Deep Residual Shrinkage Network (DRSN) คือเวอร์ชันปรับปรุงของ Deep Residual Network (ResNet) ซึ่งโดยเนื้อแท้แล้ว มันคือการผสมผสานรวมกันระหว่าง Deep Residual Network, กลไก Attention Mechanism และฟังก์ชัน Soft Thresholding
ในระดับหนึ่ง หลักการทำงานของ Deep Residual Shrinkage Network สามารถทำความเข้าใจได้ดังนี้: มันใช้กลไก Attention Mechanism เพื่อสังเกต Feature ที่ “ไม่สำคัญ” และใช้ฟังก์ชัน Soft Thresholding เปลี่ยนค่าเหล่านั้นให้เป็นศูนย์ (Zero) หรือในทางกลับกัน คือการใช้ Attention Mechanism เพื่อสังเกต Feature ที่ “สำคัญ” และเก็บรักษาค่าเหล่านั้นไว้ กระบวนการนี้ช่วยเพิ่มความสามารถของโครงข่ายประสาทเทียม (Deep Neural Network) ในการสกัด Feature ที่มีประโยชน์ออกมาจากสัญญาณที่เต็มไปด้วยสัญญาณรบกวน (Noise)
1. แรงจูงใจในการวิจัย (Research Motivation)
ประการแรก ในการจำแนกประเภทของตัวอย่าง (Classification) ข้อมูลมักจะมีสัญญาณรบกวน (Noise) ปะปนมาอย่างหลีกเลี่ยงไม่ได้ เช่น Gaussian noise, Pink noise หรือ Laplacian noise หากพูดในมุมมองที่กว้างขึ้น ตัวอย่างข้อมูลมักจะมีข้อมูลที่ไม่เกี่ยวข้องกับงานจำแนกประเภทปะปนอยู่ ซึ่งข้อมูลเหล่านี้ก็สามารถเปรียบเสมือนเป็น Noise ได้เช่นกัน และ Noise เหล่านี้อาจส่งผลเสียต่อความแม่นยำในการจำแนกประเภท (ซึ่ง Soft Thresholding ถือเป็นขั้นตอนสำคัญในอัลกอริทึมการลด Noise ของสัญญาณหลายๆ ตัว)
