Deep Residual Shrinkage Network (DRSN) – bu Deep Residual Network (ResNet) ning takomillashtirilgan variantidir. Aslida, u Deep Residual Network, Attention mexanizmlari va Soft Thresholding funksiyalarining integratsiyasidir.
Ma’lum darajada, Deep Residual Shrinkage Networkning ishlash prinsipini quyidagicha tushunish mumkin: u Attention mexanizmidan foydalanib, muhim bo’lmagan featurelarni (belgilar) aniqlaydi va Soft Thresholding orqali ularni nolga tenglashtiradi; aksincha, muhim featurelarni aniqlab, ularni saqlab qoladi. Bu jarayon Deep Neural Networklarning (chuqur neyron tarmoqlar) shovqinli signallardan foydali featurelarni ajratib olish qobiliyatini kuchaytiradi.
1. Tadqiqot motivatsiyasi (Research Motivation)
Birinchidan, namunalarni (samples) klassifikatsiya qilishda shovqin – masalan, Gauss shovqini, pushti shovqin (pink noise) va Laplas shovqini – bo’lishi muqarrar. Kengroq ma’noda, namunalar ko’pincha joriy klassifikatsiya vazifasiga aloqador bo’lmagan ma’lumotlarni o’z ichiga oladi, buni ham shovqin (noise) deb tushunish mumkin. Bu shovqin klassifikatsiya samaradorligiga salbiy ta’sir ko’rsatishi mumkin. (Soft Thresholding ko’plab signalni tozalash [signal denoising] algoritmlarida muhim qadam hisoblanadi.)
Masalan, yo’l chetidagi suhbat davomida audio yozuvga mashina signallari va g’ildirak tovushlari aralashib qolishi mumkin. Ushbu signallarda nutqni aniqlash (speech recognition) amalga oshirilganda, natijalar muqarrar ravishda ushbu fon tovushlaridan ta’sirlanadi. Deep Learning nuqtai nazaridan, nutqni aniqlash natijalariga ta’sir qilmasligi uchun, mashina signallari va g’ildirak tovushlariga mos keladigan featurelar Deep Neural Network ichida yo’q qilinishi kerak.
Ikkinchidan, hatto bitta dataset ichida ham, shovqin miqdori ko’pincha namunadan namunaga farq qiladi. (Bu Attention mexanizmlari bilan o’xshashlikka ega; tasvirlar datasetini misol qilib olsak, maqsadli obyektning joylashuvi har bir rasmda har xil bo’lishi mumkin va Attention mexanizmlari har bir rasmda maqsadli obyektning aniq joylashuviga e’tibor qaratishi mumkin.)
Masalan, it va mushuk klassifikatorini o’qitishda (training), “it” deb belgilangan beshta rasmni ko’rib chiqaylik. Birinchi rasmda it va sichqon, ikkinchisida it va g’oz, uchinchisida it va tovuq, to’rtinchisida it va eshak, beshinchisida esa it va o’rdak bo’lishi mumkin. O’qitish jarayonida klassifikator muqarrar ravishda sichqonlar, g’ozlar, tovuqlar, eshaklar va o’rdaklar kabi aloqador bo’lmagan obyektlarning xalaqitiga uchraydi, bu esa klassifikatsiya aniqligining (accuracy) pasayishiga olib keladi. Agar biz ushbu aloqador bo’lmagan obyektlarni — sichqon, g’oz, tovuq, eshak va o’rdaklarni — aniqlab, ularga mos keladigan featurelarni yo’q qila olsak, it va mushuk klassifikatorining aniqligini oshirish mumkin bo’ladi.
2. Soft Thresholding
Soft Thresholding — ko’plab signalni tozalash (signal denoising) algoritmlarining asosiy qadamidir. U absolut qiymatlari ma’lum bir bo’sag’adan (threshold) past bo’lgan featurelarni yo’q qiladi va absolut qiymatlari bu bo’sag’adan yuqori bo’lgan featurelarni nolga qarab qisqartiradi (shrinkage). U quyidagi formula yordamida amalga oshirilishi mumkin:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Soft Thresholding natijasining kirishga nisbatan hosilasi (derivative) quyidagicha:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Yuqorida ko’rsatilganidek, Soft Thresholding funksiyasining hosilasi 1 yoki 0 ga teng. Bu xususiyat ReLU aktivatsiya funksiyasi (activation function) bilan bir xil. Shuning uchun, Soft Thresholding ham Deep Learning algoritmlarida gradient yo’qolishi (gradient vanishing) va gradient portlashi (gradient exploding) xavfini kamaytirishi mumkin.
