Ang Deep Residual Shrinkage Network kay usa ka improved variant sa Deep Residual Network. Sa tinuud lang, integration kini sa Deep Residual Network, attention mechanisms, ug soft thresholding functions.
Sa usa ka sukod, ang working principle sa Deep Residual Shrinkage Network masabtan nato ani nga paagi: naggamit kini og attention mechanisms para ma-identify ang mga unimportant features, ug naggamit og soft thresholding functions para himoon silang zero; vice versa, gi-identify niini ang mga important features ug gi-retain sila. Kini nga proseso nagpalig-on sa abilidad sa deep neural network nga maka-extract og mga useful features gikan sa mga signals nga adunay noise.
1. Research Motivation
Una, inig classify nato sa mga samples, ang presensya sa noise—sama sa Gaussian noise, pink noise, ug Laplacian noise—dili gyud malikayan. Sa mas lapad nga pagtan-aw, ang mga samples kasagaran adunay impormasyon nga irrelevant sa current classification task, nga pwede usab nato isipon nga noise. Kani nga noise makadaot sa classification performance. (Ang soft thresholding kay usa ka key step sa daghang signal denoising algorithms.)
Pananglitan, samtang nag-istoryahanay sa daplin sa kalsada, ang audio mahimong masagol sa tingog sa mga busina ug ligid sa sakyanan. Kung mag-perform ta og speech recognition aning mga signals, ang resulta siguradong maapektuhan aning mga background sounds. Gikan sa deep learning perspective, ang mga features nga nag-correspond sa busina ug ligid kinahanglan tangtangon sa sulod sa deep neural network aron dili sila makaapekto sa speech recognition results.
Ikaduha, bisan sa sulod sa parehas nga dataset, ang kadaghanon sa noise kasagaran magkalahi matag sample. (Parehas kini og konsepto sa attention mechanisms; kung magkuha tag image dataset isip pananglitan, ang lokasyon sa target object mahimong magkalahi sa matag image, ug ang attention mechanisms maka-focus sa specific nga lokasyon sa target object sa matag image.)
Pananglitan, kung mag-train ta og cat-and-dog classifier, hunahunaa ang lima ka images nga gi-label og “dog.” Ang first image naay iro ug ilaga, ang second naay iro ug gansa, ang third naay iro ug manok, ang fourth naay iro ug asno, ug ang fifth naay iro ug itik. Inig training, ang classifier siguradong ma-interfere sa mga irrelevant objects sama sa ilaga, gansa, manok, asno, ug itik, nga moresulta sa pagbaba sa classification accuracy. Kung ma-identify nato ning mga irrelevant objects—ang mga ilaga, gansa, manok, asno, ug itik—ug ma-eliminate ang ilang corresponding features, posible nga motaas ang accuracy sa cat-and-dog classifier.
2. Soft Thresholding
Ang Soft thresholding kay usa ka core step sa daghang signal denoising algorithms. Gi-eliminate niini ang mga features kansang absolute values mas ubos kaysa sa usa ka threshold, ug gi-shrink ang mga features kansang absolute values mas taas kaysa niini nga threshold paingon sa zero. Ma-implement kini gamit ang mosunod nga formula:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Ang derivative sa soft thresholding output with respect sa input kay:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Sama sa gipakita sa taas, ang derivative sa soft thresholding kay either 1 or 0. Kini nga property parehas ra sa ReLU activation function. Tungod niini, ang soft thresholding makapaminus usab sa risk nga ang deep learning algorithms makasugat og gradient vanishing ug gradient exploding.
Sa soft thresholding function, ang pag-set sa threshold kinahanglan mag-satisfy og duha ka conditions: una, ang threshold kinahanglan positive number; ikaduha, ang threshold dili pwede molapas sa maximum value sa input signal, kay kung dili, ang output mahimong pure zero.
Dugang pa, mas maayo kung ang threshold mag-satisfy sa ikatulo nga condition: matag sample kinahanglan adunay kaugalingong independent threshold base sa noise content niini.