ยกตัวอย่างเช่น ขณะคุยกันริมถนน เสียงบทสนทนาอาจมีเสียงแตรรถหรือเสียงล้อรถแทรกเข้ามา เมื่อนำเสียงเหล่านี้ไปผ่านระบบรู้จำเสียงพูด (Speech Recognition) ผลลัพธ์ที่ได้ย่อมได้รับผลกระทบจากเสียงแตรและเสียงล้อรถเหล่านั้นอย่างหลีกเลี่ยงไม่ได้ ในมุมมองของ Deep Learning นั้น Feature ที่เกี่ยวข้องกับเสียงแตรและเสียงล้อรถควรจะถูกลบออกไปภายในโครงข่ายประสาทเทียม เพื่อไม่ให้ส่งผลกระทบต่อผลลัพธ์ของการรู้จำเสียง
ประการที่สอง แม้แต่ในชุดข้อมูล (Dataset) เดียวกัน ปริมาณของ Noise ในแต่ละตัวอย่าง (Sample) ก็มักจะไม่เท่ากัน (จุดนี้มีความคล้ายคลึงกับกลไก Attention Mechanism ตัวอย่างเช่น ในชุดข้อมูลรูปภาพ ตำแหน่งของวัตถุเป้าหมายในแต่ละภาพอาจแตกต่างกัน ซึ่ง Attention Mechanism สามารถโฟกัสไปยังตำแหน่งของวัตถุในแต่ละภาพได้อย่างแม่นยำ)
สมมติว่าเรากำลังเทรนโมเดลจำแนก “สุนัข vs แมว” โดยมีรูปภาพที่มีป้ายกำกับว่าเป็น “สุนัข” จำนวน 5 รูป: รูปที่ 1 อาจมีสุนัขกับหนู, รูปที่ 2 มีสุนัขกับห่าน, รูปที่ 3 มีสุนัขกับไก่, รูปที่ 4 มีสุนัขกับลา, และรูปที่ 5 มีสุนัขกับเป็ด ในขณะที่เราเทรนตัวจำแนกสุนัข เราจะถูกรบกวนจากวัตถุที่ไม่เกี่ยวข้องอย่าง หนู, ห่าน, ไก่, ลา และเป็ด อย่างหลีกเลี่ยงไม่ได้ ซึ่งทำให้ความแม่นยำลดลง แต่ถ้าเราสามารถ “สังเกต” เห็นสิ่งที่ไม่เกี่ยวข้องเหล่านี้ และลบ Feature ของพวกมันออกไปได้ ก็จะช่วยเพิ่มความแม่นยำของตัวจำแนกสุนัขและแมวได้
2. ฟังก์ชัน Soft Thresholding
