Le Deep Residual Shrinkage Network (DRSN) est une variante améliorée des réseaux résiduels profonds (ResNets). Il s’agit essentiellement d’une intégration des ResNets, des mécanismes d’attention et de la fonction de seuillage doux (soft thresholding).
Dans une certaine mesure, le principe de fonctionnement du DRSN peut s’interpréter ainsi : il utilise le mécanisme d’attention pour repérer les caractéristiques non pertinentes et les annuler via la fonction de seuillage doux ; inversement, il identifie et préserve les caractéristiques importantes. Ce processus renforce la capacité du réseau de neurones profond à extraire des informations utiles à partir de signaux bruités.
1. Motivations de la recherche
Premièrement, lors de la classification, les échantillons contiennent inévitablement du bruit, tel que le bruit gaussien, le bruit rose ou le bruit de Laplace. Au sens large, les échantillons contiennent souvent des informations sans rapport avec la tâche en cours, ce qui peut aussi être considéré comme du bruit. Ces éléments parasites risquent de nuire à la performance de la classification. (Le seuillage doux est d’ailleurs une étape clé dans de nombreux algorithmes de débruitage de signal).
Prenons l’exemple d’une conversation au bord d’une route : la voix peut être mêlée à des bruits de klaxons ou de roulement. Lors de la reconnaissance vocale, ces sons parasites affectent inévitablement le résultat. Du point de vue du Deep Learning, les caractéristiques (features) correspondant à ces klaxons et bruits de roues devraient être éliminées au sein du réseau de neurones, afin d’éviter toute interférence.
Deuxièmement, au sein d’un même jeu de données, la quantité de bruit varie souvent d’un échantillon à l’autre. (Cela rejoint le principe du mécanisme d’attention : dans un jeu d’images, la position de l’objet cible varie, et l’attention permet de se focaliser sur la zone pertinente spécifique à chaque image).
Par exemple, pour l’entraînement d’un classifieur “chiens vs chats”, considérons cinq images étiquetées “chien”. La première peut contenir un chien et une souris, la deuxième un chien et une oie, la troisième un chien et un poulet, la quatrième un chien et un âne, et la cinquième un chien et un canard. Durant l’entraînement, le classifieur subit inévitablement les interférences de ces objets non pertinents (souris, oie, poulet, etc.), ce qui entraîne une baisse de la précision. Si nous pouvions identifier ces objets parasites et supprimer les caractéristiques qui leur correspondent, la précision du classifieur s’en trouverait améliorée.
2. Le seuillage doux (Soft Thresholding)
Le seuillage doux est une étape fondamentale de nombreux algorithmes de débruitage. Il consiste à mettre à zéro les caractéristiques dont la valeur absolue est inférieure à un seuil donné, et à “contracter” vers zéro celles dont la valeur absolue est supérieure à ce seuil. La formule est la suivante :
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]La dérivée de la sortie par rapport à l’entrée est :
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Comme on peut le voir, la dérivée du seuillage doux vaut soit 1, soit 0. Cette propriété est identique à celle de la fonction d’activation ReLU. Par conséquent, le seuillage doux permet également de réduire les risques de disparition et d’explosion du gradient (gradient vanishing/exploding).
Concernant le seuil, deux conditions doivent être respectées : premièrement, il doit être positif ; deuxièmement, il ne doit pas excéder la valeur maximale du signal d’entrée, sans quoi la sortie serait entièrement nulle.
Idéalement, une troisième condition devrait être remplie : chaque échantillon devrait posséder son propre seuil, adapté à son niveau de bruit spécifique.
En effet, le contenu en bruit varie souvent d’un échantillon à l’autre. Il est fréquent, dans un même dataset, que l’échantillon A soit peu bruité tandis que l’échantillon B l’est fortement. Logiquement, lors du débruitage, l’échantillon A devrait se voir appliquer un seuil plus faible, et l’échantillon B un seuil plus élevé. Bien que dans les réseaux de neurones profonds, ces seuils perdent leur signification physique explicite, la logique fondamentale reste la même : chaque échantillon nécessite un seuil indépendant, déterminé par son propre contenu en bruit.
3. Le mécanisme d’attention
Ce mécanisme est assez intuitif dans le domaine de la vision par ordinateur. Le système visuel des animaux peut scanner rapidement une zone pour détecter une cible, puis focaliser son attention sur cet objet pour en extraire les détails, tout en inhibant les informations non pertinentes. (Pour plus de détails, se référer à la littérature sur les mécanismes d’attention).
