La Deep Residual Shrinkage Network (DRSN) es una variante mejorada de la clásica ResNet (Deep Residual Network). En esencia, integra la arquitectura residual, mecanismos de atención y funciones de umbralización suave (soft thresholding).
Su principio de funcionamiento se puede resumir así: utiliza mecanismos de atención para identificar características (features) irrelevantes y emplea soft thresholding para anularlas (llevarlas a cero); simultáneamente, identifica y preserva las características relevantes. Esto potencia la capacidad de la red neuronal para extraer información útil incluso en señales altamente ruidosas.
1. Motivación de la investigación
En primer lugar, es inevitable que las muestras de clasificación contengan ruido, ya sea gaussiano, rosa, laplaciano, etc. En un sentido más amplio, las muestras suelen contener información ajena a la tarea actual, lo cual también se interpreta como ruido. Este ruido degrada el rendimiento del modelo. (Cabe notar que el soft thresholding es un paso clave en algoritmos tradicionales de denoising de señales).
Por ejemplo, en una conversación junto a una carretera, el audio se mezcla con el claxon de los coches y el ruido del tráfico. Si aplicamos reconocimiento de voz, el resultado se verá afectado. Desde la perspectiva del Deep Learning, las características correspondientes al tráfico deberían ser suprimidas internamente por la red para evitar interferencias.
En segundo lugar, la cantidad de ruido varía entre muestras dentro del mismo dataset. (Esto se alinea con el concepto de atención: igual que la posición de un objeto varía entre imágenes y la red debe “enfocar” su atención en lugares distintos).
Imaginemos que entrenamos un clasificador “perro vs. gato” con 5 imágenes de perros: la 1ª tiene un perro y un ratón, la 2ª un perro y un ganso, la 3ª un perro y una gallina, etc. Durante el entrenamiento, el clasificador sufrirá la interferencia de estos objetos irrelevantes (ratones, gansos…), reduciendo la precisión (accuracy). Si logramos identificar y anular las características de estos elementos ajenos, mejoraremos significativamente el rendimiento del clasificador.
2. Umbralización Suave (Soft Thresholding)
El soft thresholding es fundamental en la reducción de ruido. Consiste en eliminar las características cuyo valor absoluto es menor que un umbral (τ) y “contraer” hacia cero aquellas cuyo valor absoluto es mayor. La fórmula es:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]La derivada de la salida respecto a la entrada es:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Como se observa, la derivada es 1 o 0. Esta propiedad es idéntica a la función de activación ReLU. Por tanto, el soft thresholding también ayuda a mitigar el riesgo de vanishing gradient (desvanecimiento del gradiente) y exploding gradient en redes profundas.
Para configurar el umbral, se deben cumplir dos condiciones: 1) debe ser positivo; 2) no puede superar el valor máximo de la señal de entrada (o la salida sería cero).
Además, existe una tercera condición ideal: cada muestra debe tener su propio umbral independiente, adaptado a su nivel de ruido específico.
Esto es crucial porque el ruido no es homogéneo. En un mismo dataset, la Muestra A puede ser limpia y la Muestra B muy ruidosa. Por ende, la Muestra A requiere un umbral bajo y la B uno alto. Aunque en Deep Learning los umbrales pierden su significado físico explícito, la lógica de adaptabilidad se mantiene.
3. Mecanismo de Atención
El concepto es intuitivo en Visión por Computador (Computer Vision). El sistema visual biológico escanea rápidamente para detectar un objeto y luego “focaliza” su atención en él para extraer detalles, ignorando el fondo.
SENet (Squeeze-and-Excitation Network) es un referente en este campo. SENet asume que la contribución de cada canal de características (feature channel) varía según la muestra. Utiliza una sub-red para aprender un conjunto de pesos (weights) que, al multiplicarse por los canales, ajustan su importancia relativa.
