Deep Residual Shrinkage Network je improved variant ti Deep Residual Network. Ni pataki, o je integration ti Deep Residual Network, attention mechanisms, ati soft thresholding functions.
Ni ipele kan, a le loye bi Deep Residual Shrinkage Network se n sise bayi: o n lo attention mechanisms lati identify awon features ti ko important, o si n lo soft thresholding functions lati set won si zero; ni idakeji, o n identify awon features ti o important, o si n retain won. Process yii n mu agbara deep neural network lagbara lati extract awon useful features lati inu signals ti o ni noise.
1. Motivation fun Research
Akoko, nigba ti a ba n classify awon samples, noise—bi Gaussian noise, pink noise, ati Laplacian noise—ma n wa nibe dandan. Ni gbogbo e, awon samples ma n saba ni information ti ko relevant si current classification task, eyi ti a le tumo si noise. Noise yii le ni negative effect lori classification performance. (Soft thresholding je step pataki ninu opolopo signal denoising algorithms.)
Fun apere, nigba ti a ba n soro leti titi, audio yen le ni sounds ti car horns ati wheels. Nigba ti a ba n se speech recognition lori awon signals wanyi, awon results ma affect dandan latari awon background sounds yii. Lati oju iwoye deep learning, awon features ti o correspond si horns ati wheels yen ye ki a eliminate won kuro ninu deep neural network lati prevent ki won ma ba speech recognition results je.
Ekeji, paapaa ninu dataset kanna, amount noise saba ma n yato lati sample kan si ekeji. (Eyi ni similarities pelu attention mechanisms; ti a ba fi image dataset se apere, location ti target object le yato ninu awon images, attention mechanisms si le focus lori specific location ti target object ninu image kookan.)
Fun apere, nigba ti a ba n train cat-and-dog classifier, e je ki a gbe images marun yewo ti a label bi “aja.” Image akoko le ni aja ati eku (mouse), ekeji le ni aja ati pepeye (goose), eketa le ni aja ati adiye (chicken), ekerin le ni aja ati ketekete (donkey), karun si le ni aja ati pepeye-odo (duck). Nigba training, classifier yen ma ni interference latari awon irrelevant objects bi mice, geese, chickens, donkeys, ati ducks, eyi ti o le fa decrease ninu classification accuracy. Ti a ba le identify awon irrelevant objects yii—awon mice, geese, chickens, donkeys, ati ducks—ki a si eliminate awon features won, o seese ki a improve accuracy ti cat-and-dog classifier yen.
2. Soft Thresholding
Soft thresholding je core step ninu opolopo signal denoising algorithms. O n eliminate awon features ti absolute values won kere ju threshold kan lo, o si n shrink awon features ti absolute values won ga ju threshold yii lo si odo (zero). O le je implemented pelu formula yii:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Derivative ti soft thresholding output pẹlu respect si input ni:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Gege bi a se ko soke, derivative ti soft thresholding je 1 tabi 0. Property yii jora pelu ti ReLU activation function. Nitorinaa, soft thresholding tun le reduce risk ki deep learning algorithms ni gradient vanishing ati gradient exploding.
Ninu soft thresholding function, setting ti threshold gbodo satisfy awon conditions meji: akoko, threshold gbodo je positive number; ekeji, threshold ko gbodo ju maximum value ti input signal lo, ti ko ba ri be, output ma je zero patapata.
Pelu eyi, o da ki threshold satisfy condition keta: sample kookan gbodo ni independent threshold ti tie base lori noise content re.
Idi ni pe, noise content saba ma n yato laarin awon samples. Fun apere, o wopo ninu dataset kanna fun Sample A lati ni noise kekere nigba ti Sample B ni noise pupo. Ni case yii, nigba ti a ba n se soft thresholding ninu denoising algorithm, Sample A ye ki o lo threshold kekere, nigba ti Sample B ye ki o lo threshold nla. Botilejepe awon features ati thresholds yii le lose explicit physical definitions won ninu deep neural networks, basic logic yen si wa bakanna. Iyene ni pe, sample kookan ye ki o ni independent threshold ti o determine nipase specific noise content re.
3. Attention Mechanism
Awon attention mechanisms rorun lati loye ni field ti computer vision. Visual systems ti awon eranko le distinguish targets nipa sise scanning gbogbo area ni kia-kia, leyin naa won a focus attention lori target object lati extract awon details to po si, lakoko ti won n suppress irrelevant information. Fun specifics, e jowo refer si literature nipa attention mechanisms.