Kini tungod kay ang noise content kasagaran magkalahi sa mga samples. Pananglitan, komon sa parehas nga dataset nga ang Sample A adunay gamay nga noise samtang ang Sample B adunay daghan nga noise. Sa kini nga kaso, kung mag-perform og soft thresholding sa usa ka denoising algorithm, ang Sample A dapat mogamit og gamay nga threshold, samtang ang Sample B dapat mogamit og dako nga threshold. Bisan kung kining mga features ug thresholds mawad-an sa ilang klaro nga physical definitions sa sulod sa deep neural networks, ang basic underlying logic nagpabilin nga pareho. Sa laing pagkasulti, matag sample kinahanglan adunay kaugalingong independent threshold nga determinado sa specific nga noise content niini.
3. Attention Mechanism
Ang Attention mechanisms medyo dali sabton sa field sa computer vision. Ang visual systems sa mga hayop makaila sa targets pinaagi sa paspas nga pag-scan sa tibuok area, ug dayon i-focus ang attention sa target object para ma-extract ang daghang detalye samtang gi-suppress ang irrelevant information. Para sa specifics, palihug refer sa literature bahin sa attention mechanisms.
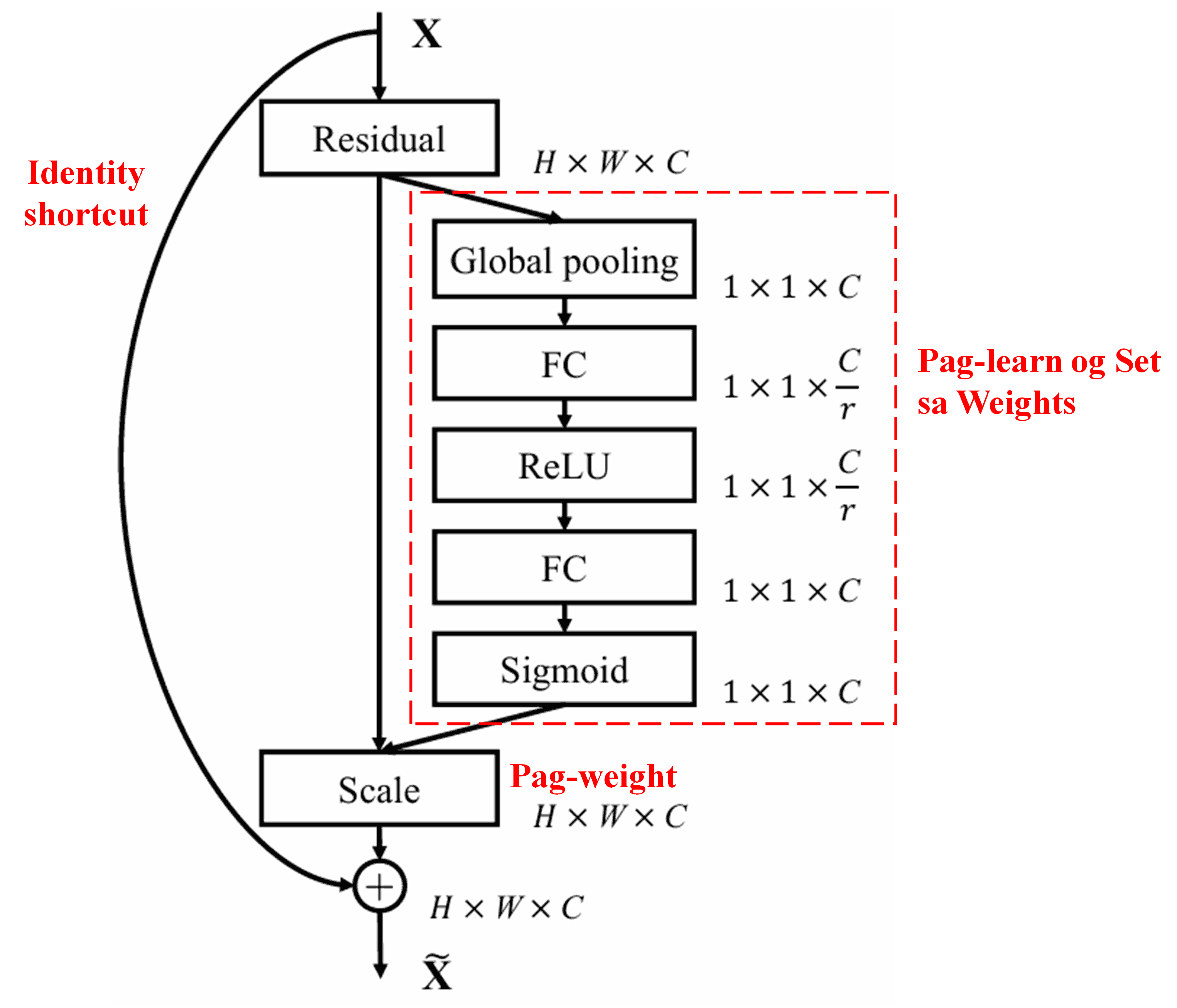
Ang Squeeze-and-Excitation Network (SENet) nagrepresentar sa usa ka relatively new deep learning method nga naggamit og attention mechanisms. Sa lain-laing samples, ang contribution sa lain-laing feature channels ngadto sa classification task kasagaran magkalahi. Ang SENet naggamit og gamay nga sub-network para makakuha og set sa weights ug dayon i-multiply kini nga mga weights sa mga features sa tagsa-tagsa ka channels aron ma-adjust ang gidak-on sa features sa matag channel. Kini nga proseso pwede tan-awon isip pag-apply og lain-laing levels sa attention sa lain-laing feature channels.
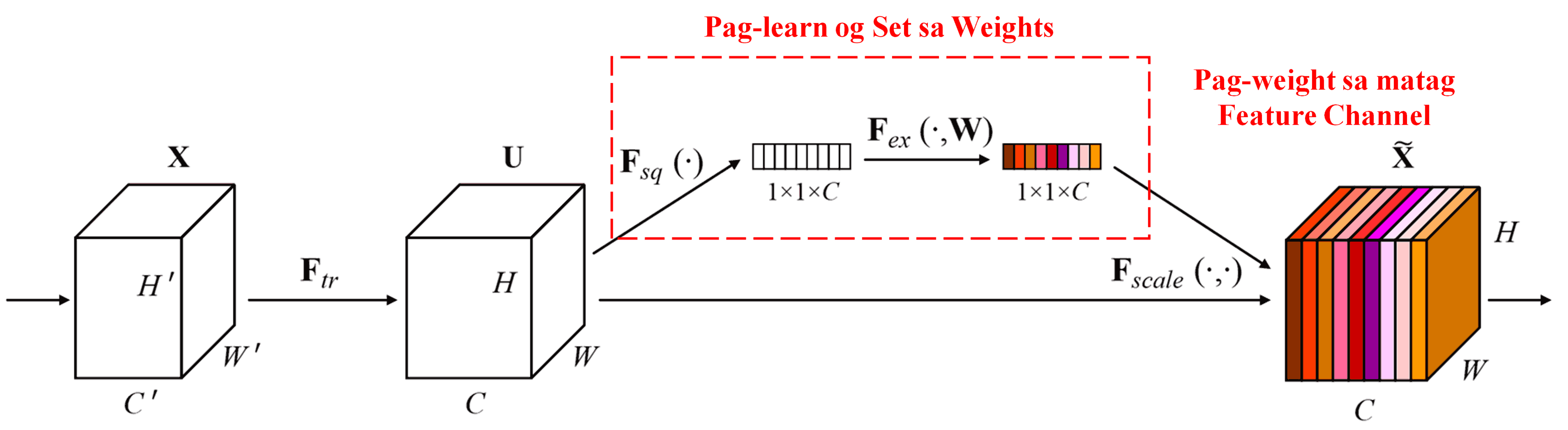
Niini nga pamaagi, matag sample adunay kaugalingon nga independent set sa weights. Sa laing pagkasulti, ang weights para sa bisan asang duha ka samples kay magkalahi. Sa SENet, ang specific path para makuha ang weights kay “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function.”