Le Squeeze-and-Excitation Network (SENet) est une méthode de Deep Learning récente utilisant ce mécanisme. La contribution de chaque canal de caractéristiques (feature channel) à la tâche de classification varie souvent selon les échantillons. SENet utilise un petit sous-réseau pour générer un ensemble de poids, qui sont ensuite multipliés par les caractéristiques des canaux respectifs afin d’en ajuster l’importance. Ce processus s’apparente à l’application d’une attention d’intensité variable sur chaque canal.
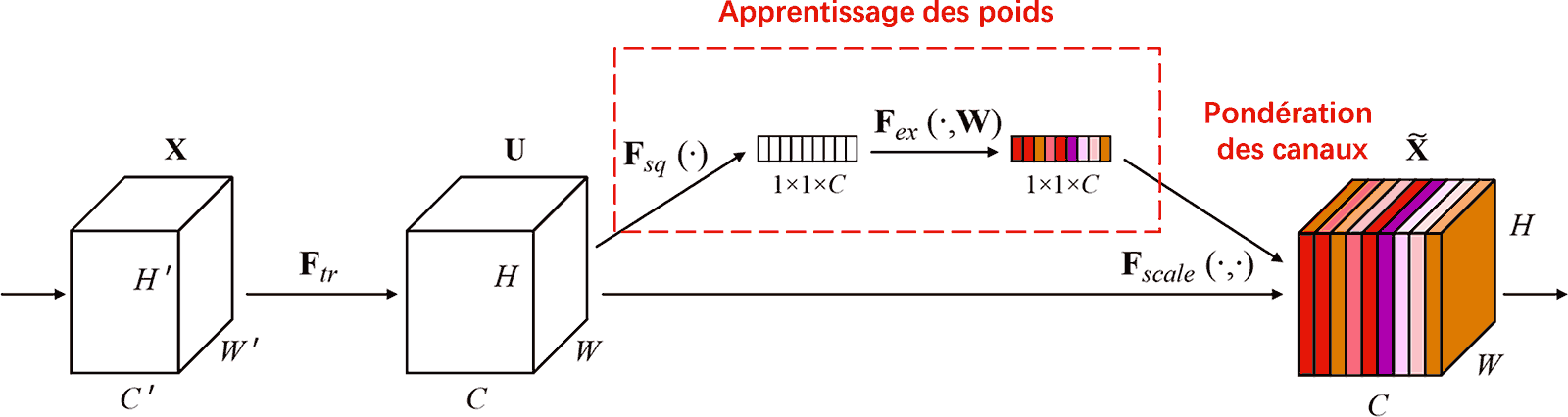
Ainsi, chaque échantillon possède son propre jeu de poids indépendants. Dans SENet, le cheminement pour obtenir ces poids est le suivant : “Global Pooling → Couche dense (Fully Connected) → ReLU → Couche dense → Sigmoïde”.
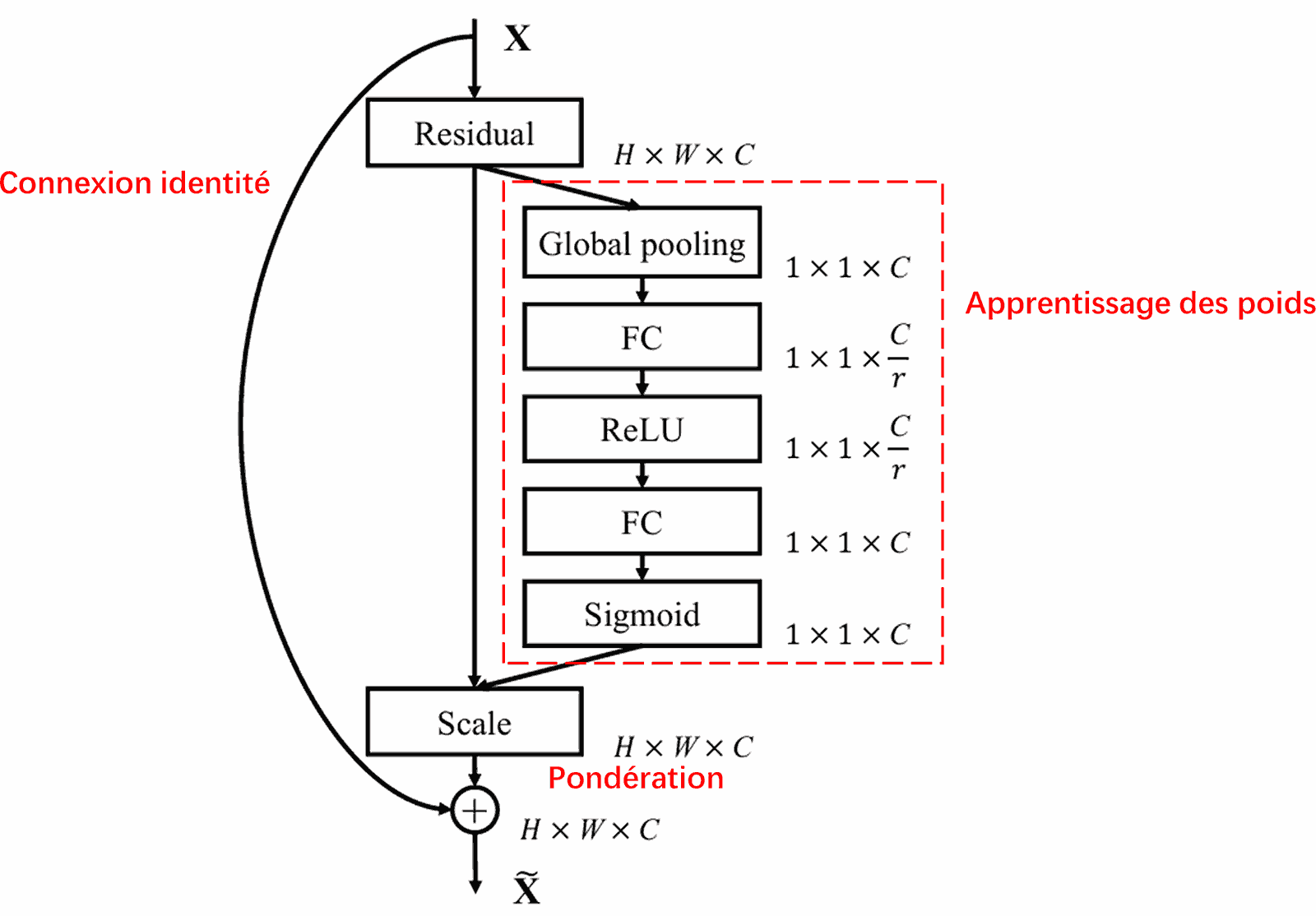
4. Le seuillage doux sous mécanisme d’attention profond