Soft Thresholding คือหัวใจสำคัญของอัลกอริทึมการลดสัญญาณรบกวน (Signal Denoising) หลายๆ ตัว โดยมันจะทำการลบ Feature ที่มีค่าสัมบูรณ์ (Absolute value) ต่ำกว่าค่าขีดจำกัด (Threshold) ที่กำหนด และทำการ “หด” (Shrink) Feature ที่มีค่ามากกว่า Threshold ให้เข้าใกล้ศูนย์ ซึ่งสามารถเขียนเป็นสมการได้ดังนี้:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]ค่าอนุพันธ์ (Derivative) ของผลลัพธ์จาก Soft Thresholding เทียบกับอินพุต คือ:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]จากสมการข้างต้น จะเห็นว่าค่าอนุพันธ์ของ Soft Thresholding จะเป็น 1 หรือไม่ก็ 0 เท่านั้น ซึ่งคุณสมบัตินี้เหมือนกับฟังก์ชันกระตุ้นแบบ ReLU ดังนั้น Soft Thresholding จึงสามารถช่วยลดความเสี่ยงที่ Deep Learning จะเจอกับปัญหา Gradient Vanishing และ Gradient Exploding ได้เช่นกัน
ในการใช้งานฟังก์ชัน Soft Thresholding การกำหนดค่า Threshold จะต้องเป็นไปตามเงื่อนไข 2 ข้อ: ข้อแรก Threshold ต้องเป็นค่าบวก และข้อสอง Threshold ต้องไม่มากกว่าค่าสูงสุดของสัญญาณอินพุต มิฉะนั้นผลลัพธ์ที่ได้จะเป็นศูนย์ทั้งหมด
นอกจากนี้ ค่า Threshold ควรจะเป็นไปตามเงื่อนไขที่ 3 ด้วย นั่นคือ: แต่ละตัวอย่าง (Sample) ควรจะมีค่า Threshold ที่เป็นอิสระของตัวเอง โดยขึ้นอยู่กับปริมาณ Noise ของตัวอย่างนั้นๆ
