Deep Residual Shrinkage Network anedi Deep Residual Network yokka improved version. Asalu cheppalante, idi Deep Residual Network, Attention Mechanisms mariyu Soft Thresholding functions yokka integration (kalayika).
Oka rakamga cheppalante, Deep Residual Shrinkage Network yokka working principle ni manam ila artham chesukovachu: idi Attention Mechanism dwara unimportant features ni notice chesi, Soft Thresholding function dwara vatini zero chestundi; leda, important features ni notice chesi, vatini alage retain chestundi. Ee process valla, noise unna signals nundi useful features ni extract chese capacity Deep Neural Network ki perugutundi.
1. Research Motivation (Parishodhana Uddesyam)
Modatiga, samples ni classify chesetappudu, vatilo noise undadam sahajam. Like Gaussian noise, Pink noise, Laplacian noise. Inka broad ga cheppalante, current classification task ki sambandham leni information edaina sare “noise” kindake vastundi. Ee noise valla classification results meeda negative impact padutundi. (Signal denoising algorithms lo Soft Thresholding anedi oka key step).
Example ki, manam road pakkana matladukunetappudu, mana maatalatho paatu vehicles horn sounds, wheels sounds kuda mix avuthayi. Ee signals meeda Speech Recognition apply chesinappudu, results kachitamga aa horn mariyu wheel sounds valla affect avuthayi. Deep Learning perspective lo chuste, ee horn mariyu wheel sounds ki sambandhinchina features ni Deep Neural Network lopala delete cheyyali, appude speech recognition accurate ga untundi.
Rendavadi, oke dataset lo unna veru veru samples lo noise levels different ga undochu. (Idi Attention Mechanism concept ki daggaraga untundi; Example ki oka image dataset tisukunte, andulo target object position okko image lo okko daggara undochu; Attention mechanism prati image lo target object ekkada undo akkada focus chestundi).
Udaharanaki (For example), manam Cat-Dog classifier ni train chestunnam anukondi. “Dog” label unna 5 images tisukunte: 1st image lo Dog tho paatu Mouse undochu, 2nd image lo Goose, 3rd danilo Chicken, 4th danilo Donkey, 5th danilo Duck undochu. Manam classifier ni train chesetappudu, ee irrelevant objects (Mouse, Goose, Chicken, Donkey, Duck) valla disturbance kaligi, classification accuracy taggipothundi. Okavela manam ee irrelevant objects ni notice chesi, vatiki sambandhinchina features ni delete cheyagaligite, Cat-Dog classifier yokka accuracy perige chance untundi.
2. Soft Thresholding
Soft Thresholding anedi chala signal denoising algorithms lo oka core step. Idi absolute value oka threshold kante takkuva unna features ni delete chestundi, mariyu threshold kante ekkuva unna features ni zero vaipu shrink chestundi. Deenni kinda formula dwara implement cheyyochu:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Soft thresholding yokka output input paranga derivative ila untundi:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Paina chusnatlaite, soft thresholding yokka derivative eppudu 1 leda 0 untundi. Ee property ReLU Activation Function ki kuda same untundi. Anduvalla, Soft Thresholding use cheyyadam valla Deep Learning algorithms lo Gradient Vanishing mariyu Gradient Exploding risks taggutayi.
Soft thresholding function lo, threshold set chesetappudu rendu conditions kachitamga follow avvali: First, threshold positive number ayyi undali; Second, threshold input signal yokka maximum value kante ekkuva undakudadu, lekapote output mottam zero aipothundi.
Ide kakunda, threshold inkoka third condition ni kuda satisfy cheste manchidi: Prati sample ki dani noise content ni batti, daniki separate independent threshold undali.
Endukante, chala sarlu samples lo noise content different ga untundi. Example ki, oke sample set lo Sample A lo takkuva noise undochu, Sample B lo ekkuva noise undochu. Alantappudu, denoising algorithm lo soft thresholding apply chesetappudu, Sample A ki chinna threshold, Sample B ki pedda threshold upayoginchali. Deep Neural Networks lo ee features mariyu thresholds ki clear physical meaning lekapoyina, basic logic matram same untundi. Ante, prati sample ki dani noise content batti independent threshold undali.
3. Attention Mechanism
Computer Vision field lo Attention Mechanism ni artham chesukovadam chala easy. Animals yokka visual system surroundings ni fast ga scan chesi, target object ni find out chesi, dani meeda matrame attention pedutundi. Deeni valla more details extract cheyyadaniki mariyu irrelevant information ni ignore cheyyadaniki veeriki sadhyam avutundi. Details kosam Attention Mechanism articles refer cheyyochu.