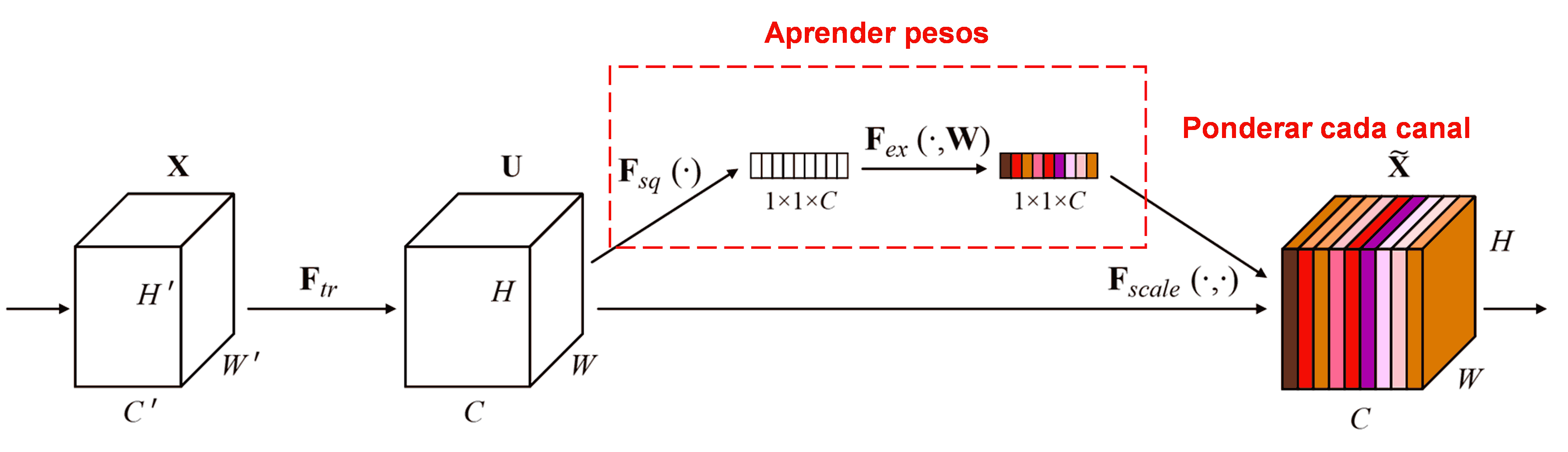
En este enfoque, cada muestra genera sus propios pesos. En SENet, estos se obtienen mediante: “Global Average Pooling → Capa Densa (Fully Connected) → ReLU → Capa Densa → Sigmoide”.
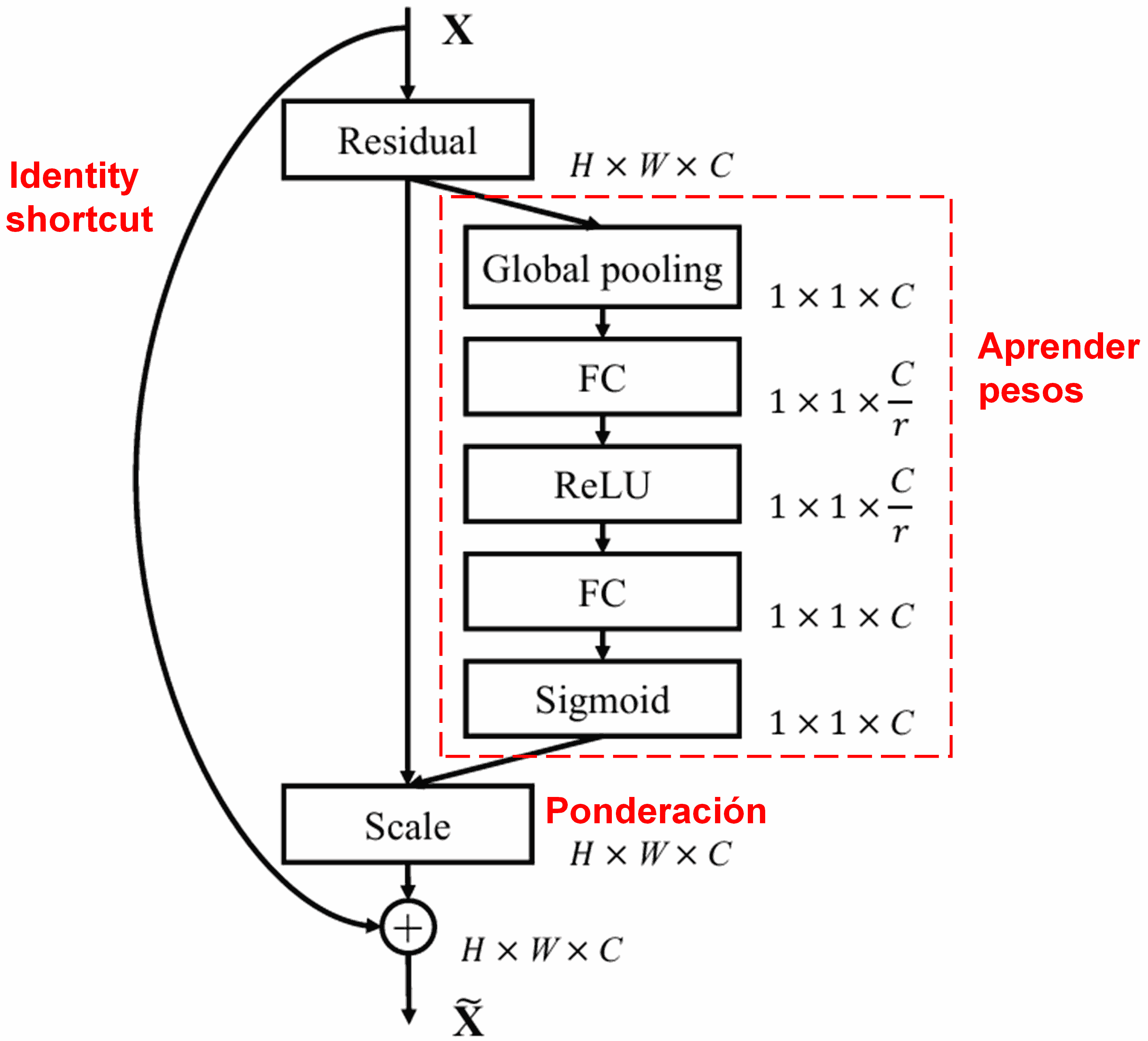
4. Umbralización Suave con Atención Profunda
La DRSN se inspira en la estructura de SENet para implementar un soft thresholding adaptativo. A través de una sub-red (marcada en rojo en los diagramas originales), la red aprende automáticamente el umbral óptimo para cada canal.