Soft Thresholding funksiyasida threshold (bo’sag’a)ni sozlash ikkita shartni qanoatlantirishi kerak: birinchidan, threshold musbat son bo’lishi kerak; ikkinchidan, threshold kirish signalining maksimal qiymatidan oshmasligi kerak, aks holda output (chiqish) butunlay nolga teng bo’ladi.
Bundan tashqari, threshold uchinchi shartni ham qanoatlantirishi maqsadga muvofiq: har bir namuna o’zining shovqin tarkibiga asoslangan mustaqil thresholdga ega bo’lishi kerak.
Buning sababi shundaki, shovqin miqdori ko’pincha namunalar orasida farq qiladi. Masalan, bitta dataset ichida A namunada kamroq shovqin, B namunada esa ko’proq shovqin bo’lishi odatiy holdir. Bunday holda, denoising algoritmida Soft Thresholding bajarilayotganda, A namunasi kichikroq thresholddan, B namunasi esa kattaroq thresholddan foydalanishi kerak. Garchi Deep Neural Networklarda bu featurelar va thresholdlar o’zlarining aniq fizik ta’riflarini yo’qotsalar-da, asosiy mantiq bir xil bo’lib qoladi. Boshqacha qilib aytganda, har bir namuna o’zining maxsus shovqin tarkibi bilan belgilanadigan mustaqil thresholdga ega bo’lishi kerak.
3. Attention Mechanism
Attention mexanizmlarini Computer Vision sohasida tushunish nisbatan oson. Hayvonlarning ko’rish tizimi butun hududni tezda skanerlash orqali nishonlarni ajrata oladi, so’ngra keraksiz ma’lumotlarni bostirib, ko’proq tafsilotlarni olish uchun e’tiborni (attention) nishon obyektiga qaratadi. Tafsilotlar uchun Attention mexanizmlariga oid adabiyotlarga murojaat qiling.
Squeeze-and-Excitation Network (SENet) — bu Attention mexanizmlaridan foydalanadigan nisbatan yangi Deep Learning usuli. Turli xil namunalarda turli xil feature kanallarining (channels) klassifikatsiya vazifasiga qo’shgan hissasi ko’pincha turlicha bo’ladi. SENet og’irliklar (weights) to’plamini olish uchun kichik bir quyi tarmoqdan (sub-network) foydalanadi va keyin har bir kanaldagi featurelarning kattaligini sozlash uchun ushbu og’irliklarni tegishli kanallarning featurelariga ko’paytiradi. Bu jarayonni turli feature kanallariga turli darajadagi “attention” qaratish deb hisoblash mumkin.
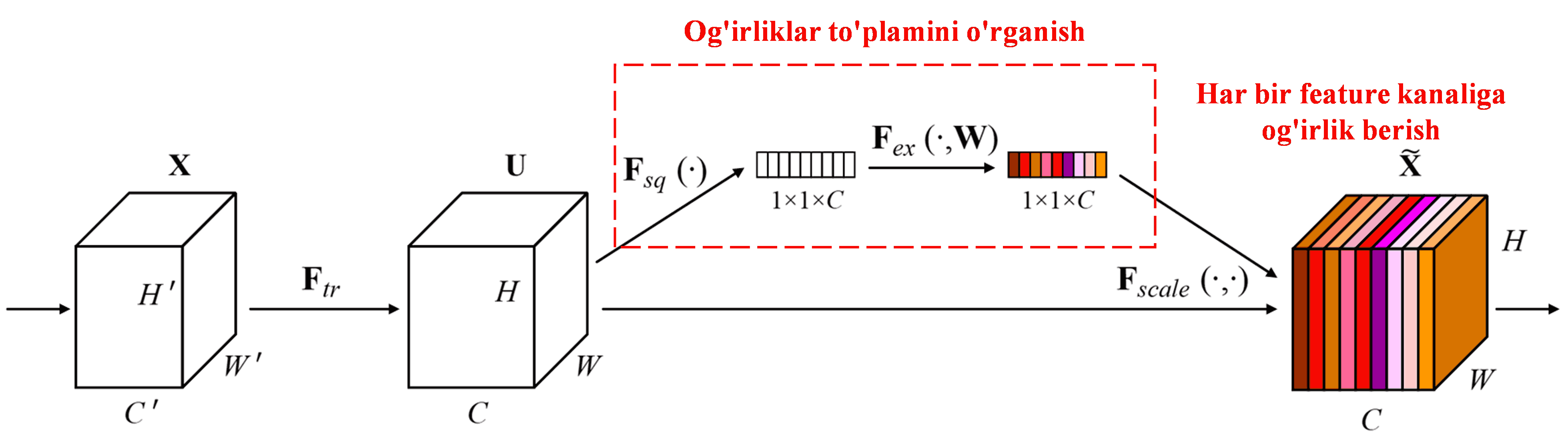
Ushbu yondashuvda har bir namuna o’zining mustaqil og’irliklar to’plamiga ega. Boshqacha qilib aytganda, har qanday ikkita ixtiyoriy namuna uchun og’irliklar har xil bo’ladi. SENet-da og’irliklarni olishning aniq yo’li: “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”.