เหตุผลก็คือ ปริมาณ Noise ในแต่ละตัวอย่างมักจะแตกต่างกัน เช่น บ่อยครั้งที่ใน Dataset เดียวกัน ตัวอย่าง A มี Noise น้อย แต่ตัวอย่าง B มี Noise เยอะ ดังนั้นเมื่อใช้อัลกอริทึมลด Noise ด้วย Soft Thresholding ตัวอย่าง A ก็ควรใช้ Threshold ที่ต่ำ ส่วนตัวอย่าง B ก็ควรใช้ Threshold ที่สูงกว่า แม้ว่าใน Deep Neural Network ความหมายทางฟิสิกส์ที่ชัดเจนของ Feature และ Threshold เหล่านี้อาจจะจางหายไป แต่หลักการพื้นฐานก็ยังคงเหมือนเดิม นั่นคือ แต่ละตัวอย่างควรมีค่า Threshold เฉพาะของตัวเองตามระดับของ Noise ที่มีอยู่
3. กลไก Attention Mechanism
Attention Mechanism ในวงการ Computer Vision นั้นค่อนข้างเข้าใจง่าย ระบบการมองเห็นของสัตว์สามารถกวาดสายตาดูพื้นที่ทั้งหมดได้อย่างรวดเร็วเพื่อค้นหาวัตถุเป้าหมาย จากนั้นจะโฟกัสความสนใจ (Attention) ไปที่วัตถุนั้นเพื่อเก็บรายละเอียดให้มากขึ้น และในขณะเดียวกันก็ยับยั้งข้อมูลที่ไม่เกี่ยวข้อง (สำหรับรายละเอียดเพิ่มเติม สามารถศึกษาได้จากบทความเกี่ยวกับ Attention Mechanism)
Squeeze-and-Excitation Network (SENet) เป็นวิธีการ Deep Learning แบบใหม่ที่ใช้ Attention Mechanism โดยหลักการคือ ในแต่ละตัวอย่าง (Sample) ช่องสัญญาณของ Feature (Feature Channels) แต่ละช่องมักจะส่งผลต่อการจำแนกประเภทไม่เท่ากัน SENet จึงใช้โครงข่ายย่อย (Sub-network) ขนาดเล็กเพื่อคำนวณชุดของ “ค่าน้ำหนัก” (Weights) ขึ้นมา แล้วนำน้ำหนักเหล่านี้ไปคูณกับ Feature ในแต่ละ Channel เพื่อปรับขนาดของ Feature กระบวนการนี้เปรียบเสมือนการให้ความสนใจ (Attention) กับแต่ละ Feature Channel ในระดับที่แตกต่างกัน