Squeeze-and-Excitation Network (SENet) anedi attention mechanism based deep learning method. Classification tasks lo, different samples lo different feature channels yokka contribution veru veruga untundi. SENet oka chinna sub-network ni use chesi, oka set of weights ni generate chestundi. Ee weights ni aa channels features tho multiply chesi, vatini adjust chestundi. Ee process ni manam different feature channels meeda different attention apply cheyyadam ga bhavinchachu.
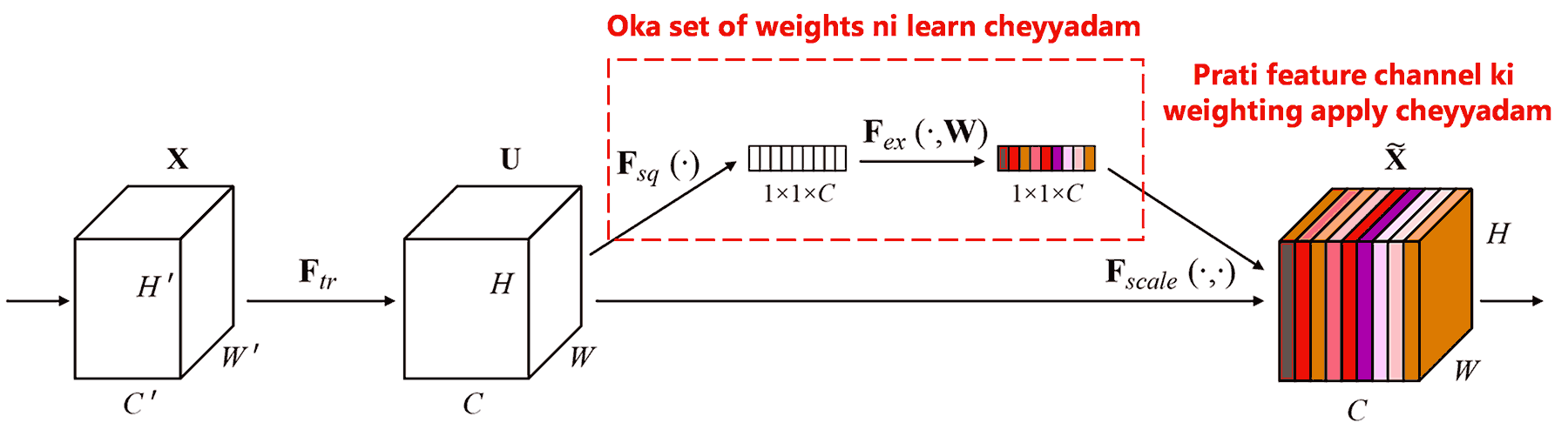
Ee method lo, prati sample ki dani sontha independent weights untayi. Ante, eh rendu samples ki weights same undavu. SENet lo, weights ponde path ila untundi: “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function”.
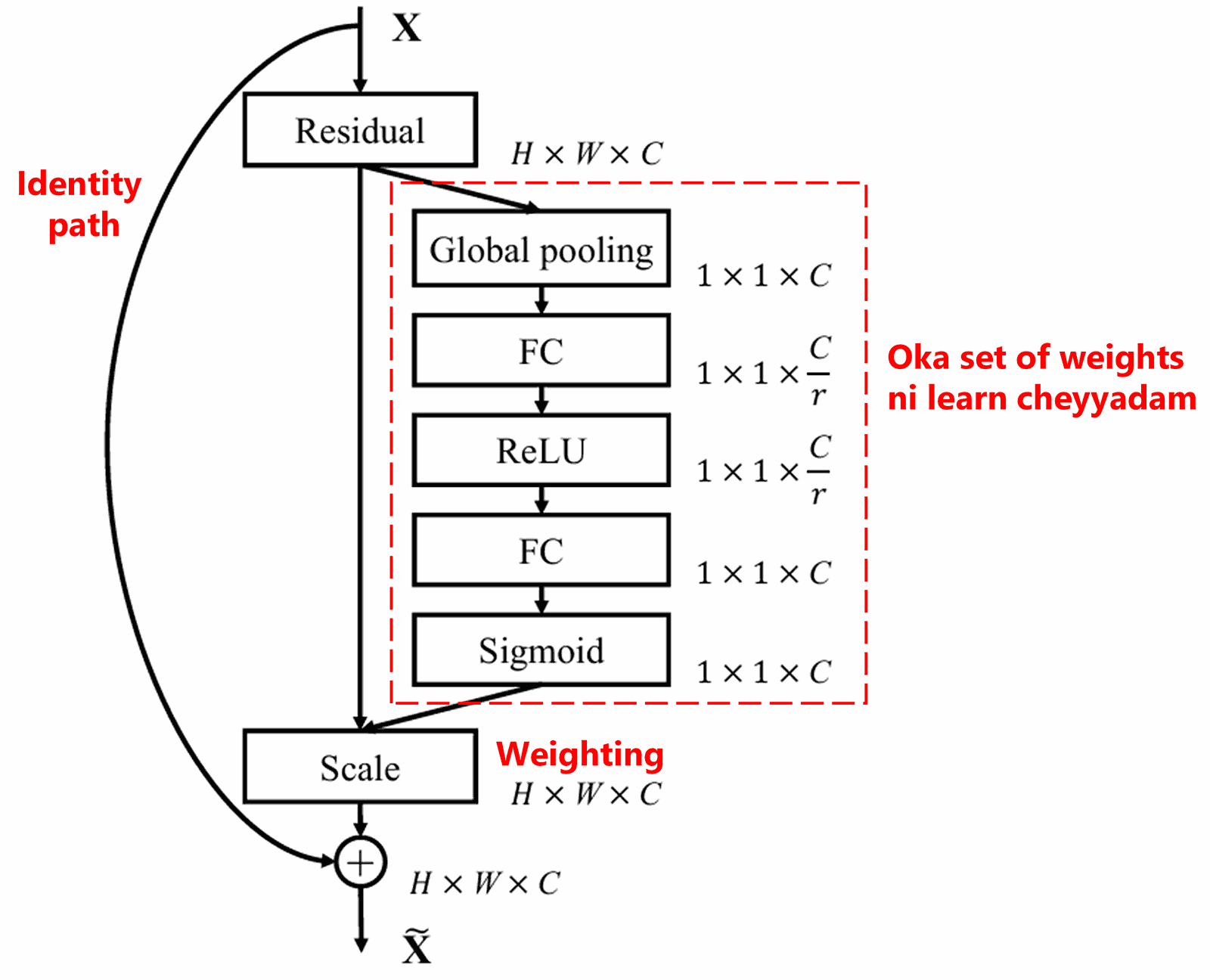