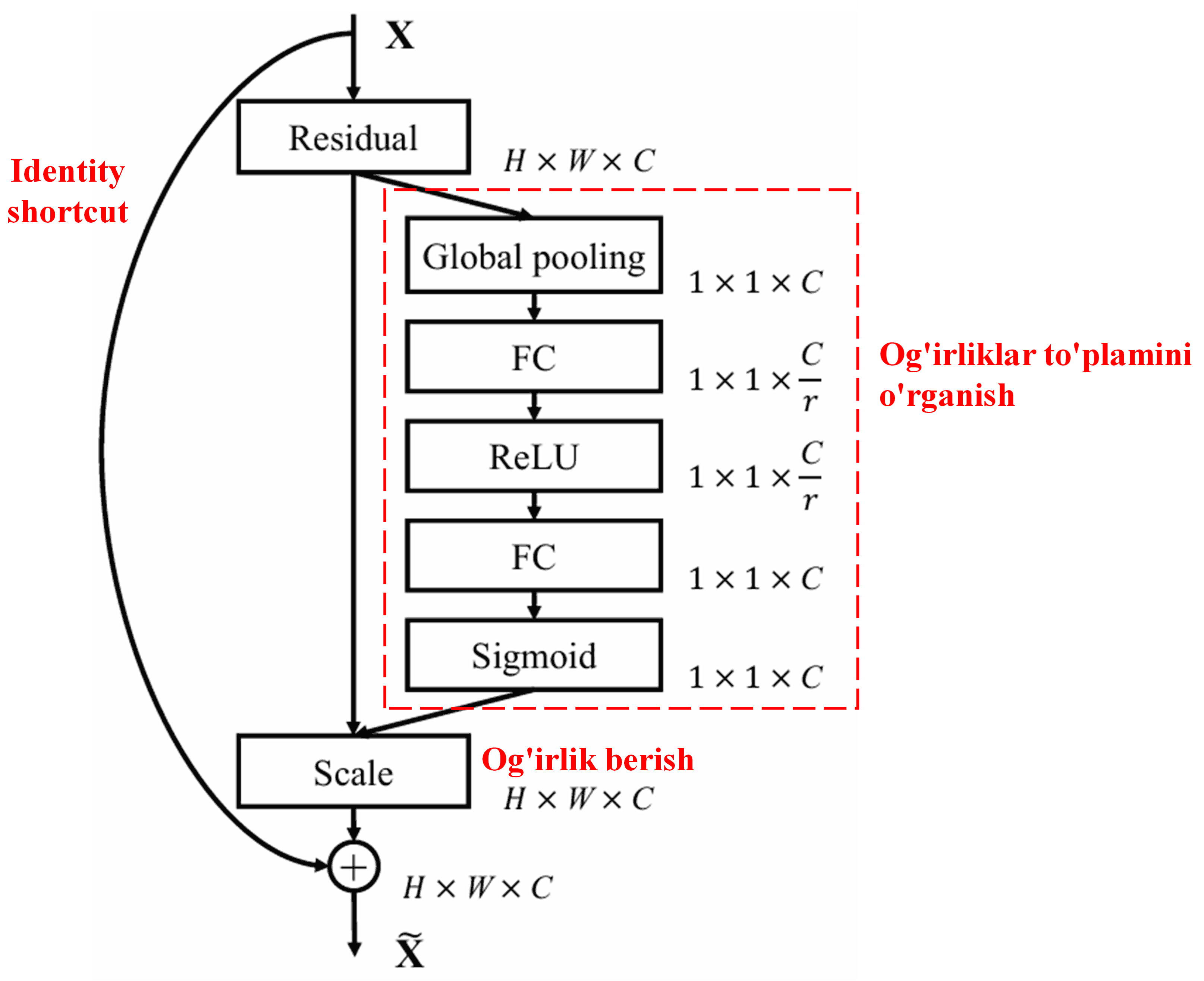
4. Deep Attention Mechanism ostida Soft Thresholding
Deep Residual Shrinkage Network yuqorida aytib o’tilgan SENet quyi tarmoq (sub-network) strukturasidan ilhomlanib, chuqur Attention mexanizmi ostida Soft Thresholdingni amalga oshiradi. Quyi tarmoq orqali (qizil ramka ichida ko’rsatilgan) har bir feature kanali uchun Soft Thresholding qo’llash maqsadida thresholdlar to’plamini o’rganish mumkin.