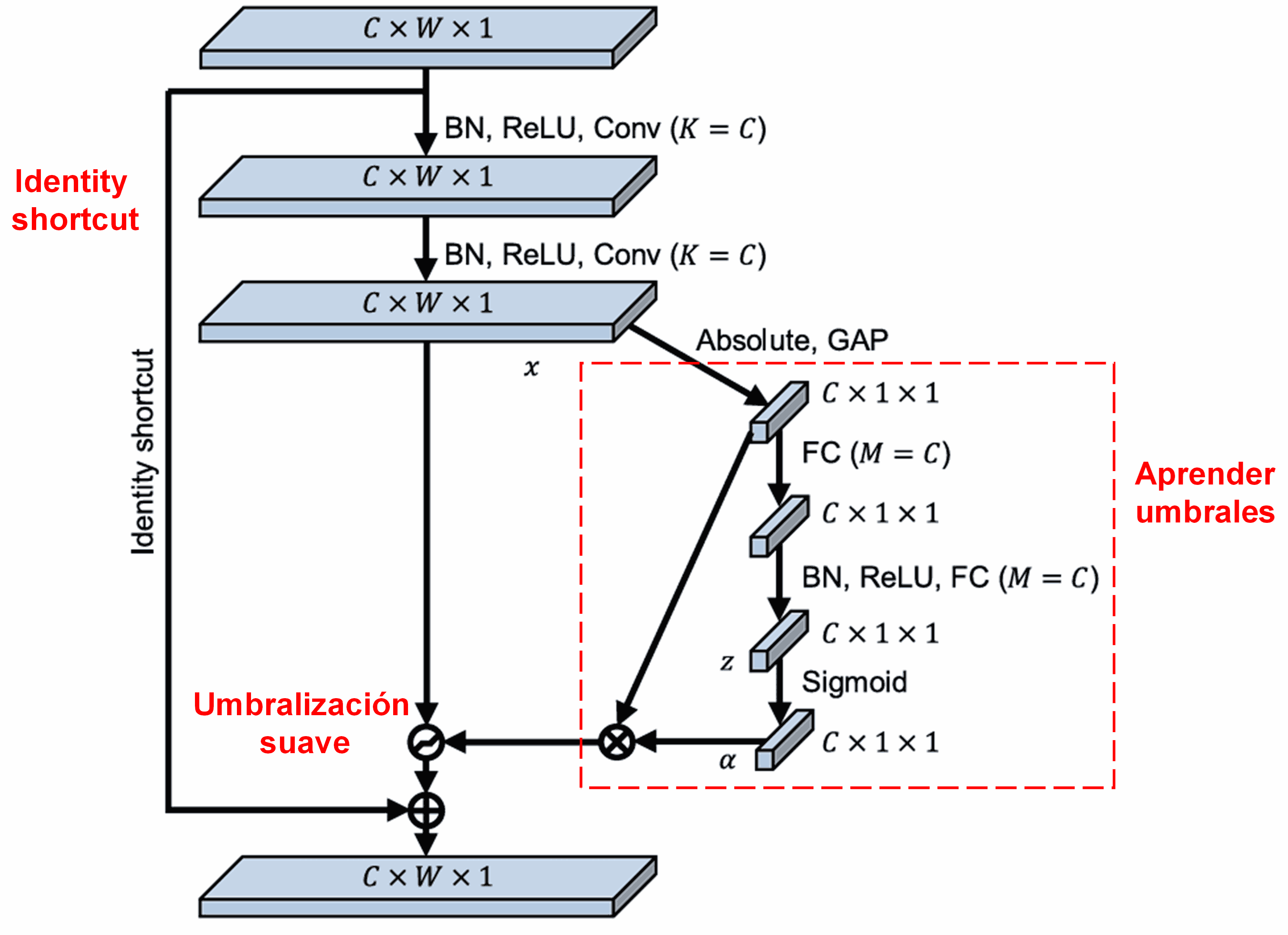
El proceso es el siguiente: primero se calcula el valor absoluto de todas las características del feature map de entrada. Luego, mediante Global Average Pooling, se obtiene un valor promedio A. Paralelamente, el mapa pasa por una pequeña red densa que finaliza en una función Sigmoide, generando un coeficiente α (entre 0 y 1). El umbral final se calcula como α×A. Esto garantiza un umbral positivo y de magnitud controlada.
Lo brillante de este método es que cada muestra genera un umbral distinto. Funciona como un mecanismo de atención especializado: detecta características irrelevantes, las lleva cerca de 0 mediante capas convolucionales y las anula con el soft thresholding; a su vez, preserva las características relevantes.
Finalmente, la red completa se construye apilando estos módulos básicos junto con capas convolucionales, Batch Normalization, activaciones, Global Average Pooling y la capa de salida.