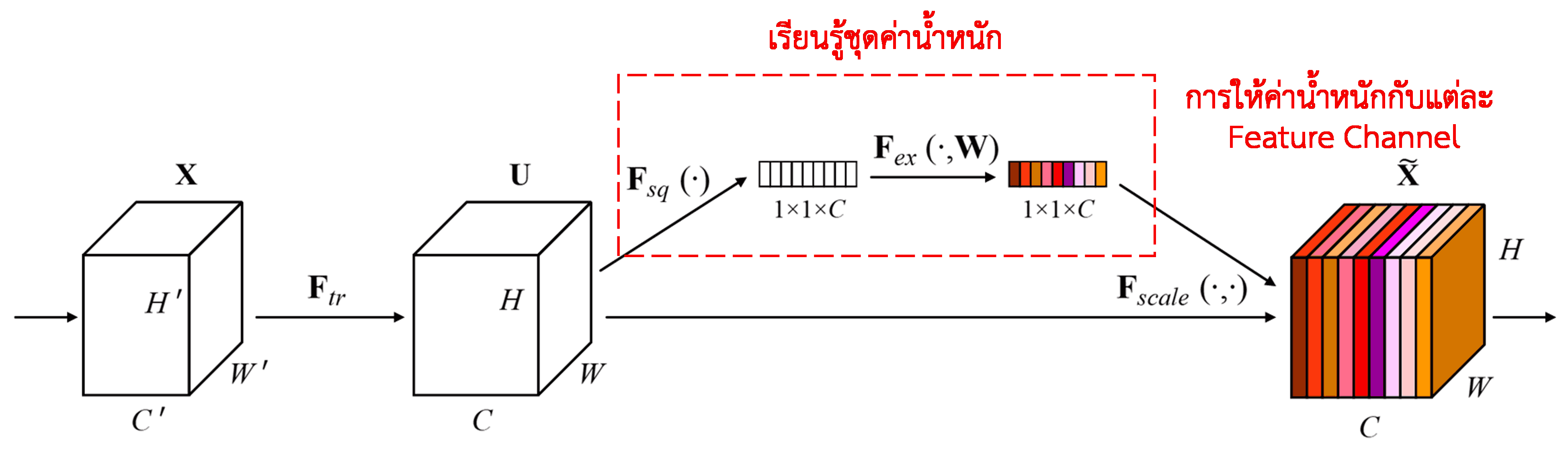
ด้วยวิธีการนี้ แต่ละตัวอย่างจะมีชุดค่าน้ำหนักเป็นของตัวเอง กล่าวคือ ตัวอย่าง 2 ตัวใดๆ จะมีค่าน้ำหนักที่ไม่เหมือนกัน ใน SENet เส้นทางในการคำนวณค่าน้ำหนักคือ “Global Pooling → Fully Connected Layer → ReLU → Fully Connected Layer → Sigmoid”
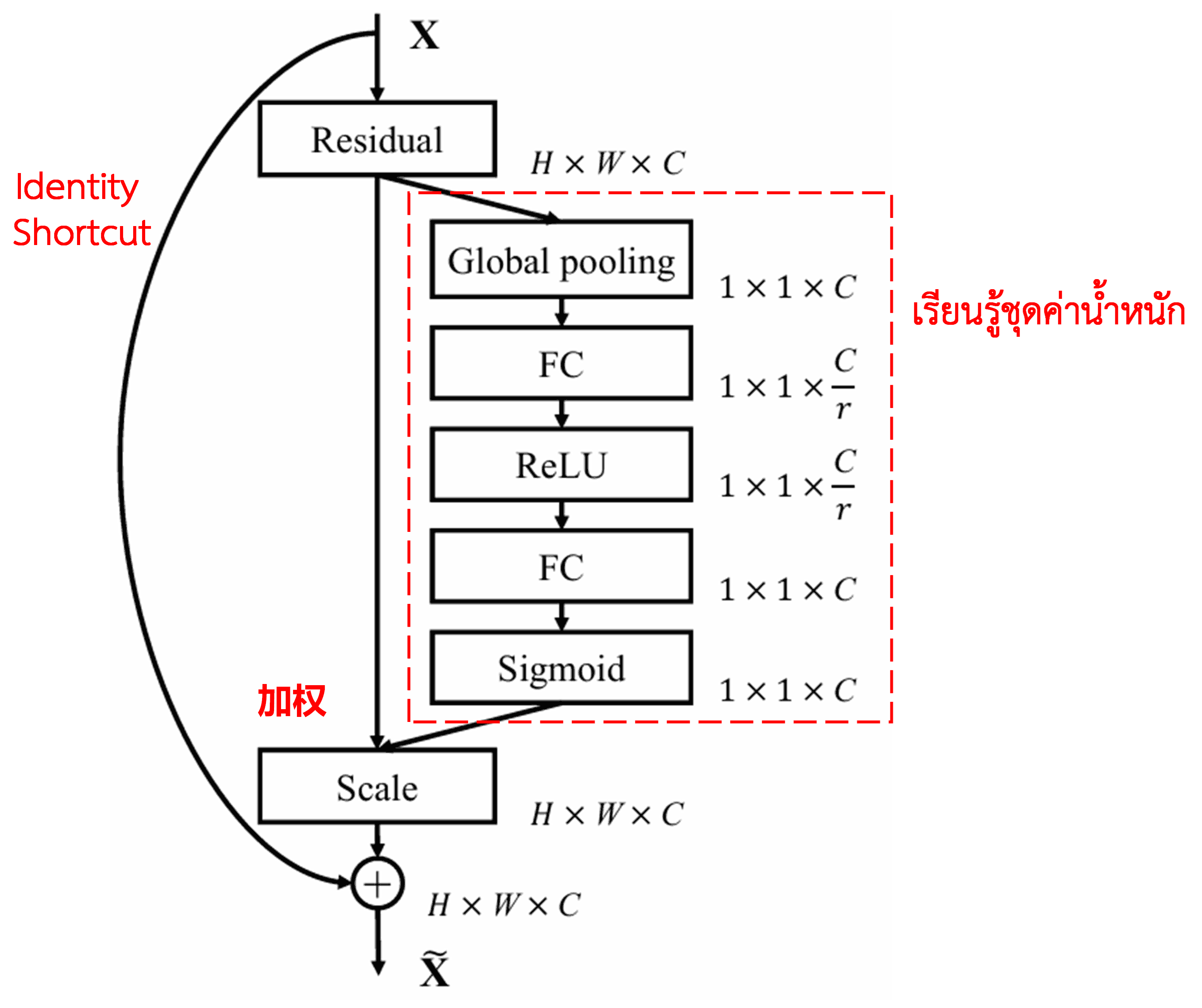
4. Soft Thresholding ภายใต้ Deep Attention Mechanism
Deep Residual Shrinkage Network ได้นำโครงสร้าง Sub-network ของ SENet ที่กล่าวถึงข้างต้นมาประยุกต์ใช้ เพื่อสร้าง Soft Thresholding ภายใต้กลไก Attention Mechanism แบบลึก โดยผ่าน Sub-network (ในกรอบสีแดง) เพื่อเรียนรู้และสร้างชุดค่า Threshold สำหรับทำ Soft Thresholding ให้กับแต่ละ Feature Channel
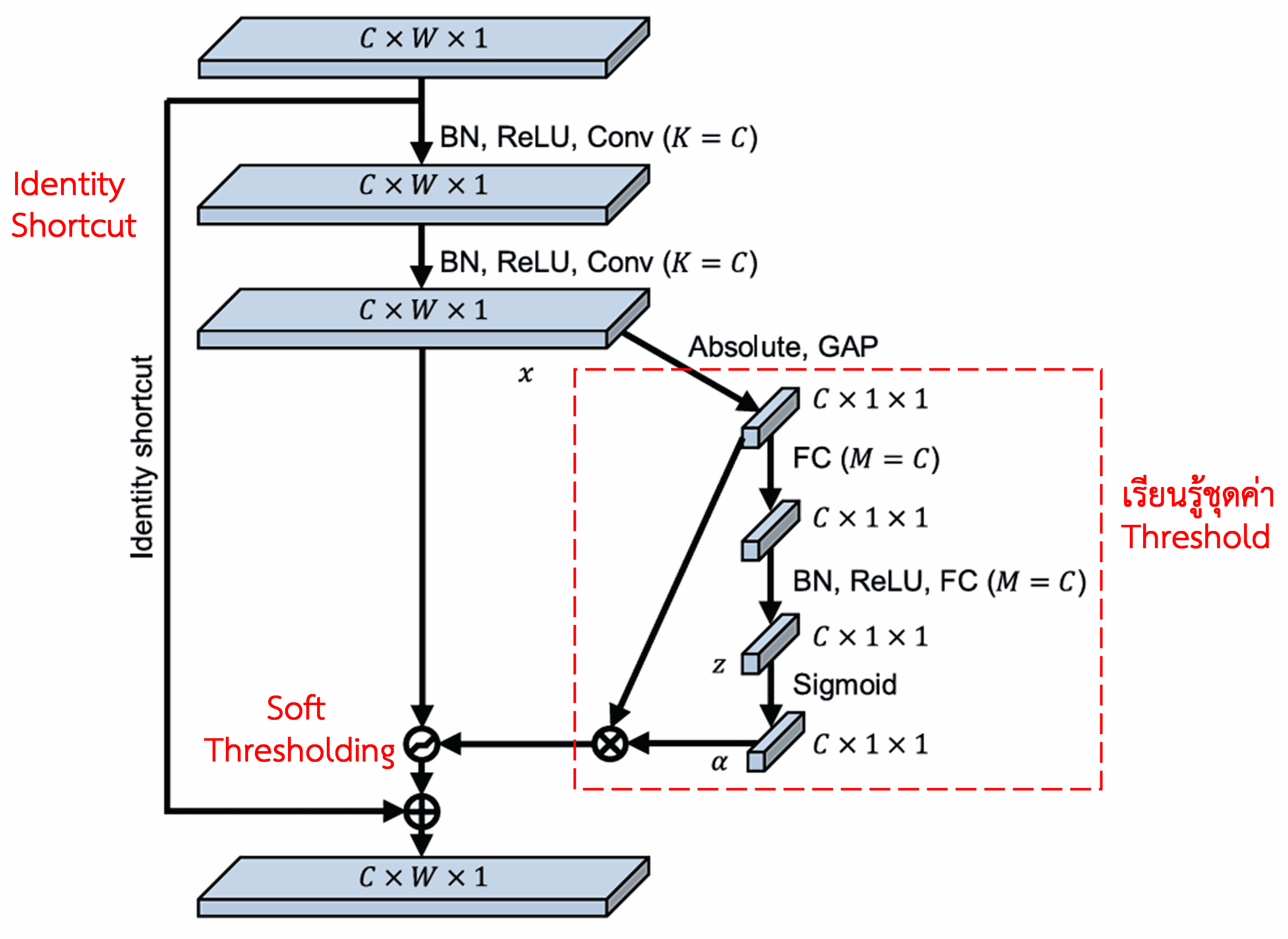
ใน Sub-network นี้ เริ่มแรกจะทำการหาค่าสัมบูรณ์ของทุก Feature ใน Input Feature Map จากนั้นผ่านกระบวนการ Global Average Pooling (GAP) และหาค่าเฉลี่ย เพื่อให้ได้ค่า Feature หนึ่งค่า สมมติให้เป็น A ในอีกเส้นทางหนึ่ง Feature Map ที่ผ่าน GAP แล้วจะถูกส่งเข้าไปใน Fully Connected Network ขนาดเล็ก ซึ่งมีฟังก์ชัน Sigmoid เป็นเลเยอร์สุดท้าย เพื่อปรับค่าให้อยู่ในช่วง 0 ถึง 1 และได้ค่าสัมประสิทธิ์ออกมา สมมติให้เป็น α ดังนั้นค่า Threshold