4. Soft Thresholding with Deep Attention Mechanism
Ang Deep Residual Shrinkage Network mikuha og inspirasyon gikan sa nahisgutan nga SENet sub-network structure aron ma-implement ang soft thresholding under sa usa ka deep attention mechanism. Pinaagi sa sub-network (nga gipakita sulod sa red box), ang usa ka set sa thresholds mahimong makat-unan (learned) para ma-apply ang soft thresholding sa matag feature channel.
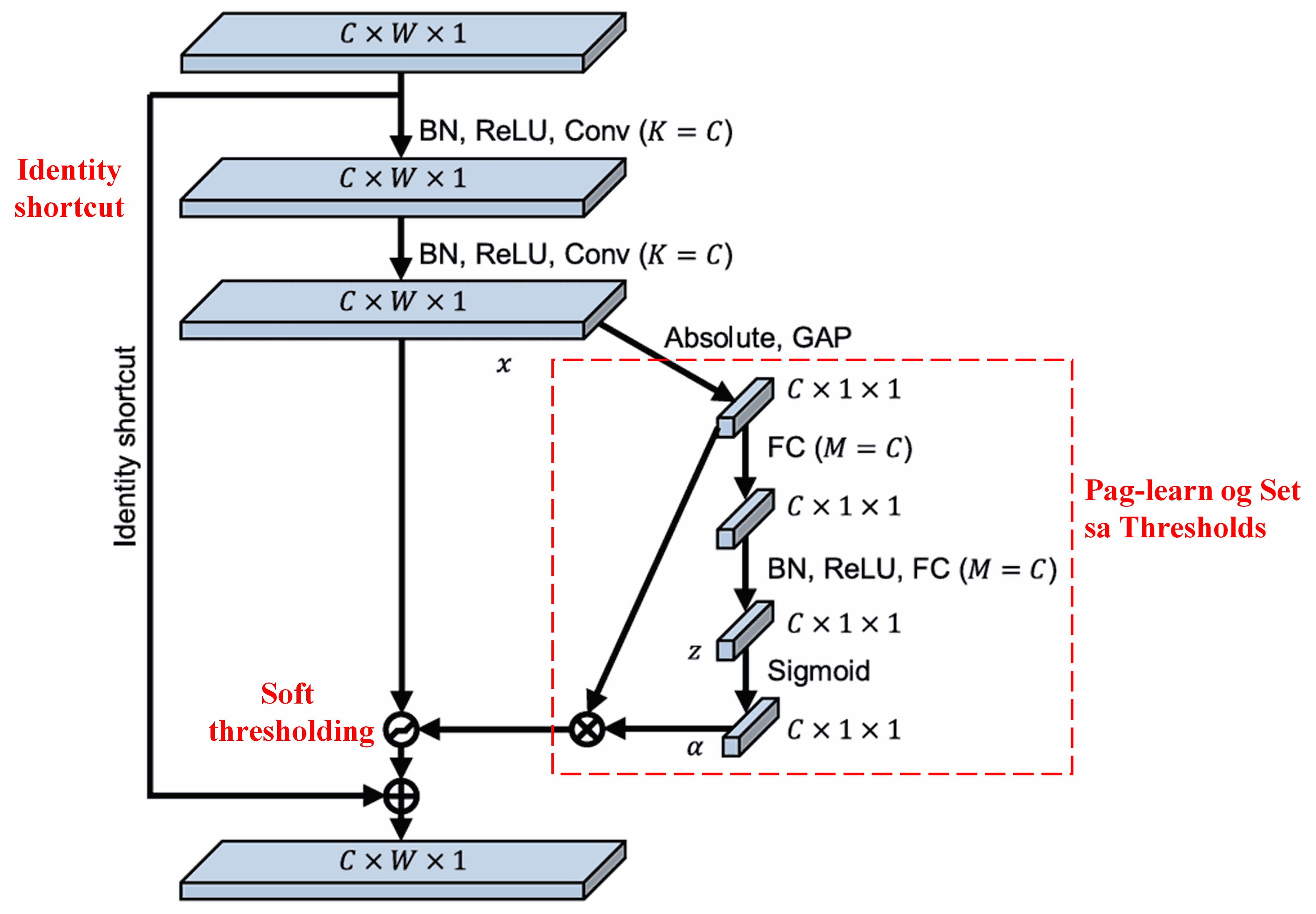
Niini nga sub-network, ang absolute values sa tanang features sa input feature map una nga gikalkulo. Dayon, pinaagi sa global average pooling ug pag-average, makuha ang usa ka feature, nga atong tawgon nga A. Sa pikas nga path, ang feature map pagkahuman sa global average pooling i-input ngadto sa usa ka gamay nga fully connected network. Kini nga fully connected network naggamit sa Sigmoid function isip final layer niini aron i-normalize ang output between 0 ug 1, nga moresulta sa usa ka coefficient nga tawgon nato og α. Ang final nga threshold ma-express isip α×A. Busa, ang threshold kay product sa numero nga between 0 ug 1 ug ang average sa absolute values sa feature map. Kini nga method nag-ensure nga ang threshold dili lang positive pero dili usab sobra kadako.
