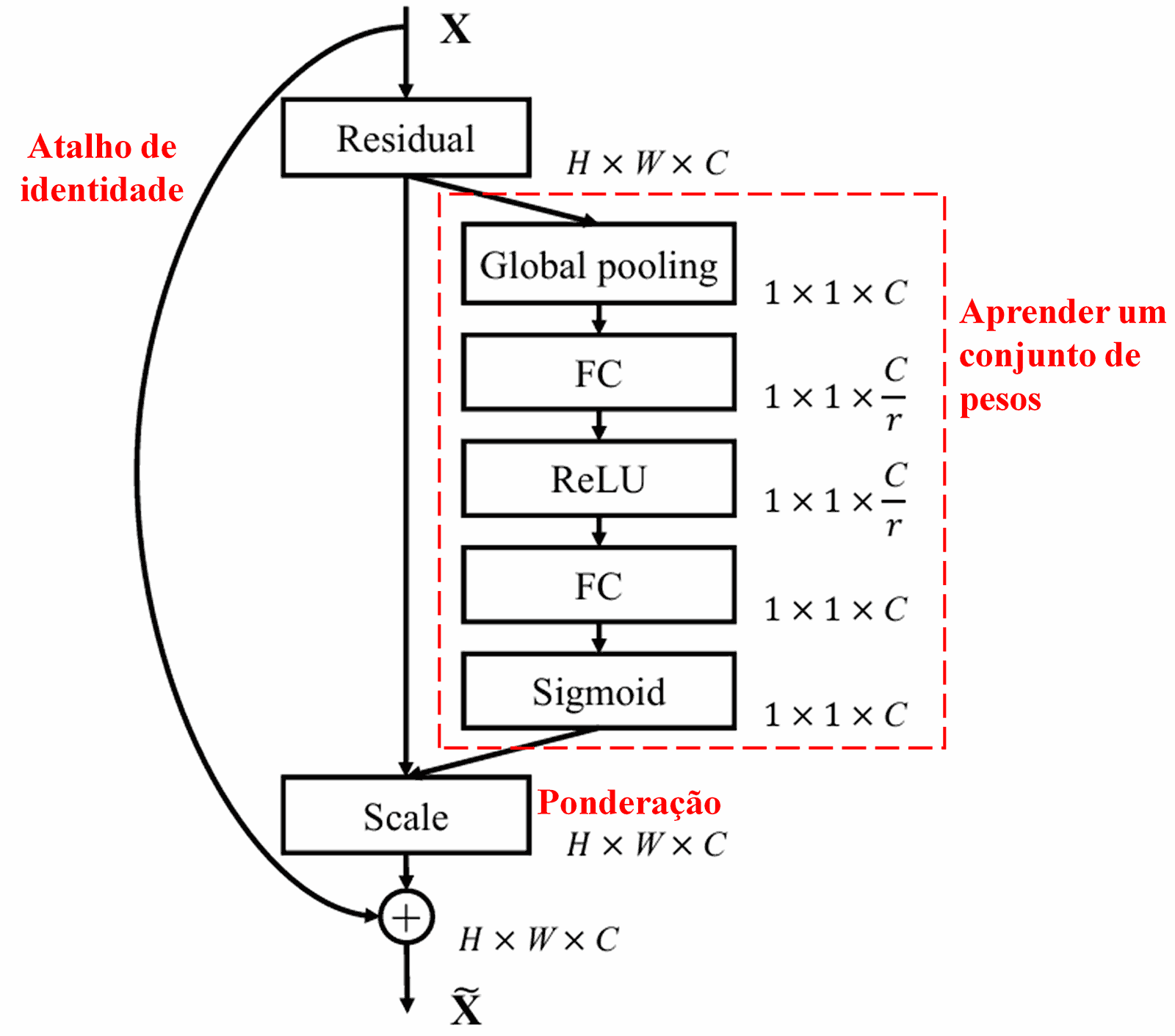
4. Limiarização Suave sob Mecanismo de Atenção Profunda
A Rede Residual Profunda de Contração baseia-se na estrutura da sub-rede da SENet mencionada acima para implementar a limiarização suave sob um mecanismo de atenção profunda. Através da sub-rede (indicada dentro da caixa vermelha nos diagramas originais), um conjunto de limiares pode ser aprendido para aplicar a limiarização suave a cada canal de características.