สุดท้ายจะสามารถเขียนได้เป็น α × A สรุปได้ว่า ค่า Threshold คือผลคูณของตัวเลขระหว่าง 0 ถึง 1 กับค่าเฉลี่ยของค่าสัมบูรณ์ของ Feature Map วิธีนี้ไม่เพียงแต่รับประกันว่า Threshold จะเป็นค่าบวกเท่านั้น แต่ยังช่วยควบคุมไม่ให้ค่า Threshold ใหญ่เกินไปอีกด้วย
ยิ่งไปกว่านั้น ตัวอย่างที่แตกต่างกันก็จะมีค่า Threshold ที่แตกต่างกัน ดังนั้น ในระดับหนึ่ง เราสามารถเข้าใจได้ว่านี่คือ Attention Mechanism รูปแบบพิเศษ: โดยมันจะสังเกต Feature ที่ “ไม่เกี่ยวข้อง” กับงานปัจจุบัน แล้วเปลี่ยน Feature เหล่านี้ให้มีค่าเข้าใกล้ 0 ผ่าน Convolutional Layers สองชั้น จากนั้นใช้ Soft Thresholding ปรับให้เป็นศูนย์ (Zero) ไปเลย; หรือในทางกลับกัน คือการสังเกต Feature ที่ “เกี่ยวข้อง” และเปลี่ยนให้มีค่าห่างจาก 0 เพื่อเก็บรักษา Feature เหล่านั้นไว้
สุดท้าย เมื่อนำโมดูลพื้นฐานเหล่านี้มาซ้อนทับกัน (Stack) ร่วมกับ Convolutional layers, Batch Normalization, Activation functions, Global Average Pooling และ Fully Connected output layer ก็จะได้โครงสร้างที่สมบูรณ์ของ Deep Residual Shrinkage Network
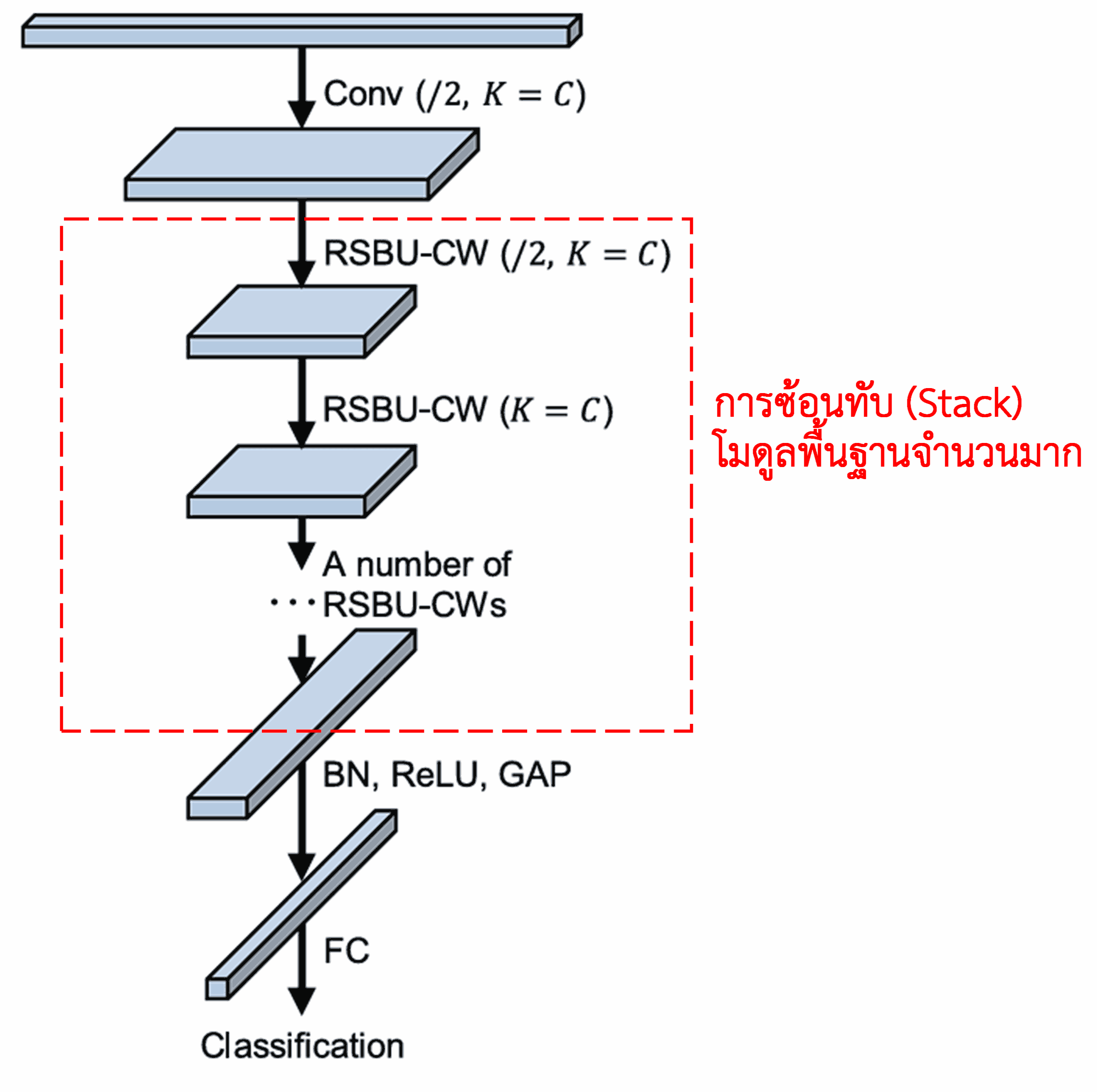
5. ความสามารถในการนำไปประยุกต์ใช้ทั่วไป (Generalization)
Deep Residual Shrinkage Network แท้จริงแล้วเป็นวิธีการเรียนรู้ Feature (Feature Learning) แบบทั่วไป เนื่องจากในงาน Feature Learning ส่วนใหญ่ ข้อมูลตัวอย่างมักจะมี Noise หรือข้อมูลที่ไม่เกี่ยวข้องปะปนอยู่ไม่มากก็น้อย ซึ่งสิ่งเหล่านี้อาจส่งผลกระทบต่อประสิทธิภาพการเรียนรู้ ตัวอย่างเช่น:
ในการจำแนกรูปภาพ (Image Classification) หากรูปภาพมีวัตถุอื่นๆ ปนอยู่ด้วยมากมาย วัตถุเหล่านั้นสามารถมองว่าเป็น “Noise” ได้ Deep Residual Shrinkage Network อาจจะสามารถใช้ Attention Mechanism เพื่อสังเกตเห็น “Noise” เหล่านี้ แล้วใช้ Soft Thresholding เพื่อปรับ Feature ที่เกี่ยวข้องกับ Noise ให้เป็นศูนย์ ซึ่งมีโอกาสที่จะช่วยเพิ่มความแม่นยำในการจำแนกรูปภาพได้
ในการรู้จำเสียงพูด (Speech Recognition) หากอยู่ในสภาพแวดล้อมที่มีเสียงรบกวน เช่น การคุยกันริมถนนหรือในโรงงาน Deep Residual Shrinkage Network อาจช่วยเพิ่มความแม่นยำในการรู้จำเสียง หรืออย่างน้อยก็เป็นแนวทางใหม่ที่สามารถนำไปพัฒนาเพื่อเพิ่มความแม่นยำได้
เอกสารอ้างอิง (Reference)
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
สถานะและผลกระทบทางวิชาการ (Academic Impact)
บทความวิจัยนี้ได้รับการอ้างอิง (Citation) บน Google Scholar มากกว่า 1,400 ครั้ง
จากสถิติเบื้องต้น Deep Residual Shrinkage Network (DRSN) ได้ถูกนำไปประยุกต์ใช้โดยตรง หรือถูกนำไปปรับปรุงเพื่อใช้งานในบทความวิจัยอื่นๆ มากกว่า 1,000 ฉบับ ครอบคลุมหลากหลายสาขา ทั้งวิศวกรรมเครื่องกล, ไฟฟ้า, คอมพิวเตอร์วิทัศน์ (Computer Vision), การแพทย์, การประมวลผลเสียง, ข้อความ, เรดาร์ และการสำรวจระยะไกล (Remote Sensing)