Squeeze-and-Excitation Network (SENet) je deep learning method tuntun ti o n lo attention mechanisms. Laarin awon samples to yato, contribution ti awon feature channels to yato si classification task saba ma n yato. SENet n lo sub-network kekere kan lati gba set ti weights, leyin naa a o multiply awon weights yii pelu awon features ti awon channels yen lati adjust magnitude awon features ninu channel kookan. Process yii le je wiwo bi apply levels ti attention to yato si awon feature channels to yato.
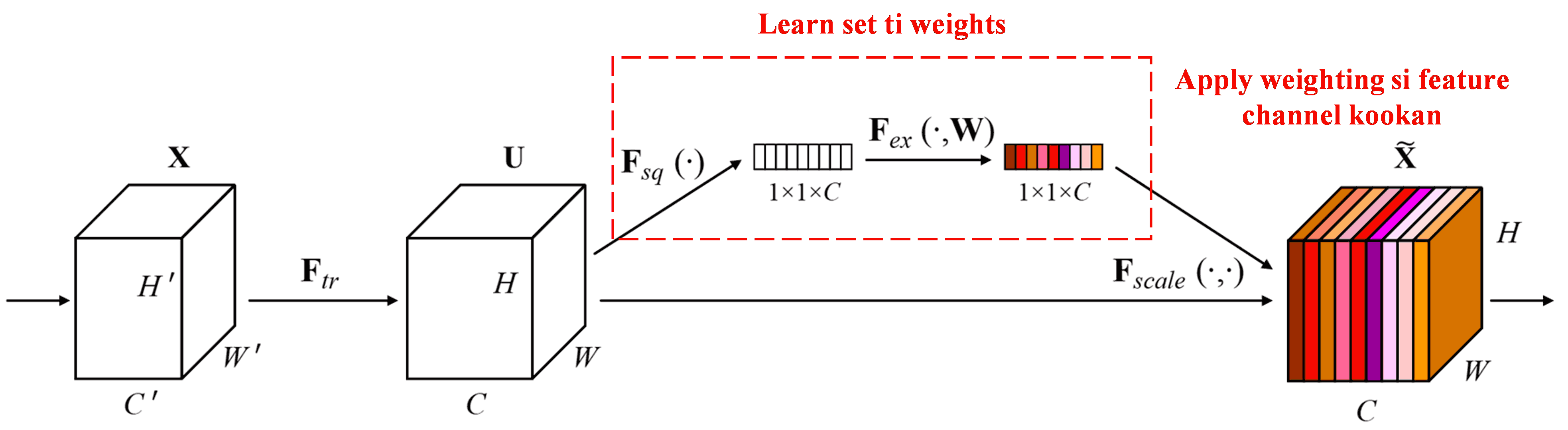
Ninu approach yii, gbogbo sample lo ni independent set ti weights ti tie. Ni oro miran, awon weights fun awon samples meji eyikeyi ma yato. Ninu SENet, specific path lati gba awon weights ni “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function.”
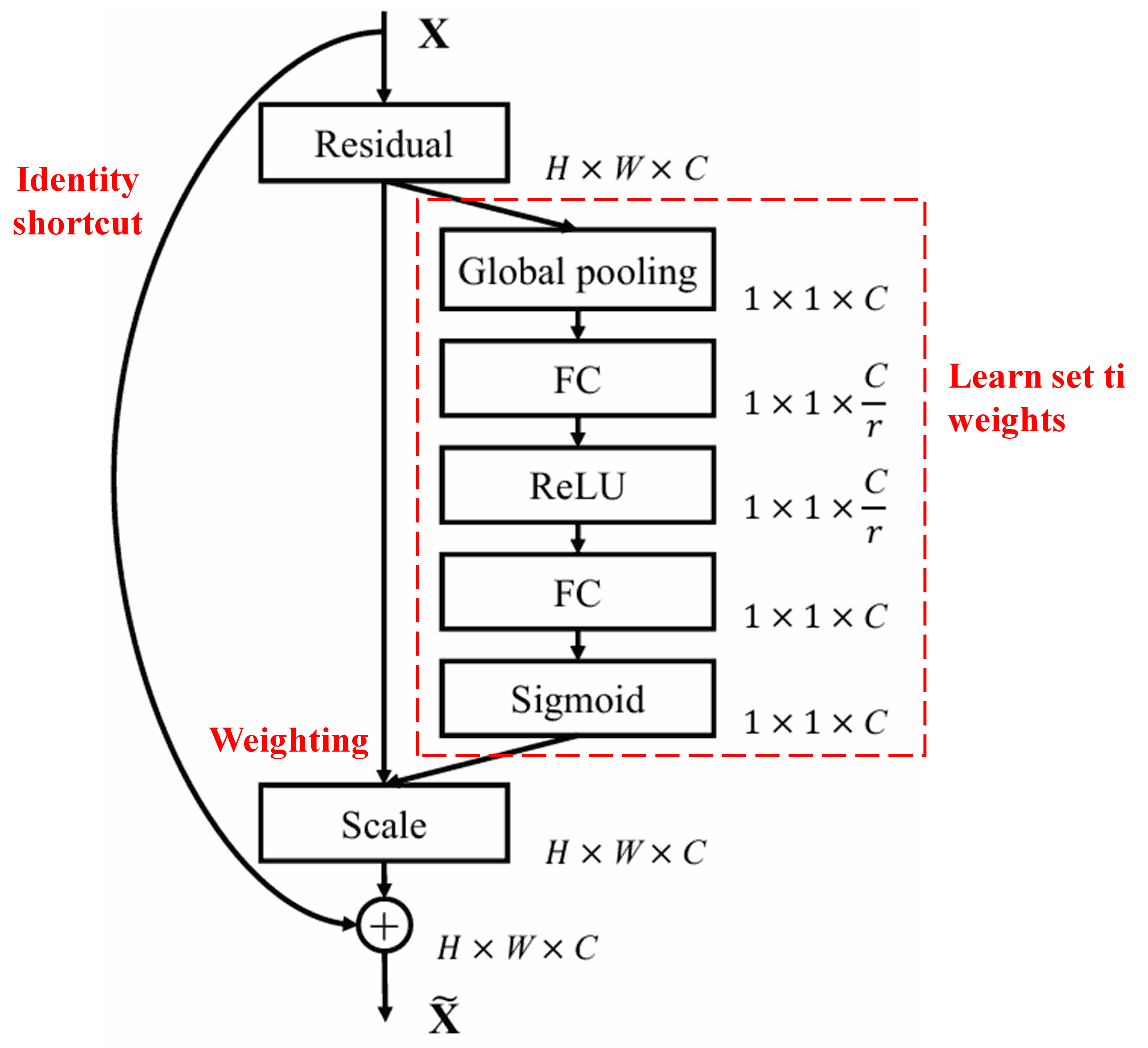
4. Soft Thresholding pẹlu Deep Attention Mechanism