Dugang pa, ang lain-laing samples moresulta sa lain-laing thresholds. Tungod niini, sa usa ka sukod, ma-interpret kini isip usa ka specialized attention mechanism: gi-identify niini ang mga features nga irrelevant sa current task, gi-transform sila ngadto sa values nga duol sa zero pinaagi sa duha ka convolutional layers, ug gi-set sila sa zero gamit ang soft thresholding; o kaha, gi-identify niini ang mga features nga relevant sa current task, gi-transform sila ngadto sa values nga layo sa zero pinaagi sa duha ka convolutional layers, ug gi-preserve sila.
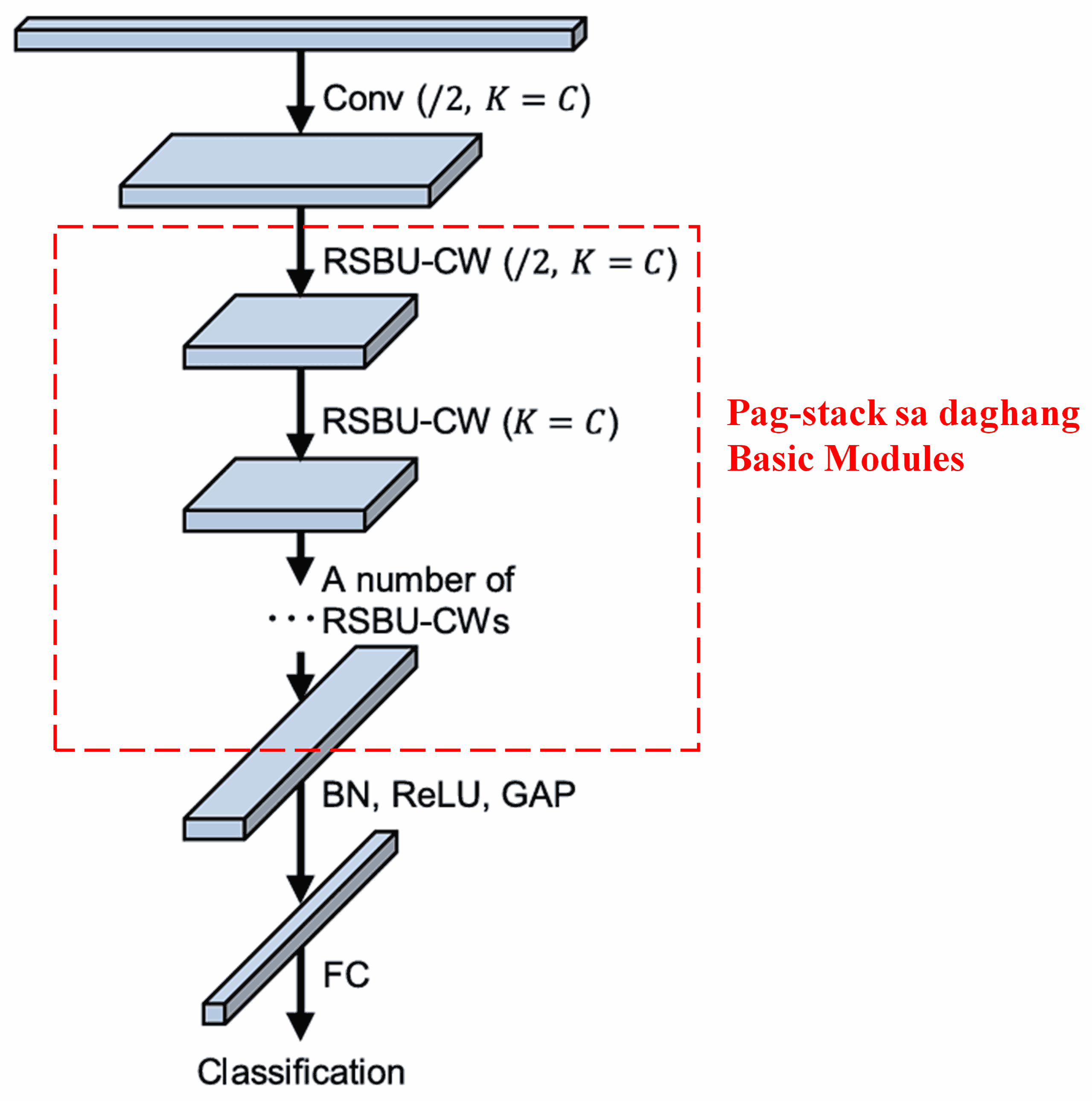
Sa katapusan, pinaagi sa pag-stack sa certain number of basic modules uban sa convolutional layers, batch normalization, activation functions, global average pooling, ug fully connected output layers, ang kompletong Deep Residual Shrinkage Network ang mabuo.
5. Generalization Capability
Ang Deep Residual Shrinkage Network kay, sa tinuud, usa ka general feature learning method. Tungod kini kay, sa daghang feature learning tasks, ang mga samples more or less adunay noise ug irrelevant information. Kini nga noise ug irrelevant information mahimong makaapekto sa performance sa feature learning. Pananglitan:
Sa image classification, kung ang image dungan nga adunay daghang uban nga objects, kini nga mga objects masabtan isip “noise.” Ang Deep Residual Shrinkage Network mahimong makagamit sa attention mechanism aron ma-notice kini nga “noise” ug dayon gamiton ang soft thresholding aron i-set ang features nga nag-correspond niini nga “noise” ngadto sa zero, sa ingon posibleng mapataas ang image classification accuracy.
Sa speech recognition, specific sa mga environment nga medyo saba (noisy) sama sa conversational settings sa daplin sa kalsada o sa sulod sa factory workshop, ang Deep Residual Shrinkage Network mahimong makapataas sa speech recognition accuracy, o at least, maka-offer og methodology nga capable sa pagpataas sa speech recognition accuracy.
Reference
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Academic Impact
Kini nga paper nakadawat na og kapin sa 1,400 ka citations sa Google Scholar.
Base sa incomplete statistics, ang Deep Residual Shrinkage Network (DRSN) direkta nga na-apply o na-modify ug na-apply sa kapin sa 1,000 ka publications/studies sa nagkalain-laing fields, apil na ang mechanical engineering, electrical power, vision, healthcare, speech, text, radar, ug remote sensing.