Le Deep Residual Shrinkage Network s’inspire de la structure du sous-réseau de SENet pour implémenter un seuillage doux dans un cadre d’attention profond. Grâce au sous-réseau (indiqué dans le cadre rouge), il est possible d’apprendre un ensemble de seuils pour appliquer un seuillage doux spécifique à chaque canal de caractéristiques.
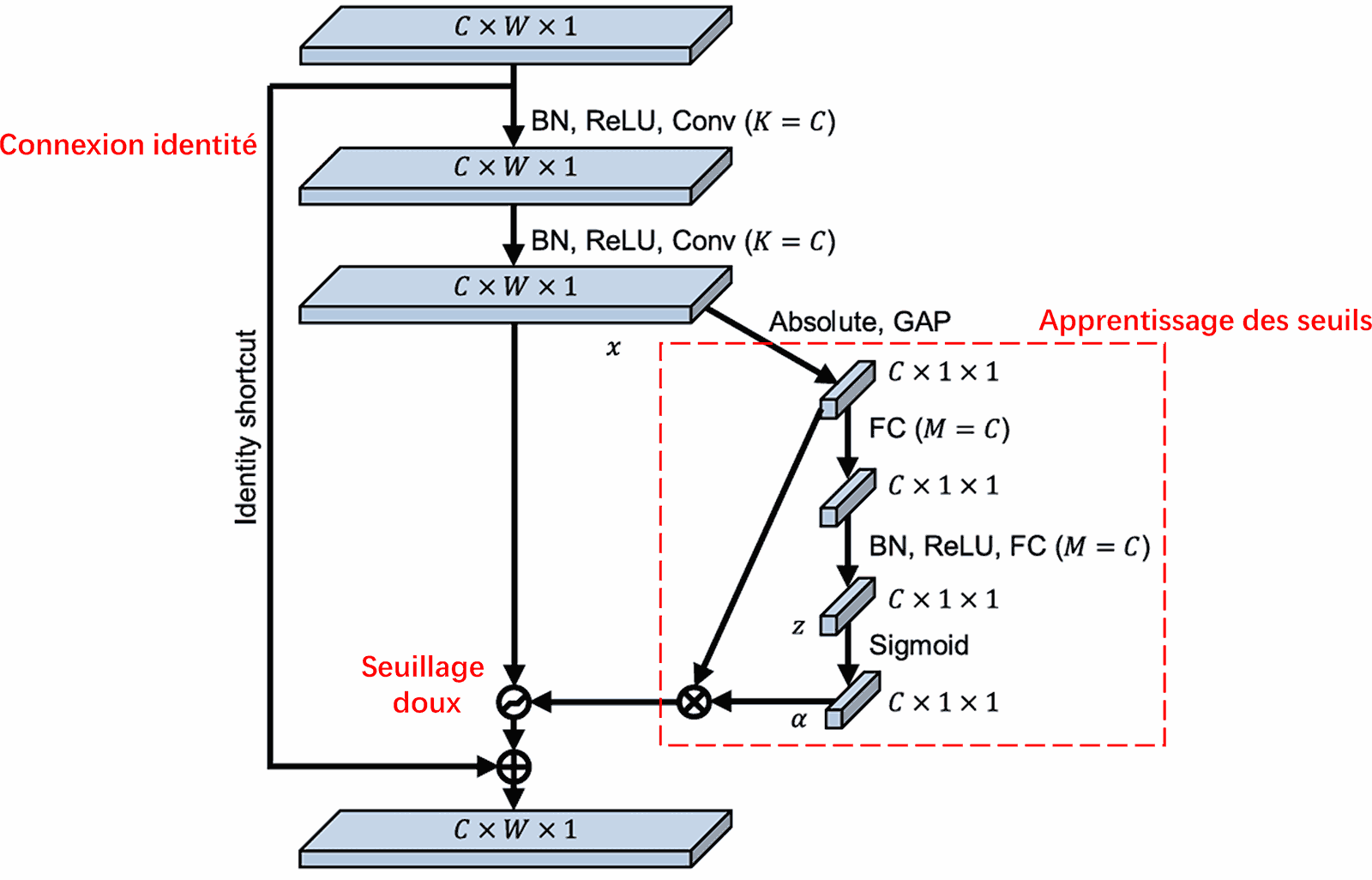
Au sein de ce sous-réseau, on calcule d’abord la valeur absolue de toutes les caractéristiques de la carte d’entrée. On applique ensuite un Global Average Pooling pour obtenir une valeur unique, notée A. Parallèlement, ce résultat traverse un petit réseau dense (fully connected). La dernière couche de ce réseau utilise une fonction Sigmoïde pour normaliser la sortie entre 0 et 1, produisant un coefficient noté α. Le seuil final est alors représenté par α×A. Le seuil est donc le produit d’un nombre entre 0 et 1 et de la moyenne des valeurs absolues de la carte de caractéristiques. Cette méthode garantit non seulement que le seuil est positif, mais aussi qu’il reste dans une plage de valeurs raisonnable.
De plus, le seuil varie d’un échantillon à l’autre. On peut donc y voir, dans une certaine mesure, un mécanisme d’attention spécialisé : il repère les caractéristiques non pertinentes pour la tâche, les transforme en valeurs proches de zéro via deux couches de convolution, puis les annule par seuillage doux ; à l’inverse, il identifie les caractéristiques pertinentes, les transforme en valeurs éloignées de zéro, et les préserve.
Enfin, l’empilement d’un certain nombre de modules de base, accompagnés de couches de convolution, de Batch Normalization, de fonctions d’activation, de Global Average Pooling et d’une couche de sortie dense, constitue le Deep Residual Shrinkage Network complet.