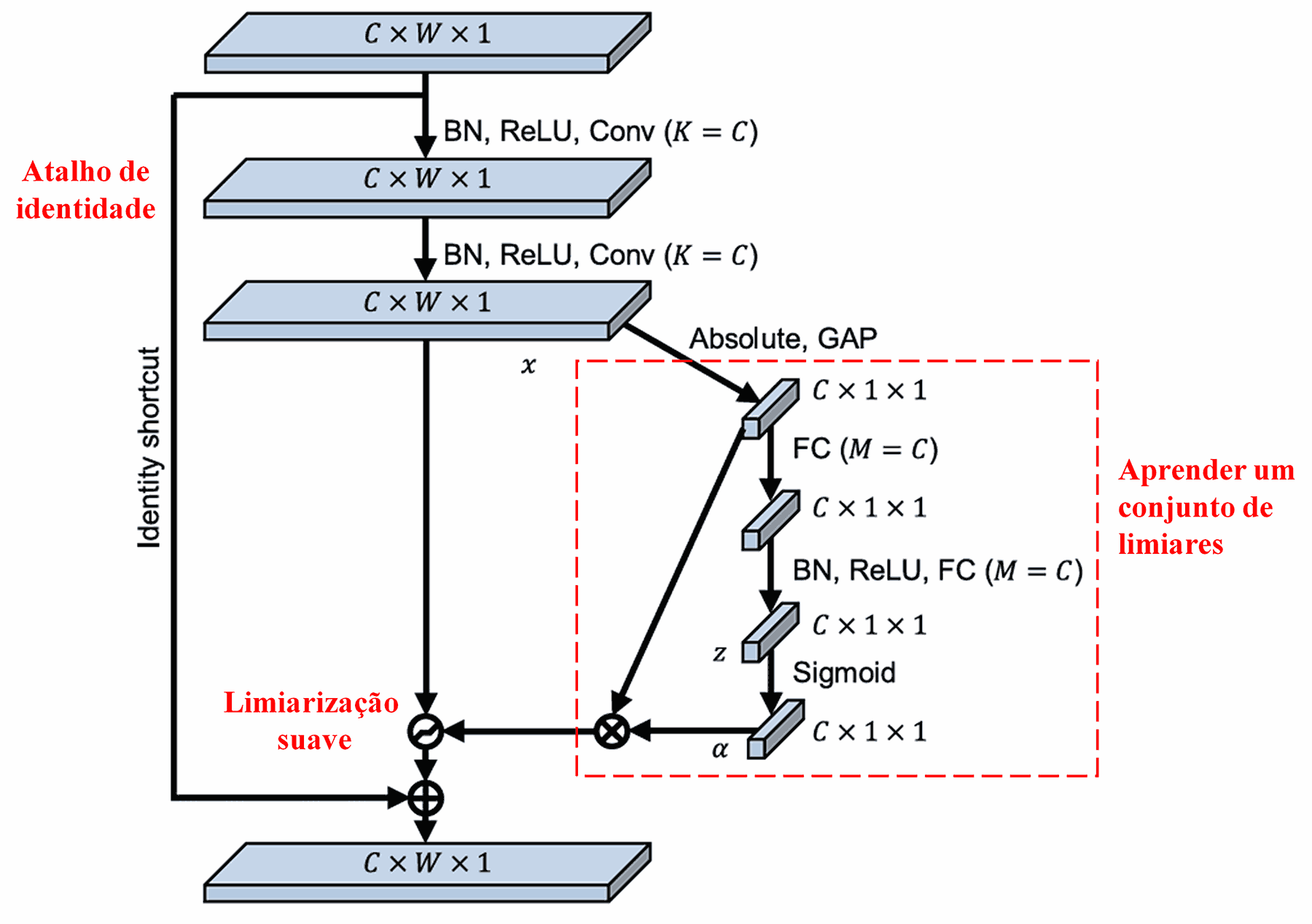
Nesta sub-rede, primeiro calcula-se o valor absoluto de todas as características no mapa de características de entrada. Em seguida, através do Pooling Médio Global (Global Average Pooling) e do cálculo da média, obtém-se uma característica, denotada como A. Em outro caminho, o mapa de características após o Pooling Médio Global é inserido em uma pequena rede totalmente conectada. Essa rede utiliza a função Sigmoid como sua última camada para normalizar a saída entre 0 e 1, obtendo um coeficiente denotado como α. O limiar final pode ser expresso como α × A. Portanto, o limiar é o produto de um número entre 0 e 1 pela média dos valores absolutos do mapa de características. Esse método garante que o limiar seja não apenas positivo, mas também não excessivamente grande.
Além disso, diferentes amostras resultam em diferentes limiares. Consequentemente, até certo ponto, isso pode ser interpretado como um mecanismo de atenção especializado: ele nota características irrelevantes para a tarefa atual, transforma-as em valores próximos de zero através de duas camadas convolucionais e as zera usando a limiarização suave; alternativamente, nota características relevantes para a tarefa atual, transforma-as em valores distantes de zero e as preserva.