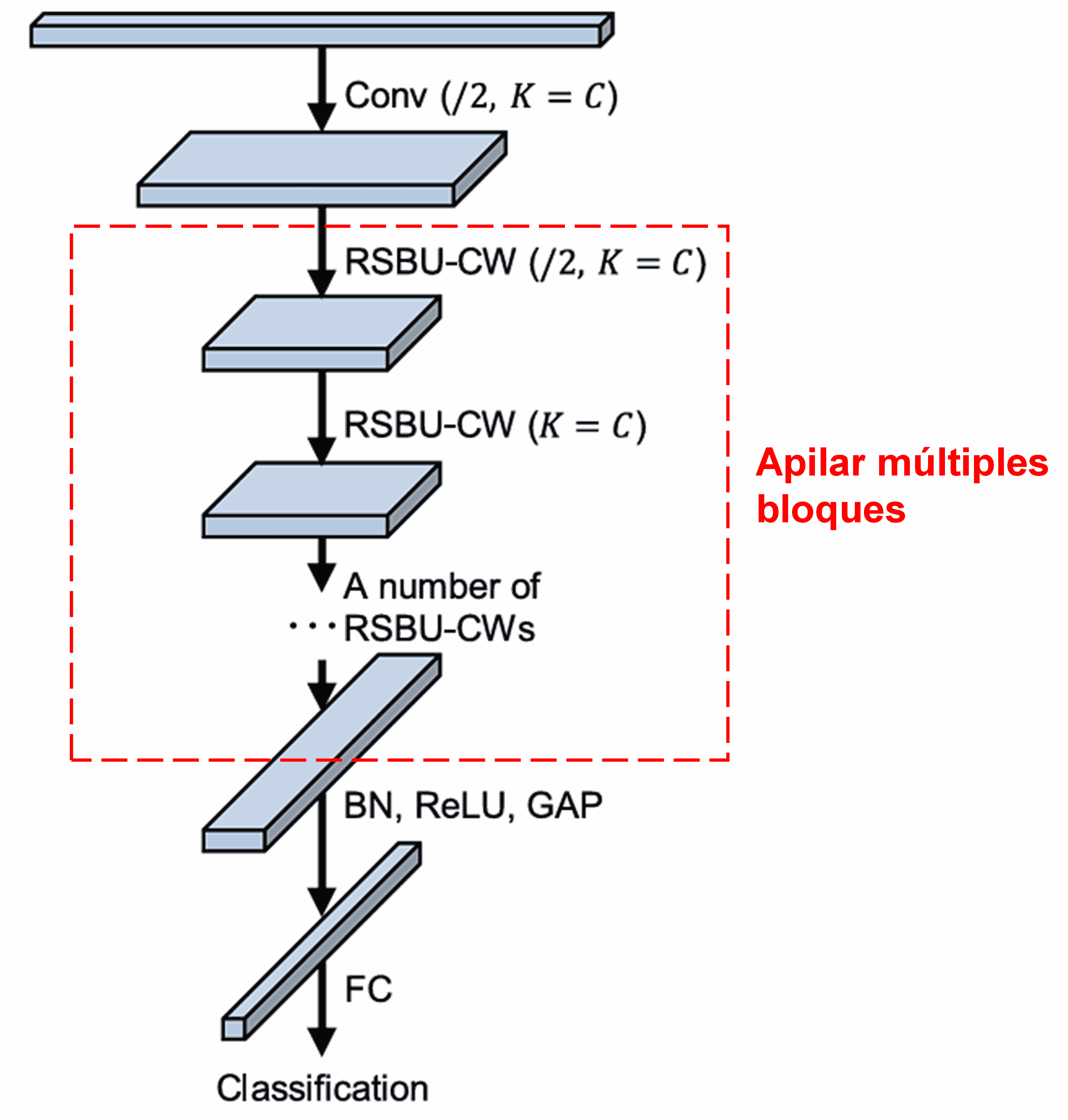
5. Capacidad de Generalización
La DRSN es, de hecho, un método de aprendizaje de características (feature learning) de propósito general, aplicable siempre que las muestras contengan ruido o información irrelevante.
- En clasificación de imágenes: Si el fondo contiene objetos distractores (“ruido”), la red puede usar la atención para detectarlos y anular sus características mediante soft thresholding, mejorando la precisión.
- En reconocimiento de voz: En entornos ruidosos (fábricas, tráfico), la red ofrece una metodología robusta para limpiar la señal y mejorar la tasa de reconocimiento.
Referencias
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Impacto Académico
El artículo original cuenta con más de 1400 citas en Google Scholar.
Se estima que la Deep Residual Shrinkage Network ha sido aplicada o mejorada en más de 1000 publicaciones en campos tan diversos como ingeniería mecánica, sistemas eléctricos, visión por computador, medicina, procesamiento de voz y texto, radar y teledetección.