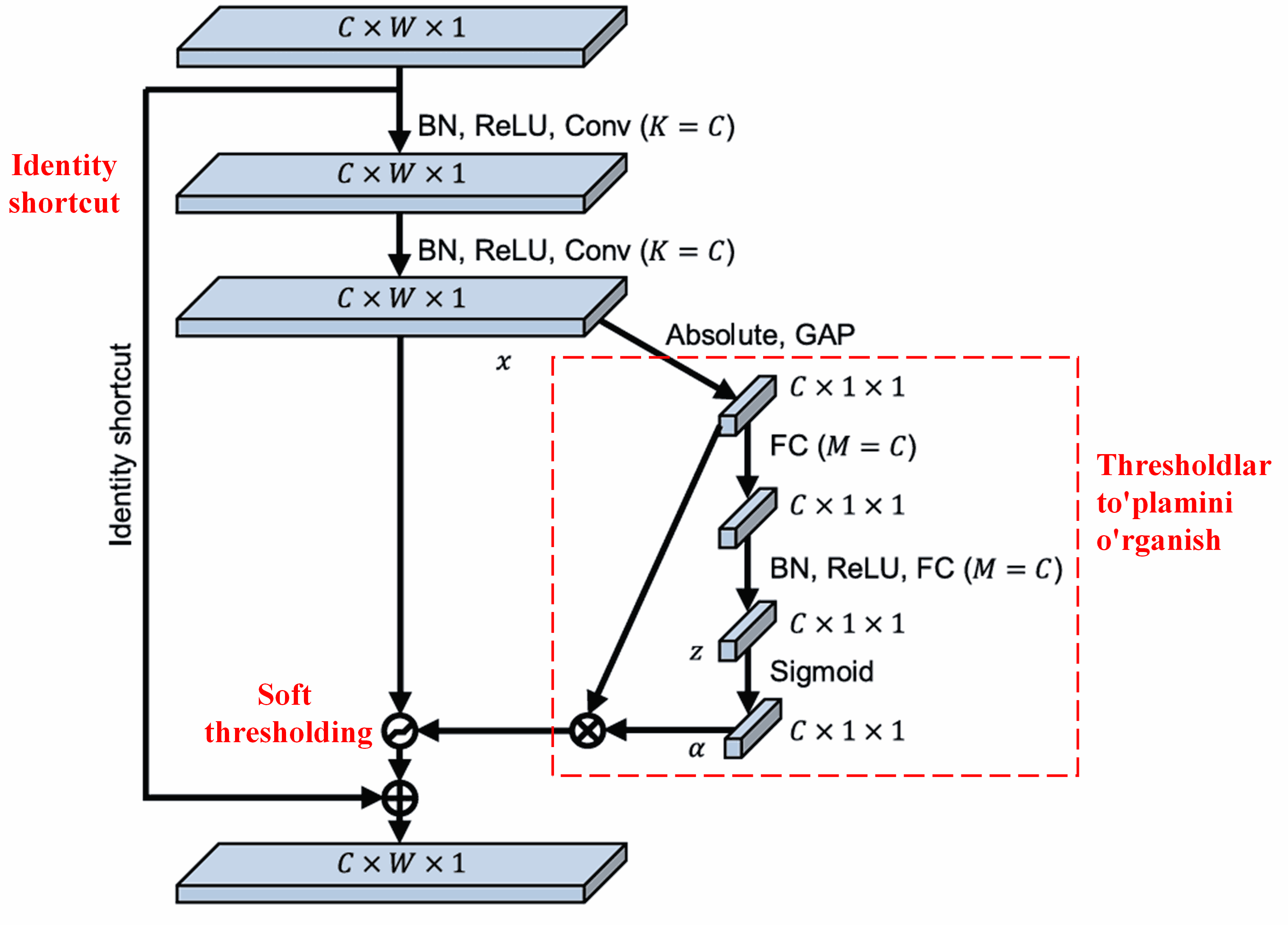
Ushbu quyi tarmoqda, avvalo, kirish feature mapidagi barcha featurelarning absolut qiymatlari hisoblanadi. Keyin, Global Average Pooling va o’rtacha hisoblash orqali A deb belgilanadigan feature olinadi. Boshqa yo’lda esa, Global Average Poolingdan keyingi feature map kichik Fully Connected tarmog’iga kiritiladi. Ushbu Fully Connected tarmoq chiqishni 0 va 1 oralig’ida normallashtirish uchun oxirgi qatlam (layer) sifatida Sigmoid funksiyasidan foydalanadi va α deb belgilanadigan koeffitsiyentni beradi. Yakuniy threshold α × A sifatida ifodalanishi mumkin. Shunday qilib, threshold — bu 0 va 1 orasidagi son va feature map absolut qiymatlari o’rtacha qiymatining ko’paytmasidir. Ushbu usul threshold nafaqat musbat bo’lishini, balki haddan tashqari katta bo’lmasligini ham ta’minlaydi.
Bundan tashqari, turli namunalar turli xil thresholdlarga olib keladi. Natijada, ma’lum darajada, buni ixtisoslashgan Attention mexanizmi deb tushunish mumkin: u joriy vazifaga aloqador bo’lmagan featurelarni aniqlaydi, ularni ikkita konvolyutsion (convolutional) qatlam orqali nolga