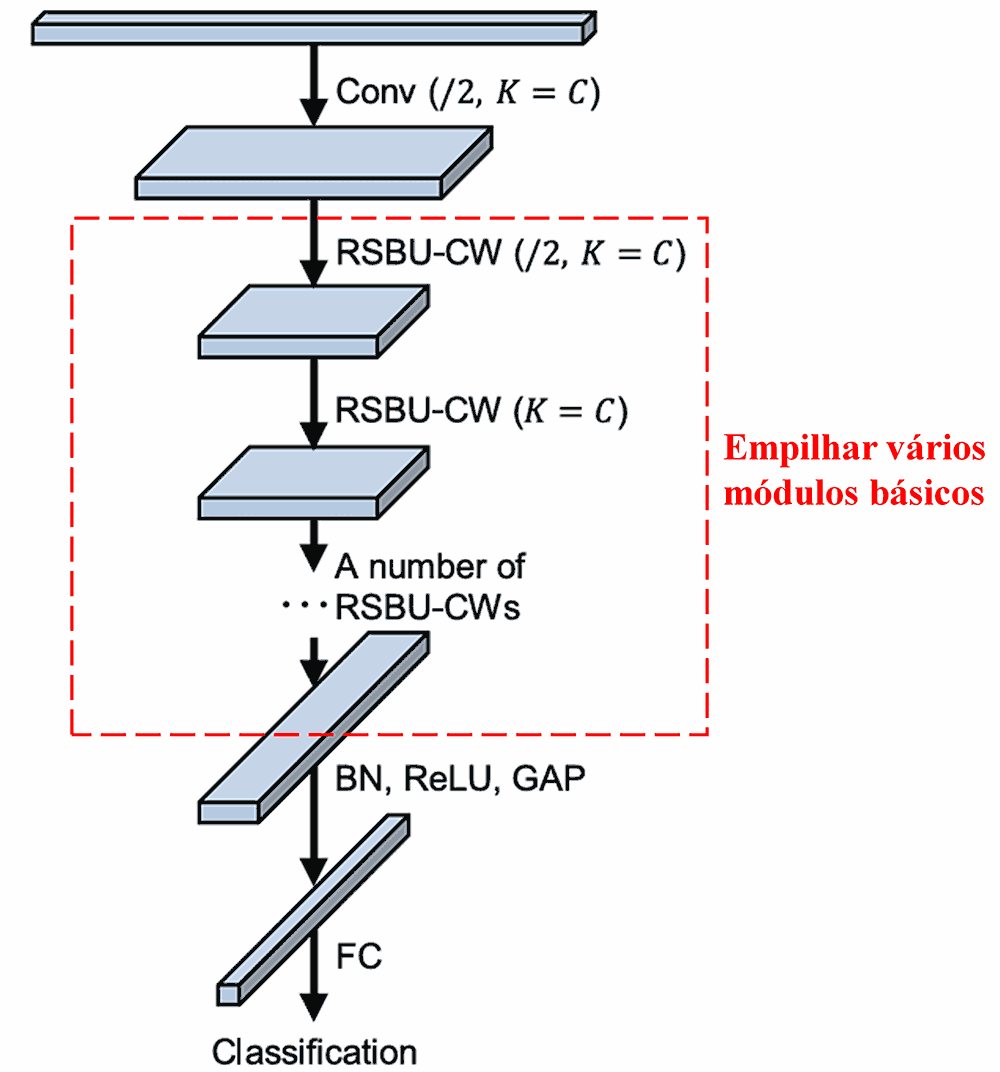
Finalmente, empilhando um certo número de módulos básicos juntamente com camadas convolucionais, Batch Normalization, funções de ativação, Pooling Médio Global e camadas de saída totalmente conectadas, obtém-se a Rede Residual Profunda de Contração completa.
5. Capacidade de Generalização
A Rede Residual Profunda de Contração é, de fato, um método genérico de aprendizado de características. Isso ocorre porque, em muitas tarefas de aprendizado de características, as amostras contêm, em maior ou menor grau, algum ruído, bem como informações irrelevantes. Esse ruído e essas informações irrelevantes podem afetar o desempenho do aprendizado. Por exemplo:
Na classificação de imagens, se uma imagem contém simultaneamente muitos outros objetos, esses objetos podem ser entendidos como “ruído”. A Rede Residual Profunda de Contração talvez consiga utilizar o mecanismo de atenção para notar esse “ruído” e, então, empregar a limiarização suave para zerar as características correspondentes a ele, aumentando potencialmente a acurácia da classificação de imagens.
No reconhecimento de voz, especificamente em ambientes ruidosos como uma conversa à beira da estrada ou dentro de uma fábrica, a Rede Residual Profunda de Contração pode melhorar a acurácia do reconhecimento, ou pelo menos oferecer uma linha de raciocínio capaz de melhorar essa acurácia.
Referências
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Impacto Acadêmico
Este artigo já recebeu mais de 1400 citações no Google Scholar.
De acordo com estatísticas incompletas, a Rede Residual Profunda de Contração (Deep Residual Shrinkage Network) já foi aplicada diretamente ou aprimorada em mais de 1000 publicações em diversas áreas, incluindo engenharia mecânica, energia elétrica, visão computacional, medicina, processamento de voz, análise de texto, radar e sensoriamento remoto.