4. Deep Attention Mechanism kindha Soft Thresholding
Deep Residual Shrinkage Network, paina cheppina SENet sub-network structure ni base chesukoni, Deep Attention Mechanism kindha Soft Thresholding ni implement chestundi. Red box lo unna sub-network dwara, manam thresholds ni learn cheyyochu, vatini prati feature channel meeda soft thresholding cheyyadaniki use cheyyochu.
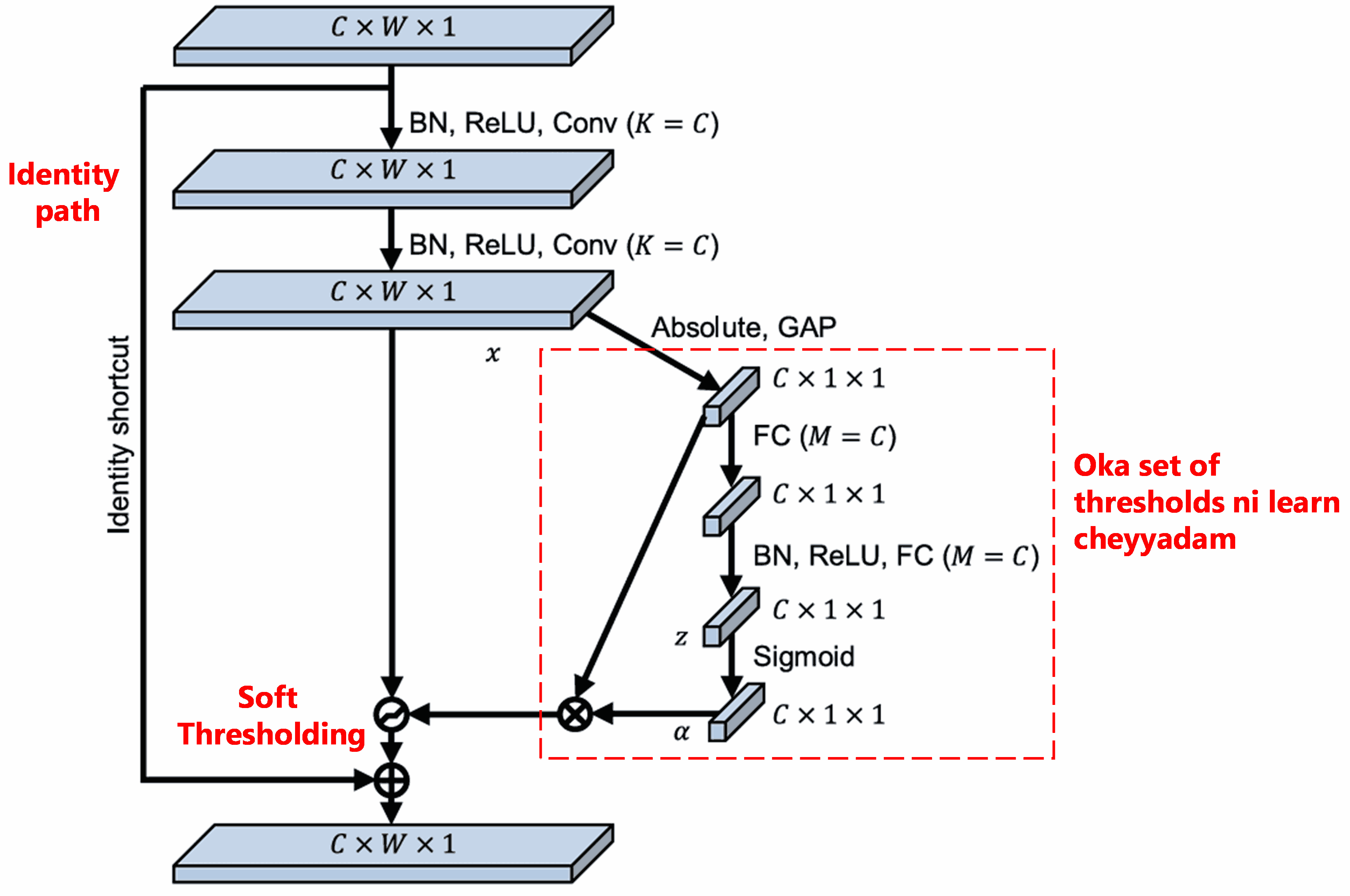
Ee sub-network lo, first input feature map yokka anni features yokka absolute values calculate chestaru. Tarvata Global Average Pooling dwara average chesi, oka feature ni pondutaru, deenni A anukundam. Inkoka path lo, Global Average Pooling tarvata vachina feature map ni oka chinna Fully Connected Network ki input ga istaru. Ee network last layer lo Sigmoid function ni use chesi, output ni 0 mariyu 1 madhya normalize chestundi. Ee coefficient ni α anukundam. Final threshold ni α×A ga cheppochu. So, threshold anedi 0 ki 1 ki madhya unde number × feature map absolute values yokka average. Ee paddhati valla, threshold positive ga undadame kakunda, mari ekkuva peddaga undakunda control lo untundi.
Inka mukhyamga, different samples ki different thresholds vastayi. Kabatti, deenni oka special Attention Mechanism ga manam artham chesukovachu: Current task ki sambandham leni features ni notice chesi, rendu convolutional layers dwara vatini near-zero values ga marchi, soft thresholding dwara vatini zero chestundi; Leda, task ki related features ni notice chesi, vatini retain chestundi.