Deep Residual Shrinkage Network gba inspiration lati structure ti SENet sub-network ti a menu ba lekan lati implement soft thresholding labe deep attention mechanism. Nipase sub-network naa (ti a indicate sinu red box), set ti thresholds le je kikeko (learned) lati apply soft thresholding si feature channel kookan.
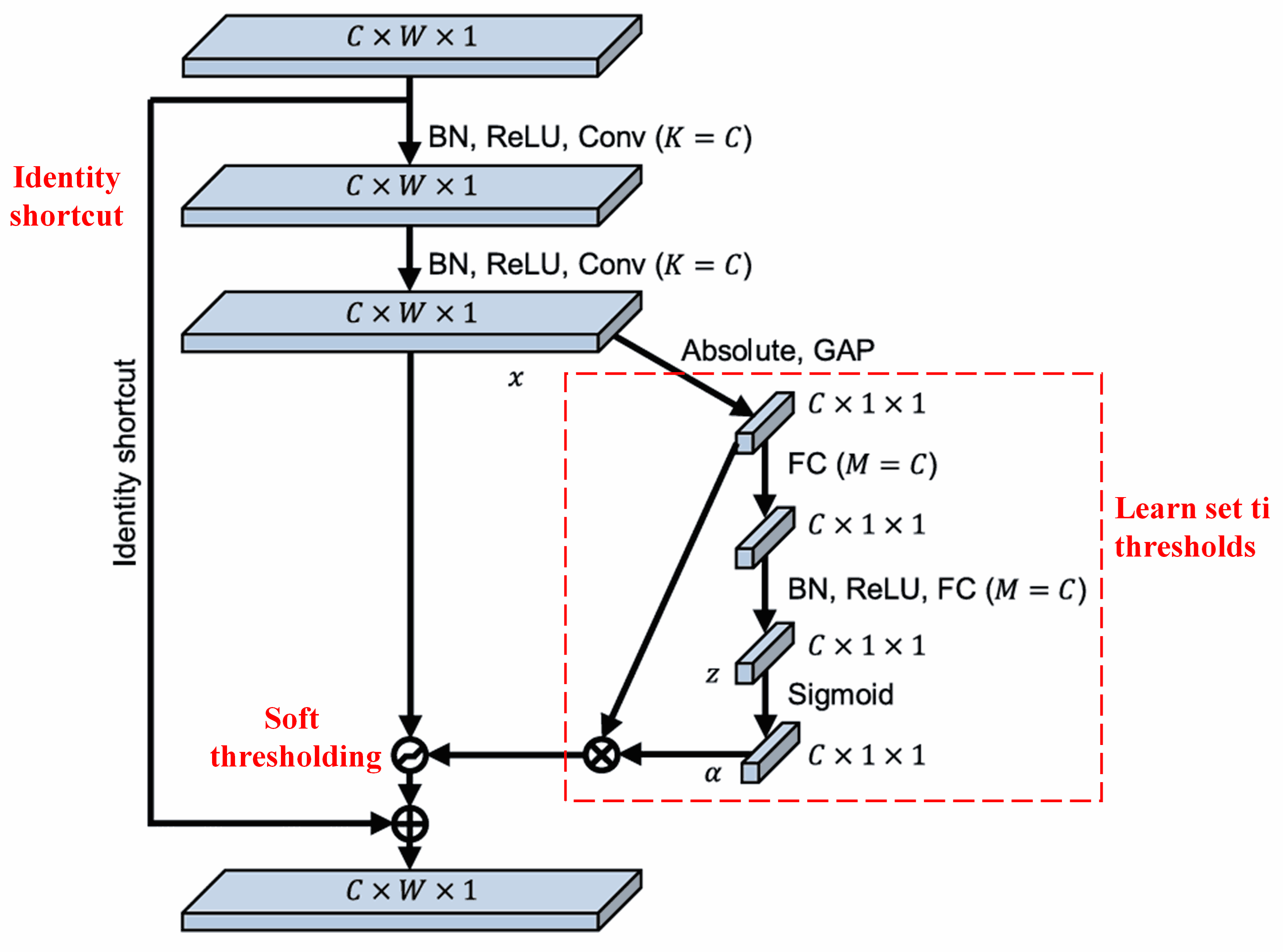
Ninu sub-network yii, a koko calculate awon absolute values ti gbogbo features ninu input feature map. Leyin naa, nipase global average pooling ati averaging, a o gba feature kan, ti a pe ni A. Ni ona miran, feature map leyin global average pooling ni a o fi sinu fully connected network kekere kan. Fully connected network yii n lo Sigmoid function gege bi layer ti o gbeyin lati normalize output si aarin 0 ati 1, eyi fun wa ni coefficient ti a pe ni α. Final threshold le je ifihan bi α × A. Nitorinaa, threshold je product ti number kan laarin 0 ati 1 ati average ti awon absolute values ti feature map. Method yii ensure pe threshold kii se positive nikan, sugbon ko tun too large ju.
Siwaju si, awon samples ti o yato ma ni awon thresholds ti o yato. Consequently, ni ipele kan, eyi le je titumo si specialized attention mechanism: o n identify awon features ti ko relevant si current task, o n transform won si values ti o sunmo zero nipase convolutional layers meji, o si n set won si zero nipa lilo soft thresholding; tabi ki a so pe, o n identify awon features ti o relevant si current task, o n transform won si values ti o jinna si zero nipase convolutional layers meji, o si n preserve won.
Ni ipari, nipa stacking number ti awon basic modules kan pẹlu convolutional layers, batch normalization, activation functions, global average pooling, ati fully connected output layers, a ti construct complete Deep Residual Shrinkage Network.