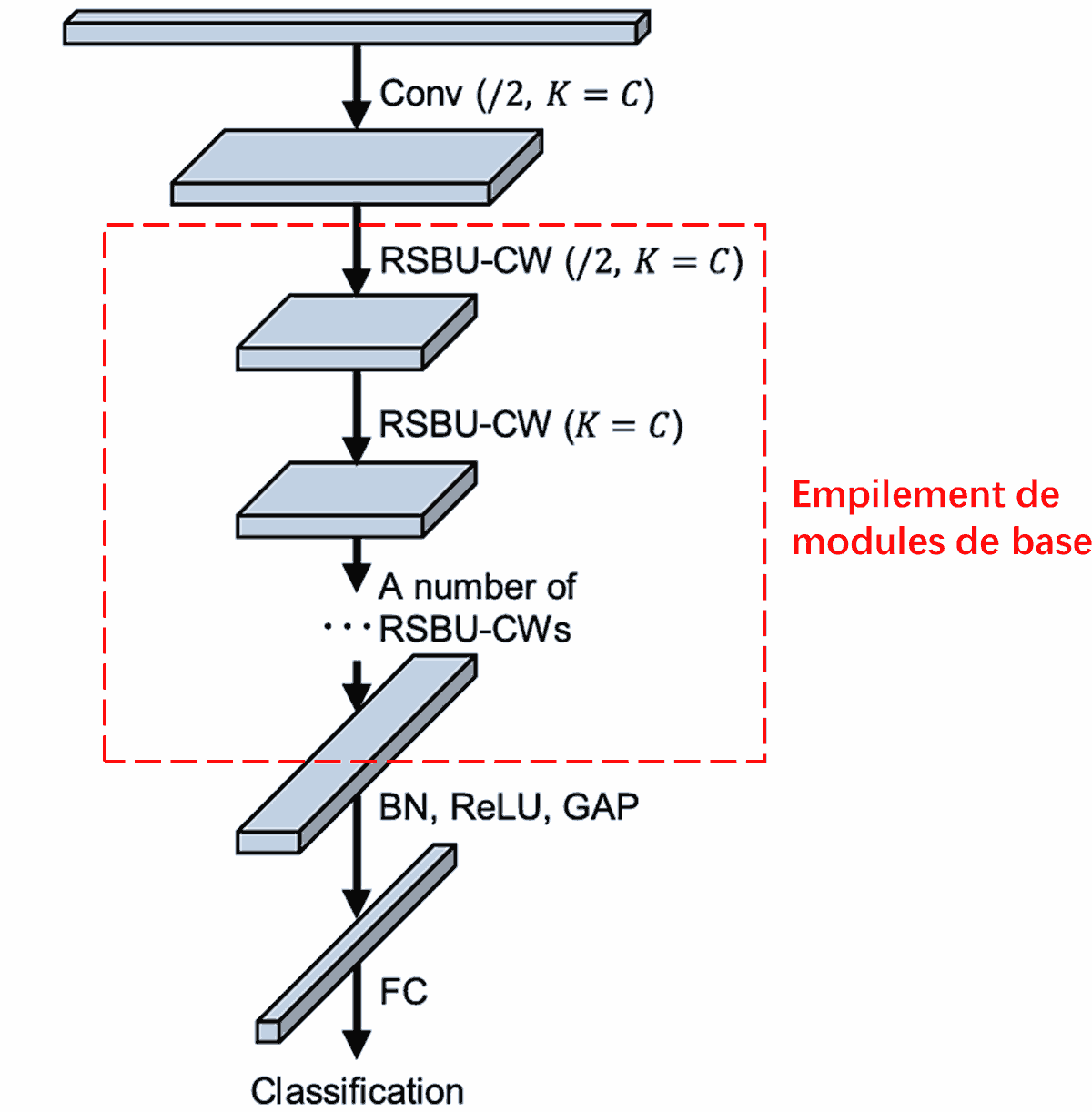
5. Capacité de généralisation
Le Deep Residual Shrinkage Network est en fait une méthode d’apprentissage de caractéristiques générique. En effet, dans de nombreuses tâches d’apprentissage, les échantillons contiennent plus ou moins de bruit et d’informations non pertinentes. Ces éléments parasites peuvent affecter la performance du modèle. Par exemple :
En classification d’images, si une image contient de nombreux autres objets en arrière-plan, ceux-ci peuvent être considérés comme du “bruit”. Le DRSN pourrait utiliser le mécanisme d’attention pour cibler ce “bruit” et le seuillage doux pour annuler les caractéristiques correspondantes, améliorant ainsi la précision de la classification.
En reconnaissance vocale, dans des environnements bruyants (bord de route, atelier d’usine), le DRSN pourrait améliorer la précision de la reconnaissance, ou du moins offrir une approche prometteuse pour y parvenir.
Références
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Impact académique
Cet article a été cité plus de 1400 fois sur Google Scholar.
Selon des statistiques non exhaustives, le Deep Residual Shrinkage Network a été utilisé directement ou amélioré dans plus de 1000 publications, couvrant des domaines variés tels que la mécanique, l’ingénierie électrique, la vision par ordinateur, le domaine médical, le traitement de la parole et du texte, le radar et la télédétection.