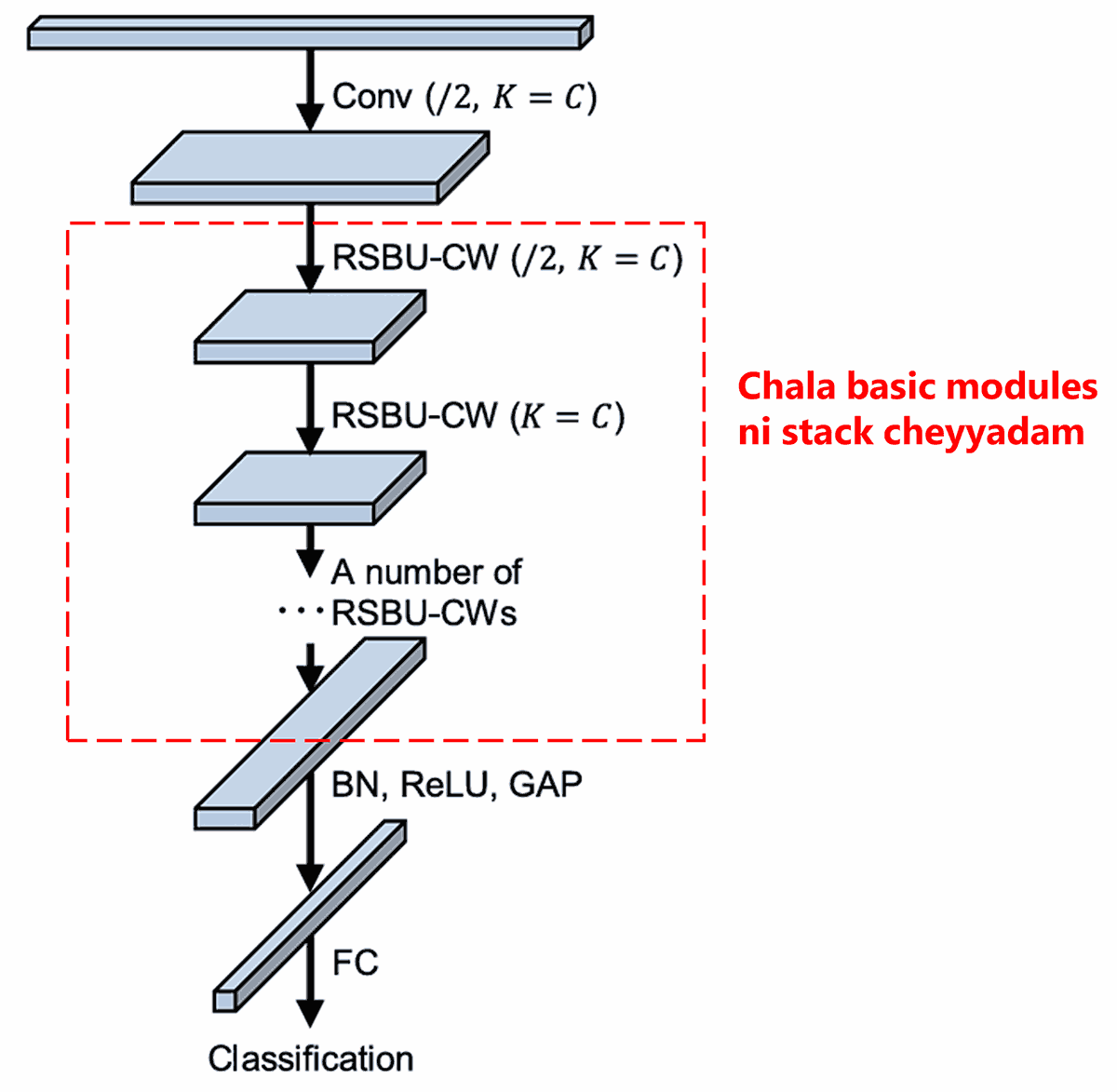
Final ga, konni basic modules, Convolutional layers, Batch Normalization, Activation functions, Global Average Pooling, mariyu Fully Connected output layer ni stack chesi complete Deep Residual Shrinkage Network ni form chestaru.
5. Generalization Capability (Sadharana Upayogalu)
Deep Residual Shrinkage Network anedi nijaniki oka general feature learning method. Endukante, chala varaku feature learning tasks lo, samples lo entho konta noise leda irrelevant information untundi. Ee noise feature learning meeda effect chupistundi. Udaharanaki:
Image classification lo, oka image lo chala objects unte, target kani objects ni “noise” ga bhavinchachu. Deep Residual Shrinkage Network attention mechanism dwara ee “noise” ni notice chesi, soft thresholding dwara vatini zero cheste, image classification accuracy perige avakasam undi.
Speech recognition lo, background noise ekkuva unna environments lo (like road pakkana, factory lo), Deep Residual Shrinkage Network accuracy ni improve cheyyadaniki help avvachu, leda oka kotha approach ni provide chestundi.
References
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Impact (Prabhavam)
Ee paper ki Google Scholar lo 1400 ki paiga citations vachayi.
Official statistics prakaram, Deep Residual Shrinkage Network ni 1000 ki paiga papers lo direct ga use cheyyadam leda improve chesi vadadam jarigindi. Idi Mechanical, Electrical power, Computer Vision, Medical, Speech, Text, Radar, mariyu Remote Sensing lanti chala fields lo upayoginchabadutundi.