yaqin qiymatlarga aylantiradi va Soft Thresholding yordamida ularni nolga tenglashtiradi; yoki aksincha, joriy vazifaga aloqador featurelarni aniqlaydi, ularni noldan uzoq qiymatlarga aylantiradi va ularni saqlab qoladi.
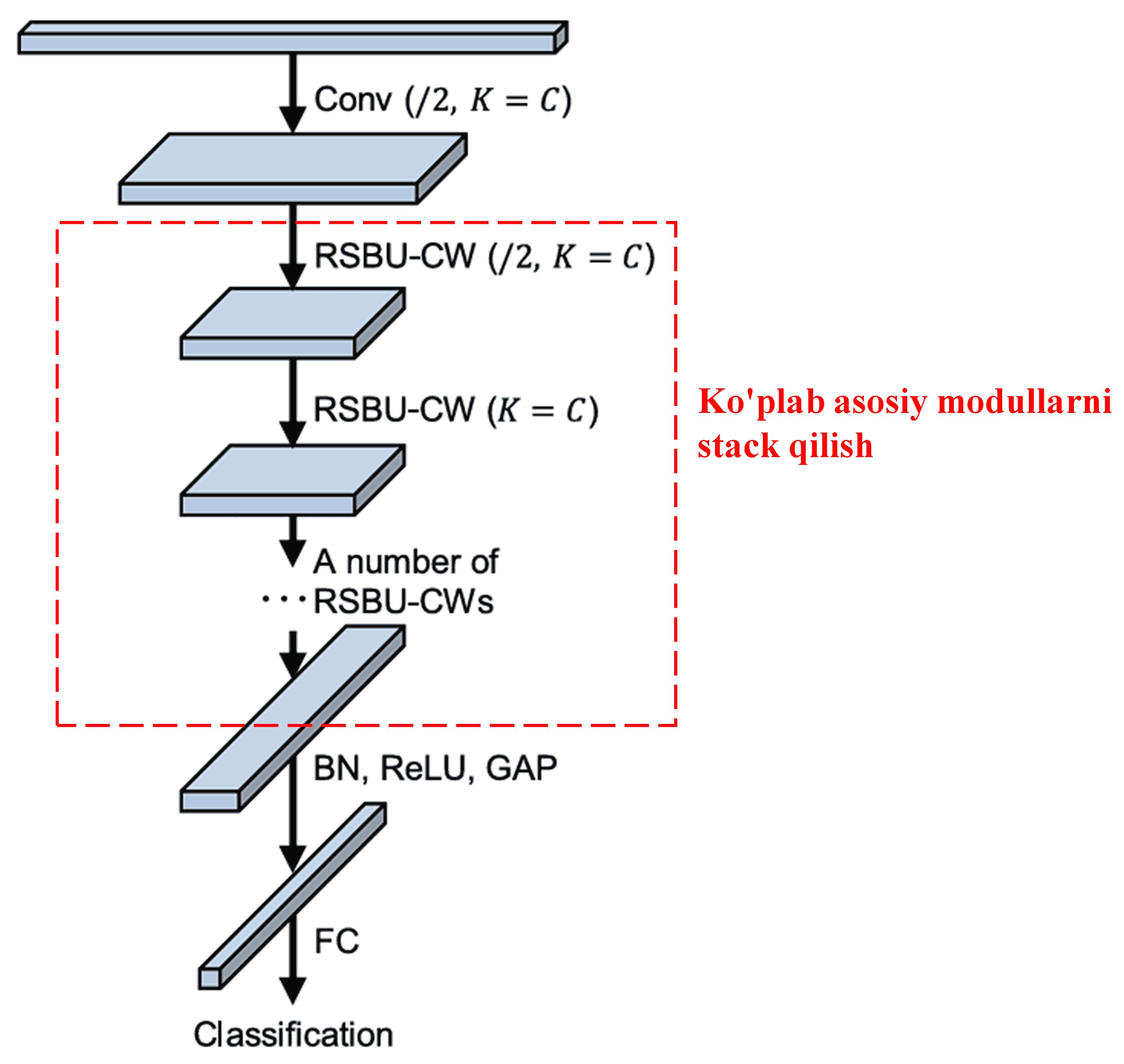
Yakunida, ma’lum miqdordagi asosiy modullarni Convolutional layerlar, Batch Normalization, aktivatsiya funksiyalari (Activation functions), Global Average Pooling va Fully Connected chiqish qatlamlari (output layers) bilan birga joylashtirish (stacking) orqali to’liq Deep Residual Shrinkage Network hosil qilinadi.
5. Umumlashtirish qobiliyati (Generalization Capability)
Deep Residual Shrinkage Network, aslida, umumiy featurelarni o’rganish (general feature learning) usulidir. Chunki ko’plab feature o’rganish vazifalarida namunalar ozmi-ko’pmi shovqin va keraksiz ma’lumotlarni o’z ichiga oladi. Bu shovqin va keraksiz ma’lumotlar featurelarni o’rganish samaradorligiga ta’sir qilishi mumkin. Masalan:
Tasvirlarni klassifikatsiya qilishda (image classification), agar rasmda bir vaqtning o’zida ko’plab boshqa obyektlar bo’lsa, bu obyektlarni “shovqin” deb tushunish mumkin. Deep Residual Shrinkage Network ushbu “shovqin”ni payqash uchun Attention mexanizmidan foydalanishi va keyin bu “shovqin”ga mos keladigan featurelarni nolga tenglashtirish uchun Soft Thresholdingni qo’llashi mumkin, bu esa tasvirni klassifikatsiya qilish aniqligini oshirishi mumkin.
Nutqni aniqlashda (speech recognition), xususan, yo’l chetida yoki zavod sexi ichidagi suhbat kabi nisbatan shovqinli muhitda, Deep Residual Shrinkage Network nutqni aniqlash aniqligini oshirishi mumkin yoki hech bo’lmaganda nutqni aniqlash aniqligini oshirishga qodir metodologiyani taklif qilishi mumkin.
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Akademik ta’sir (Academic Impact)
Ushbu maqola Google Scholar-da 1400 dan ortiq iqtibos (citation) oldi.
To’liq bo’lmagan statistik ma’lumotlarga ko’ra, Deep Residual Shrinkage Network (DRSN) mashinasozlik, elektr energetikasi, ko’rish (vision), sog’liqni saqlash, nutq, matn, radar va masofadan zondlash (remote sensing) kabi ko’plab sohalarda 1000 dan ortiq nashrlar/tadqiqotlarda bevosita qo’llanilgan yoki o’zgartirilgan holda qo’llanilgan.