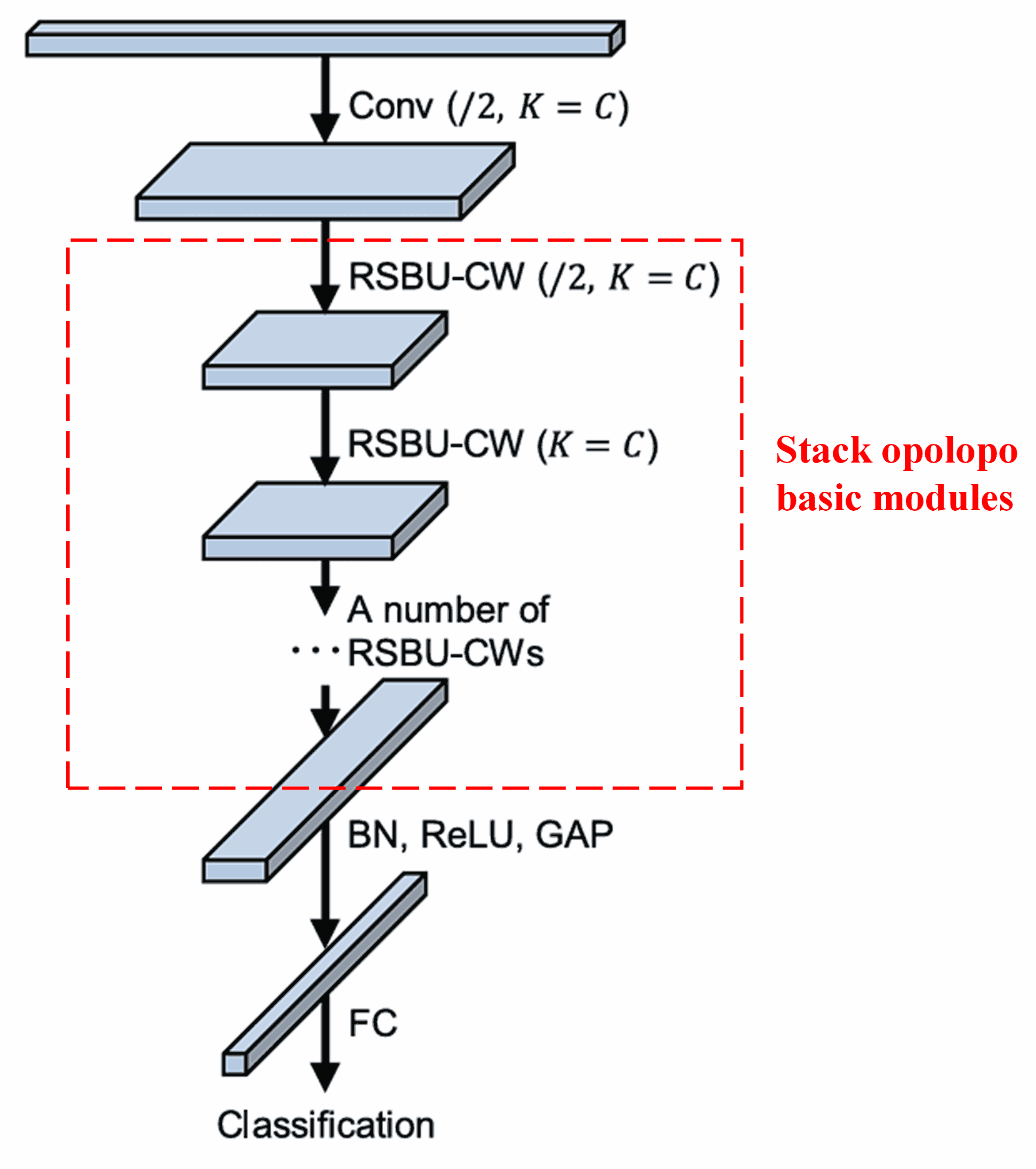
5. Agbara Generalization
Deep Residual Shrinkage Network je general feature learning method patapata. Idi ni pe, ninu opolopo feature learning tasks, awon samples ma n ni noise diẹ tabi pupo pelu irrelevant information. Noise ati irrelevant information yii le affect performance ti feature learning. Fun apere:
Ninu image classification, ti image kan ba ni awon objects miran ninu lopolopo, awon objects yii le je wiwo bi “noise.” Deep Residual Shrinkage Network le ni agbara lati lo attention mechanism lati notice “noise” yii, ki o si lo soft thresholding lati set awon features ti o correspond si “noise” yii si zero, eyi le improve image classification accuracy.
Ninu speech recognition, specifically ni awon environments ti o ni noise bi conversational settings leti titi tabi inu factory workshop, Deep Residual Shrinkage Network le improve speech recognition accuracy, tabi ki o fun wa ni methodology ti o le improve speech recognition accuracy.
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Impact ninu Academia
Paper yii ti gba citations to ju 1,400 lo lori Google Scholar.
Base lori statistics ti ko ti pe tan, Deep Residual Shrinkage Network (DRSN) ti je lilo taara tabi ti a modify ninu awon publications/studies to ju 1,000 lo kakiri awon fields to po, pẹlu mechanical engineering, electrical power, vision, healthcare, speech, text, radar, ati remote sensing.